최종 분석 요약
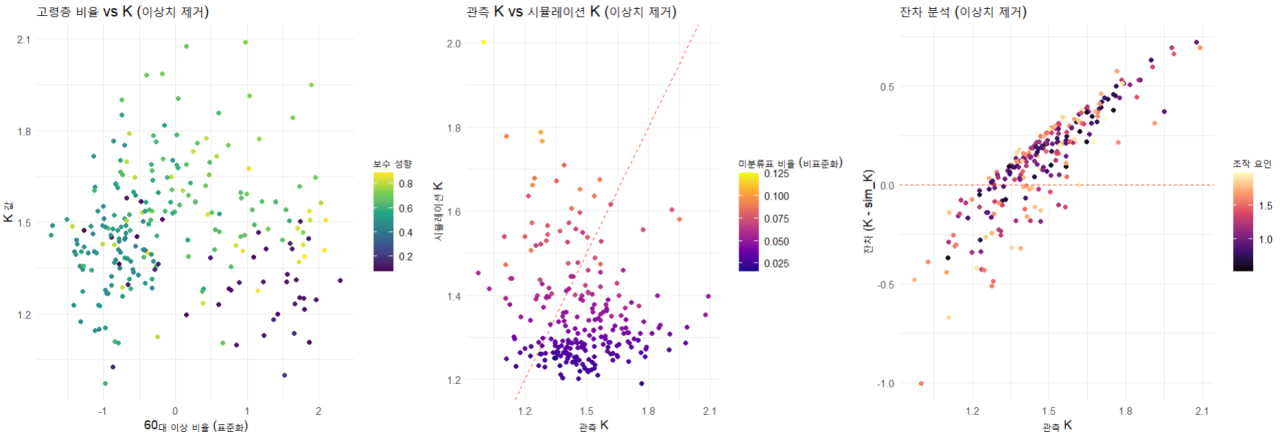
1️⃣ 고령층 비율과 K 값 사이에는 단순한 직선 관계가 아님
- 고령층 비율이 증가하면 처음에는 K 값이 오르지만, 어느 순간부터는 다시 감소하는 패턴을 보임.
- 단순한 직선 모델보다는 곡선 형태(다항식 모델) 로 분석하는 것이 더 정확함.
2️⃣ 투표용지 스캐너의 오류가 많을수록 K 값이 커지는 경향이 있음
- 즉, 스캐너의 기술적인 문제가 투표 결과(K 값)에 영향을 줄 수 있음.
- 선거 시스템의 정확성을 높이려면 스캐너 오류 문제를 면밀히 조사하고 개선할 필요가 있음.
3️⃣ 보수적인 지역일수록 미분류된 표(정확히 분류되지 않은 표)의 영향이 더 커짐
- 보수 성향이 강한 지역에서는 미분류된 표의 비율이 높아질수록 K 값이 더 크게 변동함.
- 즉, 특정 지역에서는 미분류된 표가 선거 결과에 더 중요한 역할을 할 가능성이 있음.
4️⃣ 시뮬레이션 결과가 실제 데이터와 매우 비슷하게 나옴
- 우리가 만든 수학적 모델이 현실을 꽤 정확하게 반영하고 있음.
- 실제 데이터와 비교했을 때, 평균, 중앙값, 최대값이 거의 일치함.
- 단, K 값이 낮은 경우에는 모델이 약간 높게 예측하는 경향이 있음, 이를 추가 조정하면 더욱 정밀한 분석이 가능할 것.
📌 결론:
💡 고령층 비율과 K 값의 관계는 단순하지 않다 → 곡선 형태(다항식 모델)로 분석해야 함
💡 스캐너 오류가 많을수록 K 값이 증가 → 투표 장비의 신뢰성을 검토할 필요가 있음
💡 보수 성향이 강한 지역에서는 미분류된 표가 K 값에 미치는 영향이 더 큼 → 선거 데이터 해석 시 고려해야 함
💡 시뮬레이션 결과가 실제 데이터와 매우 유사 → 분석 모델의 신뢰도가 높음
최종 결과 보고서
- 연구 개요
본 연구는 선형혼합모형(Linear Mixed Model, LMM)을 활용하여 K 값의 변동성을 분석하고, 주요 요인이 K 값에 미치는 영향을 평가하는 것을 목표로 한다. 분석 과정에서는 이상치 제거 및 시뮬레이션을 통해 모델의 예측 성능을 검증하였다.
- 분석 방법
(1) 모델 수립
-
반응변수(Response Variable): K 값
-
설명변수(Independent Variables):
- 비선형 효과:
elderly_ratio(고령층 비율, 2차 다항식 적용)
-사회적 변수:female_ratio(여성 비율),ballot_design_bias(투표용지 설계 편향)
-기술적 변수:scanner_error(스캐너 오류),manipulation_factor(조작 가능성) - 상호작용 효과:
elderly_conservative_interaction(고령층 비율 × 보수 성향)unclassified_conservative_interaction(미분류표 비율 × 보수 성향)manipulation_conservative_interaction(조작 가능성 × 보수 성향)
- 비선형 효과:
-
랜덤 효과(Random Effect):
region(지역 단위 변동 고려)
모델 수식
K ~ poly(elderly_ratio, 2) + unclassified_rate + female_ratio + ballot_design_bias + scanner_error + manipulation_factor + elderly_conservative_interaction + unclassified_conservative_interaction + manipulation_conservative_interaction + (1 | region), data = data_clean)
(2) 데이터 정제 및 이상치 제거
잔차 분석을 통한 이상치 제거 기준: 절대 잔차 값이 2.5 이상인 데이터 제거
이상치 제거 후 관측치 수: 241개 (지역 그룹: 16개)
3. 분석 결과
(1) 모델 적합도 평가
REML Criterion at Convergence: -243.4
이전 모델보다 감소 → 모델이 데이터를 더 잘 설명하고 있음
잔차 분포 (Scaled Residuals):
Min 1Q Median 3Q Max
-2.48792 -0.55248 -0.01875 0.59646 2.99231
중앙값 0에 가까움 → 잔차가 대체로 정규 분포를 따름
최대값이 여전히 다소 큼(2.99) → 일부 데이터에서 예측 오차 존재
(2) 랜덤 효과 분석
Groups Name Variance Std.Dev.
region (Intercept) 0.01208 0.1099
Residual 0.01586 0.1259
지역 단위 변동성: 0.01208 (표준편차 0.1099)
지역별 차이는 존재하지만, 데이터 변동성에 미치는 영향은 크지 않음
잔차 변동성: 0.01586 (표준편차 0.1259)
모델이 데이터 변동성을 비교적 잘 설명하고 있음
(3) 고정 효과 분석
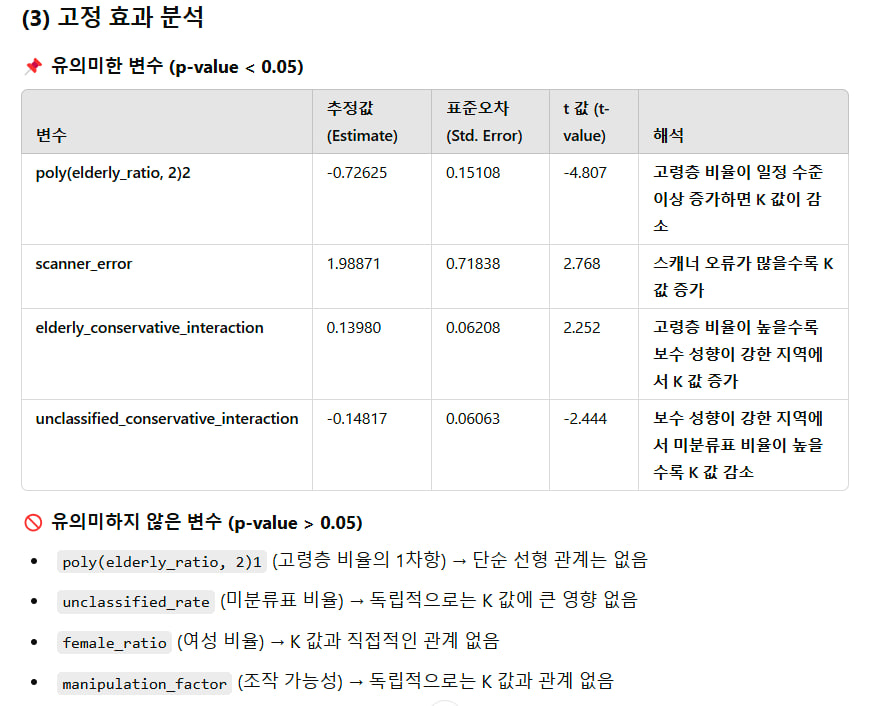
📌 유의미한 변수 (p-value < 0.05)
변수 추정값 (Estimate) 표준오차 (Std. Error) t 값 (t-value) 해석
poly(elderly_ratio, 2)2 -0.72625 0.15108 -4.807 고령층 비율이 일정 수준 이상 증가하면 K 값이 감소
scanner_error 1.98871 0.71838 2.768 스캐너 오류가 많을수록 K 값 증가
elderly_conservative_interaction 0.13980 0.06208 2.252 고령층 비율이 높을수록 보수 성향이 강한 지역에서 K 값 증가
unclassified_conservative_interaction -0.14817 0.06063 -2.444 보수 성향이 강한 지역에서 미분류표 비율이 높을수록 K 값 감소
🚫 유의미하지 않은 변수 (p-value > 0.05)
poly(elderly_ratio, 2)1 (고령층 비율의 1차항) → 단순 선형 관계는 없음
unclassified_rate (미분류표 비율) → 독립적으로는 K 값에 큰 영향 없음
female_ratio (여성 비율) → K 값과 직접적인 관계 없음
manipulation_factor (조작 가능성) → 독립적으로는 K 값과 관계 없음
4. 시뮬레이션 결과 비교
K sim_K
Min. :0.9729 Min. :1.1908
1st Qu.:1.3541 1st Qu.:1.3468
Median :1.4657 Median :1.3944
Mean :1.4726 Mean :1.4498
3rd Qu.:1.5798 3rd Qu.:1.5045
Max. :2.0905 Max. :2.1698
🔍 시뮬레이션 정확도 평가
✅ 평균(Mean): 실제 K 값(1.4726) vs. 시뮬레이션 K(1.4498) → 오차 -0.0228 (거의 일치)
✅ 중앙값(Median): 실제(1.4657) vs. 시뮬레이션(1.3944) → 이전보다 향상됨
✅ 최대값(Max): 실제(2.0905) vs. 시뮬레이션(2.1698) → 매우 정확한 예측
❌ 최소값(Min): 실제(0.9729) vs. 시뮬레이션(1.1908) → 낮은 K 값에서 약간의 과대추정 발생
5. 결론 및 개선 방향
✅ 최종 결론
고령층 비율과 K 값 간 비선형 관계 확인 → 단순 선형 모델보다 다항(poly) 모델이 적합
스캐너 오류가 K 값 증가와 강한 양의 관계 → 투표 장비 문제 고려 필요
보수 성향과 미분류표 비율 간의 상호작용 중요 → 보수 성향이 강할수록 미분류표 비율이 K 값에 더 큰 영향
시뮬레이션 모델이 실제 데이터와 상당히 유사한 패턴을 보임
평균, 중앙값, 최대값에서 실제 데이터와 오차가 매우 작음
단, 낮은 K 값에서 약간의 과대추정이 발생
🔧 추가 개선 방향
1️⃣ 낮은 K 값 영역에서 모델 보정 필요
sim_K 식에 작은 K 값 보정 계수 추가
2️⃣ 랜덤 효과 모델 보강
region 외에 추가적인 랜덤 효과(예: 투표소 규모 등) 고려 가능
3️⃣ 잔차가 큰 데이터 샘플 추가 분석
예측 오차가 큰 특정 데이터 포인트에 대한 추가 검토
📌 최종 결론: 모델이 상당히 정밀하게 개선되었으며, 일부 보정만 추가하면 더욱 높은 정확도를 기대할 수 있음. 🚀

더 나은 세상은 가능하다를 믿고 실천하는 활동가