[paper review] Recommending What Video to Watch Next: A Multitask Ranking System
abstract
- '다음 볼 영상'(youtube) 추천을 위한 large scale multi objective ranking system 제안함
- multi task learning 방식을 제안했는데, ctr 뿐 아닌, 좋아요, 공유 등 multiple competing ranking objectives 가 동시에 존재하는 현실의 상황을 해결하기 위한 것임.
- 방식
- Multi-gate Mixture-of-Experts 방식을 Wide & deep model 에 적용하고 selection bias 완화를 위한 shallow tower를 제시함.
- soft-parameter sharing techniques(such as Multi-gate Mixture-of-Experts) 을 통해서 여러 objective를 고려한 ranking을 하는 방법을 제시함.
Introduction
- 시장에서 자주 문제시 되는 '상충 되는 목표에 대한 최적화'를 달성하기 위해 multi task learning 을 이용함.
- 상충되는 목표 최적화가 필요한 경우의 예 : 영상 재생율 뿐 아니라, 사용자들이 높게 평가하고 친구들과 공유하는 동영상을 추천하고 시청하기를 원하는 경우.
- 시스템에 종종 존재하는 내재적인 편향을 "shallow tower" 라는 방식으로 제거하고자 함.
- 내재적 편향의 예시 : 사용자가 비디오를 클릭하고 시청한 이유가 단순히 높은 순위에 있었기 때문이며, 사용자가 가장 좋아하는 것이 아니었을 수 있음.
- 평가 방식
- multitask learning 자체에 대한 평가
- position bias가 제거 되었는지 평가
Model architecture
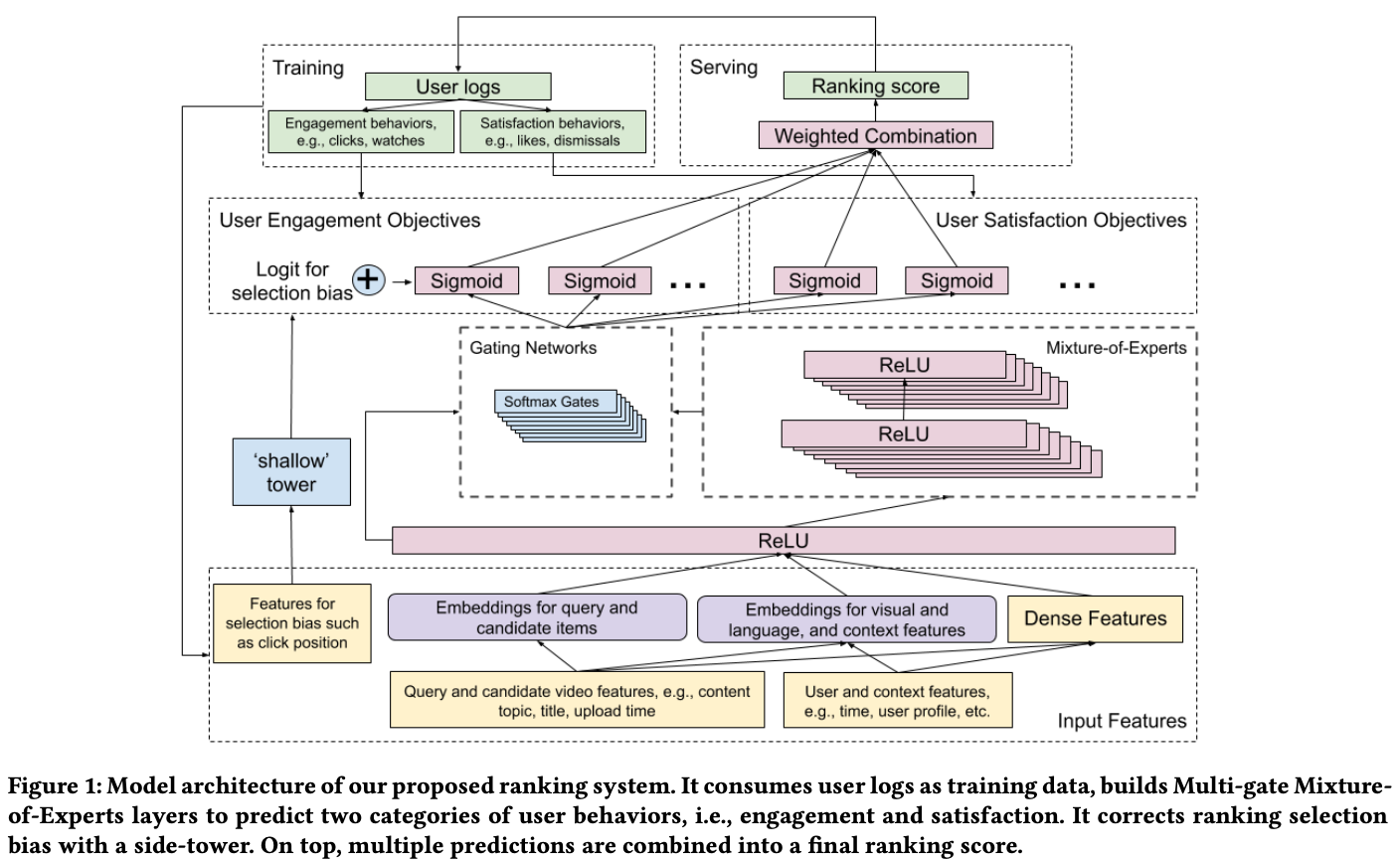
Ranking objectives
- 유저의 행동을 아래의 두 가지 기준으로 나눠서 objective 로 설정함.
- Engagement objectives
- e.g. 클릭, 시청
- binary classification task(click) 나 regression task(시청 시간)으로 설정
- Satisfaction objectives
- e.g. 좋아요 클릭, 별점
- 동일하게 objective 성격에 따라 binary classification task(좋아요 클릭) 나 regression task(별점 수)으로 설정
Modeling Task Relations and Conficts with Multi-gate Mixture-of-Experts

- 과거의 deep learning 을 이용한 multi task learning task 는 좌측과 같은 구조를 이용한다. 그런데 이때 자주 발견됐던 단점이, 두 objective 중 적어도 하나는 single task 로 학습시켰을 때보다 결과가 좋지 않았다. 아마도 서로 다른 objective 에만 기여할 feature 들이 간섭을 하게 되면서 오히려 성능이 떨어진 걸로 보인다.
- 최근 연구에서 이런 단점을 해결해 줄 방안으로 MMoE(Multi-gate Mixture of Experts) architecture 가 제시되었다. 이는 우측의 그림에서처럼 shared bottom layer 위에 expert layer 를 위치시키고, 이 expert layer 의 out connection 을 바로 task layer 로 연결시키지 않고, softmax gate 를 통해서 연결시킨다. 이를 통해 shared bottom을 이용할때 처럼 쓸데없는 정보가 서로 다른 objective에 관여하여 성능이 저하되는 현상을 막을 수 있게 한 것이다.
Modeling and Removing Position and Selection Biases

- Implicit feedback(e.g. click)은 랭킹 모델을 학습하는 데 널리 사용되지만(사용자 로그에서 추출된 대규모의 click feedback을 사용하여 모델을 학습), 이런 피드백들은 기존의 랭킹 시스템에서 생성되었기때문에 편향되어있을 수 밖에 없다.
- 사용자가 실제 사용자 효용과 사용자 선호도와 관계없이 목록 상단에 표시된 비디오를 클릭하고 시청하는 경향이 있다는게 이런 position bias의 예시라고 볼 수 있고, 이로 인한 문제점들은 다수의 연구에서 이미 확인된 바 있다.
- 이걸 해결하기 위해 shallow tower 를 사용하게 된다. 모델 예측을 두 부분을 figure1의 그림에서처럼 main tower 와 shallow tower로 나누고, main tower에서의 사용자 feature 로 학습하되, shallow tower 에서는 bias에 대한 요소를 학습하게 한다.
- 즉, shallow tower에서는 position bias 학습을 위한 position feature등의 같은 selection bias에 기여하는 피쳐로 shallow tower 를 학습시키고, 이를 main tower의 최종 logit에 추가하는 식으로 학습하게 된다.
- 학습 시에는 모든 위치를 사용하며, position feature에 과도하게 의존하지 않도록 10%의 피쳐 드롭아웃 비율을 적용한다.
- 단 serving 할때에는 position feature를 제거한다.
Experiment
Multitask ranking with MMoE
- live experiment
- baseline model 로는 shared bottom 형태로 만들고, 단 이때에 공평한 설계를 위해서 model architecture 내의 multiplication 수를 동일하게 한다.

- MMoE를 썼을때에 모든 메트릭의 지표가 상승함
- baseline model 로는 shared bottom 형태로 만들고, 단 이때에 공평한 설계를 위해서 model architecture 내의 multiplication 수를 동일하게 한다.
- Gating Network Distribution

- 일부 expert들의 결과물이 다른 작업들에서 잘 공유되고 있단걸 볼 수 있음.
- Gating Network Stability.
- 여러 개의 machine을 사용하여 모델을 학습시킬 때, distributed training strategy는 모델 발산을 자주 야기시키곤 한다.(e.g. Relu death)
- MMoE에서는 softmax gating network가 불균형한 expert distiribution 문제를 가질 수 있다고 보고되었다. (즉, 대부분의 전문가에 대한 제로 활용으로 수렴되는 것)
- distribution training을 통해 이 모델에서는 gate network 극성 문제가 발생할 가능성이 20%라는 것을 관찰했다.
- 이 문제를 해결하기 위해 gating network에 drop out을 적용했고, 10%의 확률로 expert의 활용도를 0으로 설정하고 softmax 출력을 다시 regularization해서 모든 gate network의 극성을 제거한다.

data scientist