
- 전체보기(37)
- machine learning(8)
- 블록체인(5)
- python(4)
- Bitcoin(3)
- joblib(3)
- 비트코인(3)
- multiprocessing(3)
- blockchain(3)
- Deep Learning(2)
- BERT(2)
- high performance python(2)
- mining(2)
- 채굴(2)
- SHAP(2)
- 이더리움(2)
- matomo(2)
- paper-review(2)
- Crypto coin(2)
- 암호화폐(2)
- interpretable model(2)
- Auto Encoder(2)
- PCA(2)
- 가상화폐(2)
- block chain(2)
- data 수집(2)
- token economy(1)
- text embedding(1)
- kmeans(1)
- shapely value(1)
- 평가지표(1)
- KNN(1)
- 분류 문제(1)
- monte carlo(1)
- 차원 축소(1)
- f1 score(1)
- deeplift(1)
- udemy(1)
- 전략(1)
- tfx(1)
- Anomaly Detection(1)
- t-SNE(1)
- bandit algorithm(1)
- pinterest(1)
- Probability(1)
- explainable model(1)
- Recommendation(1)
- accuracy(1)
- OpenAI(1)
- 팀 하포트(1)
- CLEAN CODE(1)
- 무담보(1)
- Classification(1)
- EOS(1)
- tensorflow(1)
- roc auc(1)
- 추천(1)
- erc(1)
- Out of Memory(1)
- pr auc(1)
- DeepLearning(1)
- 머신러닝(1)
- consensus(1)
- Fetch(1)
- youtube(1)
- pull(1)
- Adapt(1)
- 토큰 이코노미(1)
- 암호화폐 담보(1)
- mlops(1)
- Token(1)
- 개발지침(1)
- gpt4(1)
- crypto token(1)
- spark(1)
- umap(1)
- binary model(1)
- git(1)
- imbalanced data(1)
- Dimension Reduction(1)
- stable coin(1)
- 확률(1)
- gradient(1)
- Neural Network(1)
- CBDC(1)
- 피아트 담보(1)
- Experiment(1)
- 상품 담보(1)
- pintext(1)
- deep double descent(1)
- ethereum(1)
- DPoS(1)
- spark error(1)
- 병렬화(1)
- traditional algorithm(1)
[paper review] Recommending What Video to Watch Next: A Multitask Ranking System
'다음 볼 영상'(youtube) 추천을 위한 large scale multi objective ranking system 제안함multi task learning 방식을 제안했는데, ctr 뿐 아닌, 좋아요, 공유 등 multiple competing ranking
[Lecture review] openai api 마스터하기 - Sec1
"OpenAI API 마스터하기: GPT-4의 무한한 창의성 끌어내기"ChatGPT API, Whisper, 임베딩, DALL-E 에 대해 배우면서, 프롬프트 엔지니어링을 체험해 볼 수 있는 강의라기에 시도해보았다.api를 활용한 다양한 예제들을 보여주고 있어서, op

[paper review] Bandit based Optimization of Multiple Objectives on a Music Streaming Platform
온라인 추천시스템의 경우 여러 multi-stakeholder 를 만족시켜야 하는경우가 종종 있다. e.g. 판매자와 구매자, listener와 artist 등 이 논문에서는 contextual bandit 을 multi objective setting 으로 확장시켜서
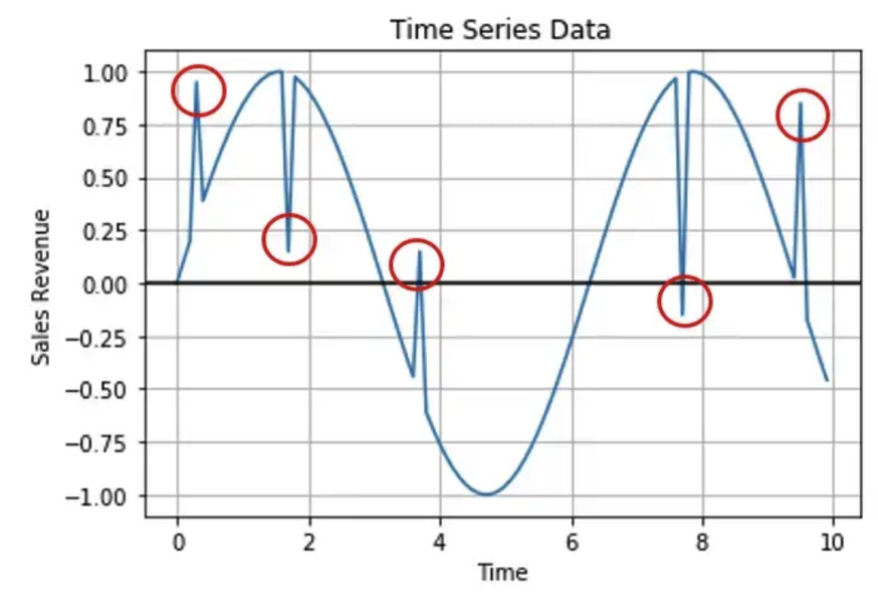
[Timeseries data anomaly detection] article 요약
https://towardsdatascience.com/effective-approaches-for-time-series-anomaly-detection-9485b40077f1집단의 공통적인 trend, seasonality, cycle 형태를 따르지 않는 데

Spark executor 에 메모리가 부족해지는 경우
Spark executor 에서 메모리가 부족할 경우 yarn 은 자동적으로 이 잡을 죽여버린다.이때에 worker 의 log 를 보면 "Container killed on request. Exit code is 137" 이라는 메시지가 남게 되고, executor 의
ML system design 때의 유의할 점
time dependent 한 feature 라면 -> 지금까지 user 가 click 을 몇번 했는가 등 -> training time 동안 계산해서 넣는건 쉽지 않다(그 이전까지만의 값으로 잘 넣아야한다.)데이터 수집 자체에 문제가 있을 수 있음 -> 이들에 있어서
[파이썬클린코드]3장. 좋은코드의 일반적인 특징
Do not Repeat Yourself, Once only once코드에 있는 지식은 단 한번, 단 한곳에 정의되어야한다.그렇지 않을경우오류 발생이 쉬워진다 (여러 반복중에 하나라도 빠트리면 버그발생)비용이 비싸다 (변경에 더 많은 시간이 쓰이게 될 것)신뢰성이 떨어

[MATOMO] javascript tracker 방식 vs image beacon 방식
MATOMO를 이용하여 Java script tracker 방식으로 로그를 수집하면 아래와 같은 경우에 대해서 로그 수집이 불가능해진다.JavaScript를 disable 해둔 사용자 로그내가 제어하지 않는 웹사이트에서 페이지가 조회된 경우(타사 마켓 플레이스 등)뉴스

MATOMO 기본 작동원리
## MATOMO? - 분석 데이터 수집 및 저장하는 오픈소스 라이브러리(유료 cloud버전도 있기는 함) - 저장된 데이터에 대한 보고서 제공
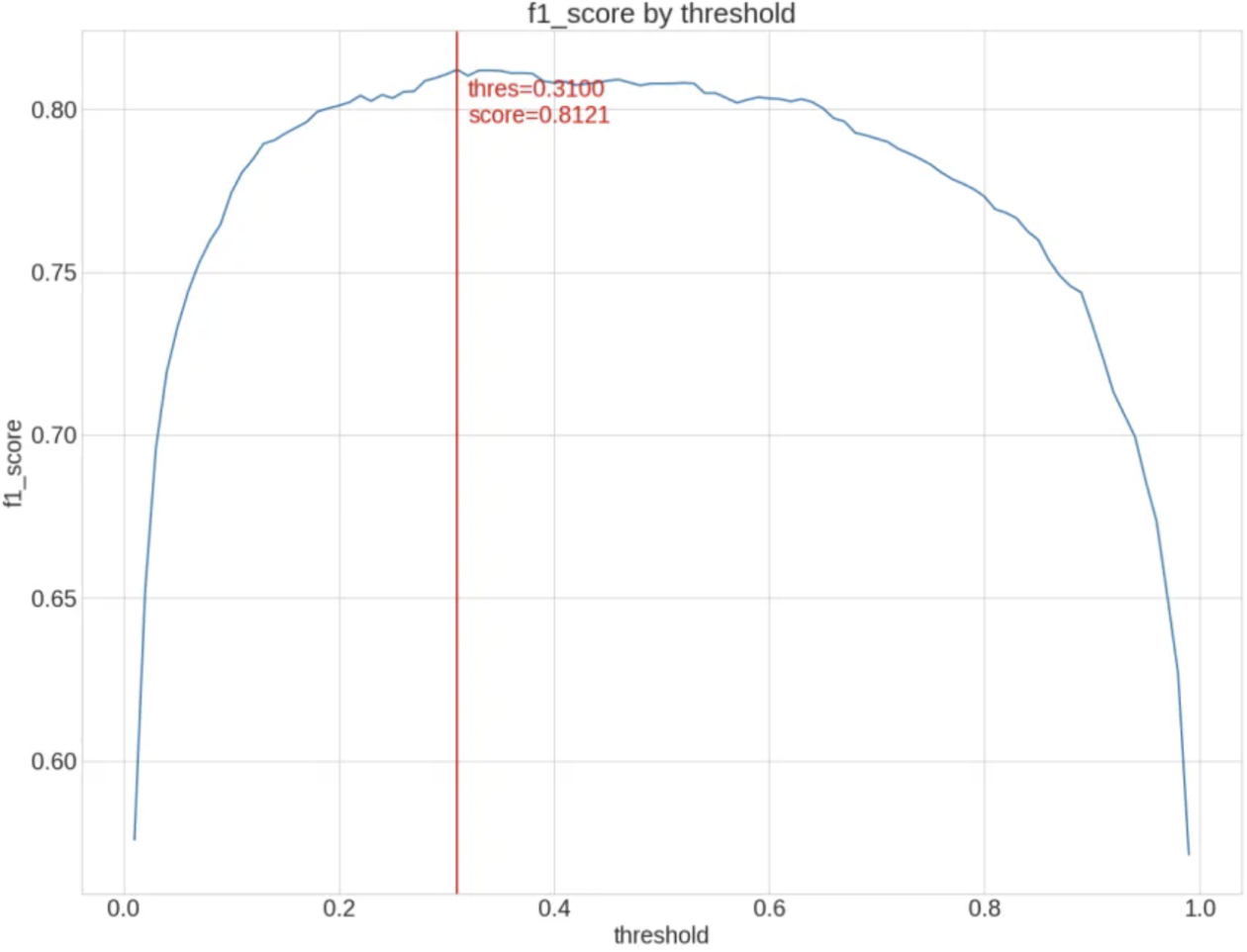
Evaluation metric survey
imbalanced되어있으면서도, ranking이 중요한 데이터에 대해서(e.g. click이 잘 일어나지 않지만, ctr의 순위를 잘 결정하는것이 중요한 데이터에 대해서) 평가 지표를 찾는다.accuracy, f1score, ROC AUC, PR AUC 등의 여러 지

[책 리뷰]ADAPT -팀하포드
세계는 복잡하고 빠르게 변화하며 그 안에 존재하는 문제들 또한 복잡하고 빠르게 변화한다. (기후변화에 대응할 수 있도록 경제체제를 변경하는 방법, 가난한 나라를 부유하게 만드는 방법, 투자은행들이 또다시 금융 시스템을 붕괴시키지 못하도록 제어하는 방법 등)이런 문제들을
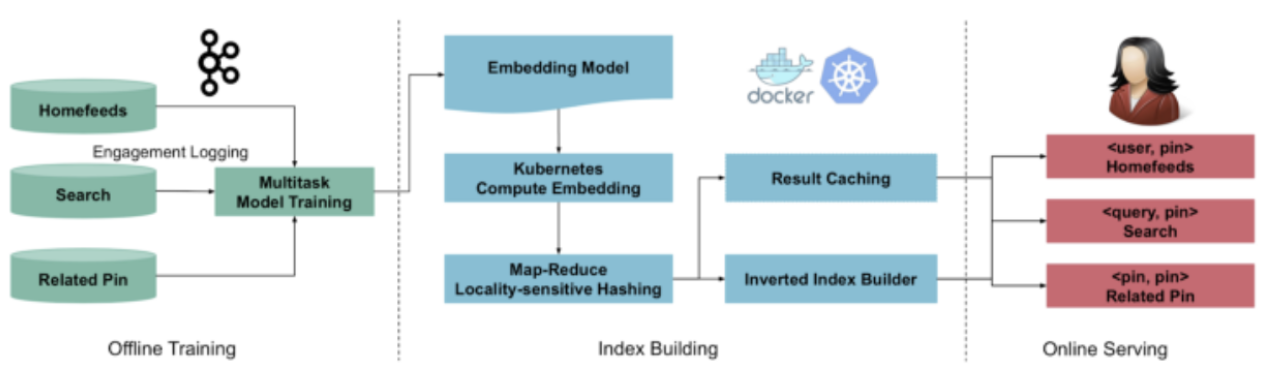
[Paper review]PinText : A Multitask Text Embedding System in Pinterest
pinterest 에서 19년에 kdd에 냈던 논문.https://dl.acm.org/doi/10.1145/3292500.3330671multitask text embedding solution 제안word level semantic vectors 생성함. 이
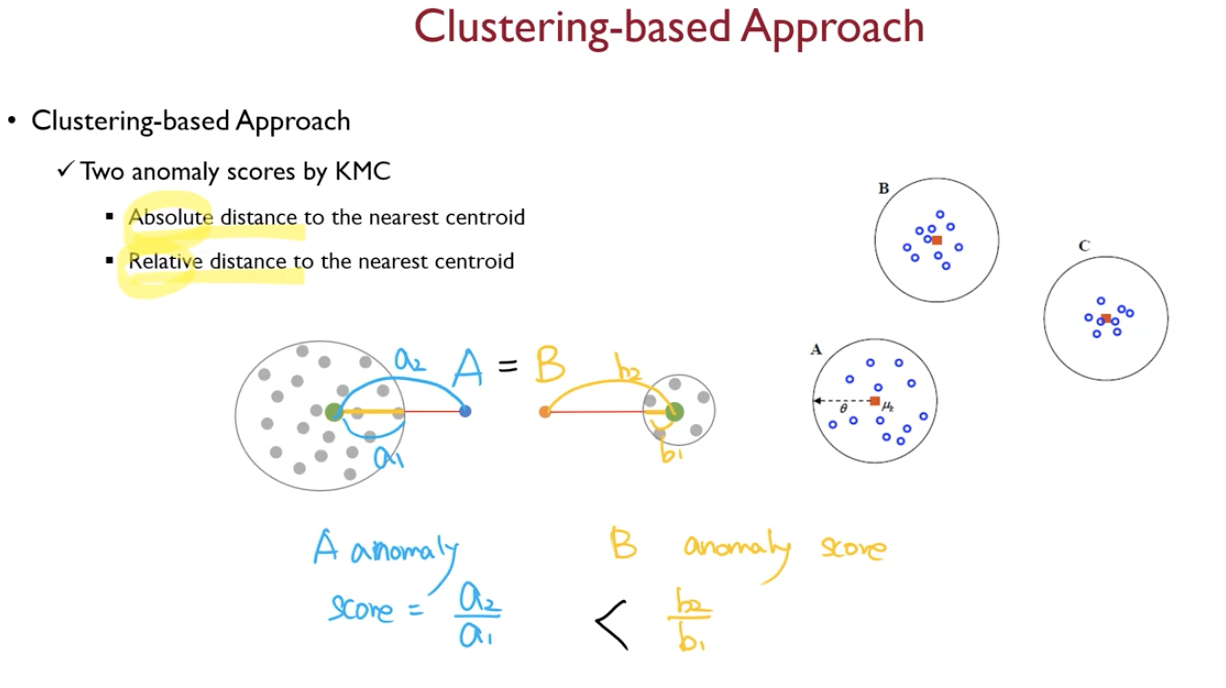
[Anomaly detection] Traditional way - Distance-based methods
이상치 데이터는 거리상으로 멀리 떨어져있을 것이라는 가정이때엔 거리만으로 이상치 여부를 판단하고, normal class에 대해서 어떠한 사전분포도 가정하지 않는다.parzen window density estimation 에서 p(x)=k/(N\*V) (k=영역에 존
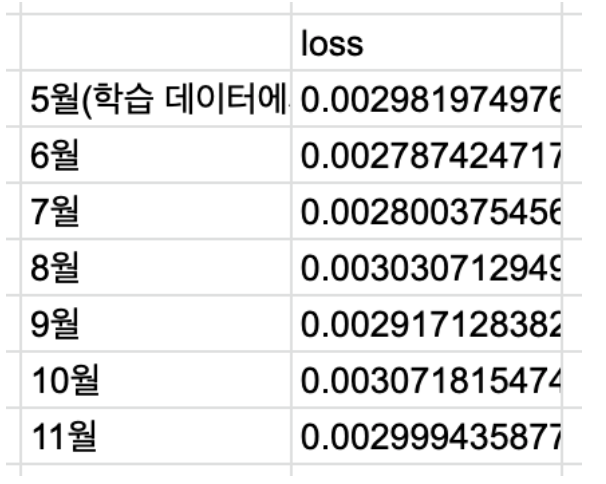
Auto encoder 의 시간에 따른 성능 열화 실험
뉴스 기사의 multi lingual bert emb 를 차원 축소시키는데에 auto encoder를 이용하게 될 예정.model 의 학습에 쓰이는 feature를 정기적으로 재학습 시키고 update하는 과정을 꼭 해야만 할지 알아보기 위해 실험을 진행한다.5월에 학
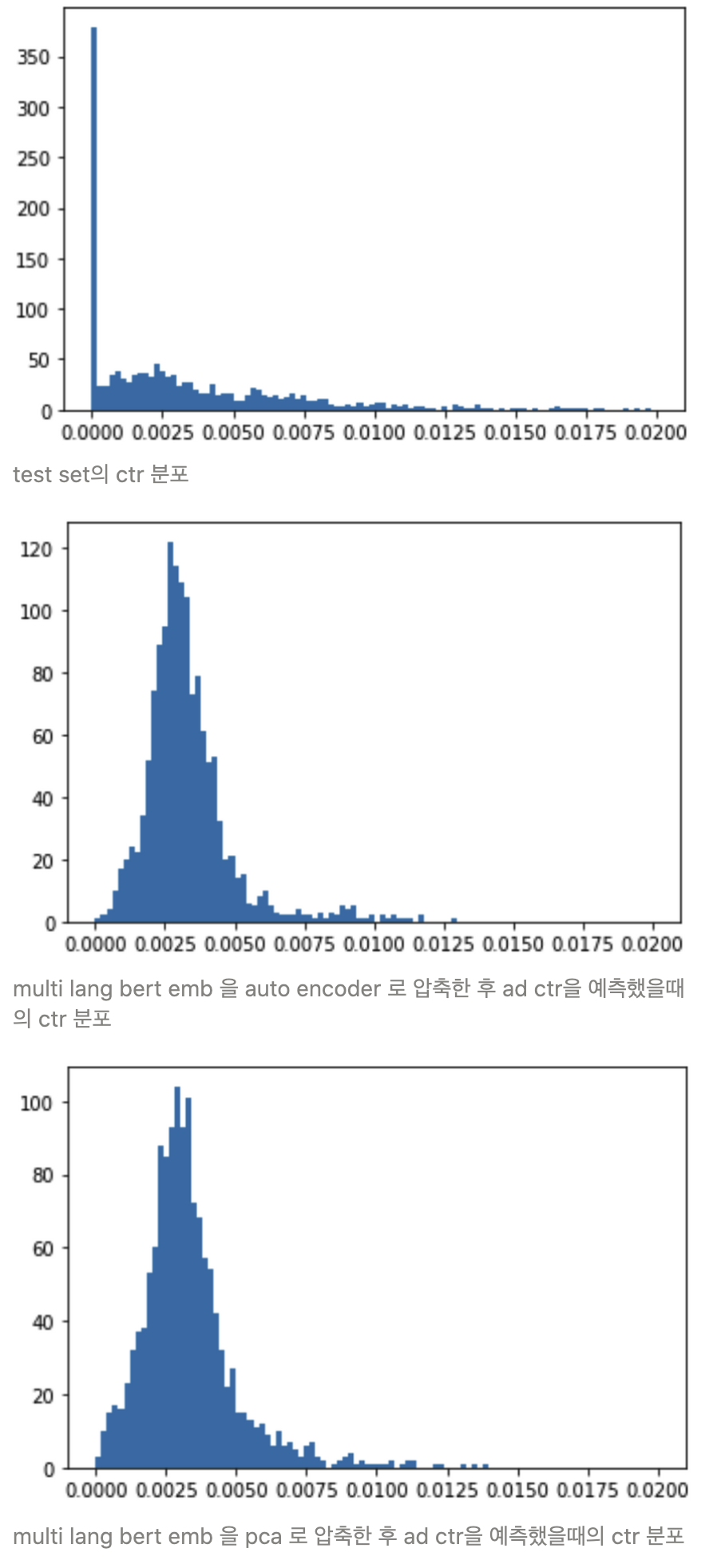
Auto encoder 와 pca 의 차원 축소 성능 비교 실험
model 의 feature 로 뉴스기사 제목과 내용의 embedding 을 사용하고 있다. 이때 768차원의 bert embedding 결과물을 축소할 방법으로 auto encoder, pca 둘 중 어떤 방법이 적절할지를 실험을 통해 비교한다.각 방법으로 차원축소한
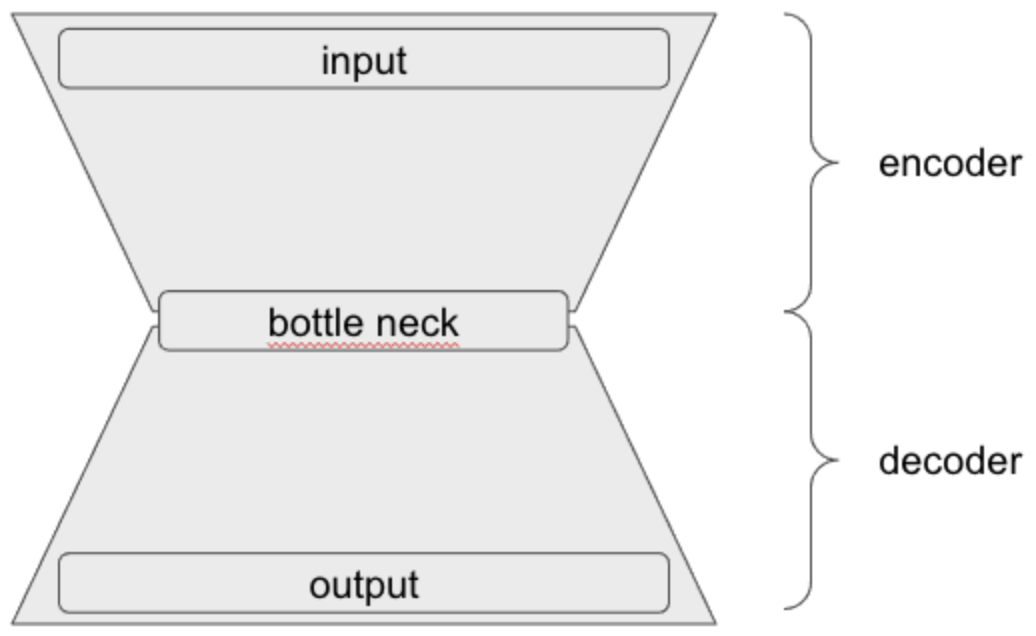
Multi lang bert emb의 auto encoder 압축 실험
Multi-lingual bert 의 차원을 축소시킬 방법으로 auto encoder 를 사용할 수 있을지(loss 값이 줄어드는 등 학습이 잘 진행되는지), 적절한 layer 갯수와, layer dimension은 무엇일지 확인한다.실험결과, auto encoder
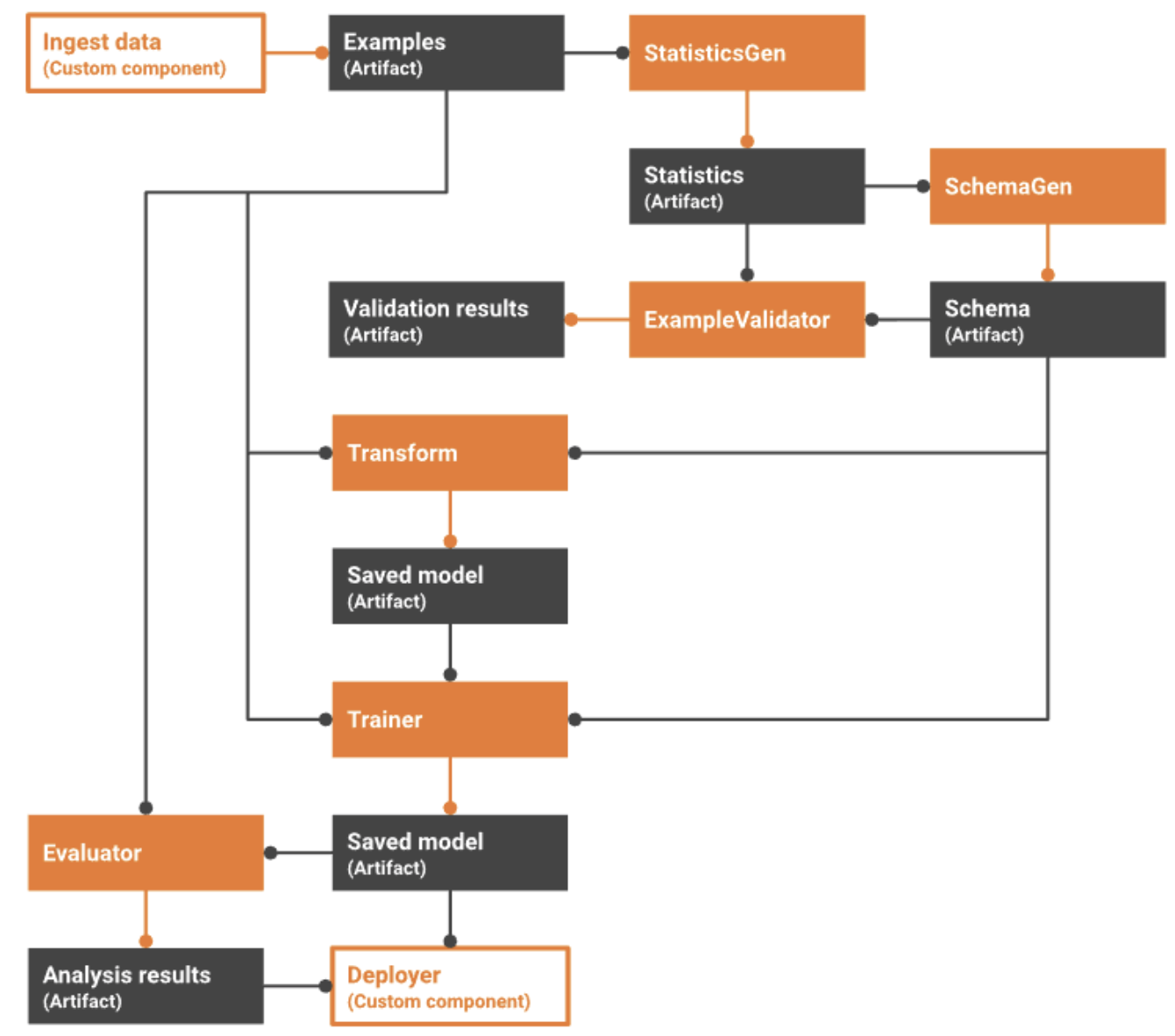
TFX(Tensorflow Extended)란 무엇이고, 어떻게 구성되어있는가
TFX 가 뭐고, 어떤 구성요소, 라이브러리를 포함하는지 확인한다. 또한 우리 시스템에 적용이 가능한 부분이 있는지 확인한다.특히 TFX라이브러리 중 TFT(TensorFlow Transform)부분만 독립형 라이브러리로 사용해본 바 있는데, 아래 네개 구성요소에 대해

[Blockchain] Bitcoin mining process
"새로운 블록과 비트코인이 블록 체인 네트워크 상에 추가되는 과정"채굴자블록 생성 위해서 어려운 수학문제를 푸는데 필요한(해시값을 찾아내기 위한) 네트워크에 컴퓨팅 파워 제공(PoW:Proof of Work)하고 보상(bitcoin 등)을 제공받는다. 이때 블록 생성
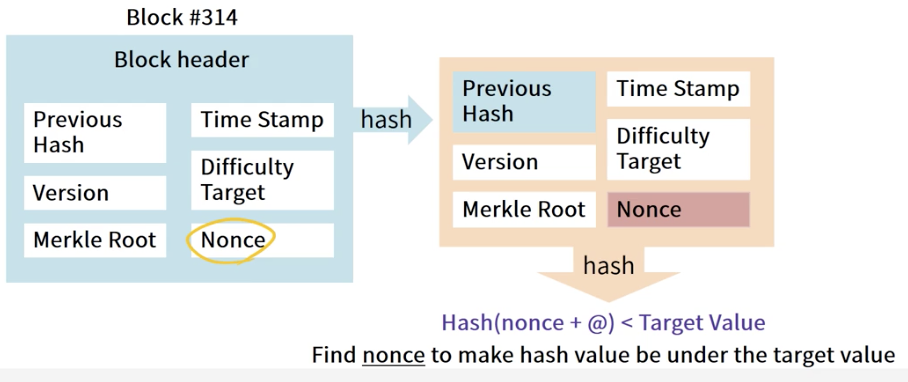
[Blockchain]Bitcoin mining step by step
Detailed mining process 비트코인의 분산화된 합의는 네트워크상의 노드들 사이에서 독립적으로 일어나는 아래의 프로세스에 따라 이루어진다. 모든 full node 가 각 거래에 대해 독립적으로 검증 작업 증명(PoW) 알고리즘을 이용하여, 마이너들

Shap repo 삽질기
개발했던 deep learning 추천 시스템에 shap(https://github.com/slundberg/shap) 을 적용해보았다.이때 발견했던 해당 레포의 문제점들과, 삽질들, 해결과정을 기록한다.아래 내용은 2021년 9월 29일에 적용해보았던 내용으