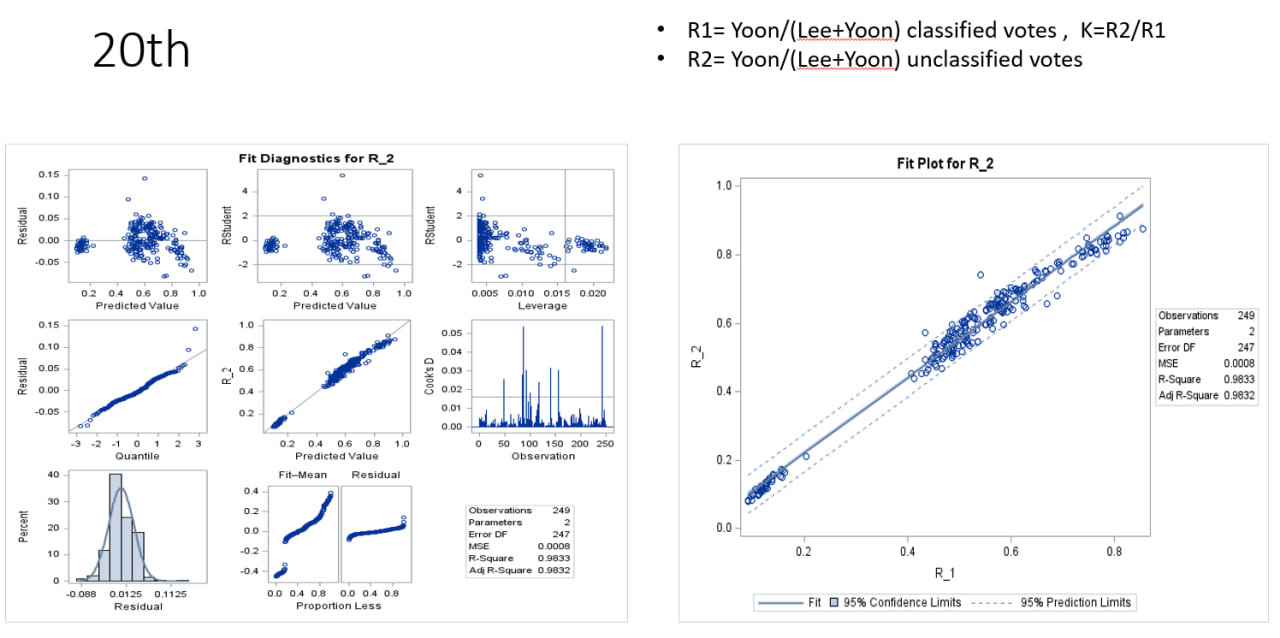
R_1 = 보수후보 분류표/(진보후보 분류표+보수후보 분류표) 비율
R_2 = 보수후보 미분류표/ (진보후보 미분류표 + 보수후보 미분류표) 비율
R_1을 X축으로 하고 R_2를 Y 축으로 해서 그림을 그리면,
지난 3회의 대통령 선거에서 똑같은 경향을 볼 수 있다.
어떤 경향일까? 미분류표는 모든 후보에게 똑같이 발생하지 않는다.
정치 성향이 보수일수록 미분류표를 더 많이 만들어 낸다.
보수 지지층이 많은 지역에서 미분류표를 더 많이 만든다.


20대: R2 = -0.139 + 1.47 R1 (R-sq=0.93)
R_2= -0.002 + 1.11 R_1 (R-sq=0.98)
19대: R2 = 0.012 + 1.64 R1 (R-sq=0.98)
R_2= 0.053 + 1.11 R_1 (R-sq =0.97)
18대: R2 = 0.012 + 1.52 R1 (R-sq=0.96)
R_2= 0.042 + 1.06 R_1 (R-sq=0.98)
대선에서 보여준 분류표율과 미분류표율 비율로 그린 그림
1차 방정식(R2=a*R1+b or R_2=a*R_1+b) 또는
2차 방정식 (R_2= a*R_1^2+ b*R_1+c)으로 98% 데이터 설명이 가능하다.재미 있는 현상이다.
어떻게 해석할 수 있을까?
정치 성향에 따라 지역에 따라 행동 패턴이 다른데, 그 행동 패턴은 연속적으로 비슷했다.
지난 2012년 18대 대선부터 2022년 20대선 까지 10년 동안 유사하다.
18대선에서,
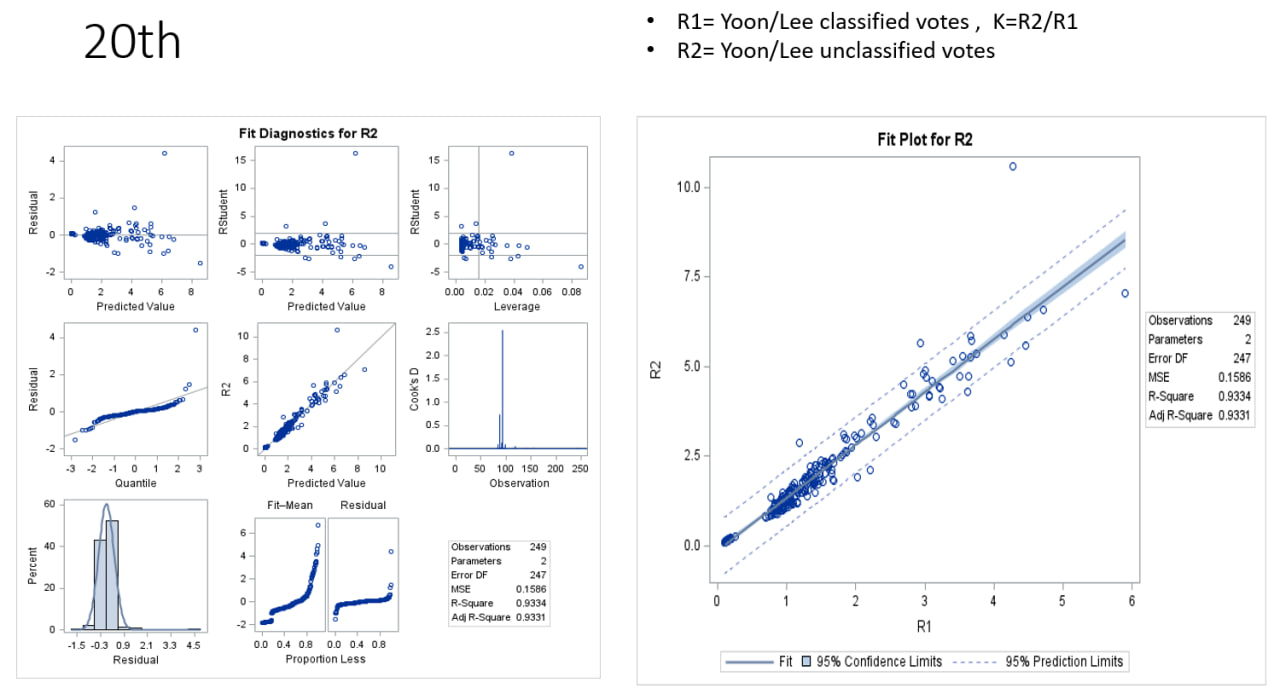
K=R2/R1=두후보 미분류표비율/ 두후보 분류표비율
= (당선자 미분류표/경쟁자 미분류표)/ (당선자 분류표/경쟁자 분류표)로 정의했었다.
이를 조금 변형해서 K' = (보수 미분류표/진보 미분류표)/ (보수 분류표/진보 분류표)로 바꾸어보면,
보수후보 우세 지역인 경남 6개 지역(거제, 거창, 사천, 창원, 진주, 의령) K'값이 1.95-2.17
19대선 같은 지역에서 K'= 1.49-2.08
20대선에서는 K'= 1.32-1.62
진보후보 우세 지역: 전북 무주, 전남 광양 등에서
18대: K'= 1.00 - 1.03
19대: 1.17 - 1.57
20대: 1.01 - 1.04
18대 대선에서 K=1.5 라는 값은, 분류표에서 (총 투표수의 96% 해당) 보수후보가 진보후보의 99% 이상만 득표하면 선출될 수 있는 수치라는 의미다. 박후보가 문후보보다 미분류표에서 상대적으로 더 많이 득표하여 선출되었다. 박빙에서 미분류표가 역할을 한 셈이다.
20대선에서 기존 K값 정의를 이용해 그래프를 그리면, 기울기 1.47이 나온다. 20대선에서 18대선과 비슷한 경향이 나왔다.
총투표자수는 33,863,210명이고 이재명 후보는 1,6147,738표(47.6%), 윤석열 후보는 16,394,815표(48.4%)를 얻었다. 두 후보의 차이는 247,077표이다.
그런데 미분류표에서는 어땠을까?
전체 미분류표 1,960,718표 중에서 이재명 후보는 736,397표(37.5%), 윤석열 후보는 884,705표(45.1%)로 나타났다.
미분류표에서 두 후보의 차이는 148,308표이다.
한 마디로 정상분류표에 비해 윤석열 후보에게 미분류표가 많이 나왔다.
(참고로, 19대선에서는 문후보가 홍후보보다 미분류표를 더 적게 받았으나 당선되었다!)
K >> 1이면, 당선자가 미분류된 비정상표에서 경쟁자보다 득표를 더 많이 하여 선출된 것이므로, 즉 미분류표에 의한 이득이 있으므로, 그 원인을 찾는 것이 필요하다. 노령층이 미분류표를 많이 만든다는 것은 일부만 설명 가능하다. 20대선에서 60대 이상 비율은 K와 마이너스 관계가 나왔다.
(미분류표/총투표수)를 보면 강원,경남,경북에서 미분류표가 많이 나왔고, 평균 7%이고 지역별로 3-14%를 보인다.
보수 정치 성향의 국민들이 미분류표를 더 많이 만들어낸다.
그 이유가 궁금하지 않은가?
데이터 분석가 및 관심있는 분들의 분석을 기대한다.
20대선 그래프
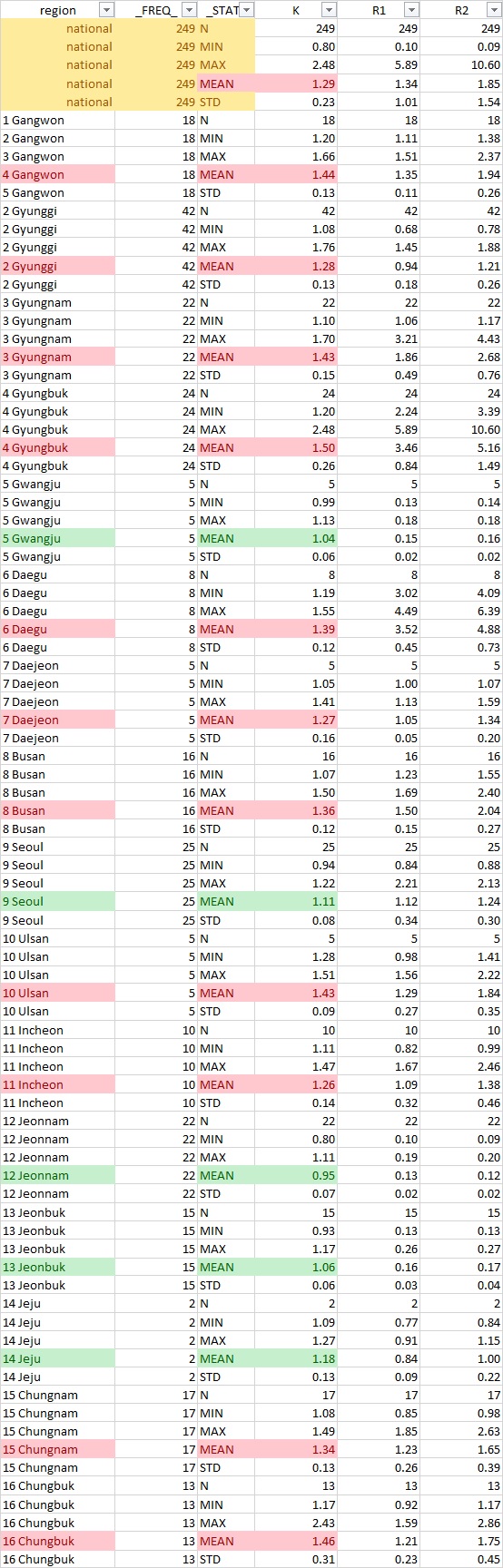
K값 평균으로 보는 지역의 보수, 진보성향은?
K, R2 (미분류표비율) 값의 평균(mean), 최대값(MAX) 을 지역별로 살펴보시기 바란다.
- 데이터 수집과 코멘트를 해주신 정병진님과 윤복원님에 감사드립니다.
