마스크 착용 상태 이미지 분류 대회
Exploratory Data Analysis(EDA)

데이터의 분포를 확인해보고 모델을 적용하기 전 방향성을 정하기 위해 수행한다.
from glob import glob
PATH = '../input/data/train/images/*/*'
total_train_images = glob(PATH)
def age_group(x):
return min(2, x // 30)
def process(total_train_images):
new_train_df = pd.DataFrame(columns={"id", "gender", "race", "age", "mask", "img_path", "path"})
total_id, total_gender, total_race, total_age, total_img_path, total_mask, total_folder = [], [], [], [], [], [], []
for i in total_train_images:
split_list = i.split('/')
file_name = split_list[-1]
#print(file_name)
path = split_list[-2]
#print(path)
path_split = path.split('_')
id_ = path_split[0]
#print(id_)
gender = 0 if path_split[1] == 'male' else 1
#print(gender)
race = path_split[2]
#print(race)
age = int(path_split[-1])
#print(age)
if 'normal' in file_name:
mask = 2
elif 'incorrect' in file_name:
mask = 1
else:
mask = 0
total_id.append(id_)
total_gender.append(gender)
total_race.append(race)
total_age.append(age)
total_mask.append(mask)
total_img_path.append(i)
total_folder.append(path)
new_train_df['id'] = total_id
new_train_df['gender'] = total_gender
new_train_df['race'] = total_race
new_train_df['age'] = total_age
new_train_df['mask'] = total_mask
new_train_df['img_path'] = total_img_path
new_train_df['path'] = total_folder
new_train_df['age_group'] = new_train_df['age'].apply(lambda x : age_group(x))
return new_train_df.sort_values(by='id').reset_index(drop=True)
new_train_df = process(total_train_images)
new_train_df.to_csv(OUT_PATH)데이터 labeling을 통해 새로운 csv를 만든다.
데이터 모델 적용을 3가지로 해볼 예정이기 때문에 label을 3개를 적용을 시킨다.
그렇게 만든 csv의 상위 5항목을 출력해보면 다음과 같다.
train = pd.read_csv(OUT_PATH)
train.head()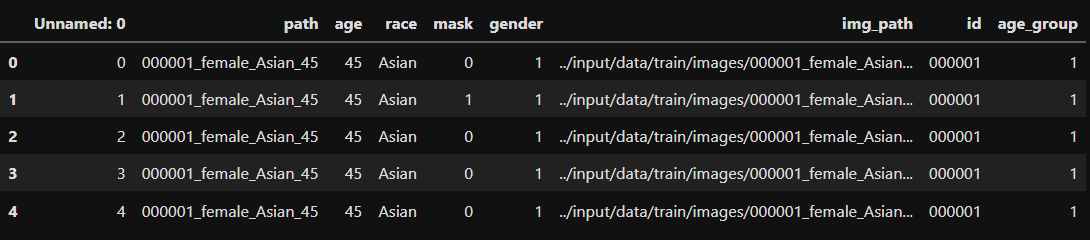
이런식으로 label링된 데이터를 가지고 자료의 분포도를 확인해보면 다음과 같이 데이터가 불균형한 것을 확인할 수 있다.
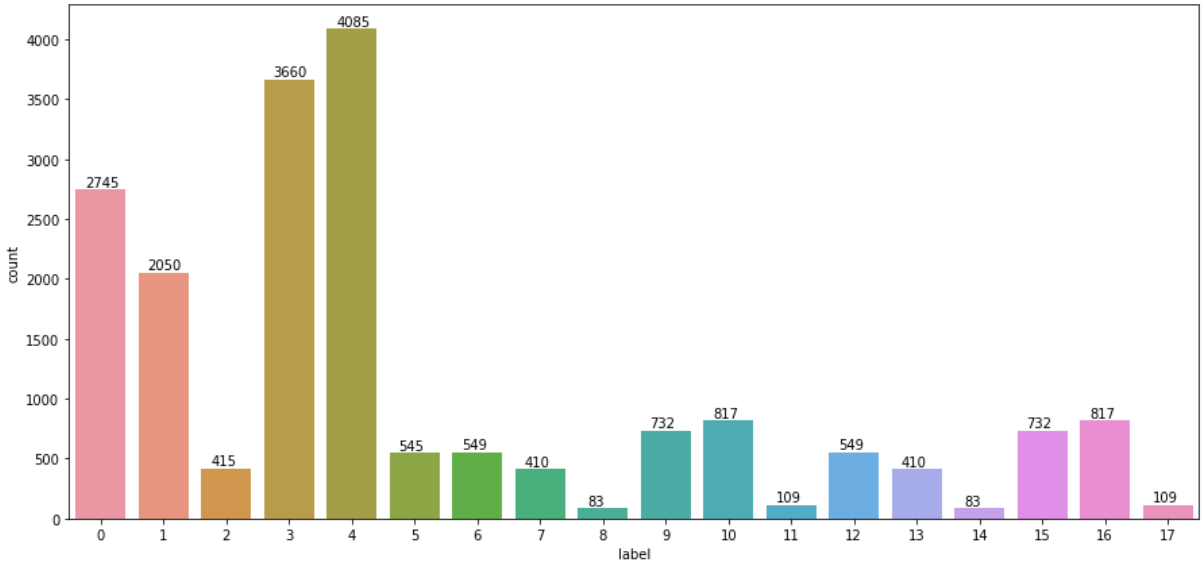
특히 저 8과 11과 14 17에 해당하는 데이터는 개수가 100개남짓이라 train 과정에서 제대로 학습이 안될 우려가 있다.
그렇기 때문에 피어세션을 통해 내려진 결론은 모델을 3가지로 나눠서 생각을 해보면 어떨까 하는 것이다.
성별만 학습시키는 모델
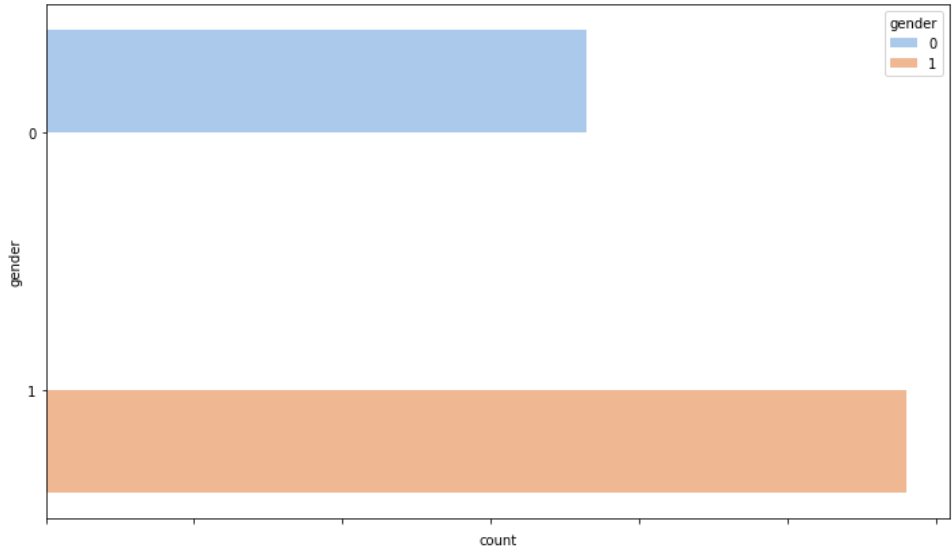
성별만 학습시키는 모델은 이렇게 2가지의 라벨을 가지게 된다.
나이를 학습시키는 모델
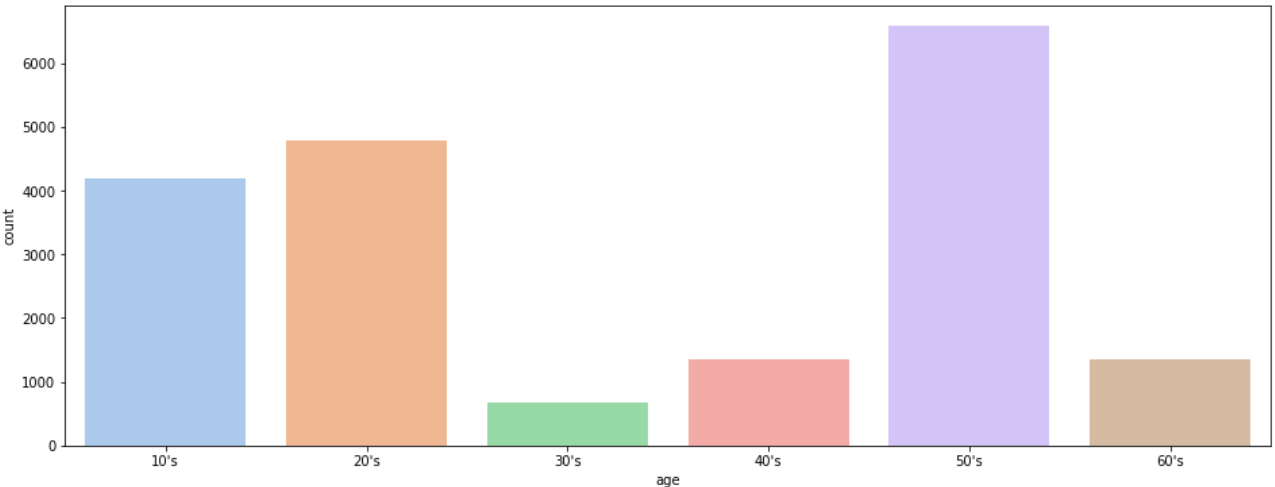
나이는 이렇게 나눠놨지만 결국 30대 미만 30~60, 60 이상인 3가지 라벨을 가지고 학습을 하게 된다.
마스크 착용여부를 학습시키는 모델
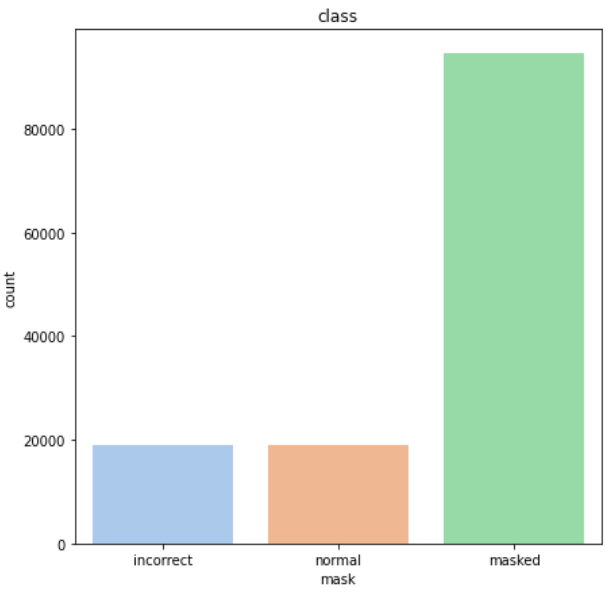
데이터는 한 폴더에 마스크 정상착용 5장, 미착용 1장, 이상하게 착용한 것 1장 해서 7장씩 들어가있다. 그렇기 때문에 3개의 라벨을 가지고 학습을 진행하게 된다.
이런식으로 3개의 모델을 학습시키면 어떨까 하는 의견이 나와서 그쪽으로 해볼까 생각중이다. 우선은 하나의 모델인 CNN으로 구현을 해보는 것을 목표로 진행중이다.
그리고 개인적으로 마스크 착용여부를 학습시킨다면 데이터를
음영으로 구분짓거나 흑백으로 아예 바꿔서 진행시키면 RGB 사진보다 구분짓는것보다 성능이 좋아질 것같은 생각이 들어서 그쪽으로 시도를 해보려고 한다.
