ReceptiveField를 확장시킨 Models
Deeplabv2
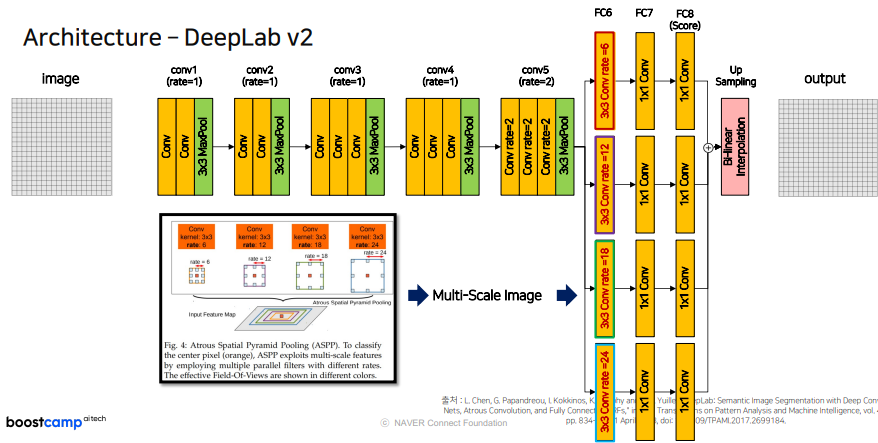
DilatedNet에서 Encoder 부분은 같고 Decoder 부분에서 4개의 가지를 만들어서 그것들을 합해서 사용해 변화를 주었다.
Rate가 큰 부분은 커다란 Object를 잘 검출해내기위해 사용했다.
각 Conv Block 마다 실행해주는 것들이 다르지만 공통적으로 크기를 맞춰준다.
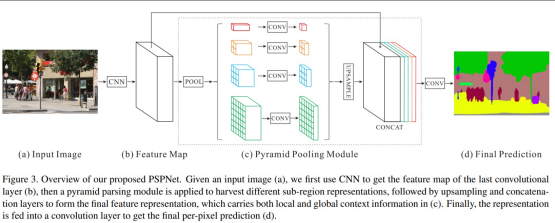
PSPNet
- MissmatchedRelationShip(외형이 비슷한 물체끼리 잘 구별을 못하는 문제)
- ConfusionCategories(Building과 Skyscrapper를 잘 구별하지 못하는 문제)
- InconspicuousClasses?(작은 물체를 찾기 힘든 문제)
위의 3가지 문제를 해결하고자 등장한 모델이다.
FCN은 Maxpool을 사용하여 크기를 줄이기 때문에 큰 Receptive Field가 사용이 되지만 이론적인 Receptive Field 크기와 실제적인 Receptive Field 사이즈가 Pooling이 진행될수록 차이를 보였다.
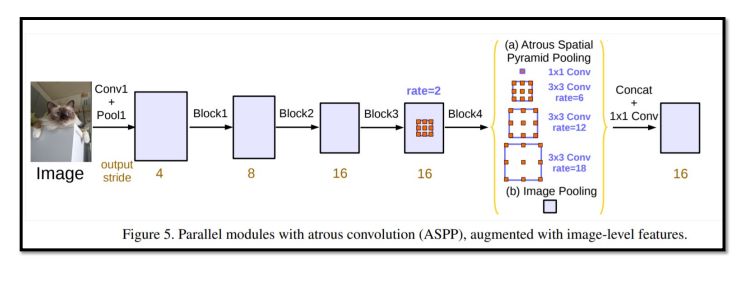
Deeplabv3
여러 개의 branch를 따서 마지막에 sum 대신 concat 해주는 형태이다.
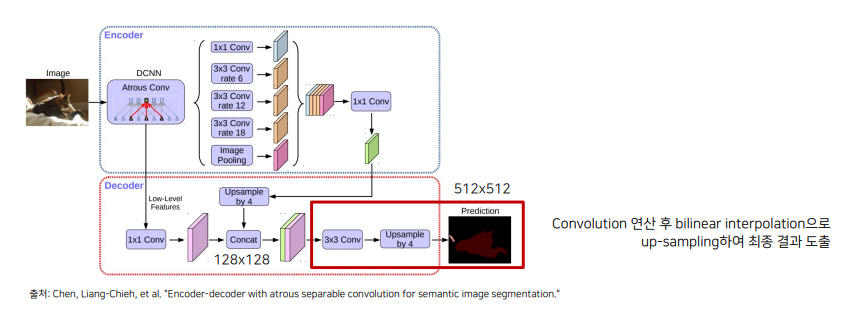
Deeplabv3+
v3에서 v3+로 넘어올 때 Encoder Decoder 구조를 사용했다.
기존 Deeplab은 ASPP를 적용하여 결과를 만들어서 Concat 혹은 sum을 취해주고 8,16배로 bilinear 하여 결과를 냈다.
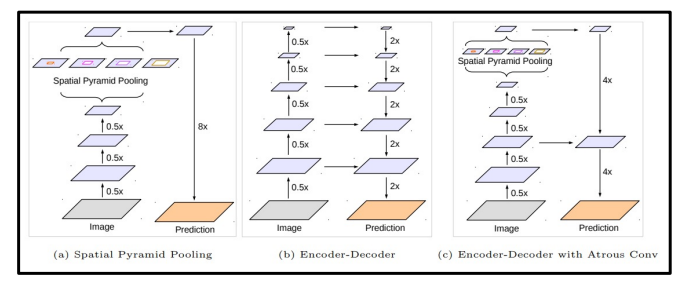
그러나 v3+는 skip connection을 활용하여 손실된 정보를 Decoder에서 점진적으로 복원했다.
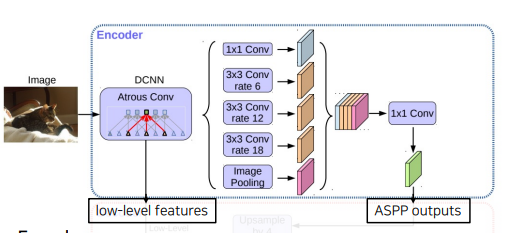
Encoder
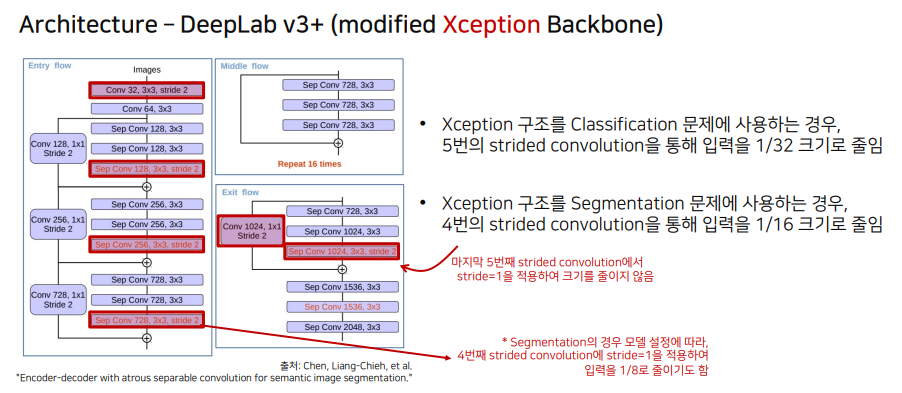
- 수정된 Xception을 backbone으로 사용했다.
- Atrous SeparableConvolution을 적용한 ASPP 모듈을 사용했다.
- Backbone내 low-level featrue과 ASPP 모듈 출력을 모두 Decoder에 전달한다.
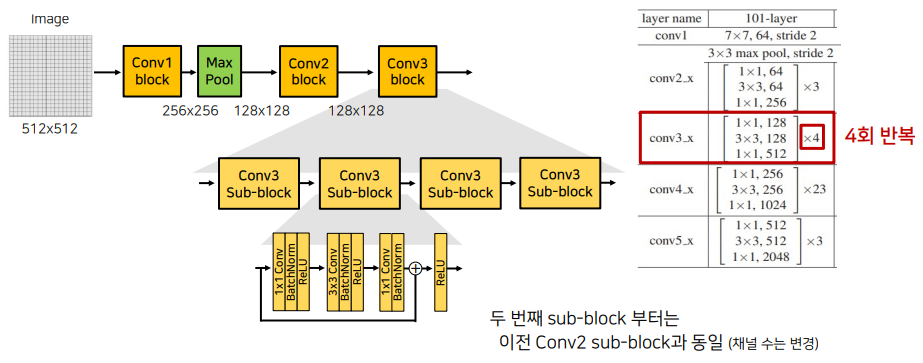
Modified Xception Backbone
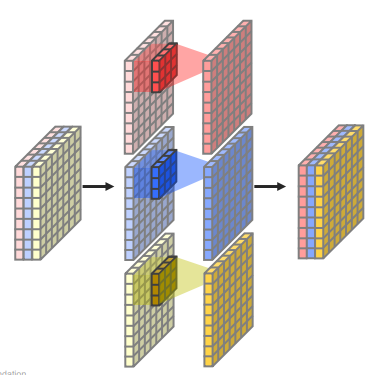
- depthwise Convolution을 사용한다. 각 채널마다 다른 filter를 사용하여 convolution 연산 후에 결합한다. input channel과 group을 동일한 값을 사용하여 구현이 가능하다.
- Pointwise convolution. 1x1 conv를 의미하여 kernel size로 1을 사용한다.
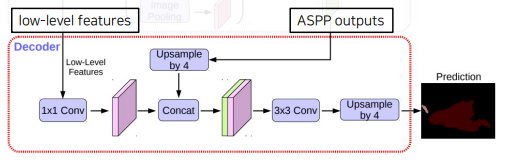
Decoder
- ASPP 모듈의 출력을 up-sampling하여 low-level feature와 결합한다.
- 결합된 정보는 convolution 연산 및 up-sampling 되어 최종 결과를 만들어낸다.
- 기존의 단순한 up-sampling 연산을 개선시켰다.