foundation model in robotics
1.SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning

https://arxiv.org/pdf/2307.06135 1. 이 논문 왜 봐? 목적 매우 넓은 실내 공간에서, 로봇이 다양한 Tasks를 수행할 수 있도록 하자! LLM의 장점 로봇에게 다양한 tasks를 주었을 때, 어떻게 수행해야할지에 대한 합리
2.LM-Nav
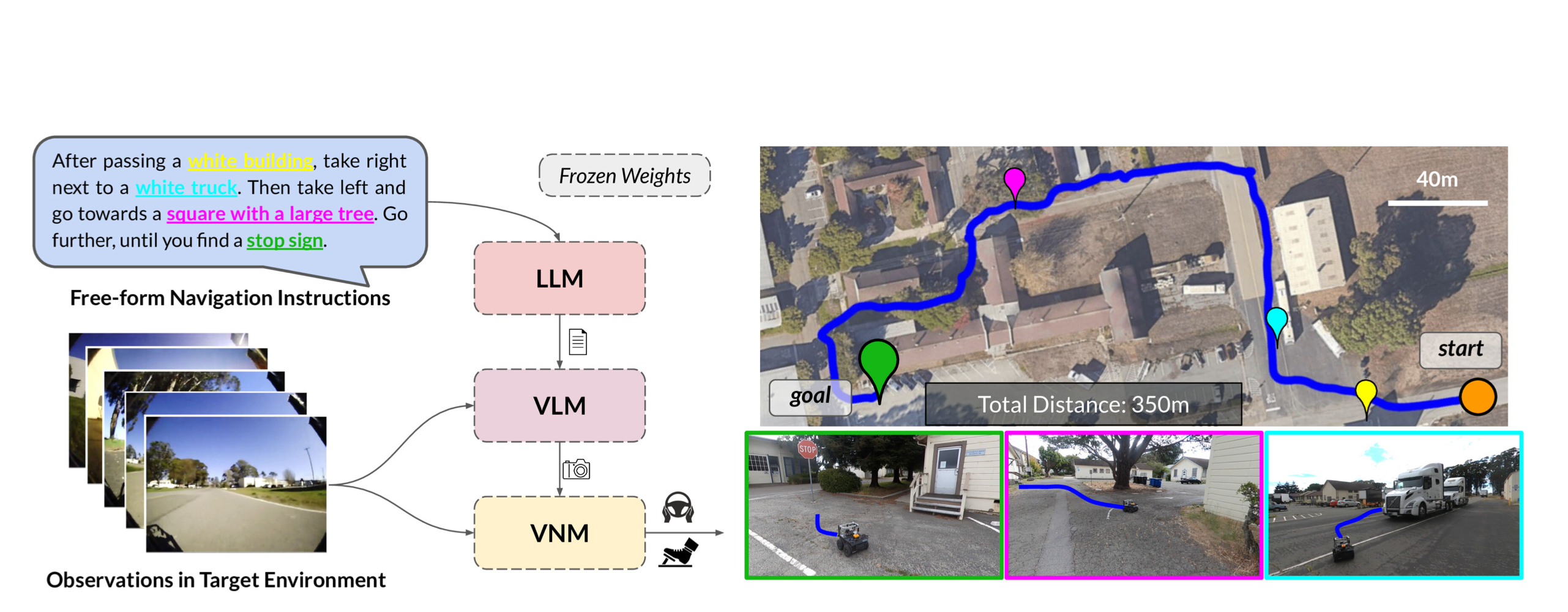
LM-Nav13은 환경 관찰을 위한 이미지를 노드로 저장하고, 이미지 간의 근접성을 에지로 나타내는 그래프 기반 접근법을 사용하는 알고리즘환경 내 이미지(예: 특정 방의 사진)를 노드로 표현이 방식은 GPT-3와 CLIP 두 가지 모델을 결합하여, 복잡한 언어 지시를
3.ViNT: A Foundation Model for Visual Navigation
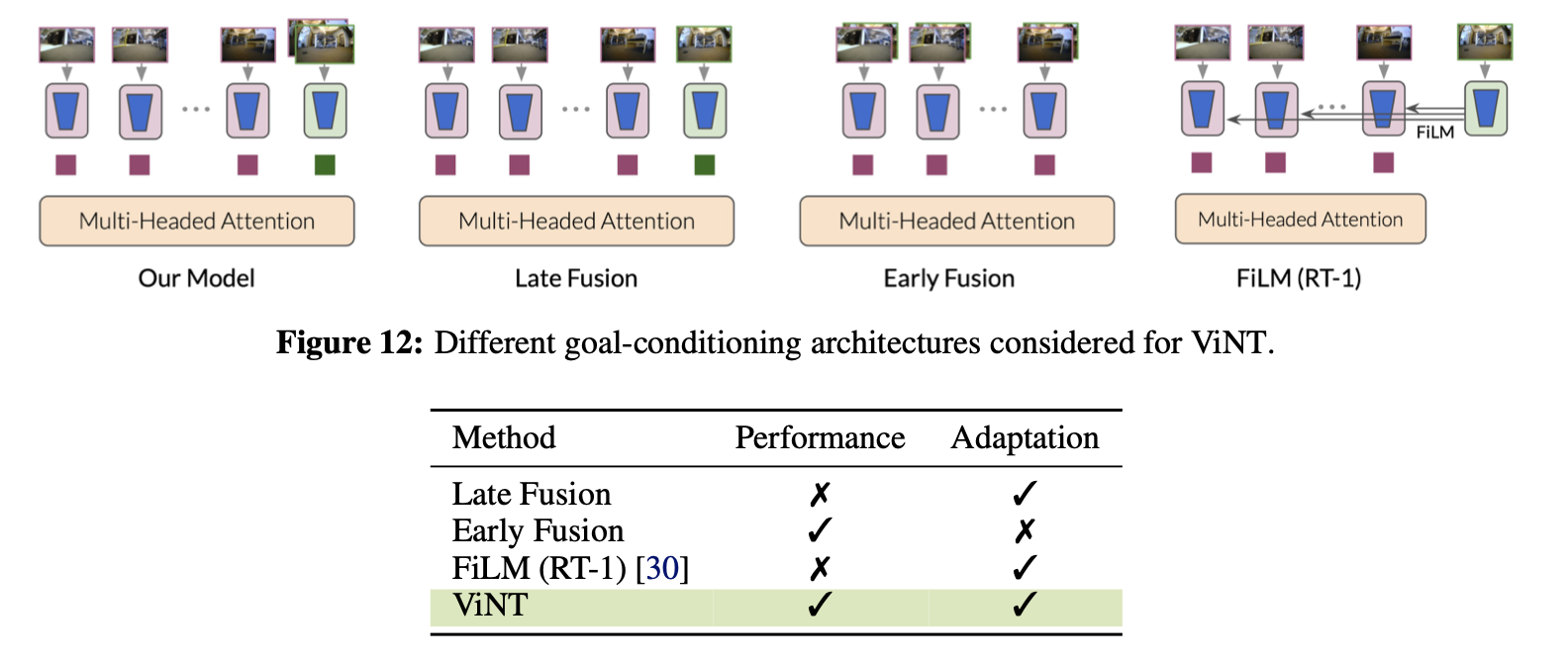
요즘엔 일명 '기초 모델'로 불리는 범용 사전 훈련 모델이 머신러닝 문제를 푸는데 큰 도움이 되고 있어요. 이런 모델들은 처음부터 학습하는 것보다 훨씬 작은 데이터셋으로도 일반화된 솔루션을 만들어낼 수 있게 해줍니다. 이 모델들은 대규모이면서 다양한 데이터셋으로 약한
4.LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
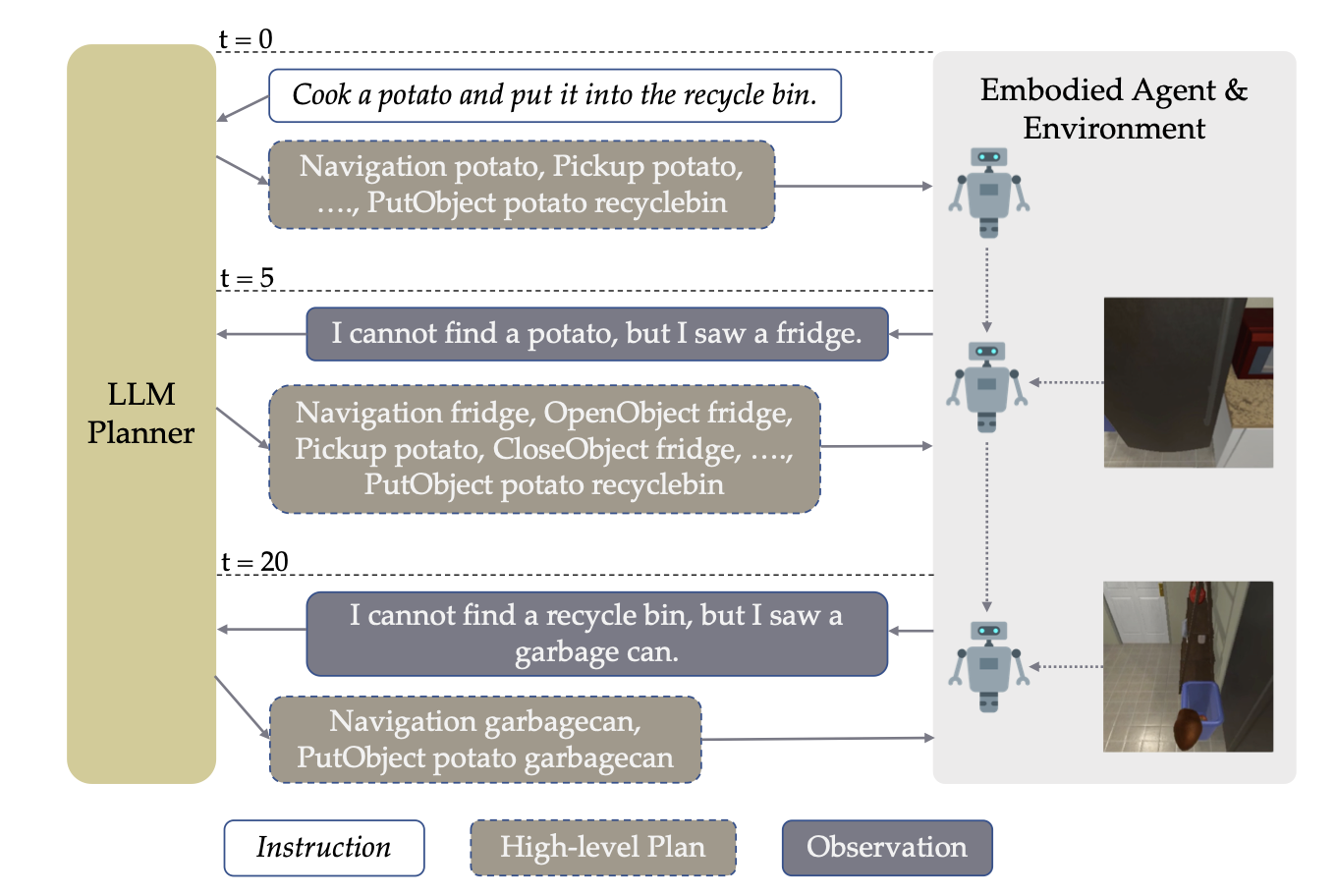
LLM planner가 생성한 HLP(하이레벨 플레닝, 에: sequence of sub-goals (감자 찾으러 갔다가, 감자 잡고, 전자레인지로 가) 수행 시간이 너무 오래걸리면, 로봇은 LLM에게 지금까지 관찰했던 사진들 + HLP 중 지금까지 수행 완료한 것들
5.R2R dataset & ALFRED dataset & AI2-Thor Simulator
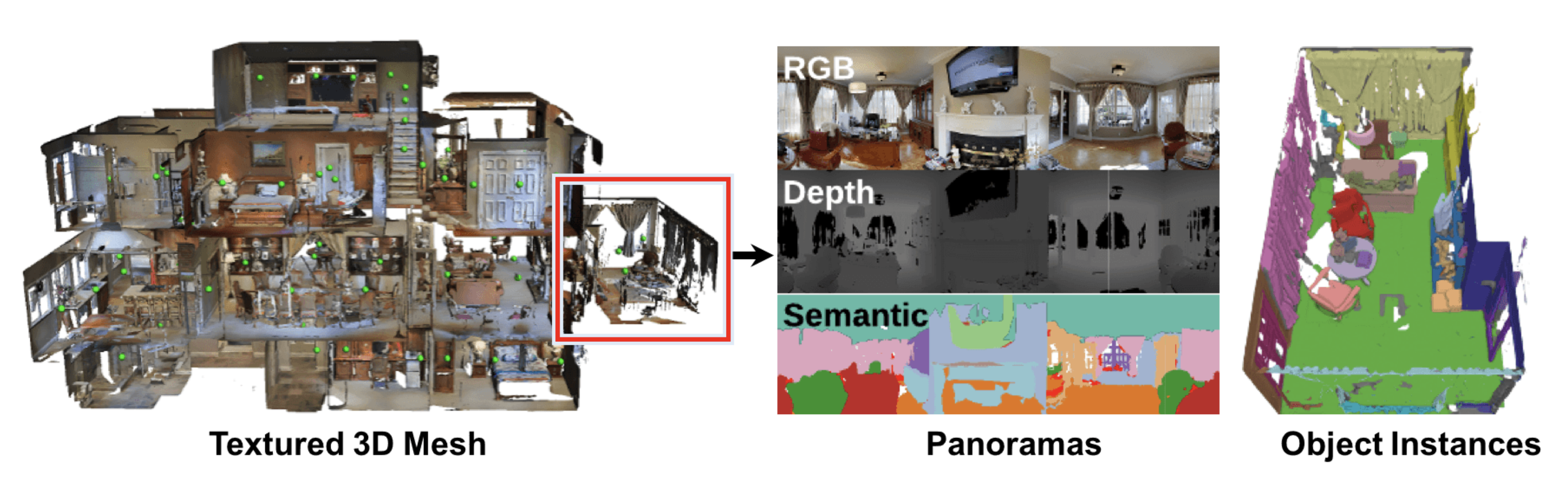
https://bringmeaspoon.org동기: 로봇과의 자연어 상호작용5살짜리 아이에게 숟가락을 가져오라고 부탁하면, 숟가락이 나타날 가능성이 높습니다. 우리는 로봇도 같은 일을 할 수 있기를 원합니다.우리의 시각-언어 내비게이션(VLN) 테스트 서버와
6.Code as Policies: Language Model Programs for Embodied Control
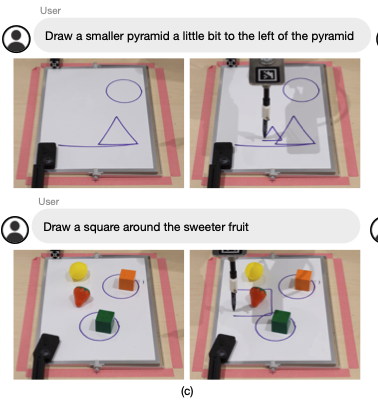
대형 언어 모델(LLM)은 코드 완성을 위해 학습된 경우, 도큐먼트 스트링에서 간단한 파이썬 프로그램을 생성할 수 있는 능력을 갖추고 있음을 보여주었다 1. 우리는 코드 작성 LLM이 -> 자연어 명령을 주어 -> 로봇 정책 코드를 작성하는 데 쓰일 수 있음을 발견구체
7.Segment Anything Model (SAM)
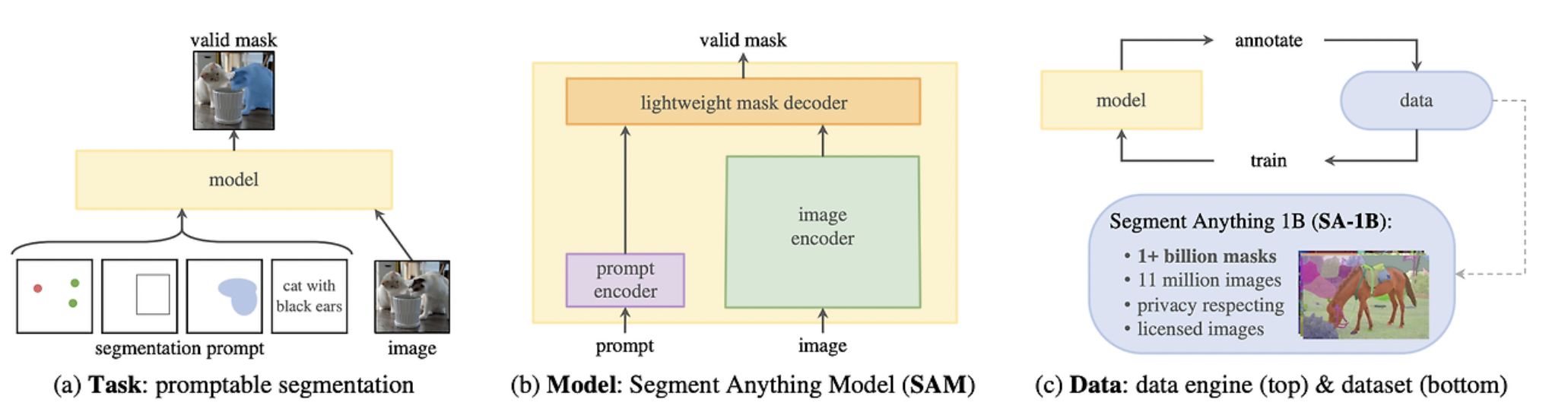
연산량 많음Masked Autoencoder(MAE) pre-trained ViT를 사용연산량 매우 적음prompt 종류sparse point점 points점 좌표가, 이미지 전체에서 차지하는 위치에 대한 positional encoding (batch, 1, embe
8.Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning

읽어볼 논문RT-2: https://arxiv.org/pdf/2307.15818 (380회 인용)PaLM-E: https://arxiv.org/pdf/2303.03378 (950 회 인용)LLM은lack of world grounding and dep
9.VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models

https://arxiv.org/pdf/2307.05973LLM: 위 input 지시어의 affordance와 constraint를 출력VLM: affordance와 constraint를 3D value map에 grounding함.위 두 과정은 code in
10.HomeRobot: Open-Vocabulary Mobile Manipulation

https://arxiv.org/pdf/2306.11565가정 내 로봇이 다양한 물체를 조작하고 이동하는 문제를 다루고 있습니다. Open-Vocabulary Mobile Manipulation(OVMM)의 중요성: 이 개념은 이전에 본 적이 없는 환경에서 임
11.OpenScene: 3D Scene Understanding with Open Vocabularies
CLIP을 활용하여 3D 포인트와 텍스트 및 이미지 픽셀을 공동 임베딩(co-embedding)하는 방식새로운 종류의 질의에 대해 효과적으로 응답할 수 있는 모델을 제공레이블이 없는 3D 데이터로 작업하는 데 중점을 둔 내용기존 3D 장면 이해 방법의 한계: 기존의 3
12.OpenEQA: Embodied Question Answering in the Era of Foundation Models
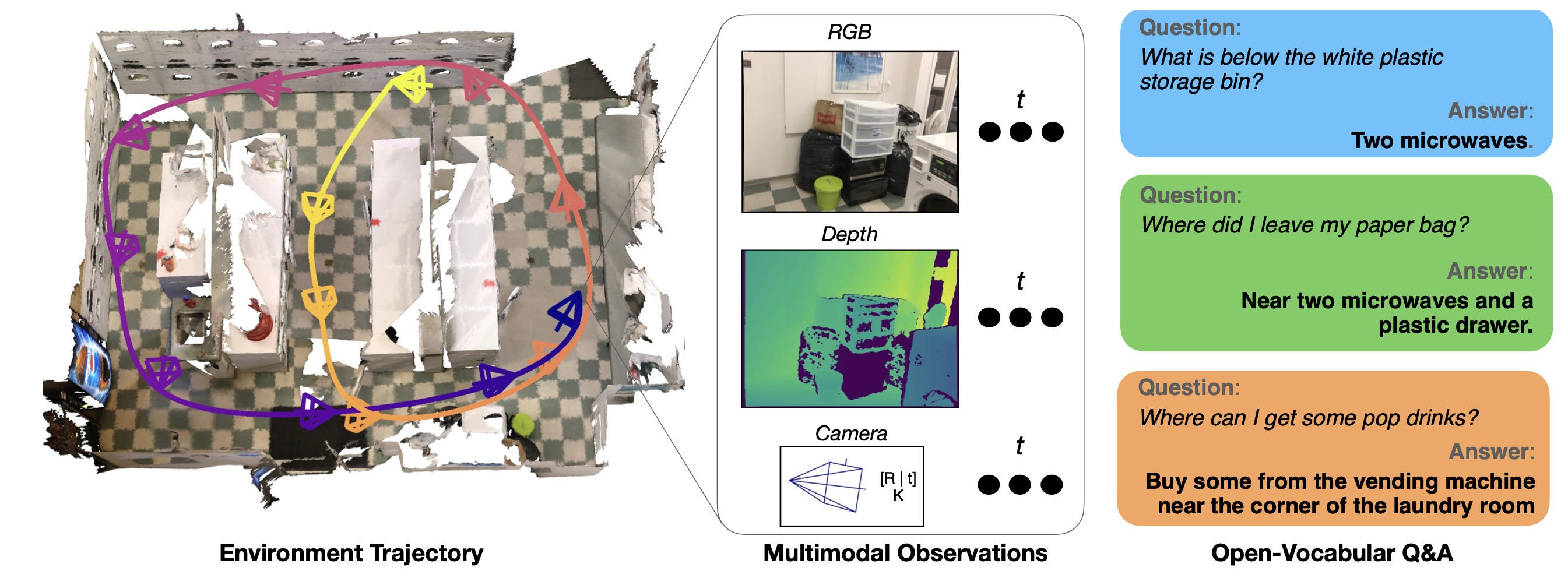
https://openaccess.thecvf.com/content/CVPR2024/papers/Majumdar_OpenEQA_Embodied_Question_Answering_in_the_Era_of_Foundation_Models_CVPR_2024_pape
13.RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
https://robotics-transformer2.github.io/assets/rt2.pdf https://github.com/kyegomez/RT-2 1. 개요 로봇공학에서의 새로운 transformer 모델인 Robotics Transformer 2(RT2)에 대해 설명하고 있습니다. RT2는 로봇의 다양한 작업 수행 능력을 향상시키기 위해 설...
14.TidyBot: Personalized Robot Assistance with Large Language Models

로봇이 가정 내에서 개인화된 도움을 제공할 수 있도록 하는 방법에 대해 연구특히, 로봇이 방을 정리할 때 사용자의 선호에 따라 물건을 적절한 장소에 배치하는 작업을 다룹니다.접근 방법: 이 연구에서는 대형 언어 모델(LLM)의 요약 기능을 활용하여, 소수의 예시를 통해