Object detection
Selective Search
bounding box를 제안하는 방법이다.
- 이미지에서 모든 부분이 1개의 영역에 할당되도록 한다.
- hierarchical grouping algorithm을 사용하여 유사한 영역들을 합친다.
- 통합된 영역을 바탕으로 후보들을 추출한다.

R-CNN
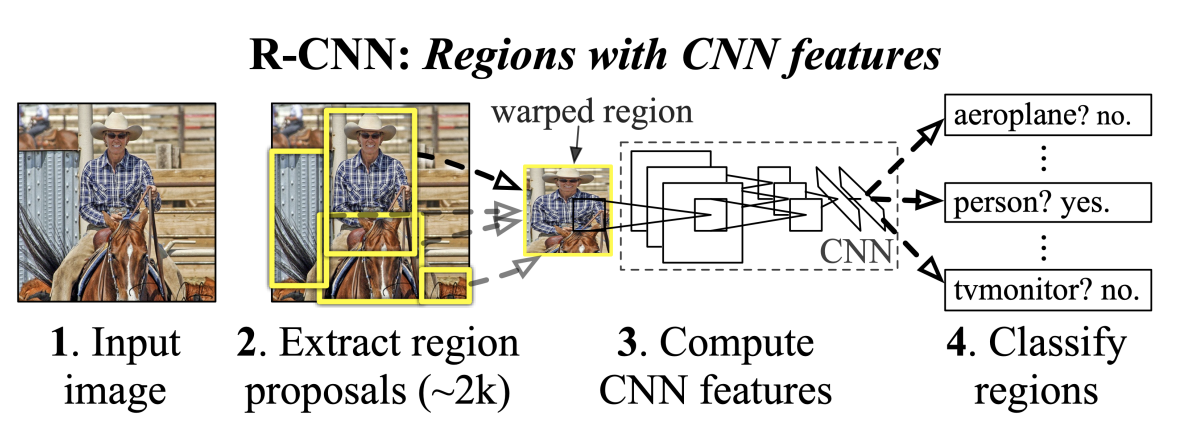
- 딥러닝을 본격적으로 Object detection에 활용했다.
- 약 2000개의 region proposal을 추출하고 각 region을 CNN에 넣어서 분류한다.
- 각각의 region을 CNN에 넣어서 계산하므로 속도가 느리고 학습에 제한이있다.
Fast R-CNN
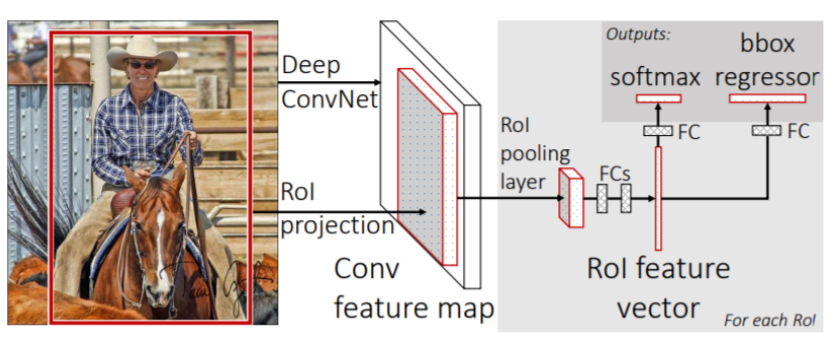
- Image로부터 feature map을 뽑는다.
- RoI Pooling Layer : Region Of Interest로 Region proposal이 제시한 물체의 위치 후보에서 Rol에 해당하는 feature만 추출한다.
- bounding box regressiong, classification을 진행한다.
- R-CNN에 비해 빠르지만 여전히 region proposal을 사용하여 데이터만으로 성능을 올리는 데 한계가 있다.
Faster R-CNN
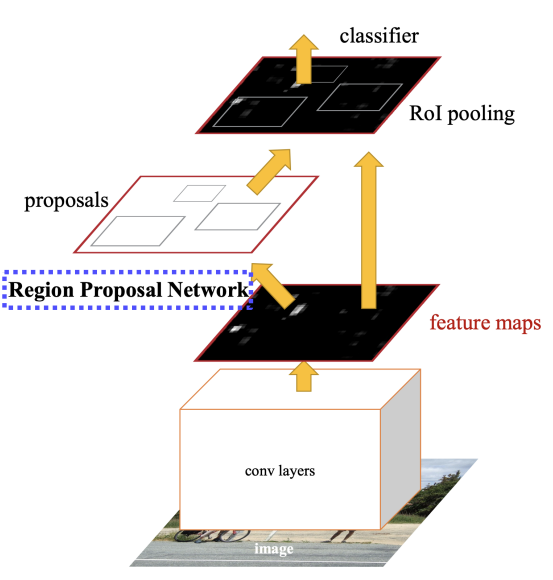
- Region proposal 부분을 Neural network로 대체했다.
- Intersection Over Union : 두 영역의 교집합/합집합으로 IoU가 높으면 두 영역이 잘 겹친 것이다.
- Anchor box 생성 : pre-defined bounding box를 미리 정해놓고 쓰는 것
- Ground Truth와의 IoU를 구해서 0.7보다 크면 positive, 0.3보다 작으면 negative이다.
- Non-Maximum Suppression
요약
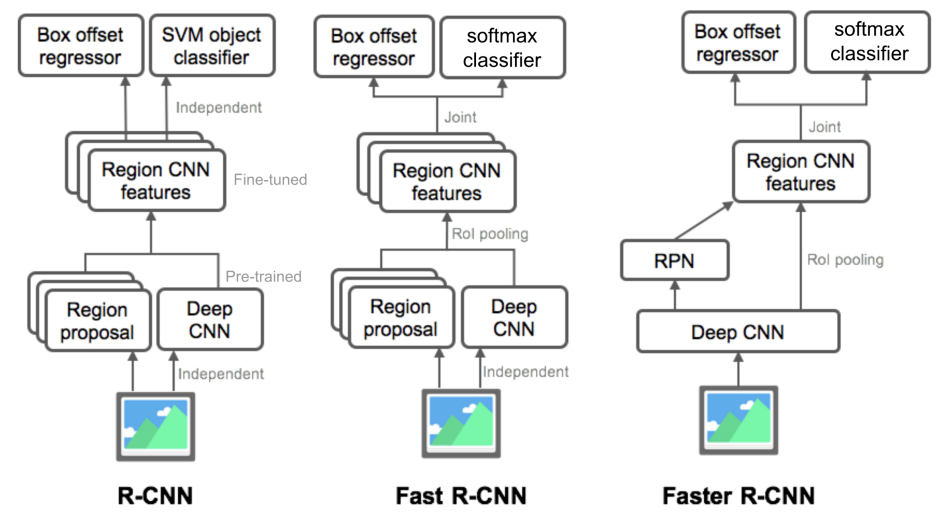
R-CNN에서 Region proposal을 별도의 알고리즘으로 구현하고 CNN부분도 Pre-trained였다. 마지막 부분에 간단한 classifier를 통해서 fine-tuning을 했다.
Fast R-CNN에서 미분가능한 Rol pooling을 통해 하나의 feature로부터 여러 물체를 탐지가능하도록 만들어서 CNN부분을 학습가능하게 만들었다.
Faster R-CNN에서 Region proposal마저도 RPN이라는 네트워크 구조를 만들게 되면서 전체 process가 학습가능하도록 진화했다. 그래서 regression과 classification 부분의 loss를 잰 joint loss가 backpropagation을 통해 RPN과 feature 모두 학습이 되어 target task에 oriented된 feature를 잘 학습할 수 있다.
One-stage detector
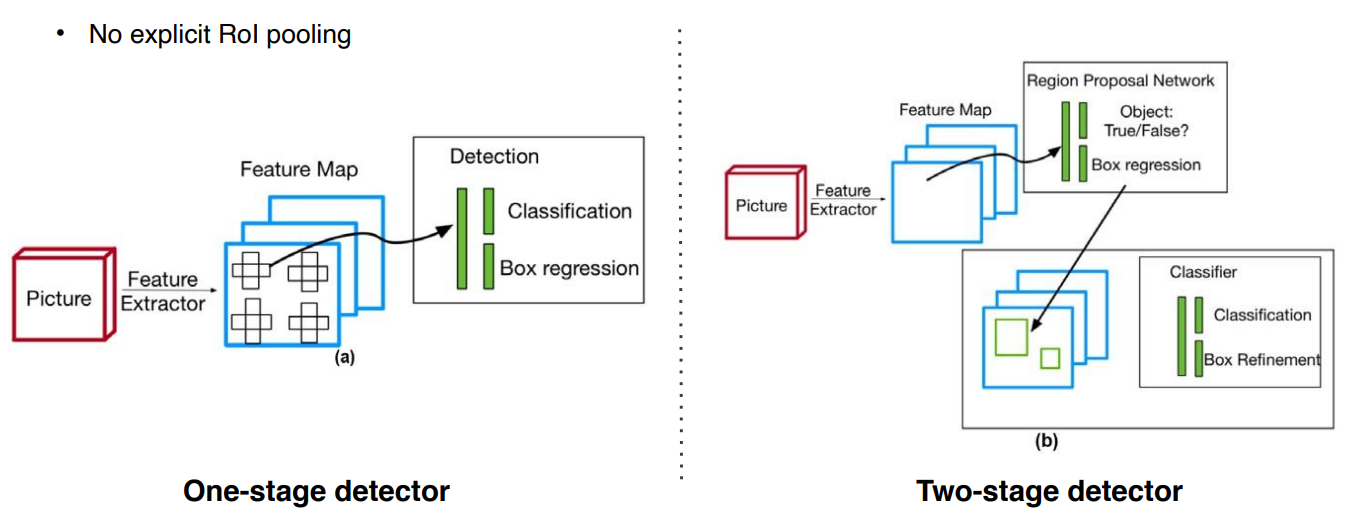
- 정확도보다 속도를 확보하여 real-time detection이 가능하게 하는 것이 목표이다.
- Rol pooling 없이 바로 box regression, classificatin을 진행하므로 속도가 빠르다.
YOLO
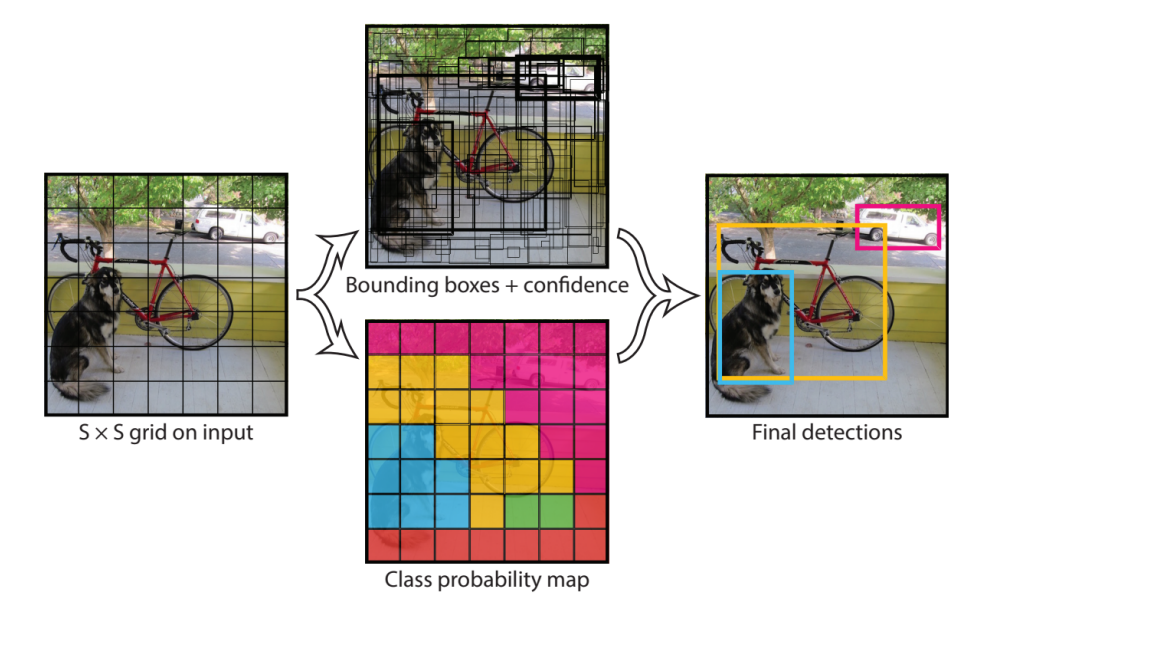
- Image를 SxS grid로 나눠서 bounding box + confidence, Class probability를 동시에 따로 구해 둘을 종합한다.
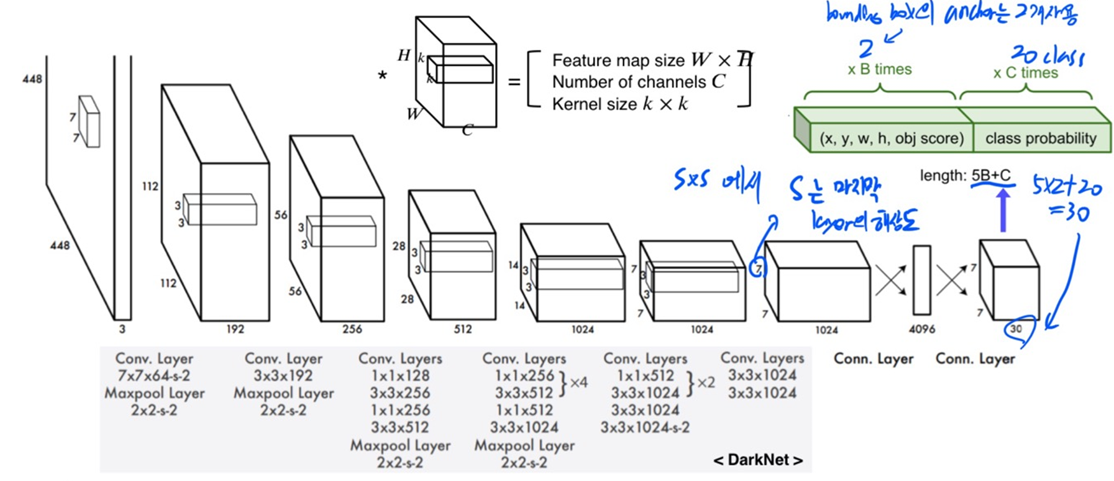
YOLO는 맨 마지막 layer에서 한 번만 prediction을 하기 때문에 localization 정확도는 조금 떨어진다. 이를 보완하기 위해 SSD가 나왔다.
SSD
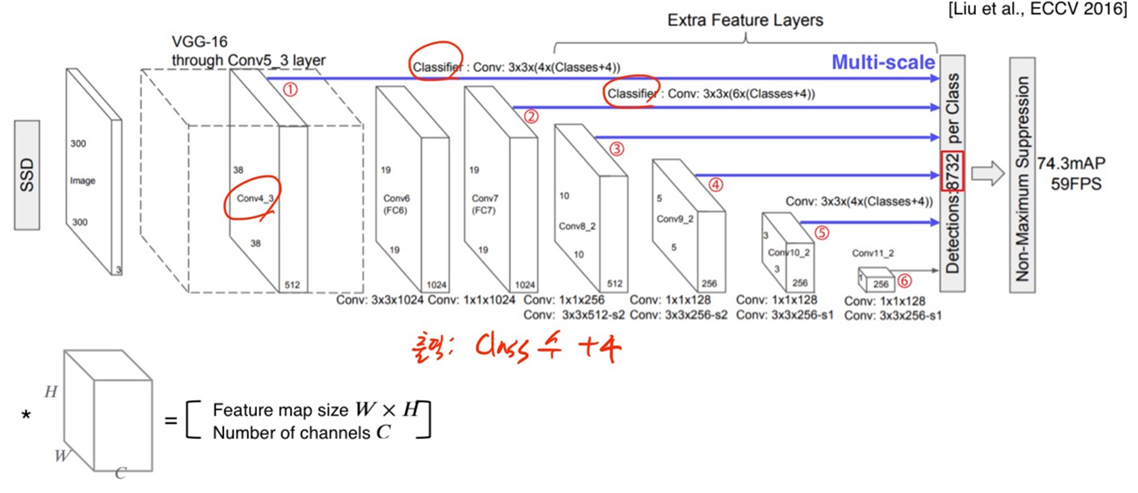
SSD는 multi-scale object를 더 잘 처리하기 위해 중간 feature map을 각 해상도에 적절한 bounding box들을 출력할 수 있도록 multi-scale 구조를 만들었다.
이때 나온 8732는 각 Feature map마다 몇 개의 anchor box가 각 위치만다 존재하는지 계산해서 각 layer마다 그 결과를 다 더한 값이다.
Focal Loss
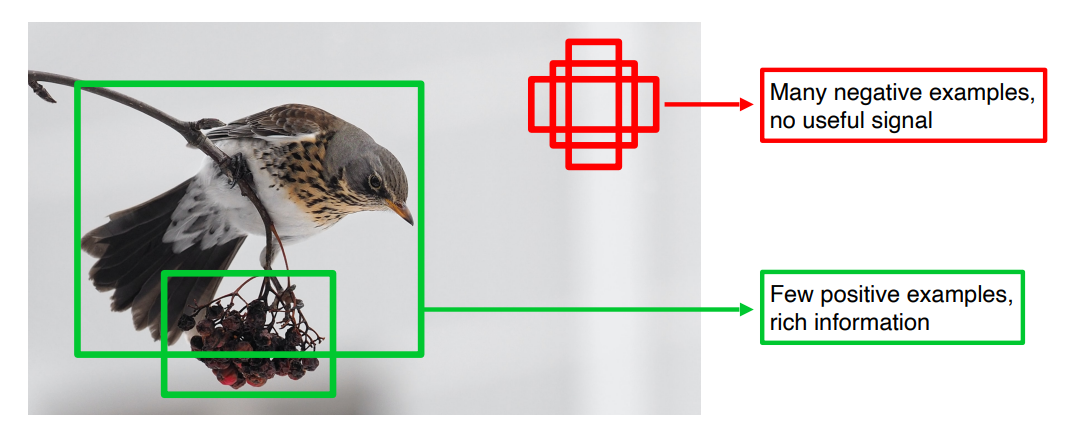
Single Stage 방법들은 Rol Pooling이 없어서 모든 영역에서의 loss가 계산되고 일정 gradient가 발생한다. 일반적인 사진에서보면 배경에 해당하는 negative example들과 사물에 해당하는 positive example들간의 불균형 문제가 발생한다. 그런 불균형 문제를 해결하기 위해 Focal loss라는 개념이 등장한다.
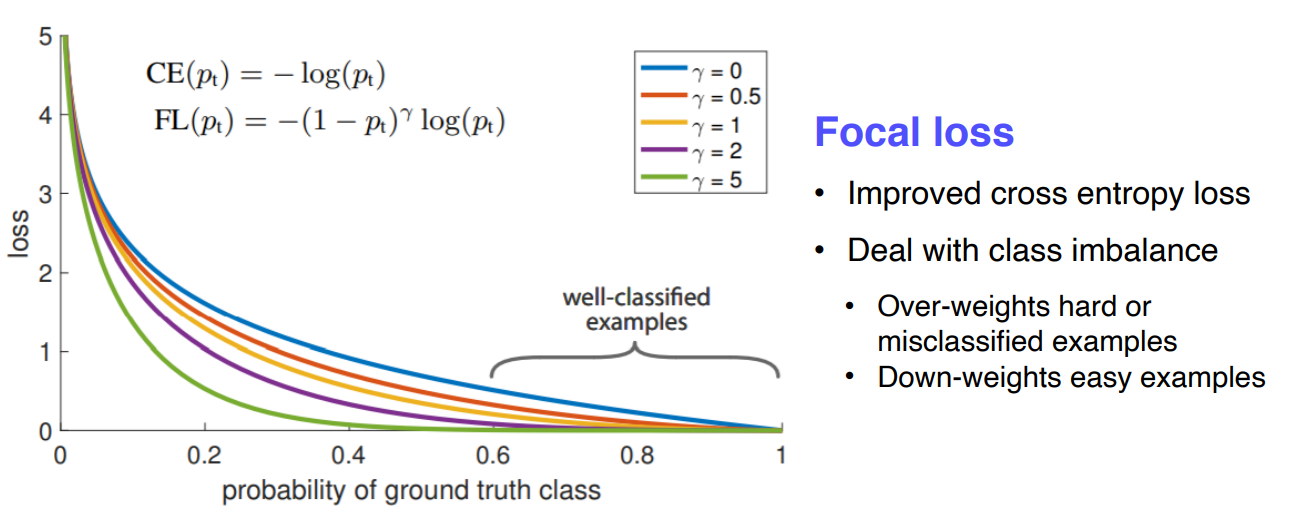
Focal Loss는 Cross Entropy Loss의 확장으로 에 따라서 function의 shape를 정해준다. 그래서 잘 맞춘애들은 더 낮은 loss를 주고 더 못맞춘 애들은 더 sharp한 loss값을 준다.
RetinaNet
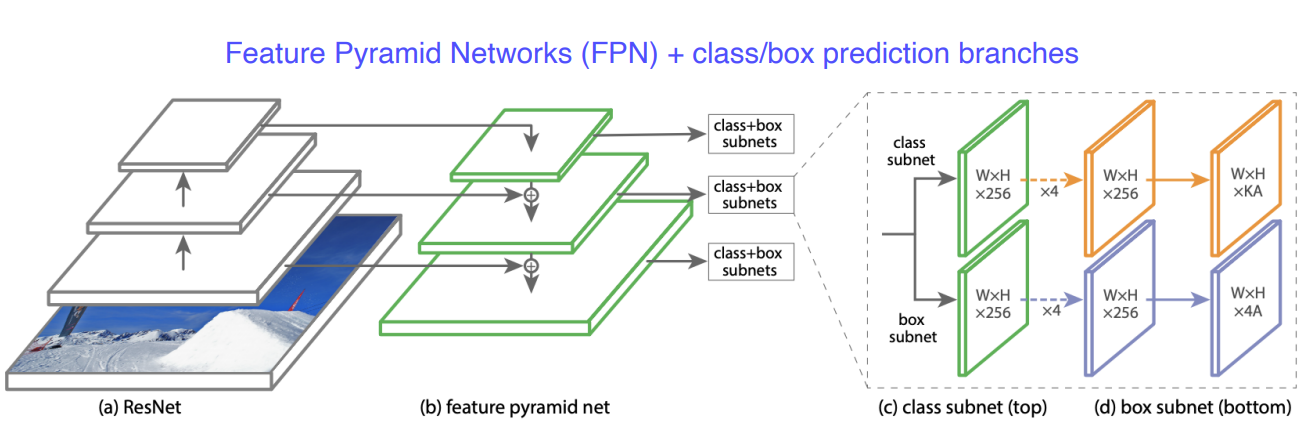
Feature Pyramid Network를 제안한다. low level과 high level의 특징을 잘 활용하면서 각 scale별로 물체를 잘 찾기 위한 multi-scale의 구조를 갖기위해서 설계되었다. 중간중간 feature를 넘겨주고 더하는 operation이 행해지게 된다. class head와 box head가 따로 구성이 되어서 classification과 box regression을 dense하게 각 위치마다 수행하게 된다.
DETR
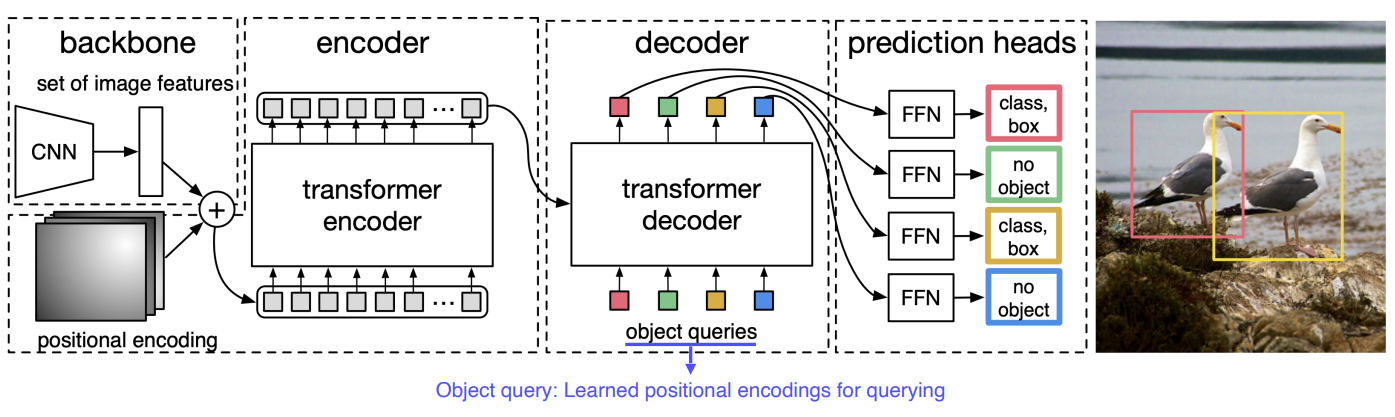
Transformer를 Object detection에 적용한 사례이다. CNN의 Feature와 각 위치의 multi-dimension으로 표현한 encoding을 쌓아서 입력 token을 만들어준다. 그리고 그 token들은 transformer encoder를 통해 encoding 되게 된다. 그렇게 추출된 정의들을 decoder로 넣어준다. decoder에서는 object query를 넣어주면서 특정 위치에 해당하는 object가 무엇인지 물어보게되고 그 위치에 어떤 물체가있는지 parsing되서 나오는 형태로 decoder가 돌아간다.
