[paper review] Bandit based Optimization of Multiple Objectives on a Music Streaming Platform

본 글에서는 KDD 2020, 스포티파이에서 발표한 논문을 요약해보았다.
이 논문에서는 Bandit 알고리즘을 multi objective 문제 해결에 사용할 수 있는 방법을 제시하고 있다.
언제부터인가 추천 시스템에서 bandit을 활용한 논문들이 싹 사라져버렸다. ㅠ 그럼에도 bandit은 streaming 에 쉽게 활용할 수 있고, cold start 문제에 적용하기도 비교적 쉽기에, 이 연구를 발견했을때에 매우 반가웠다. :)
Abstract
온라인 추천시스템의 경우 multi-stakeholder 의 objective 를 만족시켜야 하는경우가 종종 있다. 예를들어 아래와 같은 경우를 들 수 있다.
- 구매자와 판매자를 모두 만족시켜야하는 amazon
- guest 와 host 를 모두 만족시켜야하는 airbnb
- rider 와 driver를 모두 만족시켜야하는 uber
- listener와 artist를 모두 만족시켜야하는 spotify
이 논문에서는 contextual bandit 을 multi objective setting 으로 확장시켜서 multi-stakeholder를 만족시키는 추천 시스템을 만드는걸 목표로 한다.
기본적으로는 contextual bandit 세팅하에서 여러개의 objective 를 동시에 공정한 방식으로 학습하는데, 알고리즘 진행은 아래의 두 과정으로 요약할 수 있다.
1. GGI(Generalized Gini Index) 라는 aggregation function이용해서, 여러개의 objective 를 결합함과 동시에 밸런싱한다.
2. online gradient ascent learning algorithm 사용해서, GGI 로 scalarise된 objective들에 대한 reward vector를 최대화 시킨다
Introduction
intro는 이 안에 있는 몇문장으로 요약이 가능하다.(어차피 내용이 뻔해서,,, 해석까지는 안해둬도 될듯 ㅎㅎ)
- We propose a multi-objective formulation of a contextual bandit based recommender system.
- We propose a multi-objective contextual bandit model based on Generalized Gini Index (GGI) by introducing a model that assimilates contextual information and optimizes for a number of different, including competing objectives
- The goal of the proposed GGI based optimization is to be both efficient, i.e., minimize the cumulative cost for each objective, and fair, i.e., balance the different objectives
- We propose an online gradient ascent method to maximise a scalarisation of the accumulated reward over several objectives.
- Experiments with multiple user-centric objectives suggest that optimizing for multiple interaction metrics performs better for each metric than optimizing single metric. Beyond multiple user-centric objectives, experiments around adding promotional objectives (e.g. gender promotion) demonstrate that the platform can obtain gain in such promotional-centric or supplier-centric objectives without severe loss in user centric objectives.
Background and Related work
Multi objective Optimization
- 전통적인 MOO(Multi objective optimization) 방식은 Pareto front 를 바로 찾아내는걸 목표로 한다.(Pareto front line 을 그어서, 여러 objective 모두에서 손해를 보지는 않는 포인트를 찾아내는 방식)
- 이 외에는 aggregation function 등을 활용해서 vector 형태의 objective(여러 objective)를 scala 화 해서 최적화 시키는 방식 등이 있다.
(aggregation function 에는 weighted sum 이나 regularized maximin fairness policy 등이 있을 수 있음) - 이 논문에서는 위에서의 두 번째 방식인 aggregation function을 이용하는 방식을 취하는데, 이때에 generalised Gini function을 이용하고, 이 방식은 total ordering과 선형적 우선순위 모두에 대해서 일반화를 잘 시킨다고한다.
- MOO 를 supervised learning 방식으로 해결했던 과거 접근법과 달리 이 논문의 방식에선 더 interactive하고, user feedback 을 기반으로 adaptive 한 learning이 가능한 방식에 초점을 맞췄다.
MOO in Search & Recommender system
- recommendation에서의 MOO를 시도했던 예시로 collaborative filtering의 확장 또한 포함될 수 있을 것이다.
- 기존 방식과 이 논문에서 소개한 접근 방식의 주요 차이점은 밴딧기반 세팅에 초점을 맞췄다는 점인데, 그런만큼 item 간의 유사성 정보가 불확실 하거나, 새로운 item 이 들어왔을때에 더 큰 힘을 발휘한다.
Bandits & Multi-objective Bandit
- Multi objective multi-armed bandit, multi-objective variants of contextual bandit들에 대한 연구는 최근 주목을 덜 받고 있는 편이다.
- 요즘 주목받는 연구들은 그 대신 item 간의 유사성 정보(item similarity)가 이미 있다거나, objective 가 여러개더라도 dominant 한 하나가 있는 상황을 가정한 경우가 많은데, 실제 비지니스 현장에서는 이런 상황들은 많지 않다.(특히 사용자 행동 데이터를 기반으로 reward를 도출해야하는 상황에서는 더 그렇다..)
Objectives & stakeholders
Objective Definitions
- 이 논문은 spotify에서 작성된 만큼, 유저의 음악 스트리밍 상황을 가정한다. 두 가지 objective를 목표로 둔다.
- user centric objectives
- stream : 유저의 음악 스트리밍 시간
- clicks : 플레이 리스트 클릭 수
- songs played : 재생한 음악 수
- two artist and platform centric objectives
-
Diversity : 추천된 set 에서의 gender 다양성
-
promotion : platform 에서 promotion 하고자 하는 아티스트의 음악의 수
-
위 objective 들을 보면 일부를 최적화 하는게, 다른 objective 에 좋지 않은 영향을 줄 수 있도록 설계되었음을 알수 있다.
-
이런 서로 상충되는 objective 들 간의 미묘한 밸런스를 맞추는 것에 이 알고리즘도 주안점을 둔다.
Contextual Bandit based Recommendation

-
다른 여타 Contextual Bandit algorithm 처럼 이 알고리즘에서도
- context feature 들을 관찰하고
- 이 feature 들이 의해서 k개의 가능성들 중 a라는 action을 선택할 수 있게 되는데
- 주어진 context와 action에 대한 reward가 분포로서 주어지게 될 것이고, 이에 따라 action을 결정할 수 있게 될 것이다.
-
위의 과정에서 이 논문에서는 아래의 feature 들을 활용했다.
-
Context feature:
- (i) user: 나이, 성별, 사는 지역, 장르 선호도
- (ii) playlist: 아티스트, micro or macro 장르, diversity, 인기도 등
- (iii) affinity between the user and the playlist: user와 playlist 사이의 과거 interaction 들(streams, skips, likes, saves)
- (iv) 그 외... (the day of the week and the time of day)
-
Actions: selecting a set to recommend to the user.
- 사용자에게 playlist(a collection of tracks)를 제공하는 세트 기반 추천
- 각 트랙은 특정 아티스트로 구성
-
Rewards:
- 전통적인 user-centric system 이라면 user들이 얼마나 이 추천을 좋아했는지를 확인할테지만,
- 이 논문에선 multi- stakeholder recommender system을 지향하기에, reward function에서도 vectorial rewards에 대해서 최적화시킨 arm 이 선택되는 방식을 취한다.
Multi-objective Contextual Bandit
arm selection strategy
-
다른 bandit 알고리즘이 그렇듯, 아래처럼 arm selection 함수를 정의할 수 있다.

- alpha : arm 선택여부 / 뮤 : k번째 arm 선택시의 reward
- G : scalarisation function (여기서는 GGI 쓴 것이고, 이에 대한 설명은 아래에 있다!)
-
GGI (Generalised Gini Index)
- (본인은 이 함수를 처음 봤는데, 대충 1981년에 쓰여진 논문에 등장하고 있는걸로 확인했고, 그 특성에 대해서만 아래처럼 알고 있으면 될듯하다...)

- 𝜎 permutes the elements of 𝒙 such that (𝒙𝜎 )𝑖 ≤ (𝒙𝜎 )𝑖+1
- GGI 자체는 좀 생소하지만, 아래와 같은 속성을 갖는 인덱스이기때문에 여기서 활용이 가능하단걸 알 수 있다.
- GGF는 strictly monotonic하기때문에, 이 함수를 maximize시킨 지점이 pareto front(여러 objective 에 대한 최적의 해 중 하나에 해당하게 됨) 에 존재하되, weight 에 따라서 다른 지점의 점을 선택하게 된다.- GGF exhibits afairness property under the Pigou-Daltontransfer: if 𝒙𝑖 <𝒙𝑗, then 𝐺𝒘(𝒙′)>𝐺𝒘(𝒙) for 𝒙𝑖′=𝒙𝑖+𝜖 and𝒙′𝑗 =𝒙𝑗−𝜖 where 𝜖<𝒙𝑗−𝒙𝑖 and 𝒙𝑘′ =𝒙𝑘 for𝑘≠𝑖,𝑗.In other words, an equitable transfer of an arbitrarily small amount from a larger component to a smaller component is always preferable.
- -> 이 말에 대해서 완벽히 해석하긴 좀 어려워서 일단 본문을 가져왔다... 그치만 대충만이라도 요약을 하자면 이 함수는 Loss 가 높은 objective에 더 weight를 많이 주어서 더 많이 고려하여 업데이트 하면서도, 전체 objective 들에 대해서 공평하게 aggregate 를 해준다는 의미 인것으로, 여러 objective를 공평하게 스칼라화할때에 이 function을 쓰는게 유효하다는걸 강조하는 내용인걸 알 수 있다 ㅎㅎ
- GGF exhibits afairness property under the Pigou-Daltontransfer: if 𝒙𝑖 <𝒙𝑗, then 𝐺𝒘(𝒙′)>𝐺𝒘(𝒙) for 𝒙𝑖′=𝒙𝑖+𝜖 and𝒙′𝑗 =𝒙𝑗−𝜖 where 𝜖<𝒙𝑗−𝒙𝑖 and 𝒙𝑘′ =𝒙𝑘 for𝑘≠𝑖,𝑗.In other words, an equitable transfer of an arbitrarily small amount from a larger component to a smaller component is always preferable.
-
Regret 을 정의하는 과정
- (arm selection strategy에서) 시점 t에 얻을 평균 reward
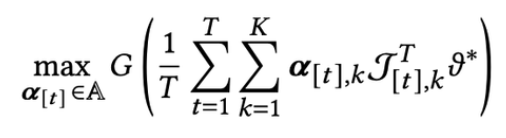
- T시점에서의 regret은 아래처럼 정의 가능함
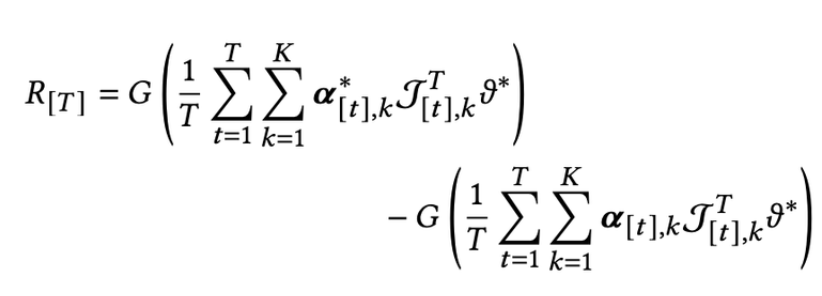
- (arm selection strategy에서) 시점 t에 얻을 평균 reward
-
regression으로 풀수도 있겠으나, matrix 가 커지면 쉽지 않을 것
- First estimate parameter 𝜗∗ via 𝑙2-regularised least-squares regression with regularisation parameter 𝜆 > 0 at each round 𝑡 ,:

- First estimate parameter 𝜗∗ via 𝑙2-regularised least-squares regression with regularisation parameter 𝜆 > 0 at each round 𝑡 ,:
-
Online gradient ascent
- 아래를 최대화시킬 alpha를 찾는 방식으로 문제 해결
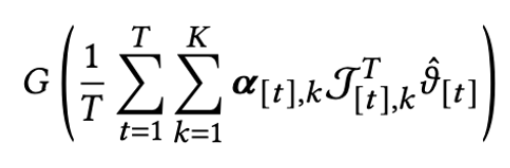
- GGF의 concave 성질에 따라서 아래처럼 풀 수 있고,
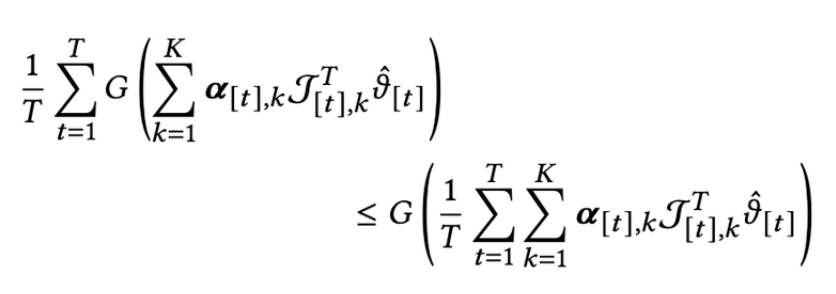
- 이걸 optimize시켜도 되지만,
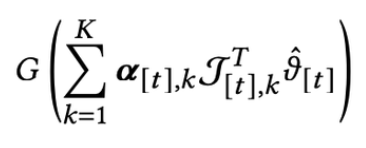
- 근데 위의 것을 linear programing으로 풀면 계산량이 많아서 아래처럼 gradient ascent로 풀 수 있음.
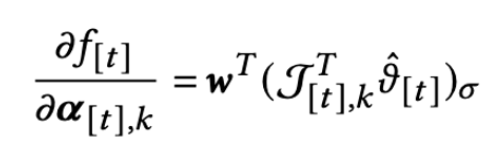
- 아래를 최대화시킬 alpha를 찾는 방식으로 문제 해결
Experimental evaluation
(이 논문에서 실험 분석할때에 그래프 형태가 아주 신박하다. 실무에서 활용해볼 기회가 있길!)
Reward base evaluation

- 이 실험에서는 다양한 bandit 알고리즘에 GGF 로 정의한 reward를 넣었을때에 어떤 알고리즘이 reward를 가장 잘 최적화 시키는지를 확인한다. 위의 그래프에서는 아래의 세가지를 확인할 수 있다.
- MO-OGDE(Non contextual bandit)와 random strategy 간 비교를 했을때엔 둘의 결과가 다르지 않았다는 걸로 봐서, context 가 중요한 역할을 한다는 걸 알 수 있다.
- mixed strategy(아마도 thompson sampling 등 sampling 기반 선택을 하는 알고리즘?) 가 pure strategy(아마도 항상 max 값을 고르는 greedy 한 알고리즘?) 보다 항상 결과가 좋았던걸로 보아서, greedy 한 선택보다는 probability distribution을 바탕으로 선택하는게 더 좋다는 걸 알 수 있다.
- 여러 알고리즘 중 MO-LinCB에서 GGF가 가장 잘 최적화 된다.
Optimizing for multiple user metric
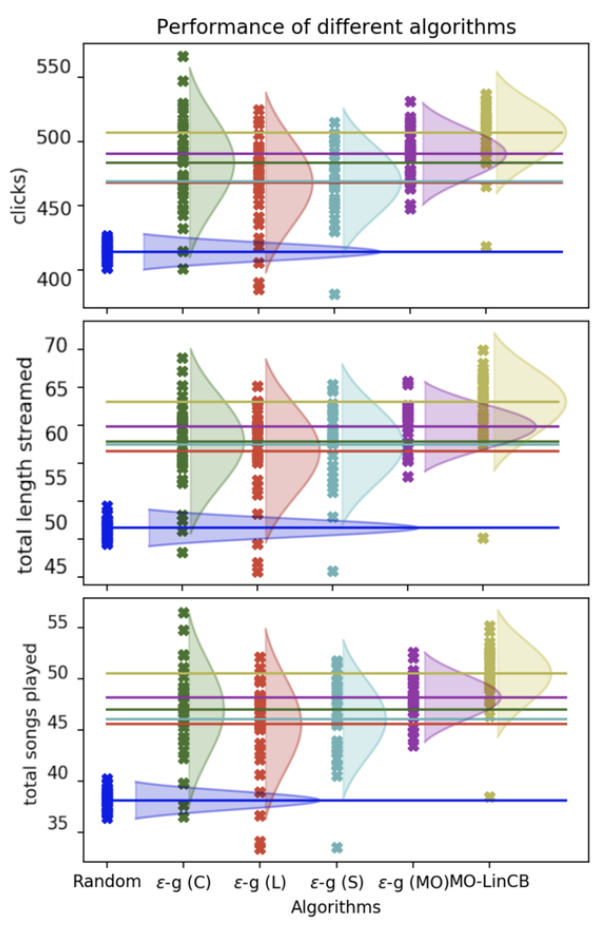
- 유저 메트릭(clicks, stream, songs played)관점에서 봤을때에 각 알고리즘을 비교해보면 세가지를 알 수 있다.
- 위 그래프에서 e-g(c), e-g(l), e-g(s)는 각각 click, length of stream, songs played의 한가지 메트릭만 최적화 시킨 single objective algorithm인데, 이 들 셋 중에서 비교를 해보면 click에 대해서 최적화시킨 알고리즘(e-g(c))이 세가지의 모든 메트릭에 대해서 다른 알고리즘에 비해 우위를 보인다는걸 알 수 있다. 이로써 click 이 feature 로서 강력하며, 다른 objective 들과의 상관성 또한 크게 있음을 알 수 있다.
- 모든 메트릭에서 single objective algorithm(e-g(c), e-g(l), e-g(s)) 보다 objective algorithm(e-g(MO), MO-LinCB)의 성능이 항상 더 좋았다.
- 하나의 정보에만 집중해서 학습시키는 것 보다 여러가지의 정보를 혼합해서 좋았을때에 더 효과가 있음을 알 수 있었다!
- MO-LinCB 알고리즘의 성능이 가장 좋았다.
Impact of Promotional Objective
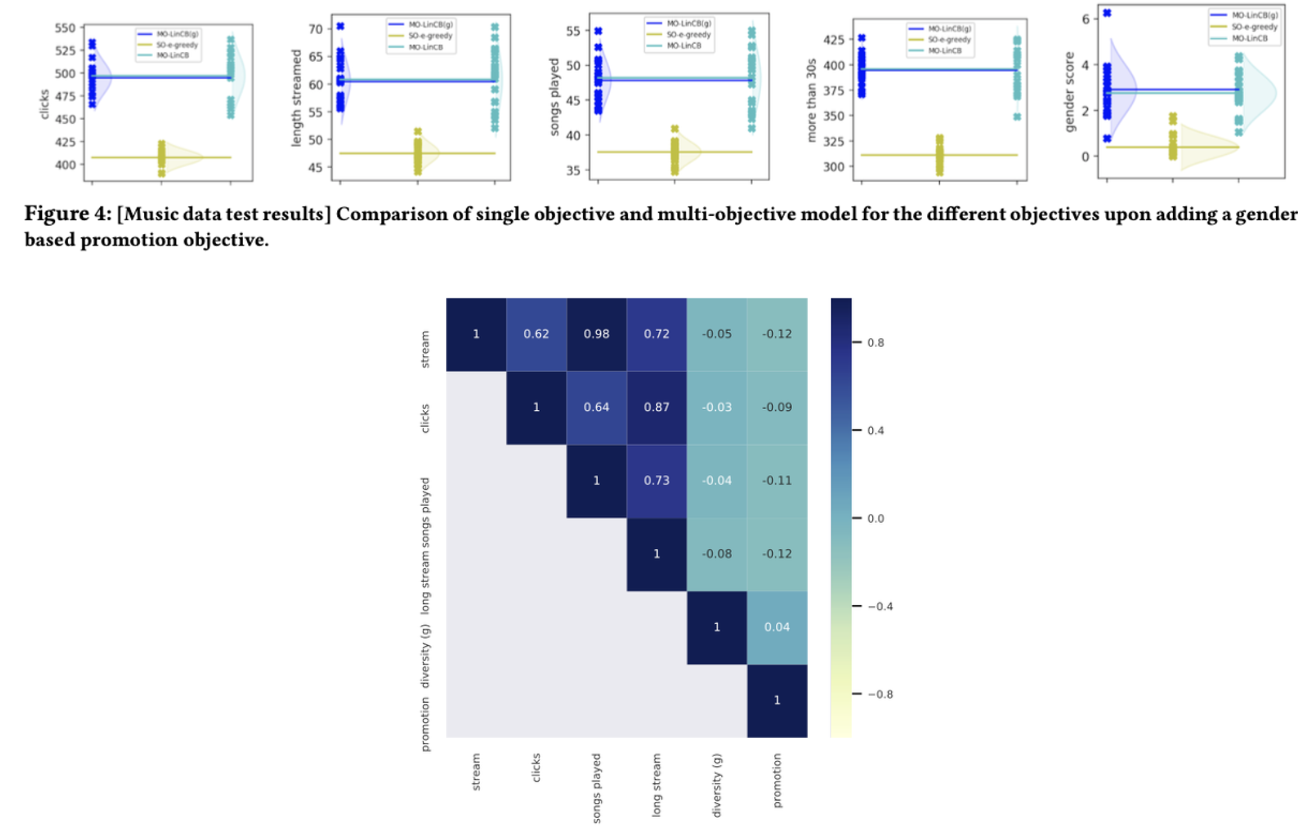
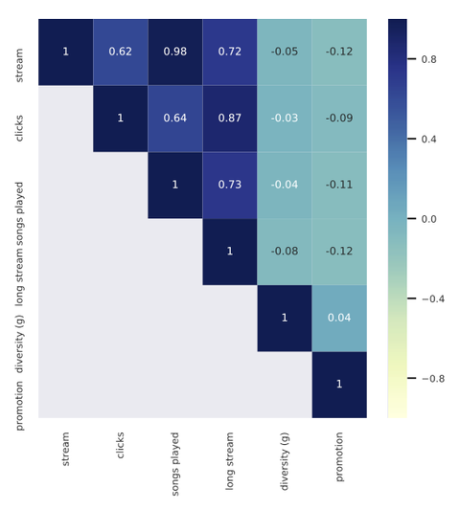
- promotional objective 는 다른 object 들과의 상관관계가 없음을 위의 히트맵으로 확인할 수 있었는데, 이건 objective 들간 competing이 생길 수 있다는 것을 의미하기도 한다.
- 그러나 promotional objective(여기서는 gender diversity) 를 포함시켰을때에, 다른 수치들이 떨어지지 않는다는게 보여서, 상반된 objective 간의 zerosum 게임이 아니라는 것을 확인할 수 있었다.
Comparing Multi-optimization Methods

- 아무 알고리즘에서나 MO 가 통하지 않음을 확인함
- e-greedy 는 MO해도 성능이 나아지지 않음
