대회 개요
마스크를 착용하는 건 COIVD-19의 확산을 방지하는데 중요한 역할을 합니다. 제공되는 이 데이터셋은 사람이 마스크를 착용하였는지 판별하는 모델을 학습할 수 있게 해줍니다. 모든 데이터셋은 아시아인 남녀로 구성되어 있고 나이는 20대부터 70대까지 다양하게 분포하고 있습니다. 간략한 통계는 다음과 같습니다.전체 사람 명 수 : 4,500
한 사람당 사진의 개수: 7 [마스크 착용 5장, 이상하게 착용(코스크, 턱스크) 1장, 미착용 1장]
이미지 크기: (384, 512)
전체 데이터셋 중에서 60%는 학습 데이터셋으로 활용됩니다.
데이터 분포 확인하기
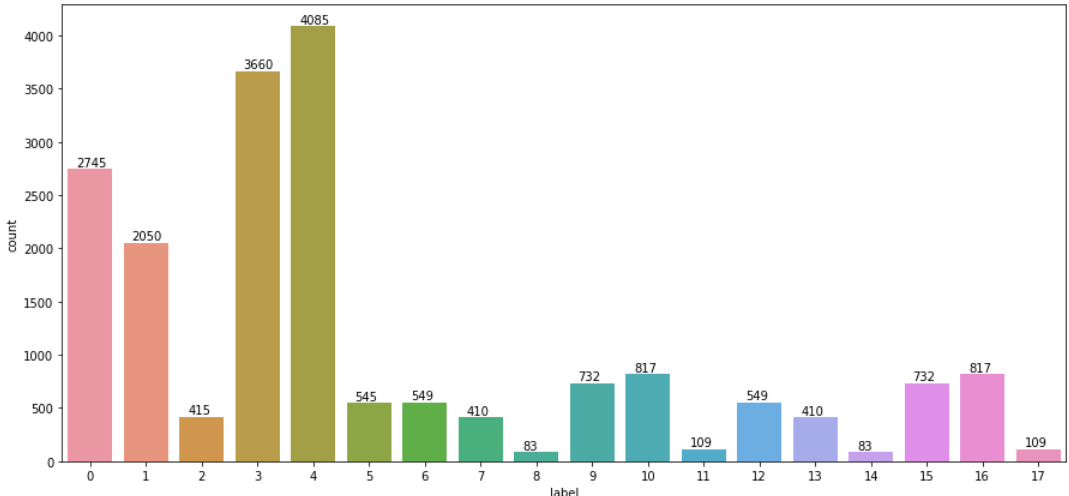
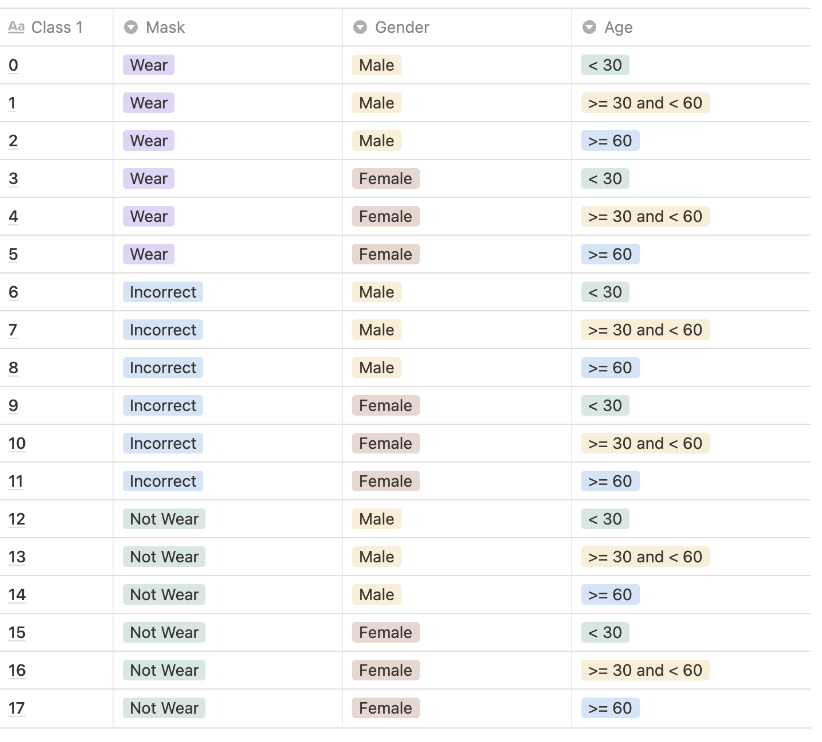
0~17 까지의 클래스의 분포를 확인해 보기 위해 train.csv로부터 성별이 남자면 1 여자면 0을 마스크 착용 여부에 따라 정상착용이면 0 비정상착용이면 1 착용하지 않았으면 2로 두고 나이에 따라 30살미만이면 0 30살이상 60살미만이면 1 60살이상이면 2로 설정했다. 그 후 각각의 가중치를 부여하여 클래스를 전부 0~17까지 총 18개로 분리하였다. 각각의 데이터 분포를 확인해보면 다음과 같다.
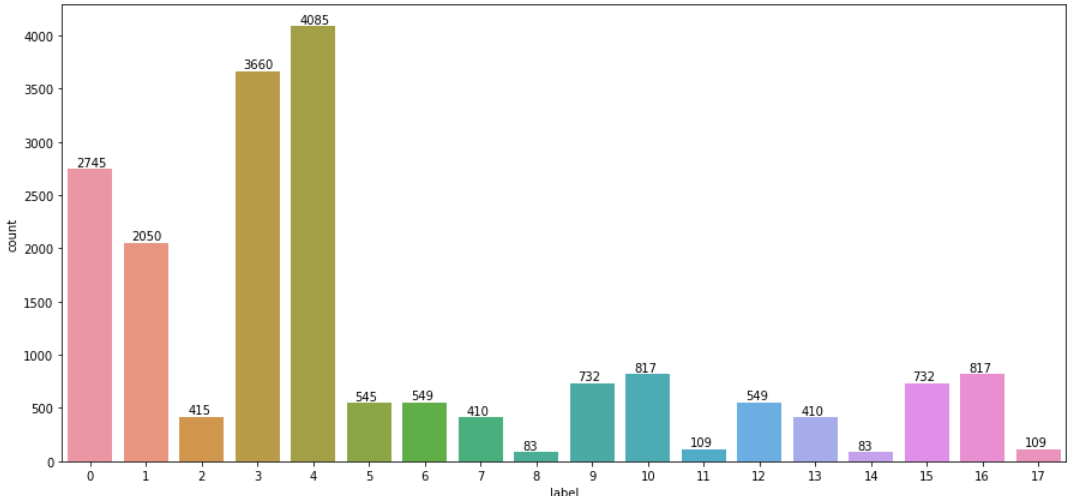
잘 보면 2 8 11 14 17 등의 데이터가 상당히 부족한 것을 알 수 있는데 이들의 공통점은 60대 이상이라는 점이다. 이를 통해 우선 60대 이상의 데이터가 상당히 부족하다는 것을 알 수 있었다.
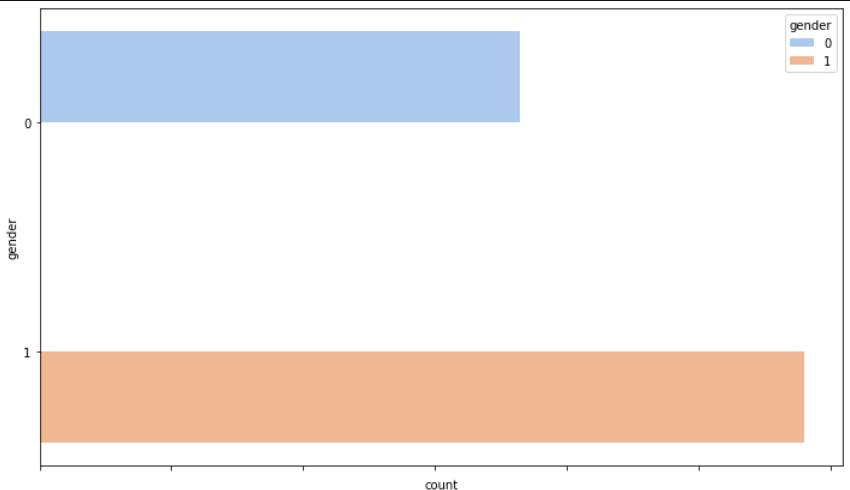
위 그래프는 남 여 성비를 나타낸 그래프로 앞선 클래스간 불균형만큼은 아니지만 데이터 불균형이 존재함을 확인할 수 있다.

다음은 마스크 착용 여부에 따른 데이터 불균형이다. 애초에 이미지 자체를 5:1:1 비율로 해놓았다고 개요에 설명이 되어있었기 때문에 이 부분은 미리 알고 있었다.
결론
학습시키기 전 데이터를 직접 눈으로 확인하면서 어떤 부분에 불균형이 존재하고 이를 해결해 줄 방법으로 어떤 것이 좋을지 생각해보는 시간이었다. 피어세션을 통해 data augmentation을 통해 데이터 양을 늘려본다거나 smooth labeling 등을 적용해 보는 방법을 생각해 보았다.
