CV
AI란 사람의 지능을 컴퓨터 시스템으로 구현하는 것이다. 여기서 지능이라함은 인지능력, 지각능력을 예로 들 수 있다. 그 중에서 가장 중요한것은 visualization, 즉 시각능력인데 우리가 어떤 것을 인지할 때에 시각능력에 75%나 의존하기 때문에 시각능력이 가장 중요하다고 볼 수 있다.
사람이 시각을 통해 어떤 장면을 인식하면 뇌에서 그것에 대해 파악하고 인지하게 된다. 마찬가지로 컴퓨터는 카메라를 통해 장면을 인식하고 GPU를 통해 어떤 사물인지 어떤 상황인지 판단하고 정보를 표현하게 된다.
머신러닝의 경우 다음과 같은 과정을 통해 출력값을 도출하게 된다.
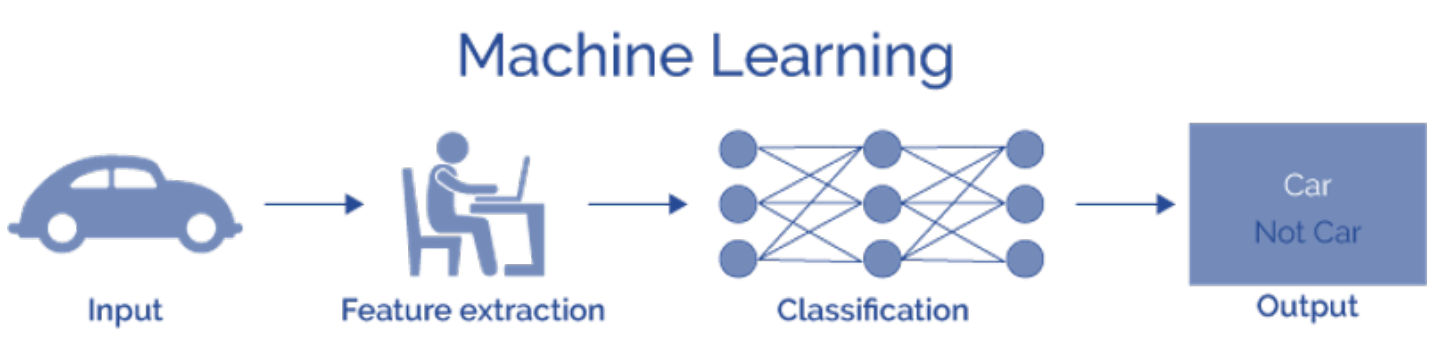
딥러닝의 경우 다음과 같은 과정을 통해 출력값을 도출하게 된다.

Image Classification
이미지 분류는 기본적으로 이미지가 입력으로 들어오면 Classifier를 통해 Class를 알려주는 형태의 Task이다. 세상 모든 데이터를 가지고 있다면 Search Engine을 통해 찾을 수 있지만 시간복잡도 공간복잡도 면에서 불가능하다. 그렇기 때문이 이런 방대한 데이터를 압축해서 Neural Network에 넣는 것이다.
가장 간단한 모델인 FCN의 구조는 다음과 같다.
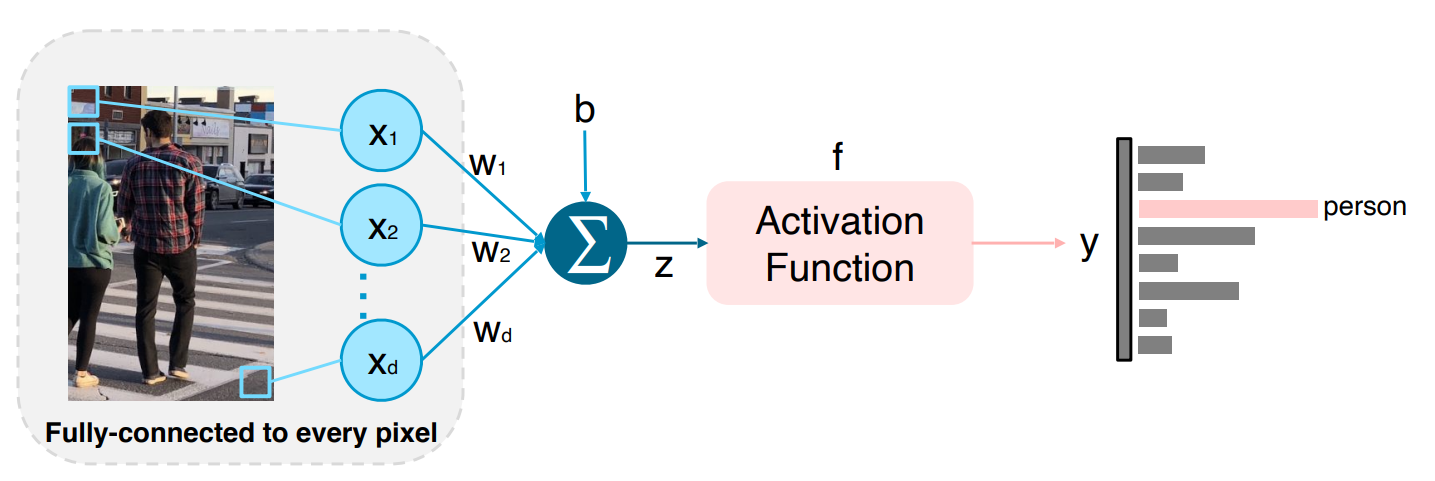
모든 Pixel을 서로 다른 가중치로 weighted sum해주는 방식이다. 하지만 이 방법은 문제가 있는데 만약 일부가 잘려있는 사진이 input으로 들어오면 그것을 특정 사물로 인식하지 못할 수 있다. 그렇기 때문에 FCN보다는 Locally Connected Neural Net을 사용한다. LCNN을 사용하면 파라미터의 수도 줄고 지역적인 부분에서 학습을 할 수 있다.
이런 CNN 모델들은 많은 CV Task들의 backbone으로 사용된다.
Data Augmentation
우리가 찍는 대부분의 사진은 bias를 가지고 있다. 그리고 현실의 데이터를 재현하는데에 사용되는 방법이 바로 Data Augmentation이다. 어두운 사진이라던지 살짝 돌아가있는 사진이라던지가 그런 예에 해당한다. 학습데이터와 실제 데이터 사이의 gap을 줄이기 위한 기법이다.
대표적으로 Crop,Brightness adjustment, Rotate, Flip, Affine Transformation, Cutmix 등이 있다.
Leveraging pre-trained information
지도학습은 항상 많은 양과 좋은 질의 데이터셋이 필요한데 이 조건들이 만족되는것은 상당히 까다롭다. 그렇기 때문에 Transfer learning 을 통해 이미 학습한 모델에 적은 데이터셋을 학습시키는 방법을 사용한다. Transfer Learning에도 다양한 방법이 있다.
첫 번째로 주어진 데이터셋에서 Conv Layer는 weight를 학습시키지 않고 Fully Connected Layer만 원하는 class의 dimension으로 바꿔서 학습시키는 방법이다.
두 번째로 전체 모델을 Fine Tuning 하는 방법이다. 미리 주어진 학습된 데이터셋에서 Conv Layer는 엄청 작은 Learning Rate를 적용하고 Fully Connected Layer는 큰 Learning Rate를 적용하는 방법으로 이것이 첫번째 방법보다 좋은 방법이다.
Knowledge distillation
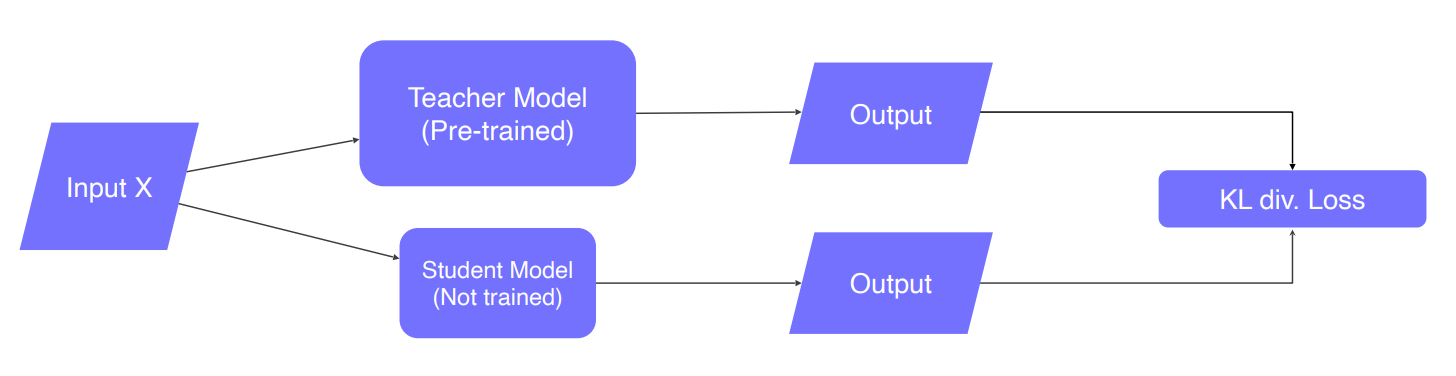
기본적으로 Teacher는 이미 학습된 모델을 활용하여 Student Model에 대해서만 학습하는 방법이다. 이때 Student 모델이 Teacher모델보다 작은 모델을 사용한다. Teacher가 Student에게 문제르 내고 학습이 잘 된 Teacher는 정답을 말한다. Student는 아무거나 답하게 되는데 이 후에 Distillation Loss에 의해서 답을 학습하게 된다. Distillation Loss는 각각의 softmax에 의해 만들어진 distribution을 비교하는 과정이다. 이 때의 softmax는 T로 나눠준 식으로 hard label처럼 0 또는 1이 아니라 0.14,0.86 같이 조금 soft 한 값으로 내준다.
Distillation Loss
- KLdiv(Soft label, Soft prediction) : 2개의 distribution이 있을 때 그 distribution의 차이를 재는 방법
- Loss : 2개의 prediction의 차이를 계산
Student Loss
- CrossEntropy(Hard label, Soft prediction)
- Loss : difference between the student network's inference and true label
- learn the "right answer"
그리고 Student는 T가 1인 softmax를 통해서 실제 정답과 비교하여 Student Loss를 학습한다. 그림으로 나타내면 다음과 같이 나타낼 수 있다.
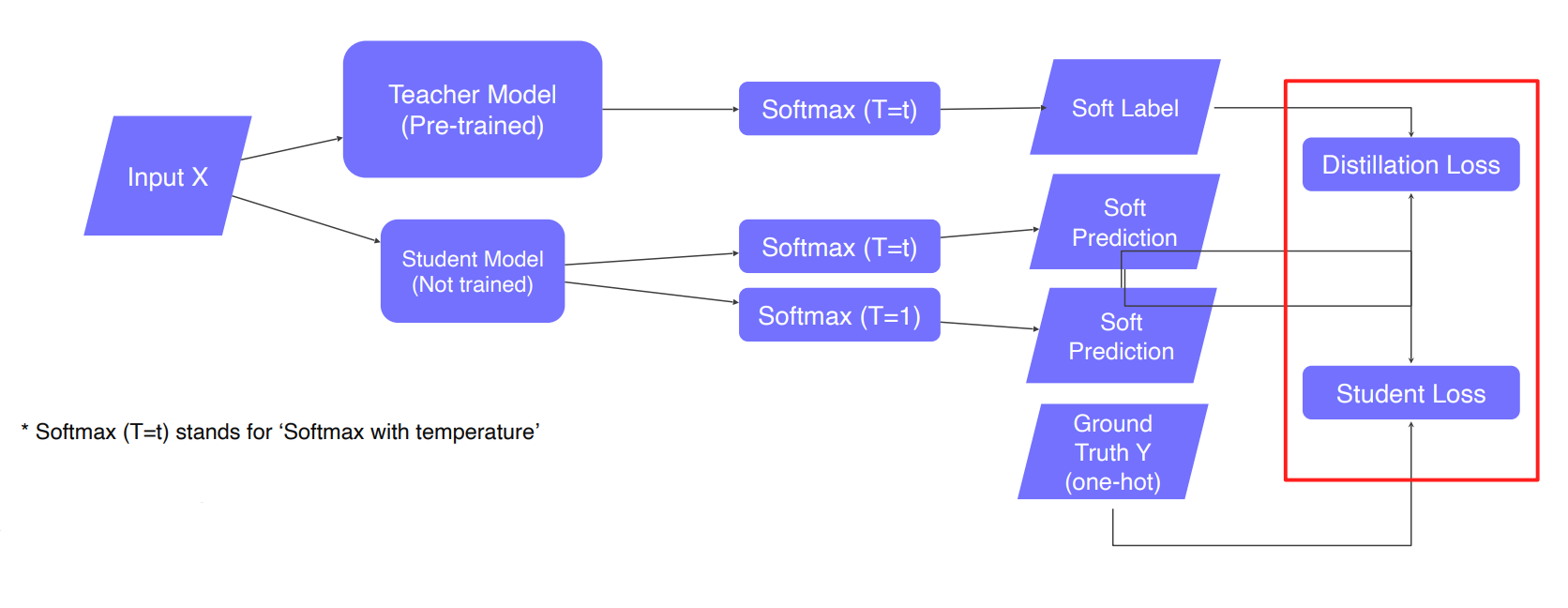
Distillation loss 와 Student loss의 weighted sum을 하는 식으로 학습이 진행된다.
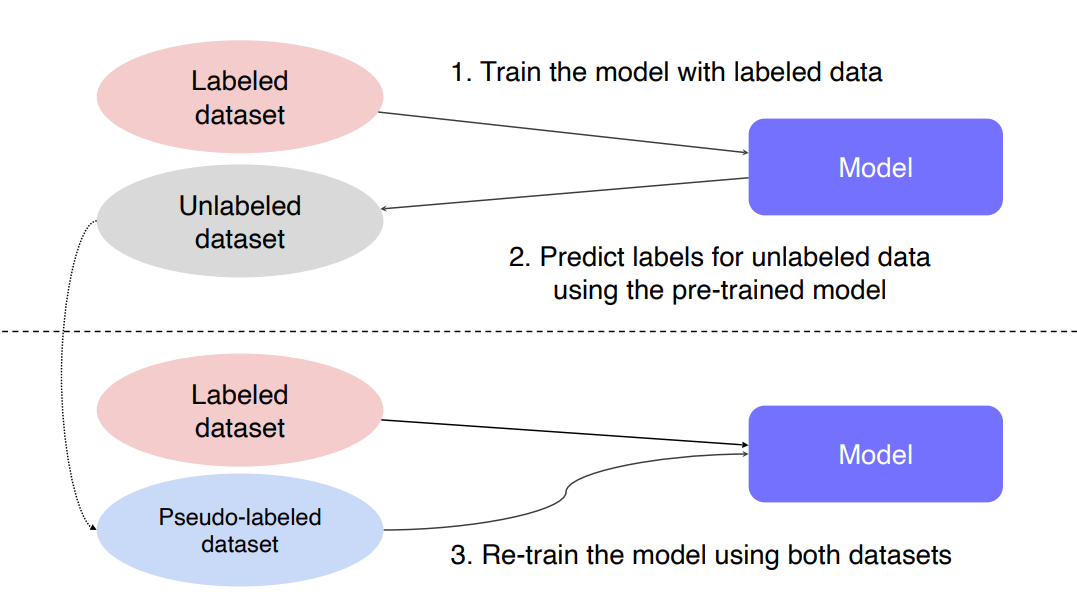
Leveraging unlabeled dataset for training
label된 데이터와 label이 되지 않은 데이터를 활용하기 위한 방법이다.
다음은 Pseudo-labeling학습을 하는 과정이다.