요약
- model 의 feature 로 뉴스기사 제목과 내용의 embedding 을 사용하고 있다. 이때 768차원의 bert embedding 결과물을 축소할 방법으로 auto encoder, pca 둘 중 어떤 방법이 적절할지를 실험을 통해 비교한다.
- 각 방법으로 차원축소한 item embedding 결과로 ad ctr 예측실험을 했을때에 auto encoder 로 차원축소한 경우 예측 성능이 더 뛰어났다.
- 즉, item 의 multi lingual bert emb 의 차원 축소 방법으로 auto encoder 를 이용하는 것이 더 적절함을 알 수 있다.
실험 목표
- model 의 feature 로 뉴스기사 제목과 내용의 embedding 을 사용하고 있다. 이때 768차원의 bert embedding 결과물을 축소할 방법으로 auto encoder, pca 둘 중 어떤 방법이 적절할지를 실험을 통해 비교한다.
실험 방법
- 뉴스기사 의 multi lingual bert vector 의 차원을 pca 로 축소시켰을때와 auto encoder로 축소시켰을 때의 값을 feature 로 사용하여 각각의 feature 로 뉴스기사에 달린 광고의 ctr 예측을 lgbm으로 학습하여, 예측 성능을 비교한다.
- 즉, pca로 압축한 뉴스기사 feature 로 광고 ctr을 예측하는 lgbm model 을 만들고, auto encoder로 압축한 feature 로 ad ctr을 예측하는 lgbm model 을 만들고, 이 각각의 예측 성능을 비교한다.
- lgbm을 사용하는 이유?
- 현재 서빙중인 모델인 deepfm 을 사용할 수 도 있지만, 이를 학습시키기 위해서는 더 많은 feature 와 더 많은 데이터가 필요하다. 적은 데이터로 빠르게 실험하기 위해서는 더 작고 간단한 lgbm model을 쓰는게 낫다고 판단했다.
- ctr 예측 실험을 구성한 이유
- 이전 실험에서 뉴스기사의 제목과 내용 정보가 광고 ctr에 영향을 미친다는것을 이미 확인했기때문에, 이 feature 를 차원 축소시킨 feature 로 광고 ctr 예측을 더 잘하는 쪽이 더 좋은 차원 축소 기법이라 생각했기 때문.
- lgbm을 사용하는 이유?
각 차원 축소 모델의 학습
- auto encoder
- layer 구성
- 4개 encoder layer 활용 (768 → 64 → 32 → 16 → 5)
- 선행실험에서 좀 더 효율적인 방식이라 확인했던 bottle neck layer 주변에 layer 를 더 쌓는 방식으로 구성
- 학습 데이터
- 100만개 뉴스기사 의 제목과 내용의 multi lang bert emb 결과 활용 ('2021-10-29'~'2021-10-31')
- layer 구성
- pca
- spark ml의 pca 활용
- 학습 데이터는 autoencoder와 동일
ctr 예측을 위한 lgbm 모델의 학습
- 데이터
- 2021-10-31부터 2021-11-04까지의 뉴스기사 중 2021-10-31부터 2021-11-15일간 view 수가 2000회 이상인 item 14016개와 동일기간에서 이 뉴스기사의 광고 ctr 데이터를 학습
- view 2000회 이상이라는 조건을 준 이유는 이런 조건이 없다면 대부분의 뉴스기사의 광고 ctr이 0인 경우가 지나치게 많다. (읽히지 조차 않은 뉴스기사들을 제거하기 위한 룰)
- 10% 는 testing, 나머지 90%는 training 에 활용
- 2021-10-31부터 2021-11-04까지의 뉴스기사 중 2021-10-31부터 2021-11-15일간 view 수가 2000회 이상인 item 14016개와 동일기간에서 이 뉴스기사의 광고 ctr 데이터를 학습
- 비교대상
- 뉴스기사의 제목과 내용을 multi lingual bert로 vector화 한 후 이를 pca 로 5차원으로 압축시킨 feature 를 활용하여 lgbm을 학습
- 뉴스기사의 제목과 내용을 multi lingual bert로 vector화 한 후 이를 auto encoder 로 5차원으로 압축시킨 feature 를 활용하여 lgbm을 학습
- 위의 두 학습 모델의 예측 성능을 비교
실험 결과 확인
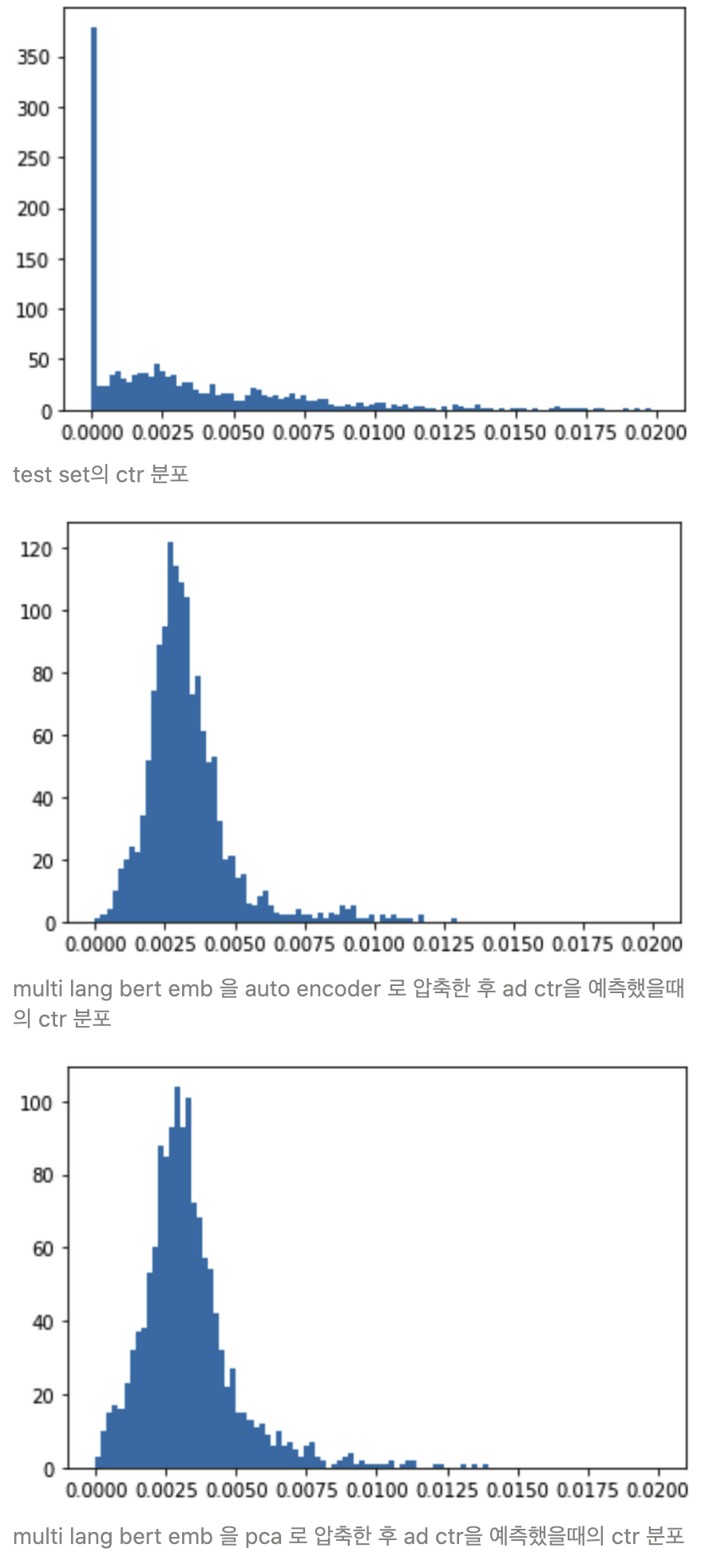
Histogram
- 실제 ctr 값의 분포와, 모델이 예측한 ctr 값의 분포를 비교한다
- (모델이 중앙값만 예측값으로 반환해서 mse 만 낮추고 있을 수도 있기 때문)
- 아래의 히스토그램을 비교해봤을때 문제가 있어 보이는 모델(유사한 값만 계속 예측한다거나, label data 의 분포를 크게 벗어나거나)은 보이지 않는다
- x 축 : ctr, y 축 : 빈도
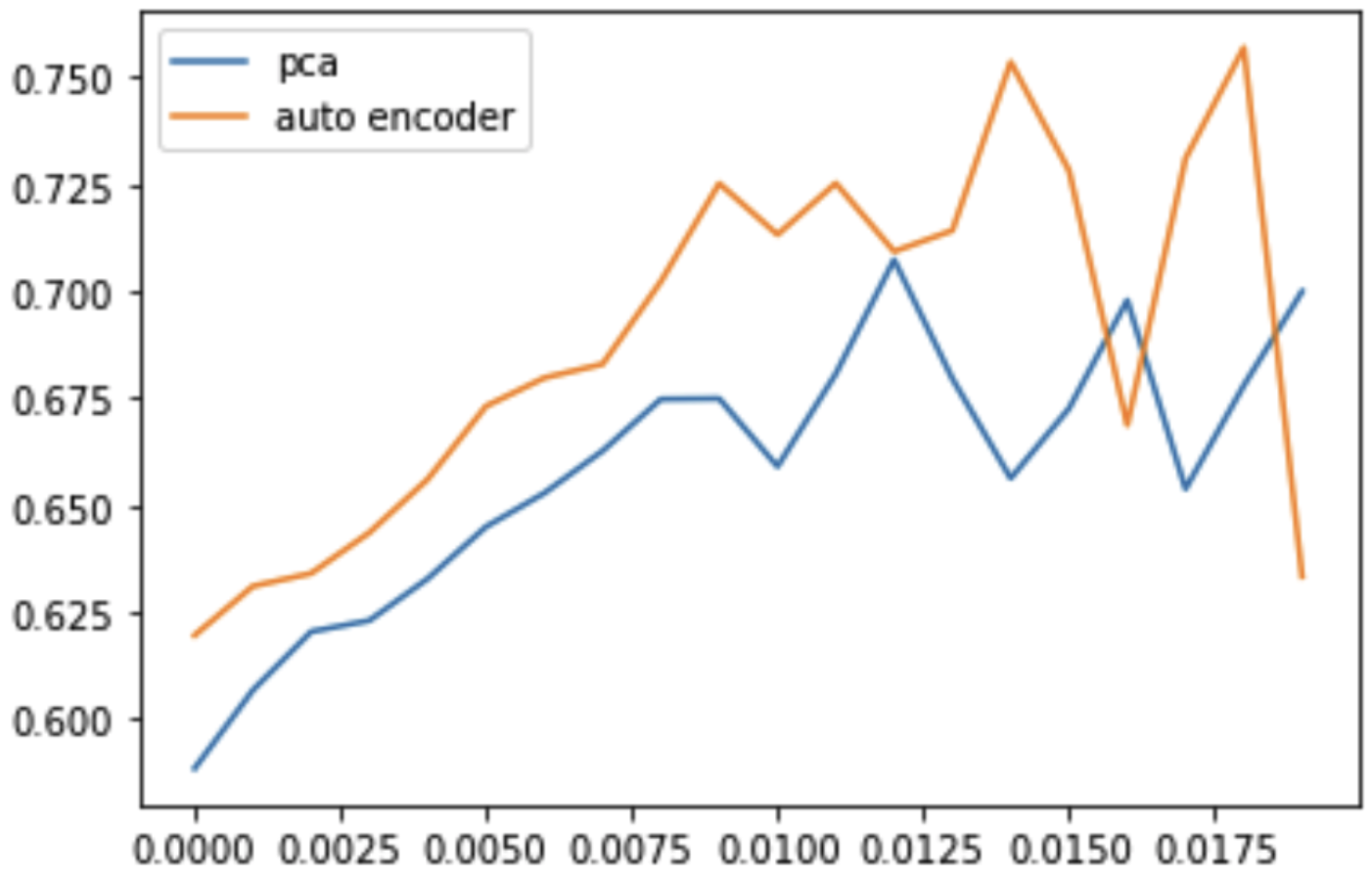
Roc auc score 확인
- 각 모델에서의 구분력을 알아보기 위해 classification에서의 평가기준인 roc auc score 를 적용
- 기준 ctr(regression 결과에서 classification 결과로 해석을 위해 true, false 를 가를 기준 ctr 을 둔다)을 변경하면서, 이때의 roc auc score 계산하여 그래프로 그린다.
- 아래 그래프를 확인해봤을때에 거의 모든 기준 ctr 상에서 차원 축소 방법으로 auto encoder 를 사용했을때에 ad ctr예측에서 더 높은 성능을 보이는 것을 확인할 수 있다.
- x 축 : 기준 ctr, y축 : roc auc score

data scientist
안녕하세요. pca 연구중인 학부생입니다. autoencoder는 구현했는데 pca를 구현하지 못해서요 ㅠㅠ 혹시 코드도 함께 알려주실수 있으실까요??