
Data Augmentation
Data Augmentation은 갖고 있는 데이터셋을 여러 방법으로 Augment해서 그 규모를 키울 수 있는 방법이다. 기본적으로 아무 처리를 해주지 않았을 때의 성능은 다음과 같았다.

그 다음 성능 향상을 위해 우선적으로 선택했던 방법은 기본적인 Transform에 있는 Rotate, Togray, HorizontalFlip 등이었다. 그러나 거의 비슷한 성능이 나와서 이것만은로는 안되겠다 싶어서 더 다양한 기능을 위해 Albumentation을 사용했다.
수 많은 Augmentation 기법들 중 사용했던 목록은 다음과 같다.
Togray
CLAHE
RandomBrightness
Rotate
GaussianBlur
이것을을 사용하여 얻은 결과는 다음과 같았다.

하지만 한 동안 이 벽에 막혀서 더 이상의 성능향상은 이루지 못하였다. 삽질을 하는 동안 내가 도전했던 결과물들은 다음과 같다.
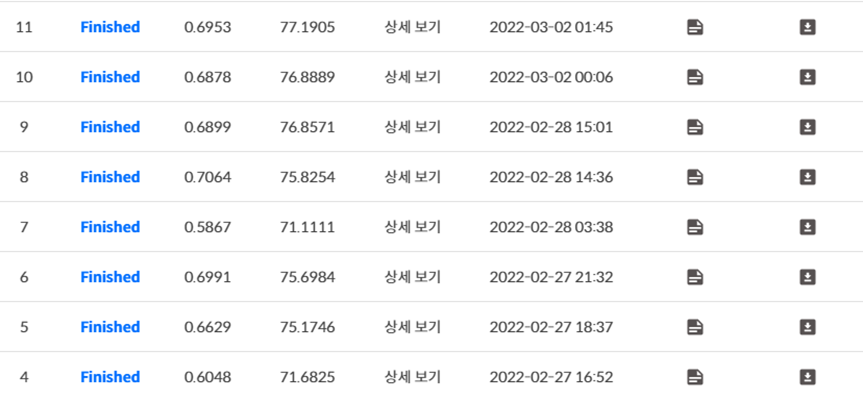
그리고 데이터 불균형 문제를 해결하기위해 맨 처음에 K-fold 기법을 사용하여 성능 향상을 시도했지만 결과는 위에 나와있는 대로 처참했다. 무려 학습시간 13시간을 투자했지만 성능이 나오지 않아서 상당히 힘들었던 시기이다.

그리고 K-fold보다 데이터 불균형 해소에 도움이 되는 stratified K-fold 기법이 있다고 해서 사용해보려고 시도했지만 그것보다 간편하게 데이터 불균형을 해소할 수 있는 Imbalanced Sampler를 발견하게 되었다. ImbalancedSampler에 대한 설명은 다음과 같이 그림으로 나타내볼 수 있다.
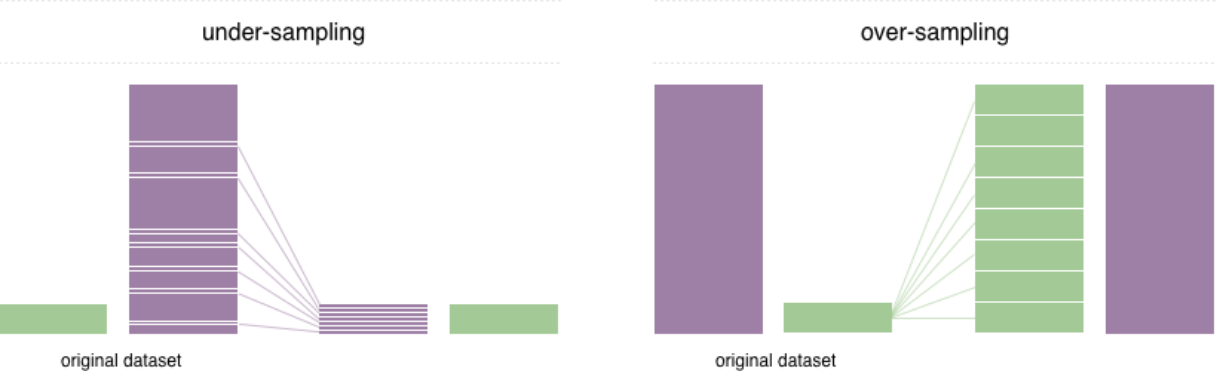
데이터 불균형을 해소하는 방법에는 크게 OverSampling과 UnderSampling이 있다.
그 두가지의 차이점은 Oversampling은 데이터가 적은 것에서 많은 비율로 데이터를 뽑는 것이고 UnderSampling은 데이터가 많은 곳에서 적게 뽑는 것이다.
그리고 ImbalancedSampler는 그 두 가지 기법을 랜덤으로 섞어서 사용하는 것으로 생각할 수 있다. 이 기법과 Label Smoothing을 사용하여 One-Hot Encoding 방식이 아니게끔 바꿔주었다. 하지만 이렇게 해도 큰 성능 향상으로 이어지지는 않았다.
그리고 팀원분이 공유해주신 Augmentation을 새롭게 적용해 보았다. 이 때 적용한 Augmentation들은 다음과 같다.
Togray
CoarseDropout
ChannelDropout
MultiplicativeNoise
HorizontalFlip
CenterCrop
여기서 가장 유효한 효과를 주지 않았을까 하는 방법은 CenterCrop이다. 마스크 착용 여부는 얼굴만 보고 판단을 하기 때문에 방해가 되는 요소들을 최대한 없앰으로써 모델이 좀 더 얼굴에 집중을 할 수 있게 해 주었다고 생각이 든다. 앞서 말한 데이터 불균형 해소 기법들과 새로운 Augmentation을 적용한 결과 다음과 같은 성능 향상으로 이어졌다.

그리고 여기에 train dataset에만 적용하던 augmentation을 test dataset에도 적용해보자는 원리인 TTA를 적용해 보았다. tta를 적용하고 나니 성능이 조금 더 올랐다. 하지만 완전히 다 tta를 적용하는 것이 아닌 0.5 tta와 0.5 tta 적용하지 않은 것을 섞어주었다. 그렇게 하였더니 다음과 같은 결과로 이어졌다.

그리고 시도한 마지막 방법으로 60세 이상의 데이터가 부족한 점을 보완하고자 57세부터 60세로 올려서 생각을 하는 방향으로 dataframe에서 수정을 해 주었다. 그렇게 해 주었더니 정확도는 조금 떨어졌지만 f1-score가 약간 올랐다.

성능평가는 f1 지표로 이뤄지기 때문에 마지막 모델을 이것으로 정했고 팀원분이 ensemble 시킬 모델로 이것이 정해졌다.
팀원분께서 사용하신 ensemble 모델은 Resnet과 Mixup을 적용한 Resnet 그리고 CoatNet을 사용하여 총 4개의 모델을 Ensemble 시켜보았다. Mixup과 Ensemble의 결과가 참 좋았던 것 같다. 마지막에 그것으로 인해 성능 향상이 엄청나게 올라갔다.

최종 순위는 11위로 당초 목표했던 20등 언저리를 하는 것보다 예상외로 높게 나왔다.
회고
느낀게 많은 프로젝트였다. 내가 너무 할 줄 아는게 없다고 느껴졌고 많이 무기력해졌던 프로젝트였다. 나는 남의것을 갖고와서 쓰기 바쁜데 다른 캠퍼분들은 정말 자신만의 코드들을 작성하고 본인만의 방식들로 프로젝트를 진행하시는거보고 많은 것을 느낄 수 있었다. 더 열심히 알아보고 더 열심히 연구하고 더 열심히 복습해야겠다는 생각이 들었다. 그리고 팀원분들이 없었다면 마지막의 좋은 결과는 절대 없었다고 확신할 수 있을 만큼 팀원분들과의 협력이 절대적으로 필요하다고 느꼈다. 다만 아쉬웠던 점은 git 이나 notion등을 활용하여 팀별 Task를 해결해나가는 과정을 따로 기록하거나 하지는 않았기 때문에 그 부분이 조금 아쉽다. 다음 프로젝트부터는 제대로 된 협업을 할 수 있도록 내가 좀 더 공부하고 협업에 익숙해지는 습관을 들여야 할 것 같다.
