CNN
CNN은 feature값을 얻어내기 위해 합성곱 연산을 하는 convolution layer, Convolution을 거쳐 나온 activation map이 있을 때 이를 이루는 convolution layer를 resizing 하여 새로운 layer를 얻는 pooling layer, 최종 결과물을 만들어 내는 fully connected layer로 구성된다.
fully connected layer가 최소화 또는 없어지는 추세인데 parameter 수가 늘어날 수록 학습이 어렵고 시간이 오래 걸리기 때문이다.
Convolution
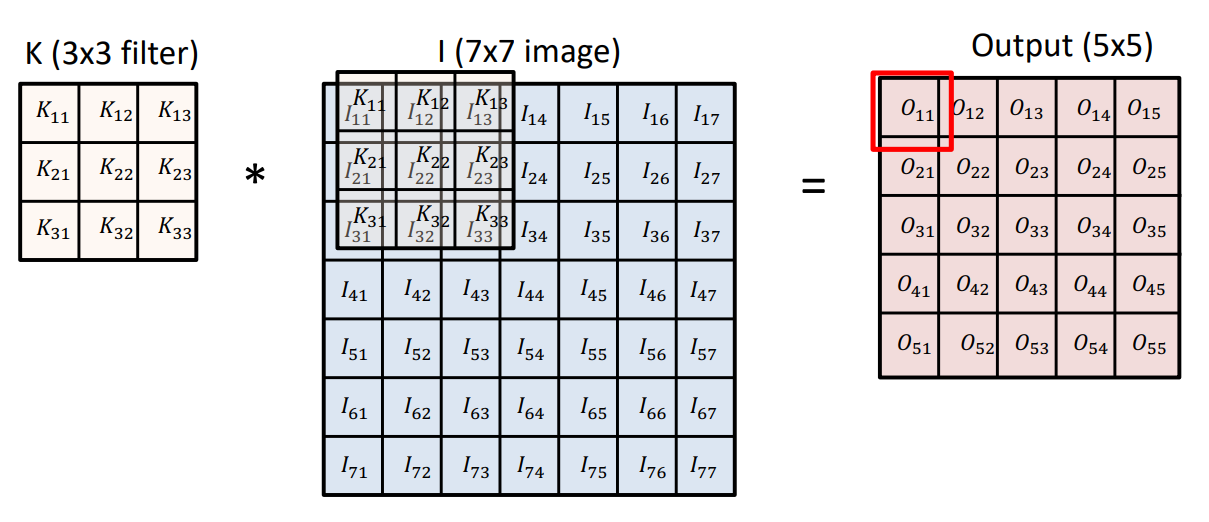
Output은 Convolution 필터를 적용하고자하는 이미지에 찍어서 나온다. 여기에 bias값을 더해줄 수 있다.
2D Convolution
27x27 이미지에 3x3 필터를 사용하면 이미지 상에서 필터가 적용될 때 3x3 픽셀의 이미지 값의 평균이 계산되고 이것이 output 값에서 한 픽셀의 값이 된다. 그래서 이미지 특정 영역에 대해 픽셀 값을 다 합쳐서 평균을 내므로 blur화 된 이미지가 만들어 진다.
RGB Image Convolution
이미지는 가로 세로 RGB 값을 의미하는 3개의 채널로 구성이 된다.
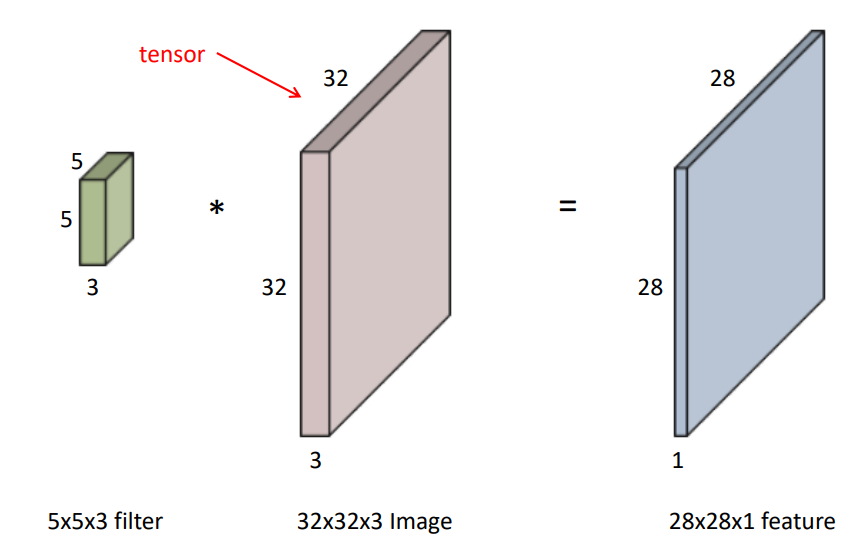
하나의 이미지에 대해서 하나의 필터를 적용하게 되면 채널이 1인 feature map이 나오게 된다. filter를 여러개 사용하면 feature map의 채널 수가 filter 만큼 늘어나게 된다. 그리고 한 번 Convolution이 거치게 되면 feature map의 각각의 Element들에 대해 Non Linear activation function(ReLU)을 적용하게 된다.
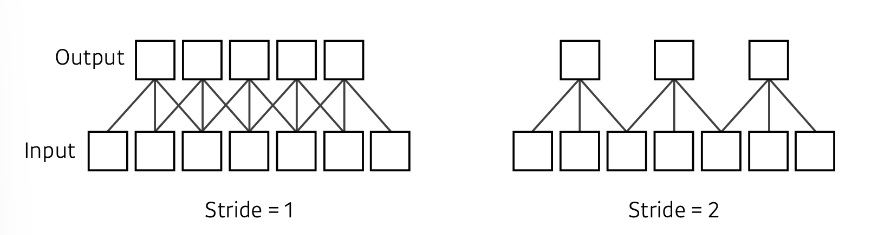
Stride
stride는 보폭으로 생각하면 쉬운데 필터를 적용할 때에 몇 픽셀씩 옮기는지를 의미한다.
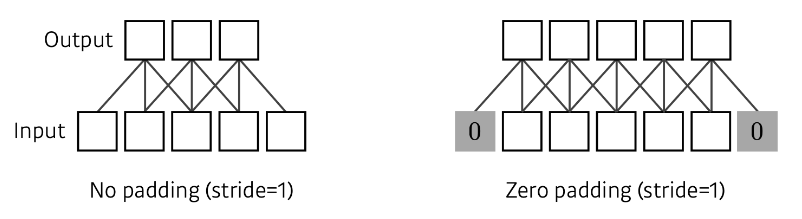
Padding
이미지에 3x3 필터를 적용하면 원래 이미지에 비해 축소된다. boundary 정보가 버려지기 때문이다. 그래서 Padding을 통해 가장자리에도 필터를 적용해서 이미지의 가장자리에 0같은 값으로 채우는 것을 말한다.
Convolution Arithmetic
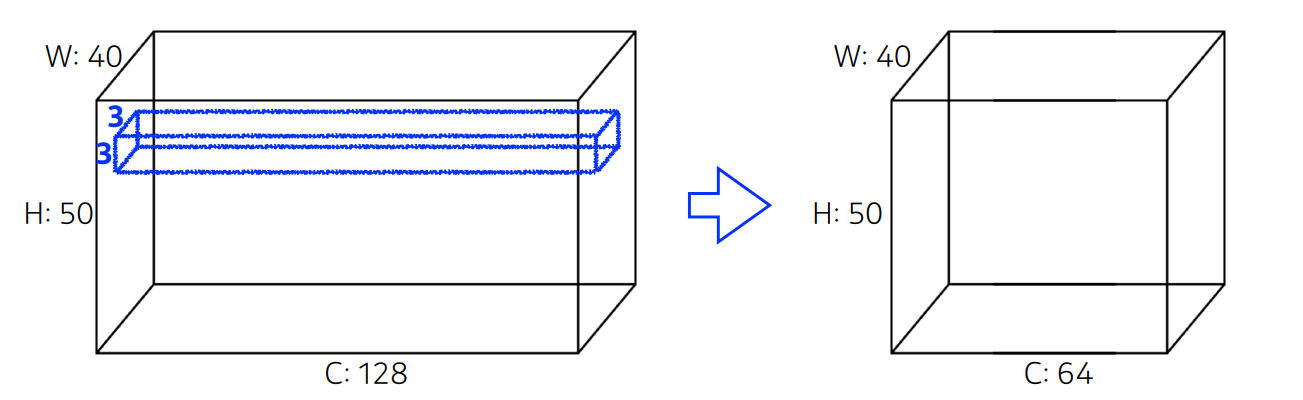
H : 세로의 길이
W: 가로의 길이
C : 채널 수 보통의 경우 R,G,B
파란 박스는 필터를 뜻하고 큰 상자와 파란 상자의 채널 수는 일치해야 한다. 필터의 파라미터 수를 계산하면 3x3x128이 된다.
출력의 채널 수가 64이므로 필터 하나당 채널이 1인 feature map을 만들기 때문에 전체 파라미터 수는 3x3x128x64가 된다.
1x1 Convolution
1x1 크기를 가지는 Convolution Filter를 사용한 Convolution Layer이다. 크게 3가지의 장점을 꼽을 수 있다.
Channel 수 조절
연산량 감소
비선형성
채널 수 조절
1x1 Convolution의 경우 채널 수를 조절할 수가 있다. 1x1 연산을 할 때에 필요한 필터는 1x1x#channelx#filter가 된다. 여기서 #channel은 입력단의 channel 수와 동일해야하고 #filter는 원하는 출력단의 channel 수로지정해야 한다.
연산량 감소
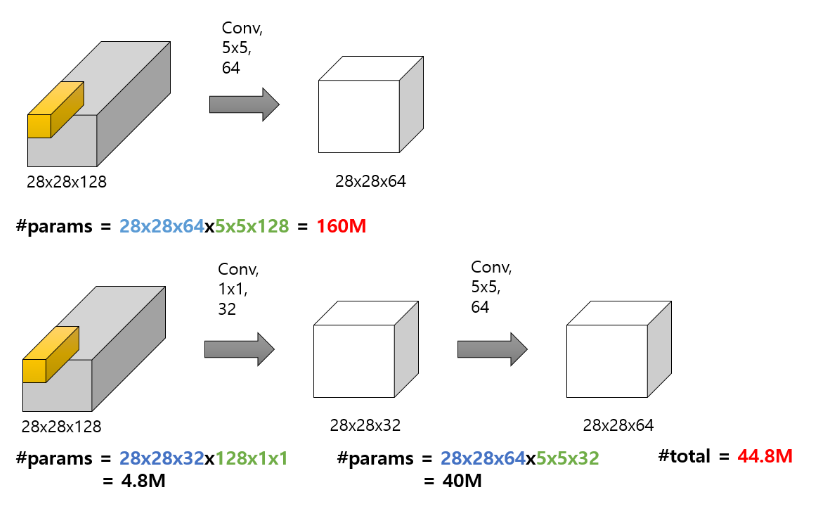
Channel 수 조절은 직접적으로 계산량 감소로 이어지게 된다. 빨간 글씨는 전체 파라미터의 개수이다. 파란글씨는 Convolution을 거치고 난 뒤의 결과값에서 사용되는 파라미터의 수이다. 초록 글씨는 Convolution 과정에서 Filter가 가지는 파라미터의 수이다.
비선형
ReLU 활성화 함수를 지속적으로 사용하여 모델의 비선형성을 증가시켜 준다. 비선형성이 증가한다는 것은 복잡한 패턴을 좀더 잘 인식할 수 있다는 의미이다.
AlexNet
ReLU 활성화 함수 사용
GPU 사용
Data Augmentation
Dropout으로 뉴런중 몇 개를 0으로 만듦
Local response normalization
Overlapping polling
ReLU Activation
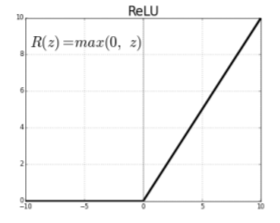
activation 값이 커도 gradient를 그대로 가지고 있다.
gradient descent를 사용해서 optimize 하기 쉽다.
기울기 소실 문제점해결
Vaninshing gradient problem
학습을 진행할 수록 기울기가 소실되는 문제
hidden layer가 많은 MLP에서 layer를 거쳐갈수록 전달되는 오차가 크게 줄어들어 더 이상 학습이 진행되지 않는 현상이 일어난다. -> 기울기 소실 문제
sigmoid 함수의 경우 출력값이 1 아래여서 이러한 문제가 매우 빠르게 일어난다.
이를 해결하기 위해 ReLU함수를 사용한다.
3x3 Convoltuion filter 활용
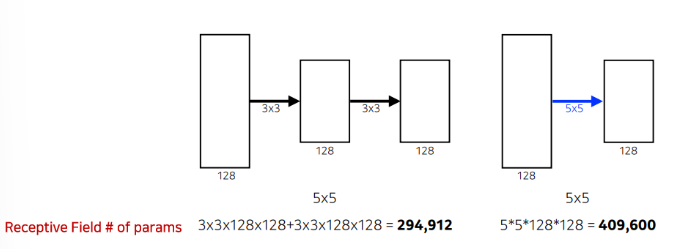
커널의 크기가 커지면서 얻는 이점으로는 하나의 convolution filter를 찍을 때 고려되는 input의 크기가 커진다.
두 방법의 출력의 차원은 같지만 파라미터 수에서 엄청난 차이를 보인다.
왼쪽은 3x3을 2번해서 3x3x2개의 채널이 생성되지만 오른쪽은 5x5를 한번 해서 18:25로 왼쪽이 훨씬 적다.
GoogleNet
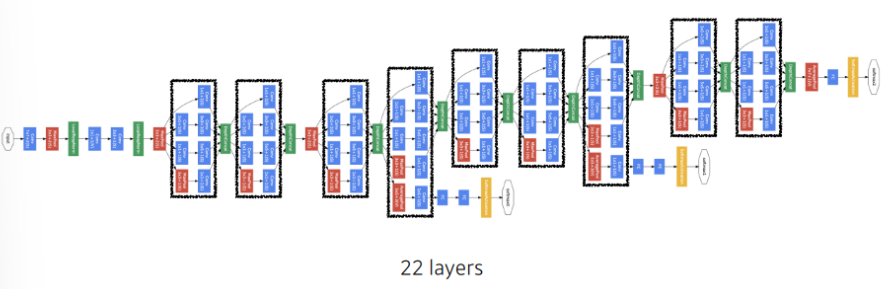
비슷하게 보이는 layer가 반복. 3x3, 5x5 convolution 연산 전에 1x1 convolution을 추가해서 파라미터의 수를 줄인다.
Inception Block
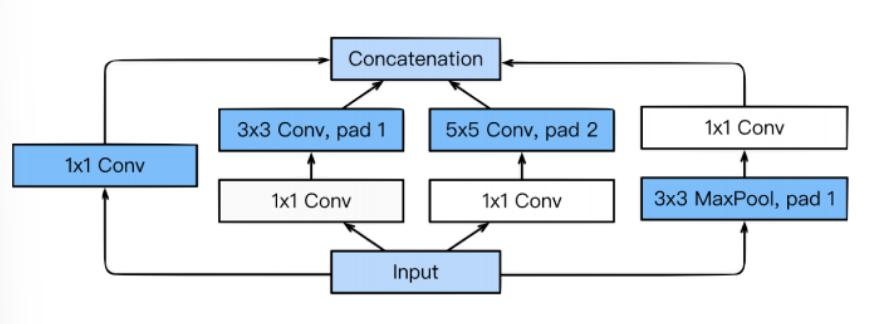
하나의 입력이 들어왔을 때에 여러개로 퍼졌다가 하나로 합쳐지게 된다.
3x3, 5x5 전에 1x1 Convolution이 들어가게 되서 전체적인 네트워크의 파라미터를 줄이게 된다.
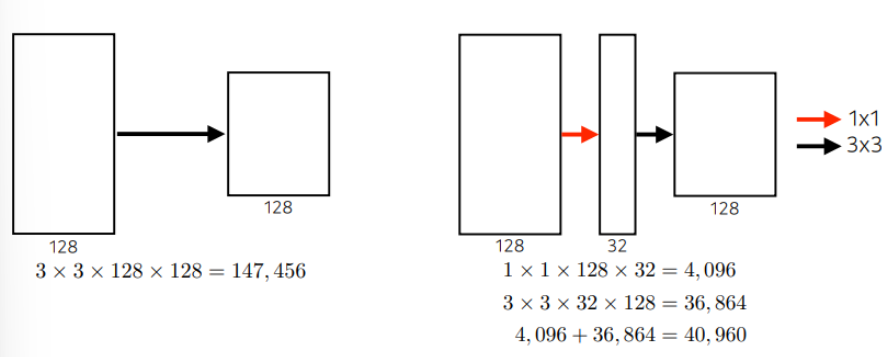
네트워크를 깊게 써도 중간에 1x1 Convolution을 잘 활용하면 파라미터의 숫자를 이런 식으로 줄일 수 있다.
ResNet
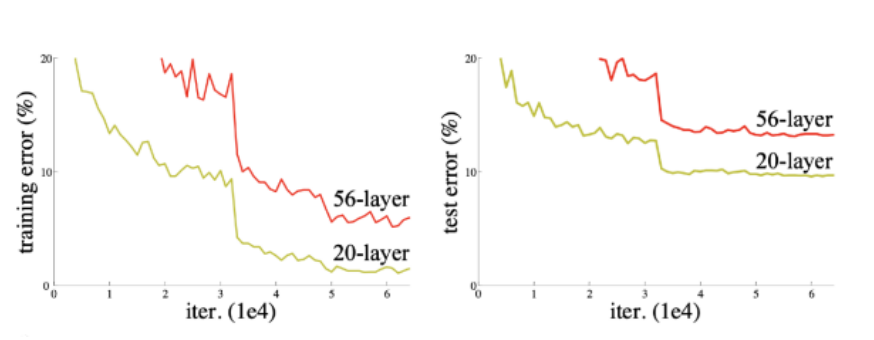
뉴럴 네트워크를 깊게 내려갈 수록 학습하기 어려워진다.
파라미터 수가 많아질 수록 overfitting 가능성이 커진다.
ResNet은 identity map을 추가해서 이를 해결하려고 함.
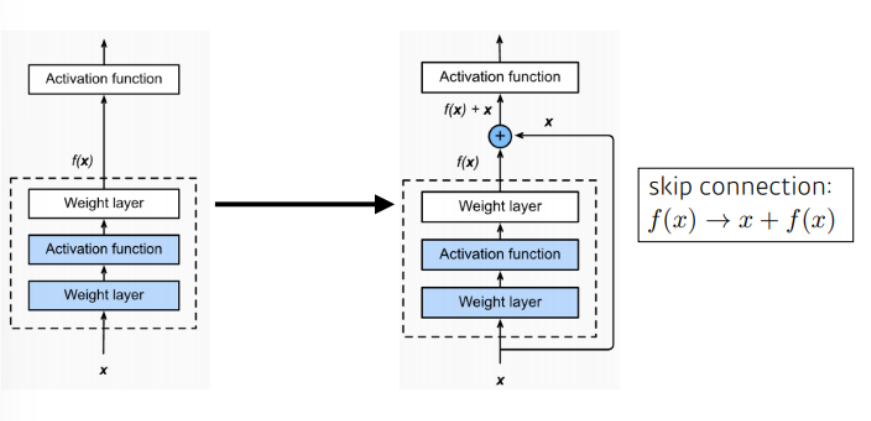
입력을 layer의 출력에 바로 연결시키는 skip connection을 사용한다.
입력을 x 중간 layer를 f(x) 라고하면 출력값 h(x)는 x + f(x)가 된다.
f(x) = h(x) - x 이고 f(x)를 학습한다는 것은 h(x)와 x의 차이를 학습하는 것이다.
h(x) - x 인 나머지를 학습하는 layer이기 때문에 이름이 ResNet이 된 것이다.
기존 모델들이 h(x)를 얻기 위해 학습을 진행했다면 ResNet은 f(x)가 0이 되는 방향으로 학습을 진행하게 된다. 또한 x와 f(x)의 dim 차이가 있다면 그것을 맞추기 위해서 새로운 파라미터 w를 추가하여 학습한다. parameter의 크기가 줄어들 수록 성능이 상승하는 결과가 나온다.
DenseNet
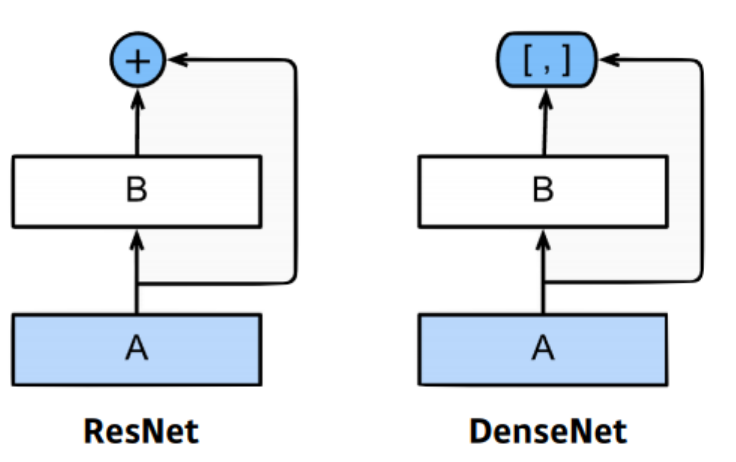
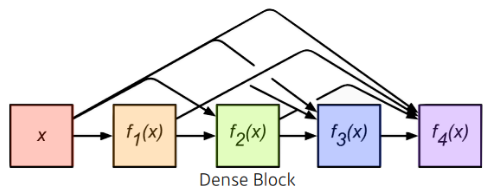
채널이 무한정으로 커지는 것을 막기 위해 나온 방법으로 채널의 concatenation을 진행한다. 채널을 줄이기 위해 1x1 convolution을 추가한다.
DenseBlock
featuremap을 계속 키워서 conv를 기하급수적으로 키운다.
각 layer는 이전 layer들의 feature map을 concatenate한다.
결론적으로 채널의 수가 기하급수적으로 증가한다.
Transition Block
Batch Norm -> 1x1 Conv(feature 사이즈 축소) -> 2x2 AvgPooling
차원축소
위의 두 과정을 반복한다.
VGG는 3x3 block의 반복으로 receptive field를 늘렸다
GoogleNet은 1x1 convolution을 통해서 채널 수를 줄여서 파라미터 수를 감소시켰다.
ResNet은 skip connection을 통해 네트워크를 깊게 쌓을 수 있게 했다.
DenseNet은 concatination을 통해 feature map을 더하는 대신 쌓아서 더 좋은 성능을 냈다.
