[Timeseries data anomaly detection] article 요약
https://towardsdatascience.com/effective-approaches-for-time-series-anomaly-detection-9485b40077f1
Time series anomaly?
- 집단의 공통적인 trend, seasonality, cycle 형태를 따르지 않는 데이터
- 다른 데이터들과 ‘상당한 수준으로’ 다른 데이터
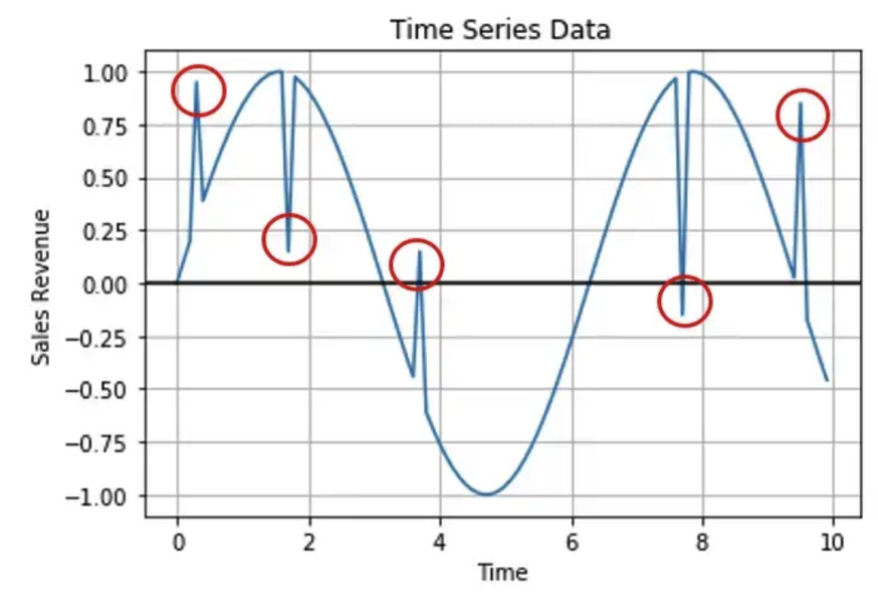
- 위의 다섯개의 점이 전형적인 anomaly
왜 이게 중요한가?
- anomaly 의 발생은 “new normal”에 대한 새로운 정의, regroup, restructure business strategy, decision making process 가 필요한 시점임을 보여줄 수 있음
- anomaly 를 항상 트래킹하고, 상세 특징에 대해서 연구해두는게 필요함.
어떻게 알아내지?
- 주로 아래 세가지 방법으로 알아낼 수 있음
- Predictive Confidence Level Approach
- Statistical Profiling Approach
- Clustering Based Unsupervised Approach
- Predictive Confidence Level Approach

- 과거 데이터로부터 전체적인 트렌드, seasonality, cycle pattern 을 읽어와서 predictive model 을 만들어내는 것 부터 시작
- 이 predictive model 로부터 MAPE(Mean Absolute Percentage Error)를 찾아내는 것
- 신뢰 구간을 찾아내거나 predictive model 로부터의 신뢰 가능한 band 를 찾아내고, 이 band 밖으로 떨어지는 data point 들을 anomaly로 간주하는 것
- Predictive model 만들어내는 유명한 방법들
- ARIMA, SARIMA, GARCH, VAR
- 이 외의 Regression, LSTM 등의 방법론 들
- 장점
- local outlier 를 찾아내기 편하다
- 단점
- predictive model 의 효과성에 지나치게 의존하는 경향이 생길 수 있음
- predictive model 의 어떤 loop hole 이 있어도, 잘못된 결과(false positive, false negative)를 낼 수 있음
- predictive model 의 효과성에 지나치게 의존하는 경향이 생길 수 있음
- Statistical Profiling Approach
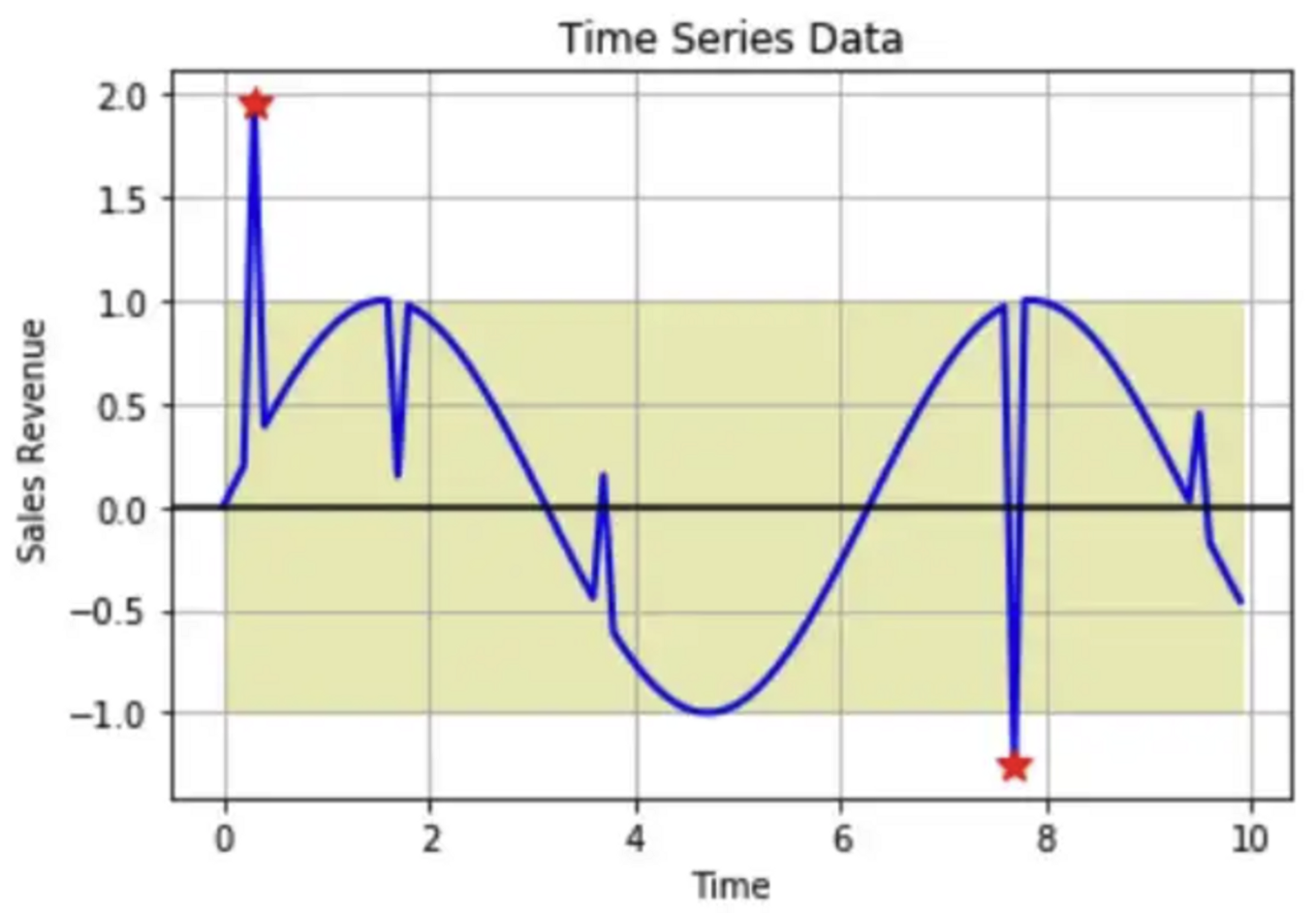
- 통계학자나 수학자가 가장 좋아하는 방법
- 경제학, 금융 섹터에서 효과가 좋다고 알려짐
- 통계적 모델이나 profile을 만들ㅇ어 내는게 가장 빠르고 효율적인 방법 → 이방법을 쓰면 통제되고, 설명 가능한 결과를 만들어낼 수 있다.
- 과거 데이터의 mean, median moving average 와 standard deviation을 이용해서 upper bound, 혹은 lower bound 를 만들어 주는 방식(즉, 통계적 값에 band 를 생성), 이 band 밖을 벗어나는 data point 를 anomaly 로 상정
- 장점
- 편해서 복잡한 방법론 적용해보기 전에, baseline approach로 유용함
- 변덕이 심한 데이터에 효과적임(predictive model 알고리즘은, 이런 데이터에서는 실패하는 경향이 크다)
- 단점
- local outlier 를 잘 못잡아낸다.(위의 그림상에 못잡아낸 세개의 포인트들)
- Clustering Based Unsupervised Approach
- labeled data 가 필요하지 않아서 유용하다.
- 근데 위험성 혹은 bottleneck으로는 clustering 알고리즘을 적용할때에 몇개의 cluster를 만들어낼지를 직접 손으로 넣어야한다는 단점
- cluster 수를 추정하는 여러 테크닉들이 있지만, time series data 에서는 dynamic 하게 적용하기가 어렵다!
- → DBSCAN
- cluster 수를 안넣어줘도 된다는 점에서 자주 쓰이는 알고리즘
- (cluster 당 최소 data 수, cluster 간 distance만 넣어주면 됨)
- local anomaly 잡아내려면 rolling window based DBSCAN을 적용해줘야할 것.

data scientist