[Paper review]PinText : A Multitask Text Embedding System in Pinterest
PinText
- pinterest 에서 19년에 kdd에 냈던 논문.
- https://dl.acm.org/doi/10.1145/3292500.3330671
Abstract
- bert 등의 pretrained model 은 산업환경에 맞지 않다며, 새로운 방법의 multitask text embedding solution을 제안함.
- word level semantic vectors 생성함. 이때 randomly sampled background 에 비해 positive engagement pair 에 더 큰 similarity 를 주도록 강제해서 학습하는 방식
Introduction
- pin, user text - pin's title, description, board name, url을 데이터로 이용
- 원하는 result - text embedding하고 word level embedding vector 를 average 해서 pin, user, search query 를 하나의 space 에 놓는 것
- → 다른 type 의 object 들에 대한 retrieval, classification 등을 nearest neighbor search 의 통합된 방법으로 해결
- pretrained word embedding(bert 등)에 대한 저자의 부정적 의견
- 연구에서의 요구사항과 산업에서의 요구사항은 다르다는 견해
- key design philosophy
- storage cost
- embedding 의 갯수는 multiple versions of embedding 과 cosine similarity 같은 realtime cost를 증가시킴
- → storage 를 아끼기 위한 all in one solution 를 원함
- memory cost
- top 10 language 에 대한 fasttext(character 기반모델) 모델의 경우 50기가
- → 메모리에 올리기 좋은 크기의 word 기반 모델
- supervised information
- guide model learning 이 더 효율적임
- throughput and latency
- latency critical realtime computation
- storage cost
- 위와 같은 needs로 in-house text embedding system이 필요하다고 생각함
- repin, click engagement 를 positive training data 로 활용 (supervised learning)
Related work
- text embedding in nlp
- sota 에서는 sequential text 를 이용한 모델이 대부분임
- But, internal data distribution 이 public corpus 와 매우 다름
- pinterest 의 데이터는 long sentence 보다는 concrete annotation term
- But, objective function 이 매우 다름
- cbow, skip gram 등은 co-occurance 를 기반으로 학습하게 됨
- facebook 의 starspace 등을 참고해서 supervised embedding training type 을 사용하고자 함
- multitask learning
- 결과 모델은 세가지 태스크에 적합해야하므로, multitask learning 을 진행할 예정
- classification 에는 흔한 task 이지만, word embedding 에서는 흔치 않음
- transfer learning
- off-the-shelf text features independent on specific task - 이걸 top 에 올리고 downstream task 를 진행하는 transfer learning 과 연관이 있다고 볼 수 있음
- e.g. elmo, gpt, bert...
- 그러나 pinterest 에 적합하지 않음
- 종종 not sequential 함
- inference efficiency 가 매우 중요함
- retrieval 이 중요 task 이기 때문에 bert의 next sentence prediction task 에는 적합하지 않음
- 태생적으로 retrieval task 를 handling 하는 starspace 를 참고할 예정
System design
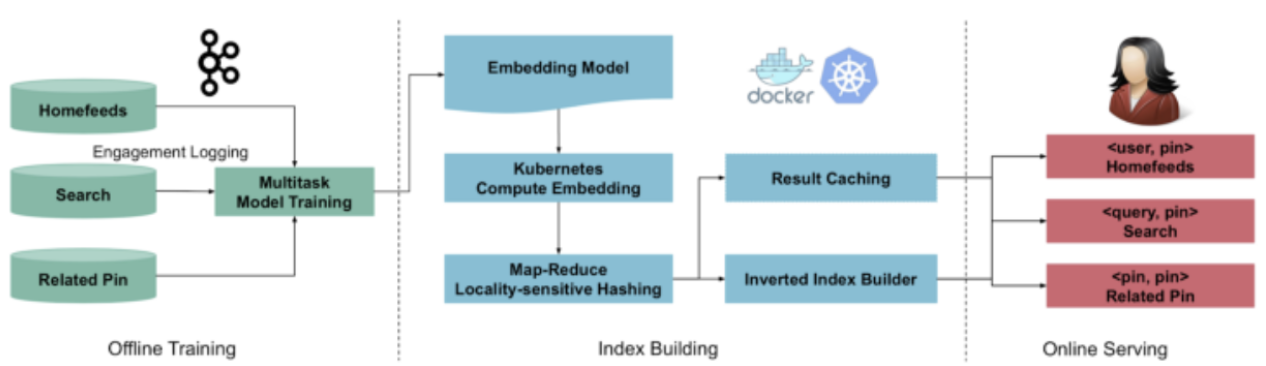
- 세개의 모듈로 구성 : offline model training, index building, online serving
- offline training
- kafka로 user engagement data 수집
- training data 구성
- index building
- kubernetes cluster (embedding vector를 distributed way 로 만든다)
- user, pin, query entity 의 candidate embedding 에 lsh 적용(pre-compute token), 여기에 inverted index 적용
- embedding vector 와 knn 결과를 caching
- online serving
- embedding vector lsh token 사용해서 retreival 등에 사용
Multitask text embedding
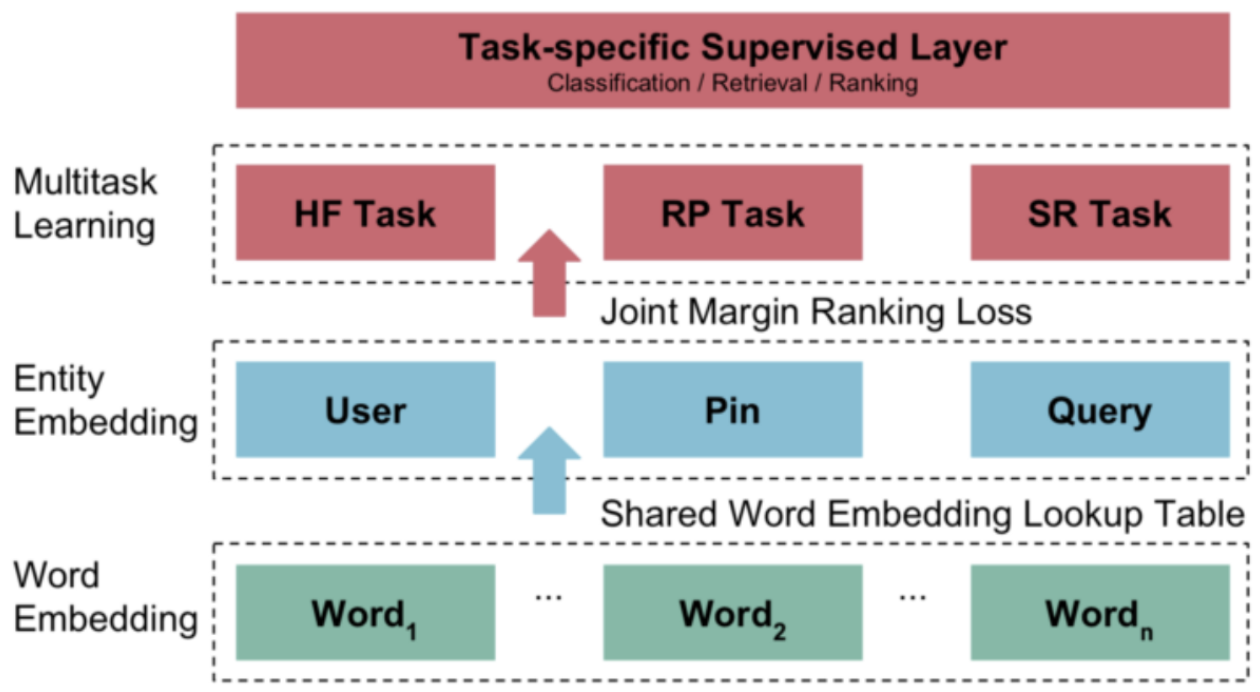
- task definition
- q, p
- positive pair - repin, long click
- q 에 해당하는 task
- home feed 에서 user
- search 에서의 search query
- related pin 에서의 subject pin
- p - a set of words {w } where each word wi appears in the union of pin’s text metadata:
- title, description, boardname, url
- u - a set of words {w } where each word wi appears in the union of user’s interests
- Multitask formulation
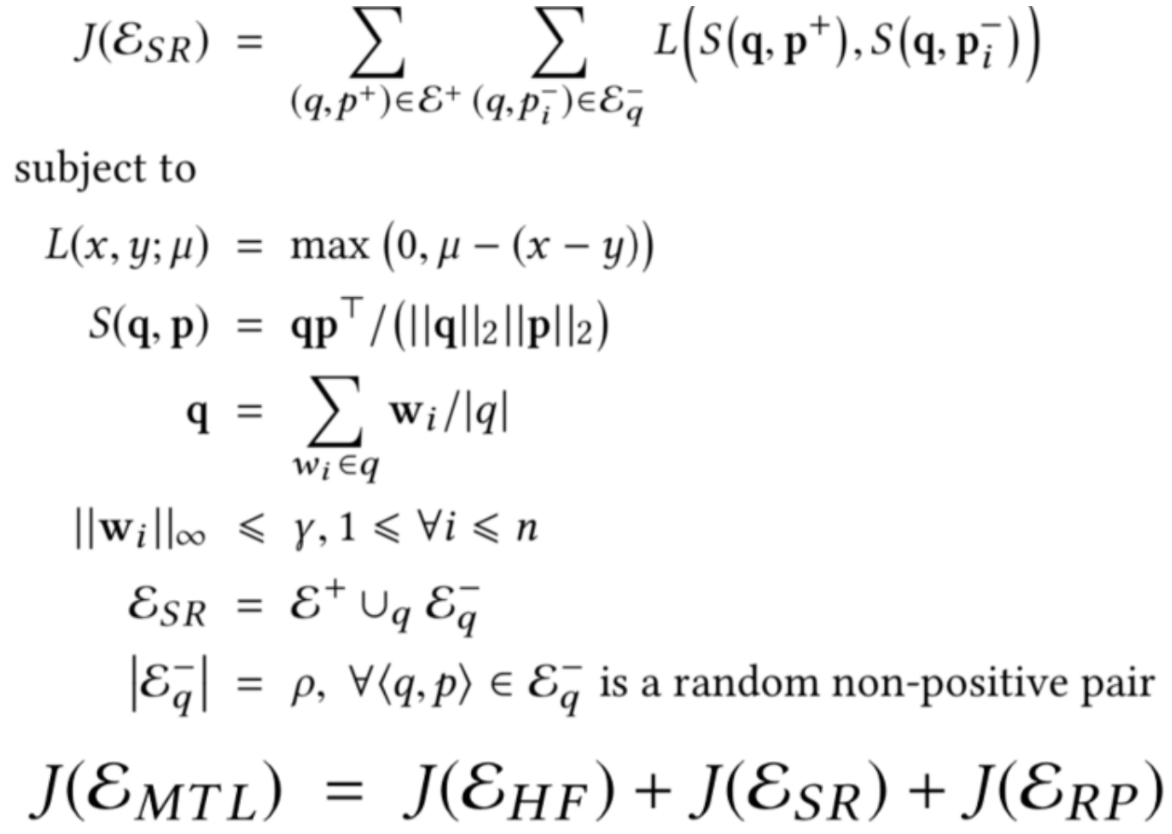
- L : hinge loss
- S : cosine similarity
- → positive entity 의 similarity 가 random 에 비해 크게 학습되도록 함
- details
- importance of each task - 따로 주지 않음 (objective function 이 natural engaged traffic 을 반영하게 하고자 함)
- tradeoff btw coverage and precision - positive pair 에 대해서 강한 filter를 주면 precision 은 늘어나지만, coverage 가 좁아짐
- 처음엔 약한 filter로 낮은 precision 으로 학습을 시켜보고, 점차 filter 강화
- coverage가 높은 모델의 결과로 다음 모델학습에서 initialization embedding dictionary로 사용함.

data scientist