AI Math
벡터
벡터는 숫자를 원소로 가지는 list 또는 배열로써 공간의 한 점을 나타낼 때 사용한다. 벡터는 원점으로부터의 상대적 위치를 의미하며 벡터에 스칼라 곱을 하면 길이만 변한다. 음수를 곱하면 방향이 변한다. 벡터끼리의 모양이 같다면 벡터간 연산이 가능하다. 모양과 크기가 같은 두 벡터의 덧셈은 다른 벡터로부터의 상대적인 위치이동을 표현한다.
벡터의 노름
벡터의 노름은 원점으로부터의 거리를 의미한다.
1. L1 노름은 각 성분의 변화량의 절대값을 모두 더한 값으로 그림으로 표현하면 다음과 같다.

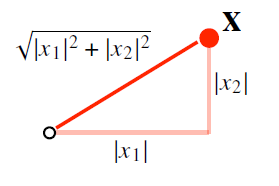
2. L2 노름은 피타고라스의 정리를 이용하여 거리를 계산한다. 이를 그림으로 나타내면 다음과 같다.
행렬
행렬은 벡터를 원소로 가지는 2차원 배열을 뜻한다. 행(row)과 열(column)로 구분지을 수 있다. 행렬은 공간의 여러 점들을 나타낸다. 행렬의 곱셈은 numpy의 @ 연산을 통해 수행할 수 있다. 또한 numpy의 inner 함수를 통해 i번째 행벡터와 j번째 행벡터의 내적을 계산할 수 있다. 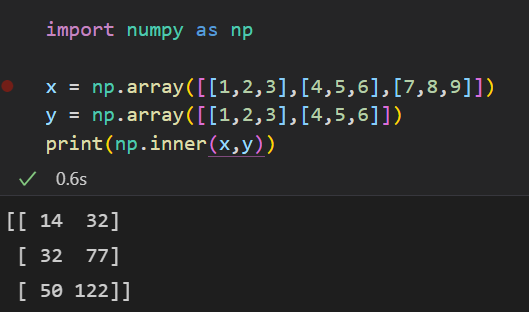
행렬은 벡터공간에서 사용되는 연산자이며 행렬곱을 통해 다른 차원의 공간으로 보낼 수 있다. 또한 패턴을 추출하고 데이터를 압축시키는 데에 사용될 수 있다.
역행렬
행렬 A에 곱했을 때 단위 행렬이 나오는 행렬을 역행렬이라고 한다. determinant가 0이 아닐 때에만 구할 수 있으며 만약 역행렬을 구할 수 없다면 유사역행렬 또는 무어펜로즈 역행렬을 이용한다.
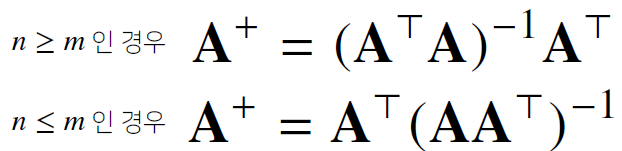
선형대수학에서는 행렬의 연립방정식을 푸는 것을 많이 배웠는데 numpy에서는 np.linalg.pinv 를 통해 간편하게 연립방정식의 해를 구할 수 있다. 그리고 데이터를 선형모델로 해석하는 선형회귀식을 찾을 수 있다.
경사하강법
미분
미분은 변수의 움직임에 따른 함수값의 변화를 측정하기 위해 사용한다. 최적화에 가장 많이 사용한다. 파이썬에서는 미분을 sympy.diff를 통해서 식을 대입하여 계산할 수 있다. 미분은 또한 특정 점에서의 접선의 기울기를 구할 때에도 쓰이는데 이를 통해 우리는 어떤 방향으로 점을 움직여야 함수값이 증가하는 방향인지 아니면 감소하는 방향인지 구별할 수 있다.
미분값이 양수 -> 증가하는 함수
미분값이 음수 -> 감소하는 함수
이렇게 구한 미분값들을 더하는 것을 경사상승법(gradient ascent)라고 하며 극대값을 구할 때에 사용한다.
반대로 미분값들을 빼는 것을 경사하강법(gradient descent)라고 하며 극소값을 구할 때에 사용한다.
만약에 변수가 벡터일 경우에는 각 변수 별 편미분을 계산한 gradient 벡터를 이용하여 경사하강과 경사상승법에 사용한다.
여기에서 gradient 벡터를 그림으로 나타내면 다음과 같이 나타낼 수 있다.

gradient 벡터는 각각의 점들에서 가장 빨리 증가 혹은 감소하는 방향으로 흐른다. 이를 활용하여 경사하강법에 알고리즘을 적용할 때에는 변수로 벡터를 사용했기 때문에 계산을 종료하는 종료 조건을 절댓값 대신 norm을 계산하여 종료한다.
앞서 정리했던 개념중 선형회귀분석이 있는데 이것은 데이터를 선형모델로 해석하여 무어 펜로즈 역행렬을 통해 실제 y값과 예측 y값의 차이를 최소화 시키는 베타값을 구할 수 있다고 했다. 그러나 모든 모델이 선형모델은 아니기 때문에 경사하강법을 통해 실제값과 예측값의 차이를 최소화 시키는 베타값을 구해야 한다.
수식으로 나타내면 다음과 같다.
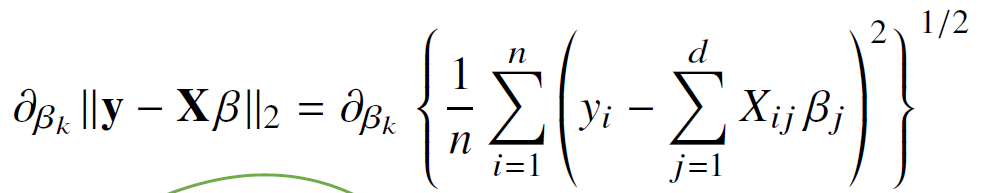
n개의 데이터를 가지고 계산되는 L2 norm이기 때문에 1~n까지의 y-Xβ의 차이의 제곱을 n으로 나눠주어 평균으로 만든 후 이것의 제곱근을 구해준다. 위의 식을 더 깔끔하게 정리하면 다음과 같이 만들어 볼 수 있다.
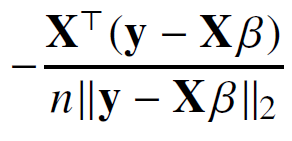
Xβ의 모델을 β에 대해 미분한 것이기 때문에 X가 아닌 X의 전치행렬을 곱해준다. β를 구하기 위해 점화식을 세워보면 다음과 같이 정리할 수 있다.
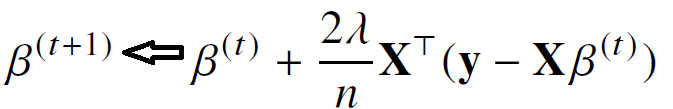
여기서의 λ는 학습률에 해당하며 이 λ의 값을 조정하면서 수렴속도를 조정할 수 있다. 또한 경사하강법을 통해 구한 값은 실제값과 차이가 나는 것이 당연하기 때문에 학습을 진행하는 횟수가 너무작거나 적절한 학습률을 지정해주지 않을경우에는 근사값이 제대로 나오지 않게 된다.
경사하강법 알고리즘에서는 학습률과 학습횟수를 적절하게 선택해야한다.
확률적 경사하강법
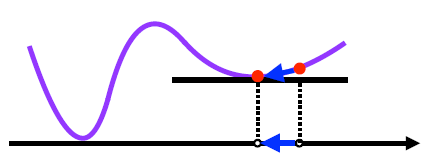
위 그림과 같은 경우에는 경사하강법으로 구한 값들이 수렴하지 않게 된다. 따라서 이를 보완하고자 확률적 경사하강법을 사용한다. 확률적 경사하강법은 데이터를 일부 활용하여 업데이트를 한다.
데이터 1개만 이용 -> SGD
데이터 일부만 이용 -> mini batch SGD

SGD는 n개의 데이터가 아니라 b개의 데이터만 가지고 계산하기 때문에 연산자원을 효율적으로 활용한다. 그리고 전체 데이터가 아니기 때문에 gradient값은 조금 다르지만 방향이 유사하다고 기대해볼 수 있다. 목적식 또한 설정한 미니배치의 영향을 받아 매번 바뀌게 된다. 그렇기 때문에 극소점이나 극대점에서도 확률적으로 미분값이 0이 아니게 된다. 앞선 방식이 미분값이 0이되면 더 이상 연산을 안하고 멈추는 반면 확률적 경사하강법은 극소값에서도 확률적으로 0이 안되게 되어 탈출이 가능해진다. 방향자체는 경사하강법과 조금은 다를 수 있지만 미니배치를 통해 계산을 하기 때문에 연산속도가 경사하강법보다 빠르다. 그러나 미니배치 크기를 너무 작게 잡으면 속도가 느려질 수 있다.
결론적으로 확률적 경사하강법에서는 학습률,학습횟수,미니배치 크기를 고려해주어야한다.
딥러닝에서는 하드웨어와 알고리즘의 효율성을 고려하여 확률적 경사하강법을 이용한다.
신경망
분류와 같이 복잡한 패턴을 가지고 있는 문제를 해결하고자 할 떄에는 선형모델로만가지고 학습하기에 어려움이 따른다. 그렇기 때문에 신경망학습을 진행한다. 신경망은 비선형모델이며 그림으로 나타내면 다음과 같다.
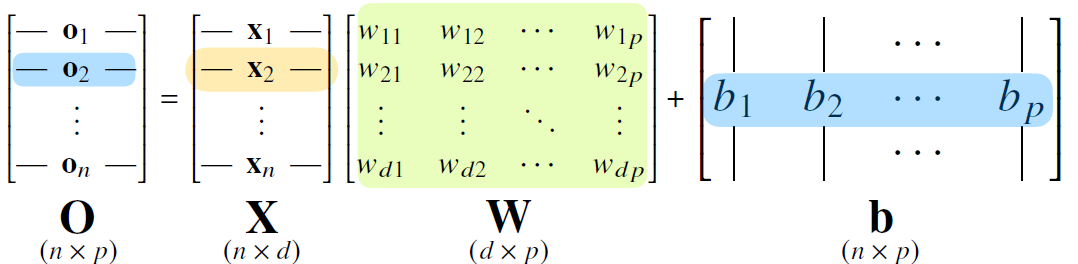
X는 데이터셋을 의미하고 W는 데이터를 다른 공간으로 보내주는 가중치 행렬을 의미한다. b는 y절편에 해당하는 행렬이다. 이것을 수식으로 표현하면
O = W * X + b 로 나타낼 수 있다.
softmax
분류문제를 풀 때에 필요한 연산자이다. 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산이다. 분류문제를 풀 때에는 이 softmax 함수와 선형모델을 결합하여 해결한다. 수식은 다음과 같이 표현할 수 있다.
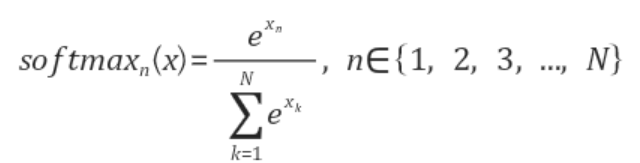
분모에 해당하는 것은 각 출력벡터들의 값에 지수함수를 씌운 값들의 합이다. 분자는 각각의 출력값의 성분에 해당하는 값에 지수함수를 씌운 것이다. softmax 함수의 출력값은 원 핫 벡터로 0 또는 1의 출력값만을 가지는 추론문제를 해결하는 데에는 사용하지 않는다.
활성함수
비선형함수로써 다른 주소의 출력값을 고려하지 않고 해당 주소의 출력값만을 고려한다. input값으로 벡터가 아닌 실수값을 받는다. 이것을 이용하여 선형모델로 나온 출력물을 비선형으로 변형한다. 그리고 그 결과물을 잠재벡터라고 한다. 딥러닝에서는 ReLU 함수를 주로 활성함수로 사용한다.
forward propagation

입력값 x에 선형모델을 적용하여 출력값 z를 얻고 z를 다시 선형모델을 적용하여 잠재벡터 H를 얻을 수 있다. 그 H를 가중치 행렬 W와 b를 통해 선형변환하여 출력하면 결과값이
O = HW + b가 되고 이것을 2층 신경망이라고 부른다. 선형모델과 활성화 함수를 반복적으로 사용하는 것을 딥러닝의 기본적인 모형이다. 층을 여러개를 만들면 multi-layer perceptron이다. 총 l개의 순차적인 신경망 계산을 통해서 출력모델 O를 만드는 과정을 순전파(forward propagation)라고 한다. 순전파는 학습이 아니라 출력값을 내기 위한 연산이다.
층을 여러개를 쌓는 이유 : 목적함수를 근사하는데 필요한 뉴런의 숫자가 빨리 줄어들기 때문
backward propagation
딥러닝은 각 층에 존재하는 파라미터들에 대한 미분을 계산하여 사용한다. 그러나 경사하강법과는 다르게 순차적으로 역순으로 계산하게 된다. 여기서 손실함수를 L이라는 것을 사용하는데 역전파 알고리즘을 각각의 가중치 행렬 W^L에 대해서손실함수에 대한 미분을 계산하는데에 사용한다. 아랫층에서 gradient vector를 계산할 때에 윗 층의 gradient vector가 필요하다.
역전파 알고리즘은 합성함수를 미분하는 방식인 연쇄법칙을 기반 자동미분을 사용한다.
연쇄법칙의 원리는 다음과 같다.

딥러닝에서 각 뉴런에 해당하는 값을 tensor라고 하는데 이 값들은 메모리에 저장을 해줘야만 역전파법이 제대로 동작한다. 그렇기 때문에 각 뉴런의 tensor값을 미리 메모리에 올려둬야해서 역전파법이 순전파법보다 메모리를 많이 사용하게 된다.
역전파법의 계산순서는 다음과 같다.
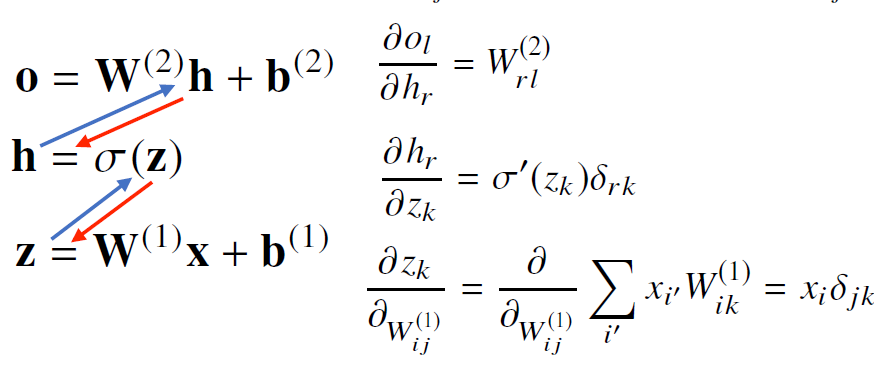
확률
회귀분석에서는 예측오차의 분산을 최소화하는 방향으로 학습을 유도하고
분류문제에서는 모델 예측의 불확실성을 최소화하는 방향으로 학습을 유도하기 때문에 딥러닝에서 확률론이 필요하다.
데이터는 확률변수로 표현한다.
확률변수는 확률분포의 종류에 따라 이산형과 연속형으로 나누어진다. 데이터 공간이 정수 집합이면 이산형으로 볼 수 있고 실수 집합이면 연속형으로 볼 수 있다.
이산형 확률변수의 식은 다음과 같다.
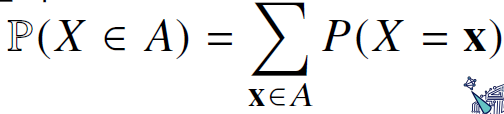
확률변수 X가 x가 될 모든 확률값을 더하여 계산한다.
연속형 확률변수의 경우에는 데이터 공간에 정의된 확률변수의 밀도위에서의 적분을 통해 모델링한다.
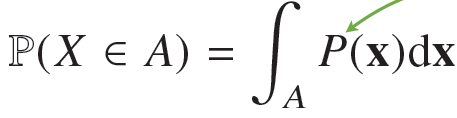
주변확률 분포는 x 혹은 y에 대한 정보만 제공한다.
조건부확률
조건부확률 P(y|x)는 x에 대해 정답이 y일 확률이다. 분류문제에서 데이터 x로부터 추출된 특징패턴을 Φ(x)과 가중치행렬W를 통해 조건부확률을 계산할 수 있다.
회귀문제의 경우에는 보통 y가 연속인 경우를 다루기 때문에 적분으로 다음과 같이 표현한다.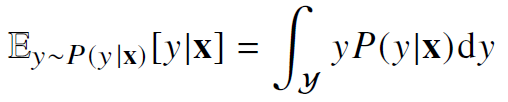
조건부 기대값은 L2 노름을 최소화하는 함수와 일치하기 때문에 회귀문제에서 사용된다.
기대값
기대값은 데이터를 대표하는 통계량이다.
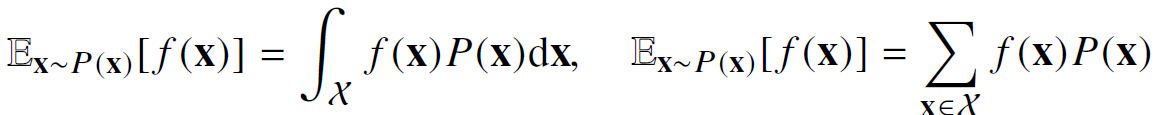
연속확률분포의 경우 주어진 함수에 확률밀도함수를 곱해서 적분하여 계산하고 이산확률분포의 경우 주어진 함수에 확률질량함수를 곱해서 더해준다.
몬테카를로 샘플링
확률분포를 모를 때에 기대값 계산을 위해 사용한다. 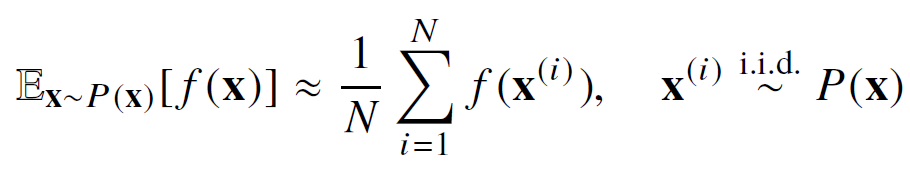
타겟 함수 f(x)에서 x에 샘플링한 데이터를 대입하여 산술평균을 계산해준다. 샘플링을 할 때에 독립적으로 해줘야 한다는 것이 중요하다.
통계학
통계적 모델링은 적절한 가정 위에서 확률분포를 추정하는 것을 목표로 한다. 평균과 모수를 묶어서 모수라고 하는데 평균과 분산을 추정하는 방법을 통해서 데이터를 학습하는 것을 모수적 방법론이라고 하고 반대로 데이터에 따라 모델의 고주 및 모수의 개수가 바뀌면 비모수적 방법론이라고 한다. 비모수적 방법론에서 모수가 없는 것이 아니라 모수가 무한히 많거나 모수의 개수가 데이터에 따라서 바뀐다. 데이터가 어떤 원리로 생성되었는지를 고려하여 확률 분포를 베르누이, 카테고리, 베타, 감마, 정규분포 등으로 구분짓는다.
데이터의 표본평균과 표분분산을 구하는 식은 다음과 같다.
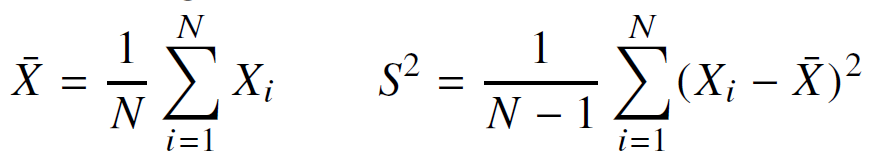
표본분산에서 N-1로 나눠주어야 표본분산의 기대값이 원래 모집단의 분산의 제곱과 일치하게 된다. 통계량의 확률분포를 표집분포라고 하며 표본평균의 표집분포는 N이 커질수록 정규분포를 따르게 된다.(중심극한정리) 모집단의 분포가 정규분포를 따르지 않는다 해도 표본평균의 표집분포는 정규분포를 따른다. 이렇게 추정된 모수를 가지고 원래 데이터의 성질이나 정보를 취합할 수 있다. 예측 또는 의사결정을 내릴 때에 이런 통계학 모델을 사용하게 된다.
최대 가능도
이론적으로 가장 가능성이 높은 모수를 추정하는 방법이다.

데이터가 주어진 상황에서 세타를 변형시키면서 값이 변경되는 함수이다. 만약 데이터집합 X가 독립적으로 추출되었을 경우에는 로그가능도를 사용하여 최적화할 수 있다.
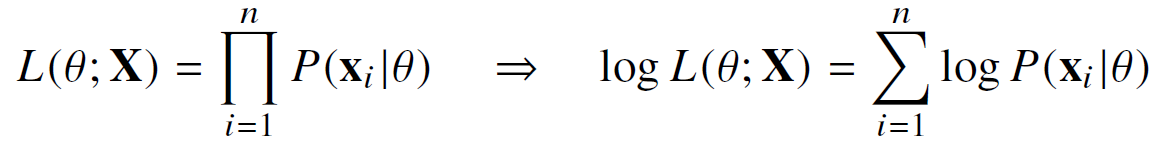
로그가능도를 사용하는 이유는 log는 곱셈을 덧셈으로 표현해주기 때문에 연산량이 O(n^2)에서 O(n)으로 줄어들기 때문에 시간복잡도가 선형적으로 변한다.
최대가능도 추정법을 사용하여 평균μ와 분산σ를 구해보면 다음과 같다.

카테고리 분포에서의 최대가능도를 추정하는 식은 다음과 같다.

이 때 X(i,k)는 전부 0 혹은 1이기 때문에 이 부분은 주어진 각 데이터에 대해서 k값이 1인 개수를 세는 부분이다.
카테고리분포에스 MLE는 각각의 경우에 해당하는 데이터의 count수를 세어서 비율을 구하는 것으로 최대가능도를 달성하는 모수를 추정한다.
딥러닝에서의 최대가능도 추적법 수식은 다음과 같다.
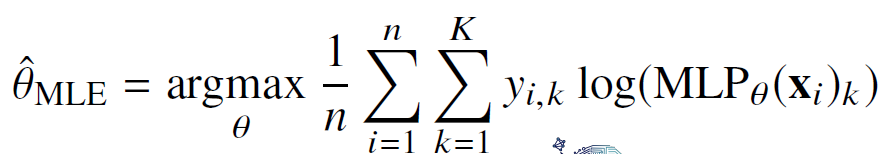
multip layer percetpron의 예측값이 k번째 예측값의 로그값과 정답 label에 해당하는 y의 k번째 주소값을 곱해준것들의 덧셈으로 표현이 가능하다.
쿨백-라이블러 발산
쿨백 라이블러는 다음과 같이 크로스 엔트로피와 엔트로피로 분해할 수 있다.

크로스엔트로피는 log(Q(x))에 대한 기대값이고 엔트로피는 lop(P(x))에 대한 기대값이다.
최대가능도에서 로그가능도를 최대화시키는 것은 정답 label에 해당하는 확률분포P와 모델예측에서 사용되는 확률분포Q사이의 거리와 동일하다.(쿨백 라이블러 발산을 최소화 하는것)
조건부확률
P(A∩B) = P(B)P(A|B) 로 사건 B가 일어난 상황에서 A가 발생할 확률을 의미한다.
베이즈 정리

D는 새로 관찰하는 데이터를 뜻하고 θ는 모델에서 계산하려는 모수이다. 사후확률은 데이터가 관찰된 이후의 확률이고 사전확률은 데이터를 관찰하기 이전에 사전에 주어진 확률로 계산한 것이다. 가능도는 현재 주어진 모수에서 이 데이터가 관찰될 확률이다. 마지막 Evidence는 데이터 자체의 분포이다.
조건부확률을 시각화하면 다음과 같다.

베이즈 정리를 활용하여 새로운 데이터가 들어왔을 때 앞서 계산했던 사후확률을 사전확률로 사용하여 갱신시킬 수 있다.
인과관계
인과관계는 데이터 분포의 변화에 강건한 예측모델을 만들 때에 필요한데 이를 알아내기 위해서는 중첩요인 효과를 제거해서 원인에 해당하는 변수만의 인과관계를 알아내야한다. 이를 그림으로 간단히 표현하면 다음과 같다.
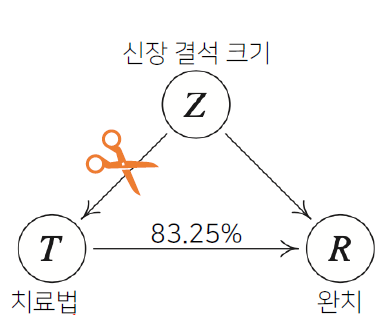
CNN
Convolution
Convolution 연산은 고정된 가중치 행렬인 커널을 사용하여 입력벡터 상에서 움직이면서 계산하는 구조이다. 커널사이즈가 고정되어있기 때문에 파라미터 사이즈 역시 많이 줄어든다. 커널은 정의역 내에서 움직여도 변하지 않으며 주어진 신호에 국소적으로 적용한다.
2차원 Convolution
1차원에서의 연산과 달리 입력벡터 상에서 움직여가면서 계산한다. 이를 수식으로 표현하면 다음과 같다.
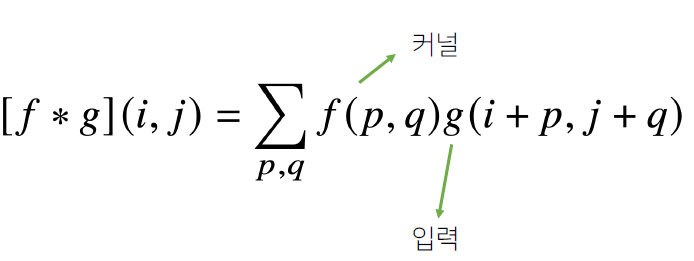
여기서 i와j는 고정되어있고 p와q만 움직이면서 계산한다. 입력의 크기를 (H,W) 커널의 크기를 (K_H,K_W), 출력의 크기를 (O_H,O_W)라 하면 출력 크기는 다음과 같은 식으로 계산할 수 있다.

Convolution 연산의 역전파
Convolution 연산은 역전파를 계산할 때에도 convolution 연산이 나온다.
RNN
소리, 문자열, 주가 등의 데이터를 시퀀스 데이터로 분류한다. 시퀀스 데이터는 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포가 변하게 된다. 이전 시퀀스의 정보를 가지고 앞으로 발생할 확률분포를 다루기 위해 조건부확률을 이용하며 식은 다음과 같다.
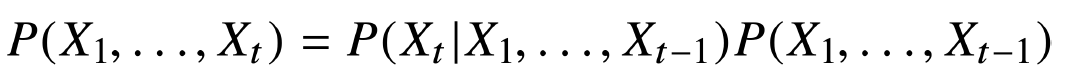
식에 나온 내용과는 조금 다르게 꼭 1~t-1까지의 모든 데이터가 필요하지는 않다.

이런식으로 데이터를 나누게 되면 바로 직전 정보와 잠재변수 2가지만 가지고 현재 혹은 미래 시점을 예측을 할 수 있기 때문에 길이가 가변적이지 않게 된다.
Recurrent Neural Network
기본적인 RNN 모형은 다음과 같다.
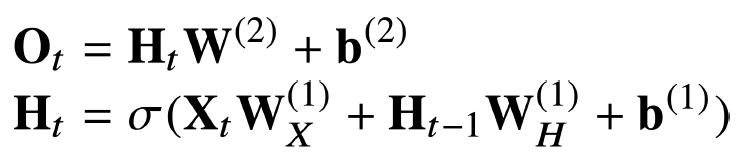
입력으로부터 전달하는 W_x 가중치행렬과 이전 잠재변수로부터 정보를 전달하는 W_h 가중치행렬을 만들어서 잠재변수 H_t를 계산하게 되고 이것을 복제해서 H_t+1의 잠재변수를 인코딩할 때 사용한다.
RNN을 역전파법을 이용하게 되면 다음과 같이 그림으로 나타낼 수 있다.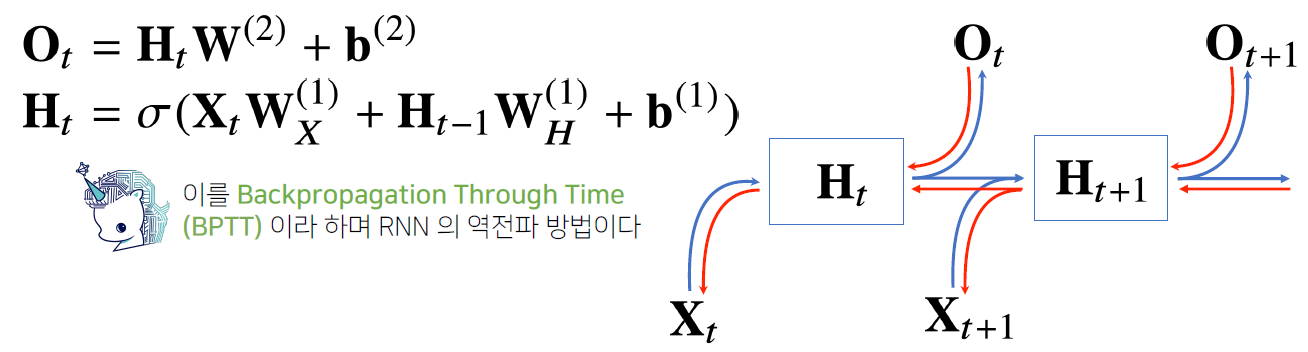
빨간 선은 gradient의 전달경로이다. 다음 시점에서 들어오는 gradient vector와 출력에서 들어오는 gradient vector 2개로 잠재변수로 전달이 된다. 이것들을 입력과 그 이전시점의 잠재변수로 전달하는 과정을 반복하면서 학습을 진행한다.
시퀀스의 길이가 길어지면 기울기 소실(gradient가 0으로 줄어드는 현상)이 발생한다. 이를 해결하기 위해 truncated BPTT라는 미래의 정보들중 중 몇 개는 끊고 과거의 정보를 블럭을 나눠서 역전파법 연산을 한다. 이를 그림으로 표현하면 다음과 같다.

