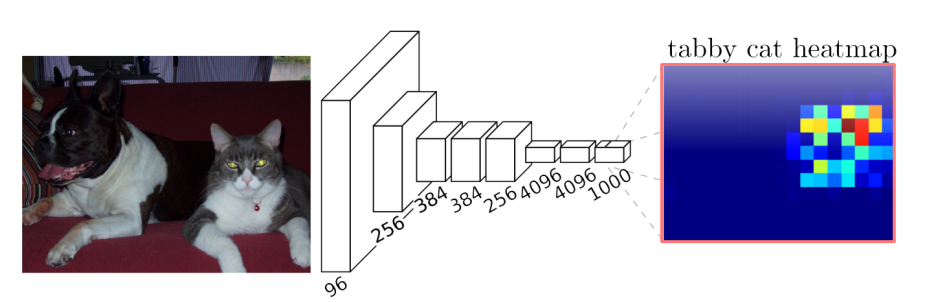
Semantic Segmentation
Semantic Segmentation이란 이미지 분류를 픽셀단위로 하는 것이다. 한 픽셀이 사물,동물,사람 등 어디에 속하는지 판단하는 것이다.
Semantic Segmentation Architectures
FCN
FCN은 기존 CNN 모델을 Segmentation에 적합하게 변형하여 Segmentation 발전의 토대를 이룬 초기 모델이다. FC Layer없이 Convolutional Layer만으로 구성했고 Unsampling을 사용했다. FCN은 Input 이미지를 patch 단위가 아닌 모든 영역을 Receptive Field로 보는 filter를 사용한 CNN이다.
Convolutional의 문제점으로 지적되는 것이 바로 다음 그림과 같은 문제이다.
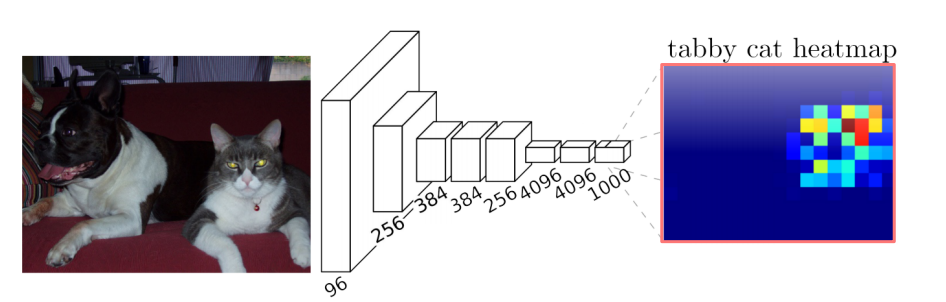
feature map의 크기가 줄고 두꼐가 점점 두꺼워지는 점이다. 이것을 해결하기 위해 upsampling이라는 개념이 나왔다. 이미지를 다시 키우는 것으로 Transposed Convolution과 Upsamplg and Convolution이 있다.
Transposed Convolution은 Convolution과정을 수행하여 Input의 이미지 크기를 얻어내지만 Output은 Input과 크기는 같지만 결과는 다를 수 있다.

하지만 다음과 같이 화질이 별로 좋지 않은 문제가 발생한다. 이러한 문제를 해결하기 위해 Upsample and Convolution이라는 개념이 등장한다.
Upsample and Convolution은 Upsample과 Convolution을 같이 사용하는 것이다. parameter가 없는 간단한 interpolation을 적용 후 parameter가 존재하는 convolution을 적용한다.
Back To FCN
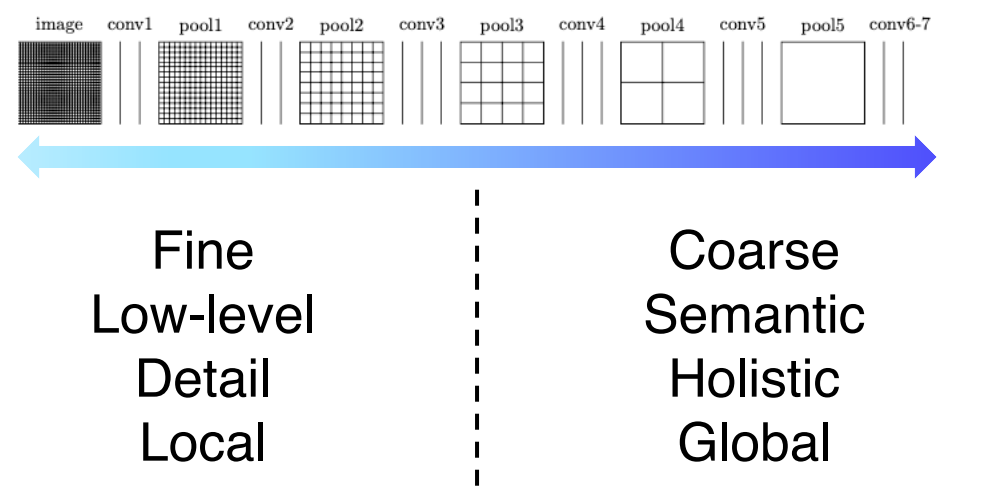
초기에는 receptive field가 굉장히 작아서 민감한 경향이 있다. 높은 layer를 보면 해상도는 낮지만 큰 receptive field를 가지고 전반적으로 전체적인 의미론적 정보를 많이 포함한다. 이런 정보들을 모두 이용하기 위해서 낮은 층의 layer에서 upsampling을 바로 거쳐서 output에 통합한다. FCN-16s, FCN-8s가 대표적인 예시이다.
U-Net
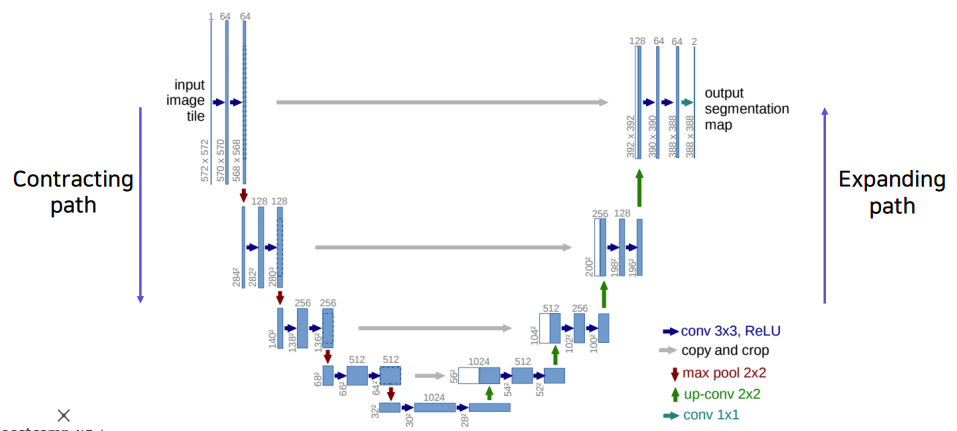
Semantic Segmentation을 목적으로 제안된 end-to-end 방식의 FCN 기반 모델이다.
Contractin Path
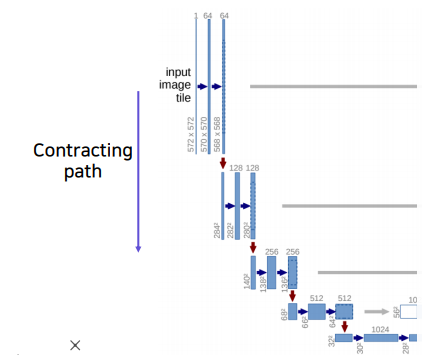
입력된 이미지의 전반적인 context 정보를 얻기 위해 conv 연산과 pooling 연산을 통해 해상도는 낮추고 channel은 늘려서 receptive field의 크기를 키운다.
- ReLU 를 활성화 함수로 사용하고 stride는1, 3x3 conv 연산을 2회 반복한다.
- stride=2, 2x2 max-pooling 연산을 한다.
- feature map의 크기는 , channel 수는 2배씩 늘어난다.
Expanding path
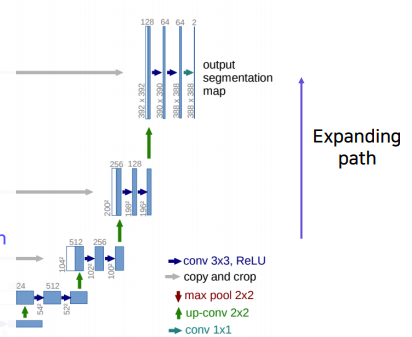
up-sampling을 통해 해상도를 높히면서 channel의 수는 줄이는 방법이다.
- stride=2, 2x2 deconvoluion연산을 통해 up-sampling을 한다. 또한 up-sampling된 feature map은 contracting path의 테두리가 cropped된 feature map과 concatenate 한다.
- ReLU를 활성화 함수로 사용하고 stride=1, 3x3 conv 연산을 2회 반복한다.
- Up-sampling마다 channel 수는 배, feature map은 2배가 된다.
- 마지막 layer에서 1x1 conv 연산을 통해 2개의 채널을 최종 출력한다. 한 픽셀당 가질 수 있는 경우의 수가 2가지이기 때문에 output channel은 2개의 channel이다. 또한 입력이미지보다 작은 출력 이미지를 output으로 내놓는다.
U-Net은 down-sampling과 up-sampling이 빈번하게 일어난다. down-sampling이 된 feature map과 상위층의 up-sampling 된 feature map을 concatenate해야한다. 이 때 홀수 크기의 이미지가 들어오면 안되는데 그 이유는 다음과 같다.
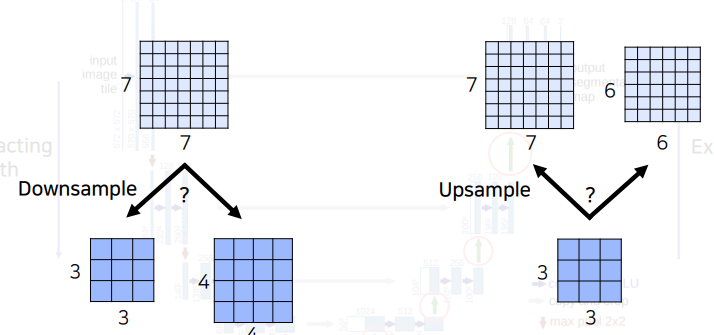
7x7 이미지를 down-sampling할 때 3x3 이미지로 버림이 되기 때문에 이를 다시 up-sampling 하면 초기 7x7 이미지가 아닌 6x6 이미지로 변경이 되게 된다. 그렇기 때문에 무조건 이미지 크기는 짝수가 되도록 설정해야한다.
DeepLab
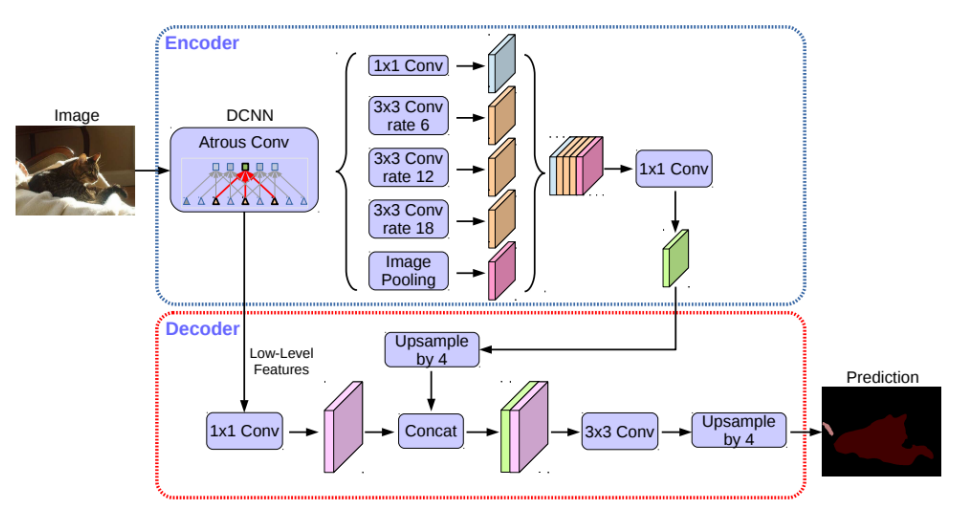
Receptive Field는 하나의 뉴런이 얼마만큼의 정보를 바라봤는지를 나타낸다. Receptive Field를 넓혀서 context를 잘 파악하고자 하는 방법이다.
CRF
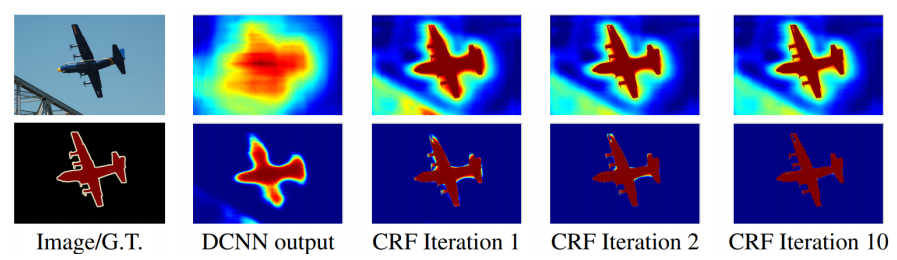
모델의 결과에 후처리를 하는 개념이다. 조금 더 깔끔하고 정교하게 정리해준다.
Dilated Convolution
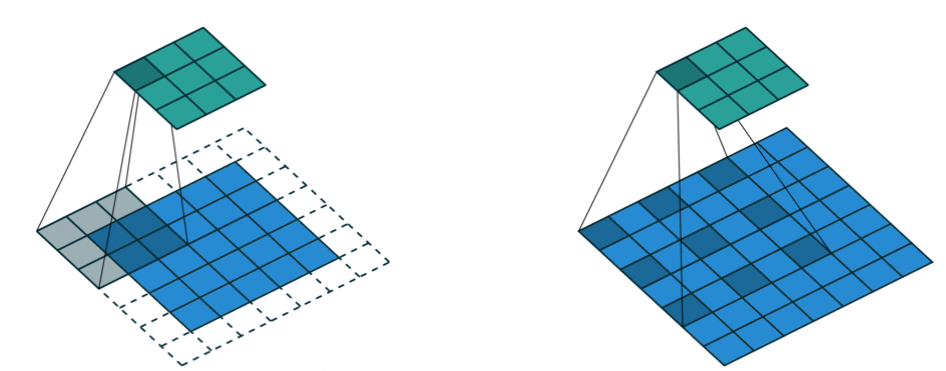
Convolutional layer에 커널사이의 간격을 의미하는 dilation rate를 도입한다. 늘려진 커널 내부에 zero padding을 추가하여 receptive field를 늘린다. 이 때 파라미터의 수를 늘리는 것이 아닌 것이 중요하다. 일반적인 CNN 구조에서 receptive field를 높히기 위해서는 layer를 높히 쌓거나 커널의 크기를 키우거나 pooling 연산을 적용한다. 하지만 이것을 하면 연산량이 증가하거나 기울기 소실 등의 문제가 발생할 수 있다. 대신 Dilated Convolution을 사용하여 파라미터의 수를 증가시키지 않고 receptive field를 늘릴 수 있게 되었다.
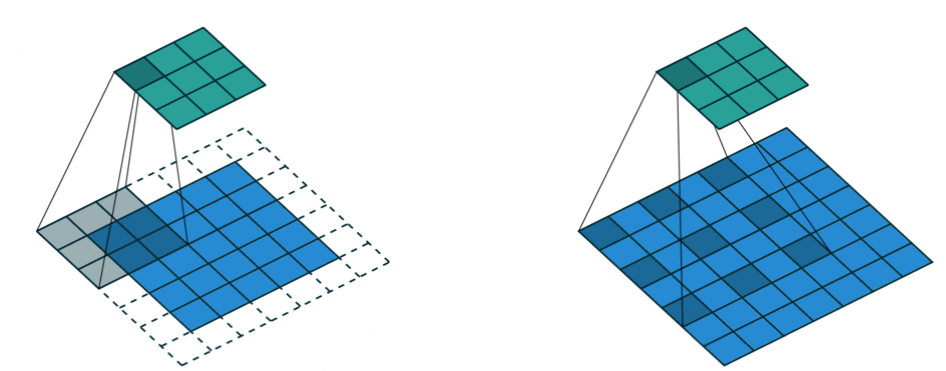
Deepwise Separable Convolution
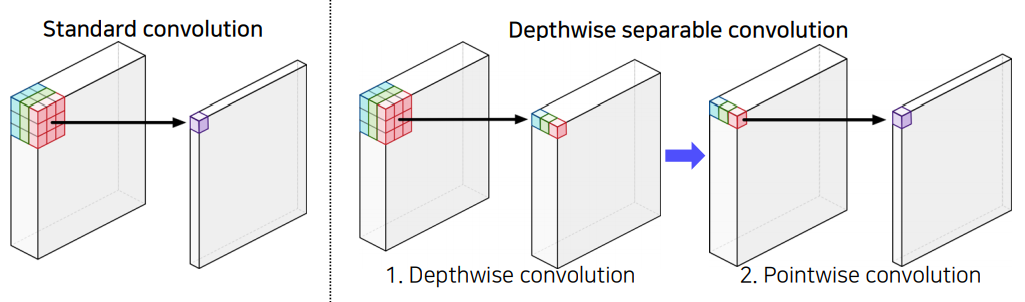
CNN은 많은 convolution연산을 하는데 Deepwise Separable Convolution은 이 연산량을 줄이는 것을 목표로 한다.
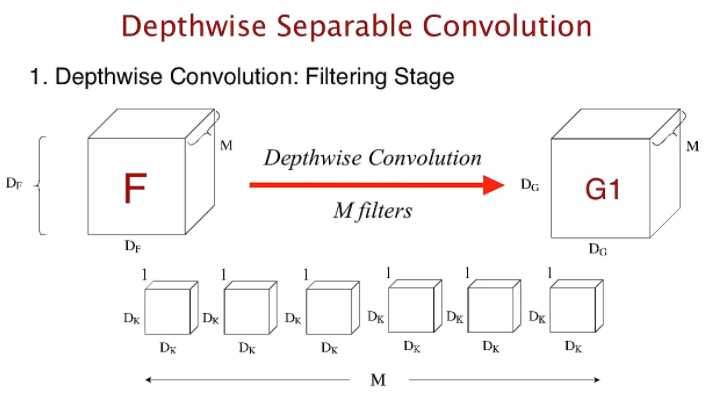
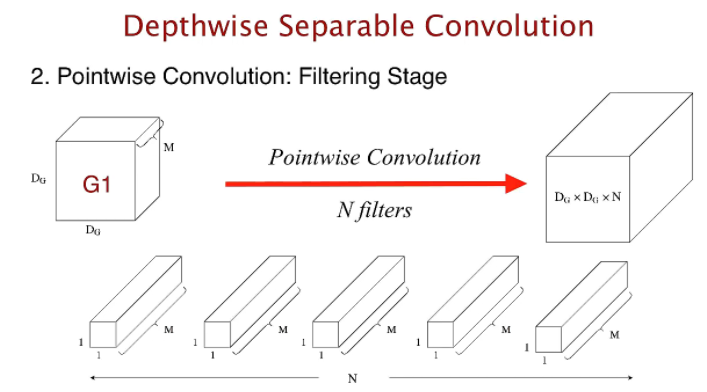
기존의 Convolution 연산은 한 개의 커널이 M채널 전체에 convolution 연산을 하는 반면 deepwise convolution은 한 개의 커널이 한 개의 채널에만 연산을 한다. 그리고 Deepwise convolution 출력에 1x1 convolution 연산을 적용하는 것이 핵심이다. 그렇기 때문에 기존 연산량이
