"OpenAI API 마스터하기: GPT-4의 무한한 창의성 끌어내기"
ChatGPT API, Whisper, 임베딩, DALL-E 에 대해 배우면서, 프롬프트 엔지니어링을 체험해 볼 수 있는 강의라기에 시도해보았다.
api를 활용한 다양한 예제들을 보여주고 있어서, open ai github readme등을 읽으며 사용법을 익히는 것보다 활용에 대한 아이디어를 떠올려보는데에 많은 도움을 주고 있는 것 같다.
첫번째 섹션에서는 open ai 의 약력부터, gpt에 대한 간단한 개요, 트랜스포머에 대한 소개, 계정 생성하는 부분까지로 이어지는데, 여기까지 본 강의 내용을 요약해보았다.
Open ai 약력
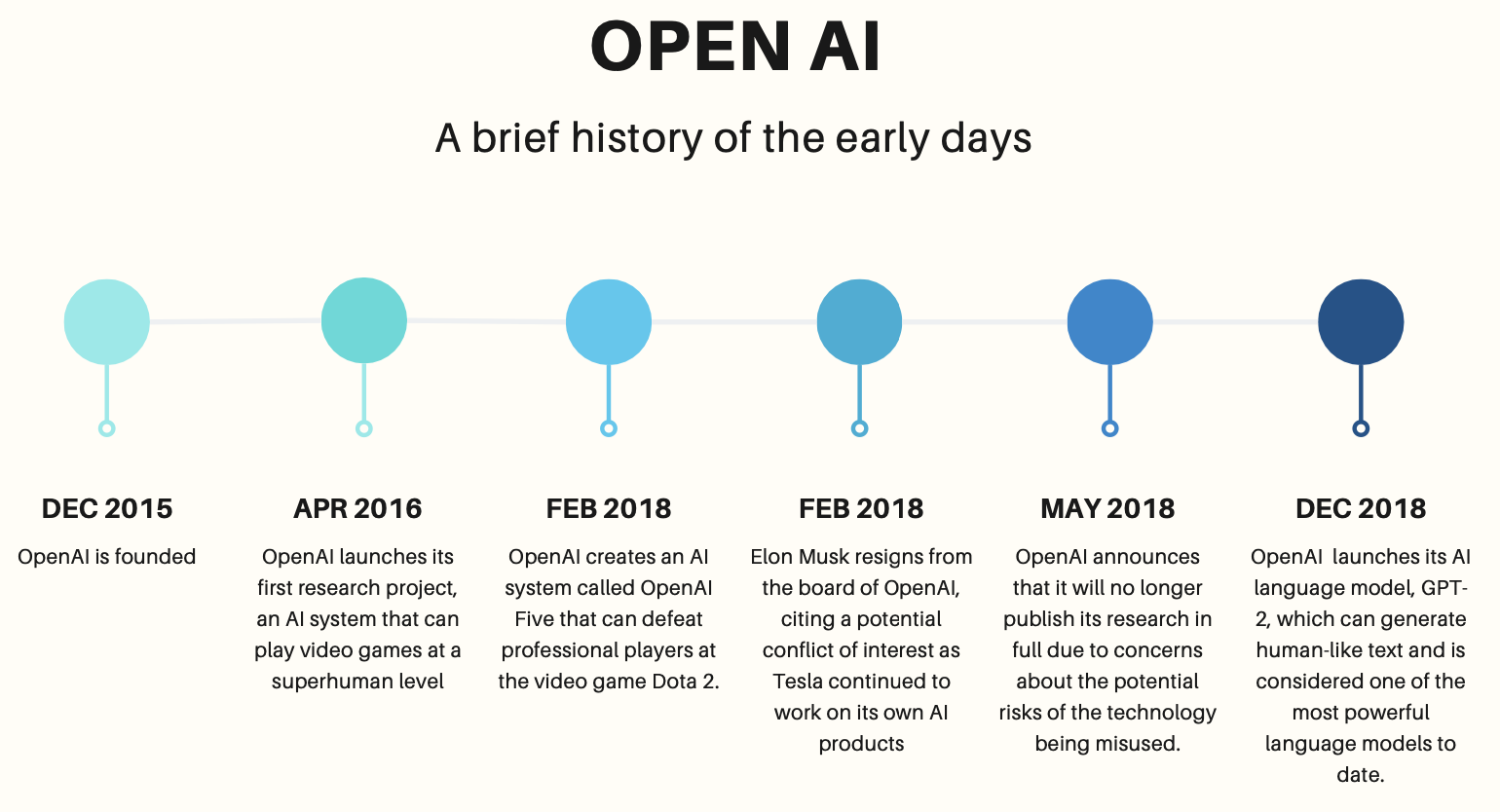
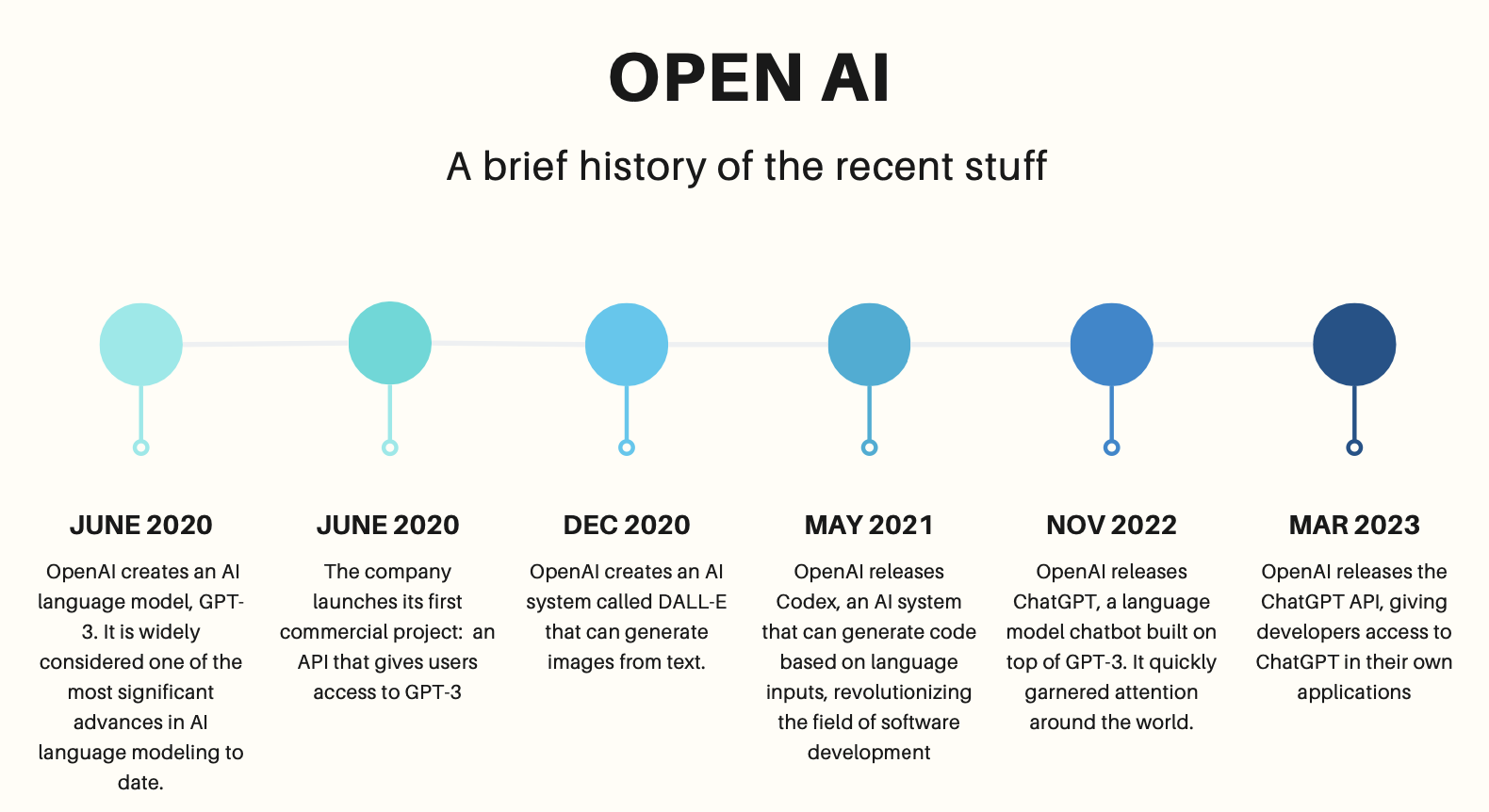
2015년 연구만을 위한 비영리단체로, 일론머스크를 포함하여 아주 유명한, 몇몇 개인의 투자로 설립되었다. 처음 설립된 이래로 내 주변 사람들 모두 저 저 회사가 얼마나 오래 비영리 단체로 유지될 수 있을지 의심하고 있었는데, 일론머스크 이탈, 산하에 영리단체 신설, 2020년 gpt3 api 를 유료 형태로 open 등의 결국은 어느정도 수익화하는 모습이었고, 그 이후로 DALL-E(generate image from text), Codex(generate code based on language input), chat GPT 를 잇달아 공개했다.
일부 영리 프로젝트가 있기는 하지만, 여전히 open ai 자체는 비영리 단체로 유지되고 있다. 그러나 2021과 2023년에는 마이크로소프트에서 추가 투자를 받으면서 GPT-4 지적재산권 라이센스와 기타 제품 상용화 독점계약을 얻어서, GPT4까지는 마이크로 소프트 소유라고 생각해도 되지 않나 싶다.
GPT와 prompt
- Generative Pre-Trained Transformer
- 생성형 language model 이라 initial text 를 주면 그 다음에 이어질 text들을 생성해내는 방식으로 사용할 수 있으며, 이때의 initial text를 prompt라고 부르고, 이 prompt를 잘 생성해내는 과정을 prompt engineering 이라고 한다.
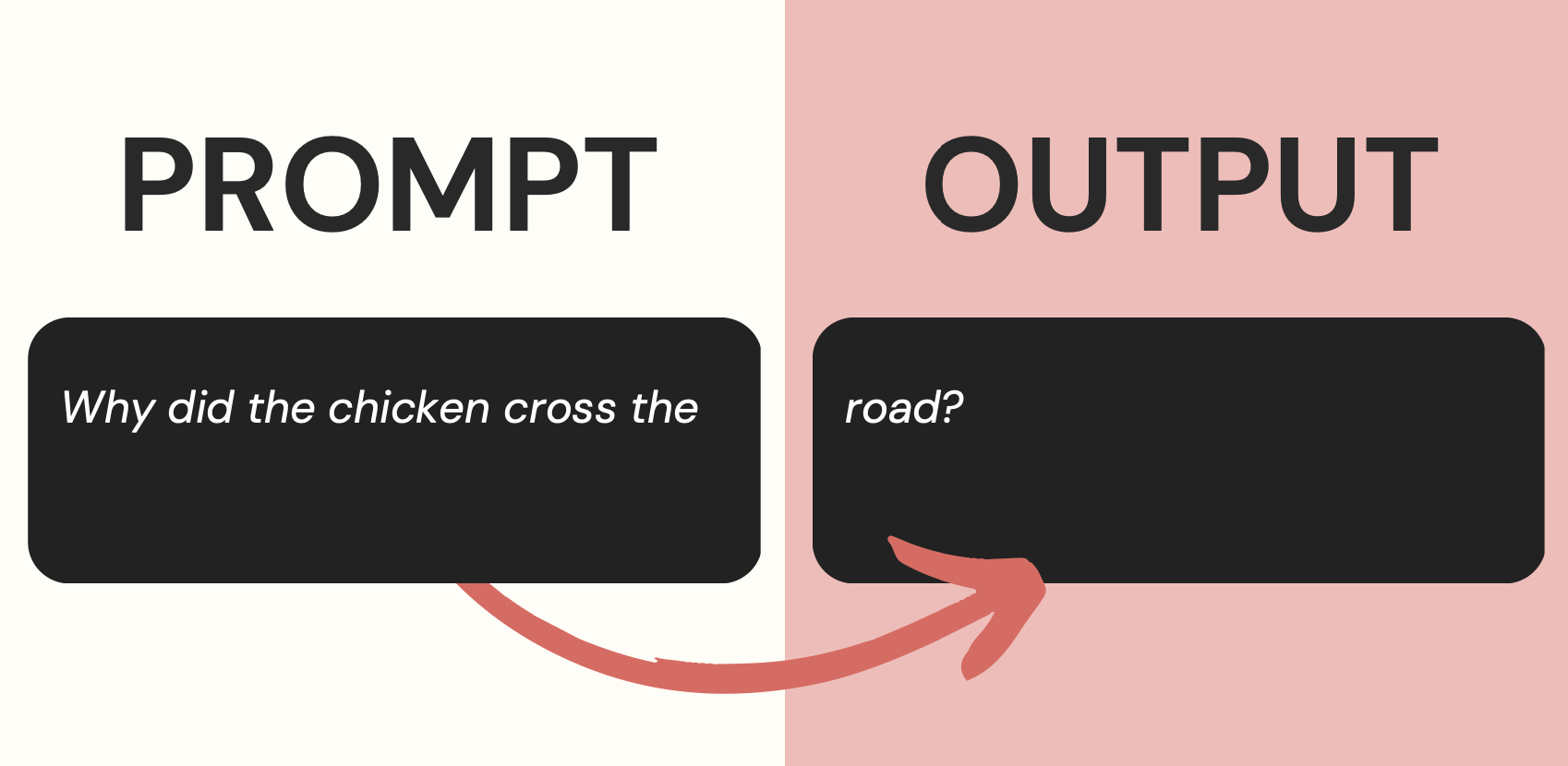
- gpt 와 상호작용하는 방법은 크게 아래의 두 가지라고 볼 수 있다.
- completion : 하나의 text prompt를 주는 방식(Expects a single text prompt)
- (gpt4는 미지원)
- chat : chat based format 으로 message 의 list를 주는 방식(Expects a list of messages in a chat-based format)
- completion : 하나의 text prompt를 주는 방식(Expects a single text prompt)
Transformer 란
- Neural network 를 구분하는 방법이 여러가지가 있을텐데, 여기서는 CNN, RNN, Transformer 로 구분짓고, 있다.
- Natural language 에 대한 연구가 처음 시작될때에는 RNN을 기반으로 했었는데, 여기엔 여러 단점이 있었는데,
- token을 하나씩 순차적으로 인식하다보니, 분량이 긴 텍스트는 분석이 어렵다는 점이 있었고,(gradient banishing)
- 속도가 느려서 많은 데이터를 학습시키기가 어렵고,
- 순차적으로 처리되다보니, 병렬화가 불가능했다.
- 이런 단점을 극복하고자 transformer가 등장했는데, 이 경우
- 전체 input을 순차 처리 하지 않다보니, (텍스트를 순차적으로 인식하는 대신 positional encoding을 이용한다) gradient banishing 문제가 사라졌고,
- 병렬화 또한 가능해졌다

positional encoding
- 순차 처리할 필요가 없어지고(위치를 encoding 해서 이미 알고있기때문에!)
- 어순의 중요도를 파악하는 역할을 해줄 수 있다.
attention
- 입력 데이터의 특정 부분에만 선택적으로 주의를 기울이는 방식으로, 입력 데이터 각 부분에 어텐션 점수를 매겨서 요소들의 가중치나 평균값을 구하게 된다.
- 이렇게 어디에 집중해야할지를 모델에 배우는게 가능지면서, 데이터가 충분하면 문법, 어순, 시제 동사 등의 언어 작동원리를 알아서 파악하는게 가능해졌다!
- attention 자체는 이미 sequence to sequence model 에서 등장했던 바가 있고 (이건 large language model 이 나오기 이전의 일이다... ㅎㅎ 옛날 같지만 별로 안됐다ㅠ), 인코더가 해당 단어를 vector 화 한 결과는 디코더가 그 단어를 예측할때에 쓰는 vector 와 같을거라는 가정에서, 각 출력에 대응되는 입력상태를 더 많이 참조하도록 가중치를 주자는 컨셉에서 등장했다. (이전에 til 하면서 정리를 했었...)
- 2018 년 cmu의 nlp 강의를 들으면서 요약했던 자료도 있는데,,, 이것도 꼭 다시 정리를 해놔야겠다... ㅎㅎ 과거의 업보가 많다...
open ai 계정
- chat gpt 를 써봤어서, 이미 계정은 있었다.
- platform.openai.com의 document 페이지에서 쓸 수 있는 api 들은 다 하나씩 찾아볼 수 있고
- api key 페이지에서 secret key 를 생성해야한다. 여기서의 key를 복사해서 보관하고 있어야 계속 쓸 수 있다.
- api document 에서 pricing도 확인할 수 있는데, 무료인 api는 하나도 없다... 카드 등록해두고, 한달에 쓰는 돈의 limit 을 꼭 걸어놔야 한없이 빠져나가지 않는다 ㅎㅎㅎ
create text project
- pip install openai 로 필요한 모듈을 설치할 수 있는데, 강의가 만들어진 이후에 업데이트가 꽤 많았던 건지,,, 강의에 나온 create text project예제로 나온 코드를 그냥 실행시키면 실행이 안된다. (pip 할때에 version을 1.0 이하로 지정해두거나, 아니면 새 버전 방식으로 콜해야한다)
