MLflow
머신러닝 실험, 배포를 쉽게 관리할 수 있는 오픈소스
MLflow의 핵심 기능
1) Experiment Management $ Tracking
- 머신러닝 관련 실험들을 정리하고 각 실험들의 내용들을 기록 할 수 있다.(여러 사람이 하나의 MLflow 서버 위에서 각자 자기 실험을 만들고 공유 가능)
- 실험을 정의하고 실행할 수 있다. 각 실행에 사용된 코드, 파라미터, Metric 등을 저장
2) Model Registry
- MLflow로 실행한 머신러닝 모델을 저장소에 등록할 수 있음
- Model Registry에 등록된 모델은 다른 사람들과 쉽게 공유 가능하고 활용 가능
3) Model Serving
- Model Registry에 등록한 모델을 REST API 형태로 서버로 Serving 가능
- Input은 Model의 Input이고 Output은 Model의 Output이다.
- Docker Image를 직접 만들지 않아도 생성이 가능하다.
MLflow Component
1) MLflow Tracking
- 머신러닝 코드 실행, 로깅을 위한 API,UI
- MLflow Tracking을 사용해 결과를 Local, Server에 기록하여 여러 실행과 비교가 가능하다.
- 팀에서 다른 사용자들과의 결과와 비교해가며 협업이 가능하다.
2) MLflow Project
- 머신러닝 프로젝트 코드를 패키징하기 위한 표준
- MLflow Tracking API를 사용하면 MLflow는 프로젝트 버전을 모든 파라미터와 자동으로 로깅
3) MLflow Model
- 모델은 모델파일과 코드로 저장
- 다양한 플랫폼에 배포할 수 있는 여러 도구 제공
- MLflow Tracking API를 사용하면 MLflow는 자동으로 해당 프로젝트에 대한 내용을 사용함
4) MLflow Registry
- MLflow Model의 전체 Lifecycle에서 사용할 수 있는 중앙 모델 저장소
MLflow Tracking
Experiement
- MLflow에서 가장 먼저 Experiment를 생성함.
- 하나의 Experiment에는 진행중인 머신러닝 프로젝트 단위로 구성됨
- 정해진 Metric으로 모델을 평가함
- 하나의 Experiment는 여러 실행을 가짐
Experiment 생성
mlflow experiments create --experiment-name my-first-experiment
mlflow experiments list : Experiment 리스트 확인
Run
- 하나의 Run은 코드 1번 실행한 것을 의미
- 보통 Run은 모델 학습 코드를 실행
- Run을 하면 여러가지 내용이 기록됨
- Source : 실행한 Project의 이름
- Version : 실행 Hash
- Start & End time
- Parameters : 모델 파라미터
- Metrics : 모델의 평가 지표, 시각화 가능
- Tags : 관련된 Tag
- Artifacts : 실행 과정에서 생기는 다양한 파일들
Run으로 실행
mlflow run "폴더 이름" --experiment-name "experiment이름" --no-conda
mlflow ui : UI 실행
autolog를 활용하여 파라미터를 매번 명시하지 않게끔 한다.
MLflow Architecture

외부 Storage 사용하기
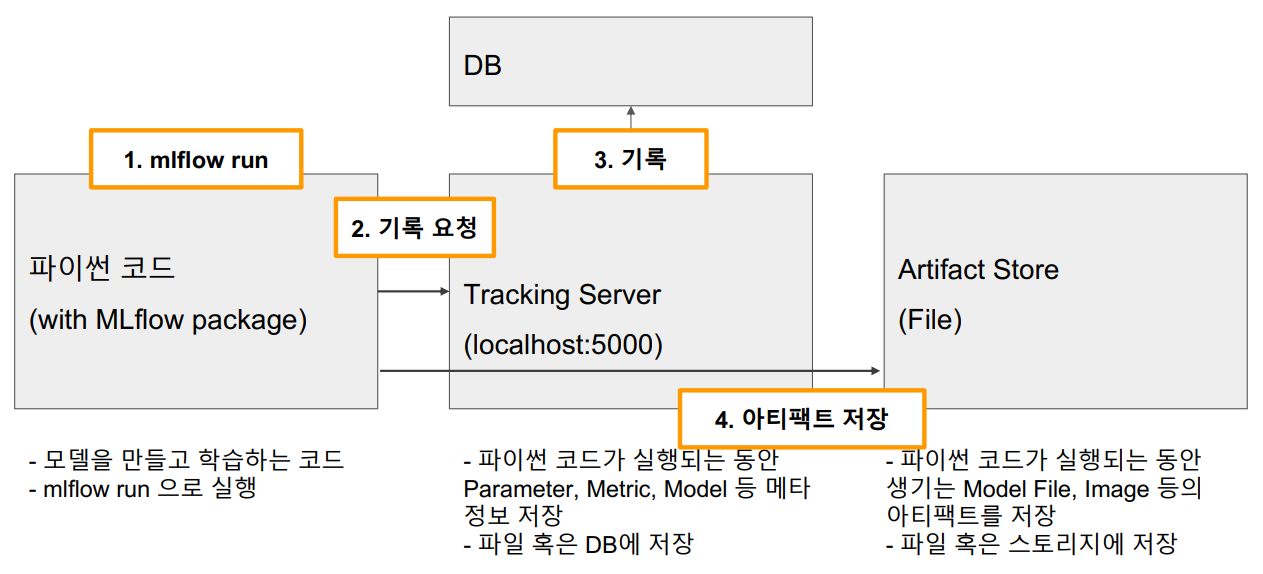
MLflow Tracking Server는 하나로 통합 운영
- Tracking Server 하나 배포하고 팀 내 모든 Researcher가 여기에 실험을 기록한다.
- 로그나 모델이 한 곳에 저장되므로 팀 내 모든 실험 공유 가능
- Artifact Storage와 DB 역시 하나로 운영
- 이 두 저장소는 Tracking Server에 의해 관리
