대선 결과 분석
1.18대선 부터 20대선 까지 공통점은?
R1 = 보수후보득표/(진보후보득표+보수후보득표) 비율R2 = 보수후보미분류표/ (진보후보미분류표 + 보수후보미분류표) 비율R1을 X축으로 하고 R2를 Y 축으로 해서 그림을 그리면 3개의 대선에서 똑같은 경향을 볼 수 있다.어떤 경향이냐고?지역에 따라 정치 성향이
2.18대선과 19대선 비교
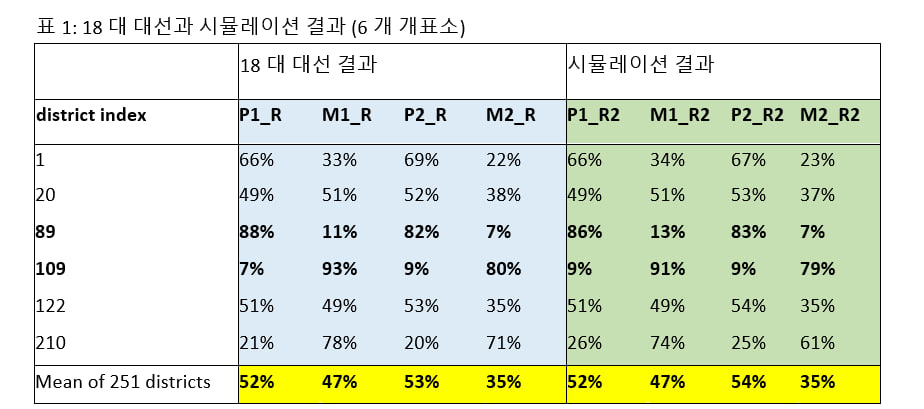
18대와 19대 대선 데이타에서 나온 K값에 대한 설명 (세 번째 자료)작성자: 전희경, 현화신작성일: 2017년 7월 30일<더플랜>에서 제시한 K가 최근 2017년 5월에 치러진 19대 대선 결과 분석에 적용되었습니다1,2. 통계적 분석 방법이 선거에 응용되는
3.19대선과 가설 요약

19대 대선과 가설 1 & 2 요약 에서 제시한 K는 이항 분포 (Binomial distribution)를 적용하여 체계를 갖춘 것으로, 각 후보의 분류표와 미분류표 득표수가 각각 모두 크다고 가정한 후 기대값을 구한 것입니다. 그런데 19대 대선의 13명의 후보자
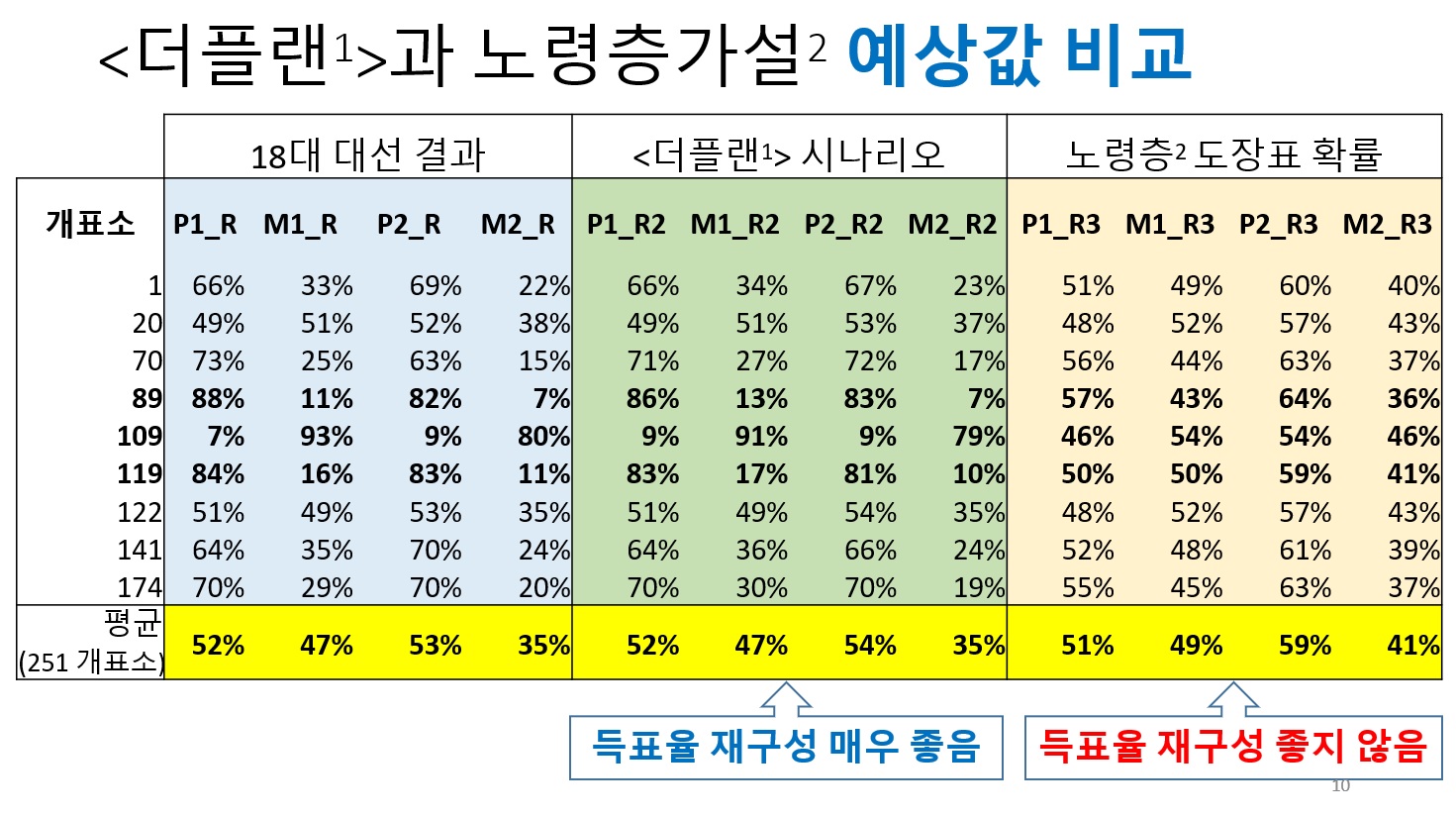
4.18대 대선의 K=1.5값이 의도된 것인가?
K=1.5를 설명하는 방법으로 에서 제시한 방법과 (시나리오) 가설2 사이에 큰 차이점이 있습니다. 에서는 정상표가 미분류로 간 것으로 간주하고 플랜에 의해 의도적으로 K=1.5이라는 결과가 나온 것으로 설명한 반면에, 가설2는 어떠한 의도 없이 노령층 도장표로 K=
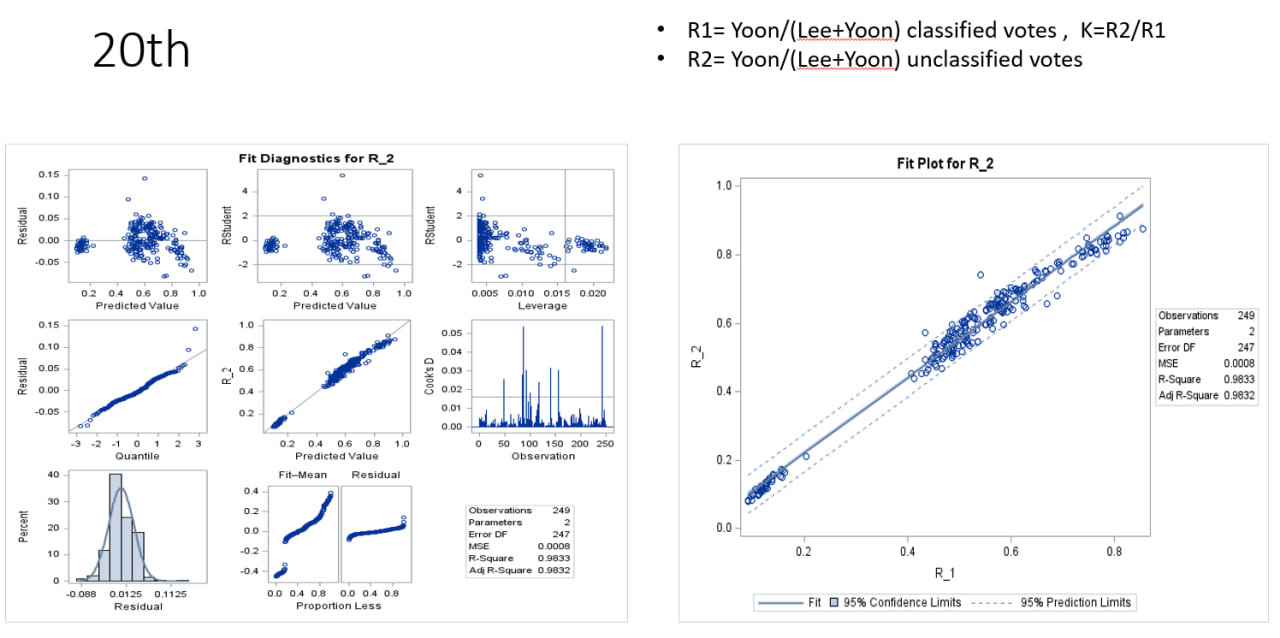
5.20대선

중앙선거관리위원회, 22대 총선 앞두고 신형 투표지분류기 제작 중이란다. 정병진: AI chatgbt가 알려주는 한국 공직선거 전자개표 방식의 문제점한국의 공직선거 개표는 주로 구식의 비효율적인 개표 시스템으로 인해 과거에 몇 가지 문제에 직면했습니다. 과거 선거에서는
6.시뮬레이션
We are going to use a conditional Bernoulli distribution for each vote. Let V=a vote to be read, W=an outcome sorted by the machine. The distribution
7.더플랜

현재 국힘당 및 윤석열파 부정선거 주장과 "더플랜"의 차이점이 뭘까요? 이완규: 투표지 분류기냐, 전자 개표기냐 선관위는 투표지 분류기가 단순한 기계장치라고 주장합니다. 하지만, 그 투표지 분류기를 생산하고 교체 작업을 하고 있는 업체가 특허출원한 시스템의 명칭은
8.전자개표기? 투표지분류기?

정병진: 다음은 천문학자 우종학 교수님의 페이스북 글 중 일부입니다. "2. 전자개표기를 통해서 1번을 찍었는지 2번을 찍었는지 카운트하지 않습니다. 우리가 사용하는 것은 투표용지 분류기 이고 그리고 용지의 숫자를 세는 개수기입니다. 분류는 기계가 일단 하지만 분류된
9.더플랜2
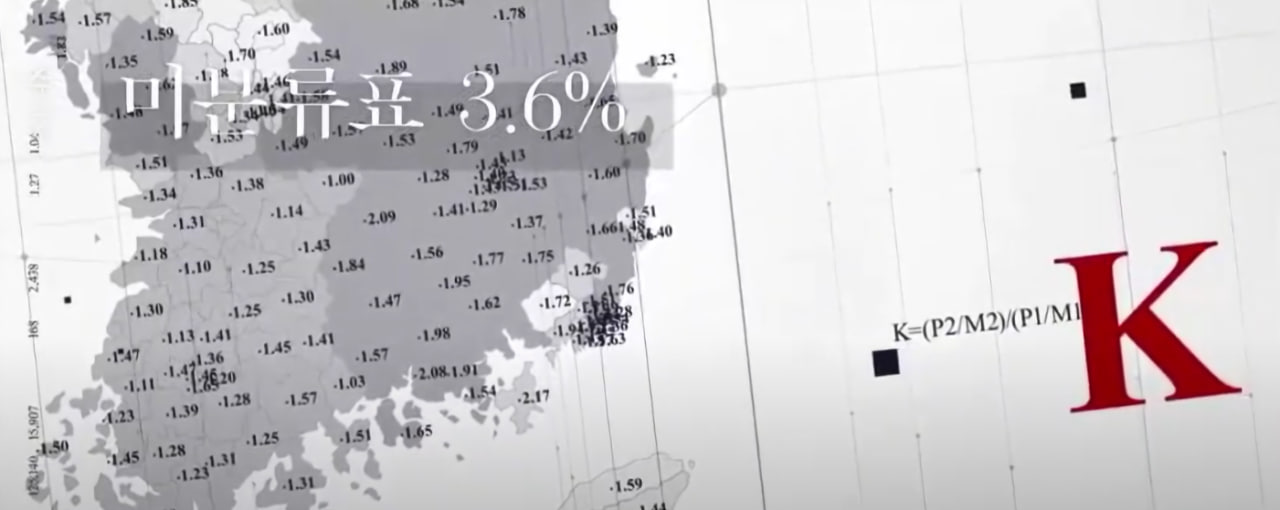
A. 《더 플랜》의 부정선거 주장 (2017년 대선 관련) 김어준이 제작한 다큐멘터리 《더 플랜》(2017)은 2012년 제18대 대통령 선거(박근혜 vs 문재인)에서 전자 개표 조작 가능성을 제기했습니다. 주요 주장 K 값(당선자가 미분류표에서 상대적으로 득표를 더
10.개표업무에 전자개표기를 왜 써야 하나?

개표업무에 전자개표기를 왜 써야 하나?편리하나? 신속하나? 정확하나? 저렴하나? 도대체 왜?편리하나? 신속하나? 정확하나? 저렴하나? 도대체 왜?(진실의길 / 신상철 / 2025-02-11)집단최면에 빠진 사람들지난 수 년에 걸쳐 기회가 있을 때마다 사람들에게 물어봤다
11.Analysis
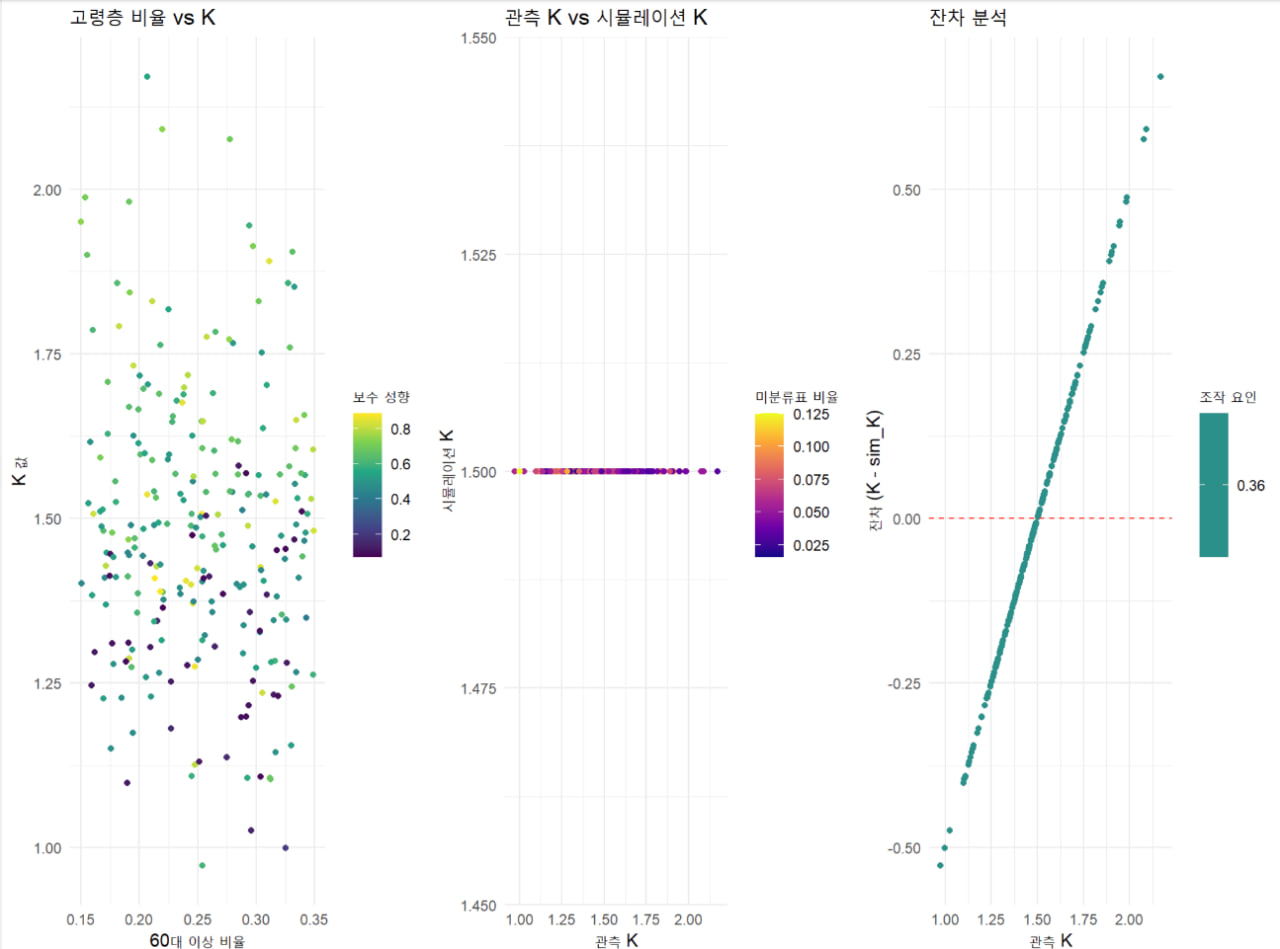
이 코드는 논문의 6개 가설(H1~H6)을 종합한 통합 가설을 검증하며, 다중선형회귀분석과 시뮬레이션을 수행합니다. R에서는 lm() 함수로 회귀분석을 수행하고, ggplot2로 시각화를 구현합니다. K 계산: KC = P1/M1, KU = P2/M2, K = KU/K
12.Analysis6
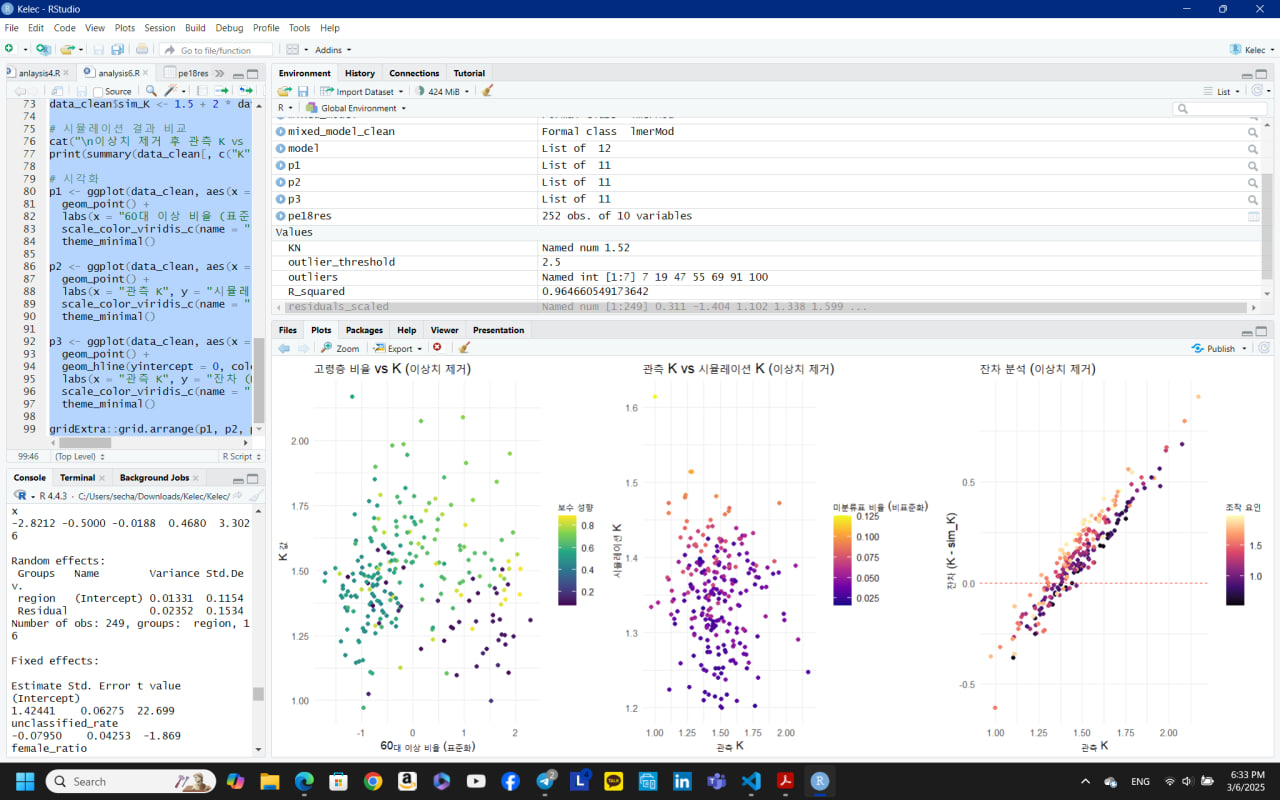
이상치(outlier)를 제거하는 것은 모델의 적합성을 개선하고, 극단값으로 인한 왜곡을 줄일 수 있는 방법입니다. 제공된 다층 모델 결과에서 Scaled residuals의 범위(-2.8212 ~ 3.3026)를 보면, 일부 극단값(예: 절대값 > 2.5 또는 3)이
13.Analysis18
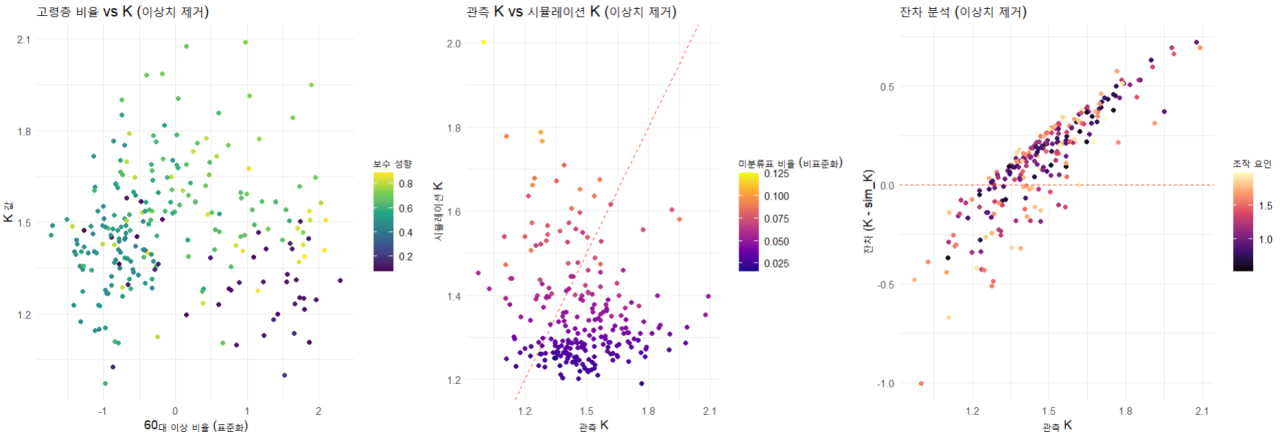
최종 결과 보고서 연구 개요 본 연구는 선형혼합모형(Linear Mixed Model, LMM)을 활용하여 K 값의 변동성을 분석하고, 주요 요인이 K 값에 미치는 영향을 평가하는 것을 목표로 한다. 분석 과정에서는 이상치 제거 및 시뮬레이션을 통해 모델의 예측 성능
14.Kelection19
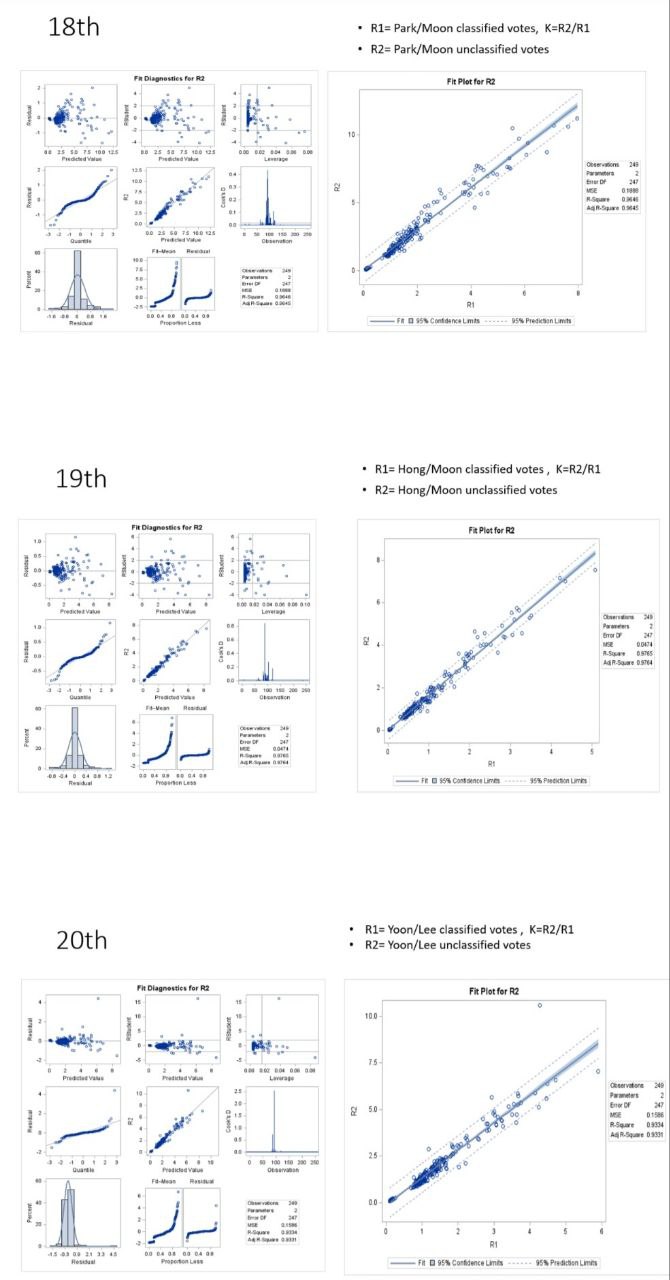
다층 모델(lmer) 분석 결과와 시뮬레이션 결과를 해석하겠습니다. 이 해석은 데이터의 변수 정의와 모델링 결과를 기반으로 이루어지며, K 값의 의미와 시뮬레이션 결과의 차이를 중심으로 설명하겠습니다.주요 변수 정의:M1: 문재인 득표수H1: 홍준표 득표수M2: 문재인
15.Kelection20
REML Criterion at Convergence: -330.3 이전 모델보다 낮아졌으나, 절대적인 기준에서 REML 값을 평가할 수 없으므로 다른 지표와 함께 해석 필요. Scaled Residuals (잔차 분석) 중앙값(0.06389) → 0에 가깝다 →
16.Kelec18to20
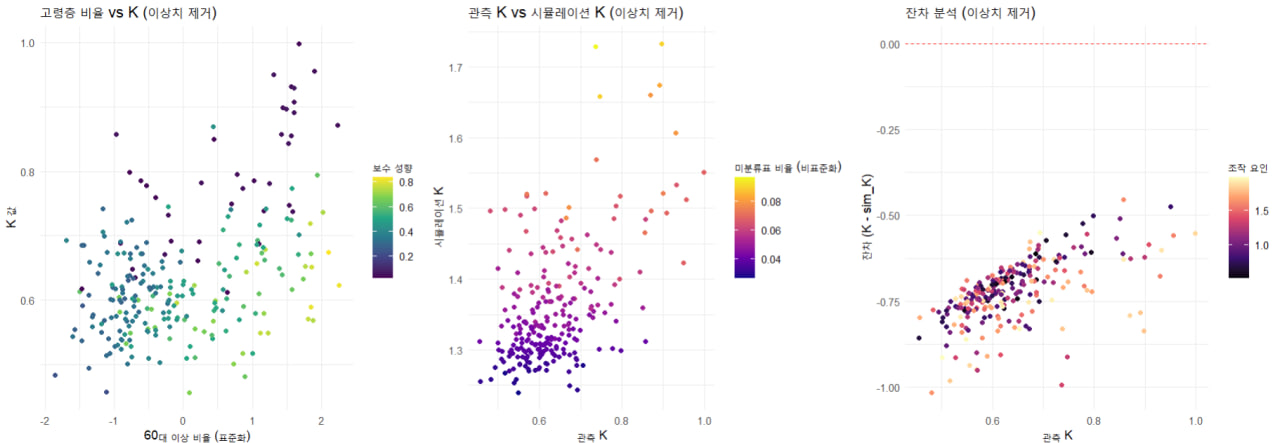
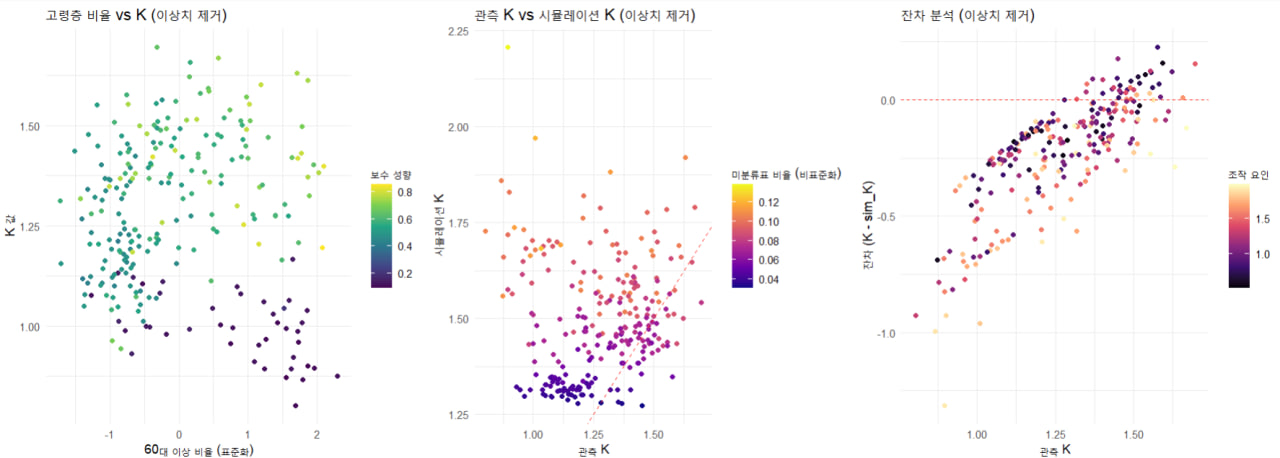
각 대선에서 K 값(특정 선거 패턴을 설명하는 지표)을 설명하는 요인들을 선형혼합모형(LMM)을 사용하여 분석함.각 모델에서 주요 설명변수를 비교하고, 고령층 비율, 미분류표 비율, 스캐너 오류, 조작 가능성 등의 변수들이 선거 결과에 미치는 영향을 평가함. 🔹 해
17.Kvalue
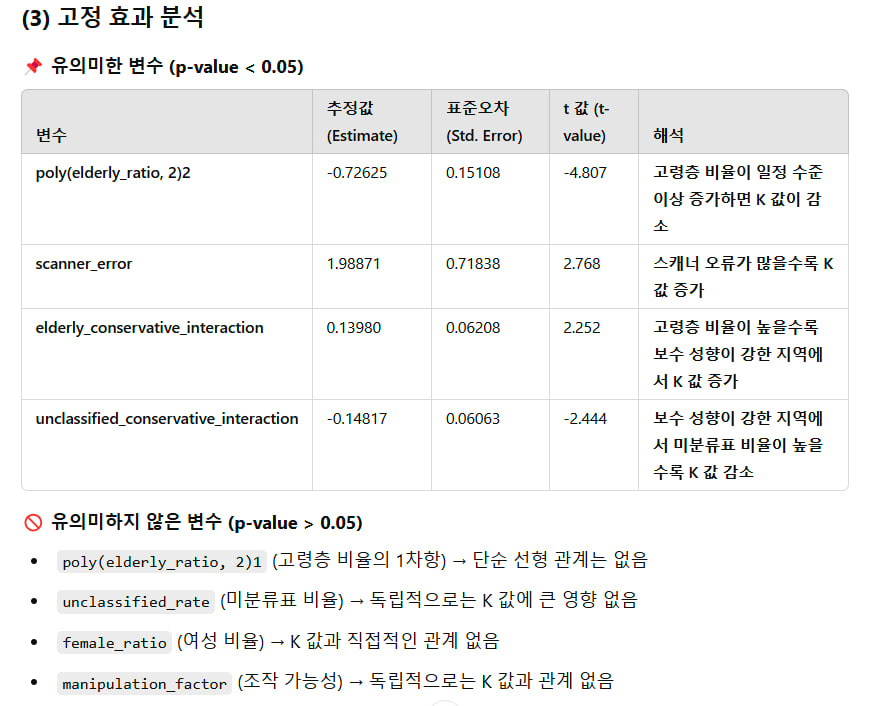
본 연구는 다층 모델(Linear Mixed Model, LMM)을 활용하여 K 값에 영향을 미치는 요인을 분석하고, 시뮬레이션 결과(sim_K)를 통해 관측 데이터와의 일치성을 평가하였습니다. 데이터는 이상치 제거 후 241개 관측치로 구성되었으며, region을 랜
18.21Kelection
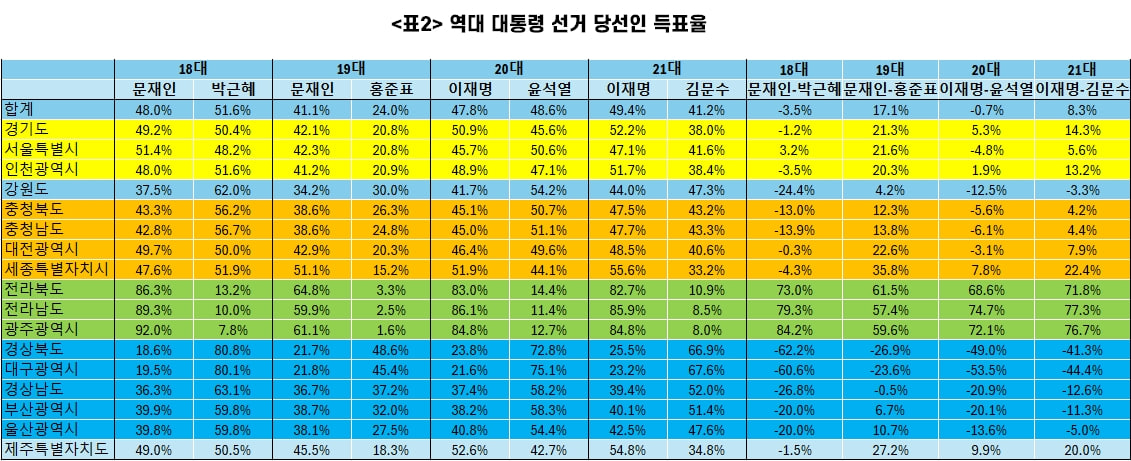
이철호님 분석: 선거 결과가 나온 후 두 가지 상반된 의견을 들었다. 하나는 2위 김문수와의 득표율 차이(8.3%)를 보면 압도적 승리이다 라며 자축하는 의견이고, 다른 하나는 윤석열의 내란죄로 인해 치러진 선거에서 어떻게 이재명의 득표율이 50%를 넘지 못하느냐 하는
19.K21election
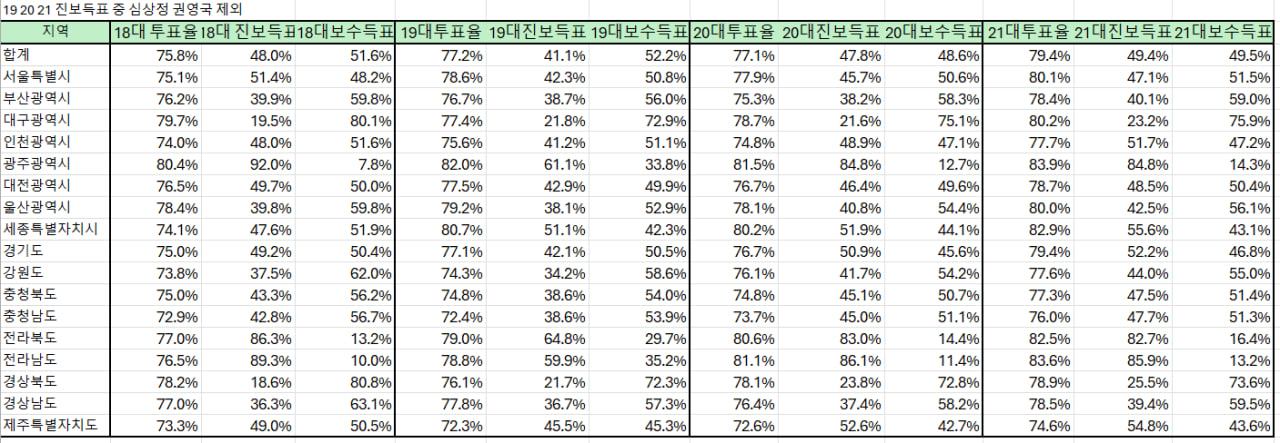
18대(2012년), 19대(2017년), 20대(2022년), 21대(2025년) 대통령 선거의 지역별 진보 & 보수 득표율과 투표율을 심층 분석. 분석 목표는 투표율이 3% 증가할 때 지역별 진보 득표율에 미치는 영향을 평가하고, 어떤 지역이 가장 큰 영향을 받는지
20.KelectionTrend

데이터: 18대부터 21대까지의 연령대(20대, 30대, 40대, 50대, 60대이상)별 진보 및 보수 득표율을 포함하며, 성별(남성, 여성) 데이터데이터는 백분율(%)로 주어져 있으므로 소수로 변환하여 계산에 활용.연령대별로 18대, 19대, 20대, 21대에 걸친
21.MorseTan

해당 유튜브 영상(https://rumble.com/v6vjbil-live-congressional-briefing-on-election-fraud-in-south-korea.html)은 2024년 6월 3일 한국 대선을 부정선거로 주장하는 내용을 다루고 있으