SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
foundation model in robotics
목록 보기
1/14
1. 이 논문 왜 봐?
- 목적
매우 넓은 실내 공간에서, 로봇이 다양한 Tasks를 수행할 수 있도록 하자!- LLM의 장점
- 로봇에게 다양한 tasks를 주었을 때, 어떻게 수행해야할지에 대한 합리적인 high-level plan을 생성해준다는 장점
- common sense를 탑재하고 있기 때문
- 로봇에게 다양한 tasks를 주었을 때, 어떻게 수행해야할지에 대한 합리적인 high-level plan을 생성해준다는 장점
1.1. 가벼운 예시
- input
- 3D scene graph (3DSG)
- 특정 환경에 대한 계층적 정보를 잘 담고 있는 계층 지도. (별도의 알고리즘으로 얻었다는 가정)
- 지시어: peter에게 커피를 만들어줘.
- 3D scene graph (3DSG)
- output
peter에게 커피를 만들어줘->커피 머신에 가서, 커피 잔을 집어서 머신에 올리고, 다시 집어서, 피터에게 데려다주는 계획을 로봇에게 주입
1.2. 논문 기여 3가지 포인트
- (1) exploit the hierarchical nature of
3DSGs to allow LLMs to conduct a semantic search for task-relevant subgraphs from a smaller, collapsed representation of the full graph; - (2) reduce the planning horizon for the LLM by integrating a classical path planner and
- (3) introduce an iterative replanning pipeline that refines the initial plan using feedback from a
scene graph simulator, correcting infeasible actions and avoiding planning failures
1.3. 논문의 한계점
- SayPlan의 현재 프레임워크는 미리 구축된 3D 장면 그래프를 필요로 하며, 맵 생성 후 객체가 정적 상태로 유지된다는 가정을 하기 때문에 동적 현실 세계 환경에 대한 적응력이 크게 제한
- 향후 연구에서는 이러한 문제를 해결하기 위해 온라인 장면 그래프 SLAM 시스템을 SayPlan 프레임워크에 통합하는 방법을 탐구할 수 있습니다.
- 장면 그래프 내에 오픈 보캐블러리(단어) 표현을 통합하여
- 텍스트 노드 설명만을 사용하는 대신 일반적인 장면 표현을 생성할 수 있을 것
- 현재 시스템의 잠재적 한계: 장면 그래프 시뮬레이터와 환경 내에서 발생할 수 있는 다양한 계획 실패를 포착하는 능력의 성능이 부족함
- 이 시스템은 이 논문에서 제시된 사례에서는 잘 작동하지만,
- 다양한 술어와 가능성을 포함하는 더 복잡한 작업의 경우,
- 각 상황에 대한 관련 피드백 메시지를 통합하는 것이 어려워질 수 있으며, 이는 이 분야의 향후 연구에서 중요한 과제가 될 것
2. 그림
2.1. 그림 1
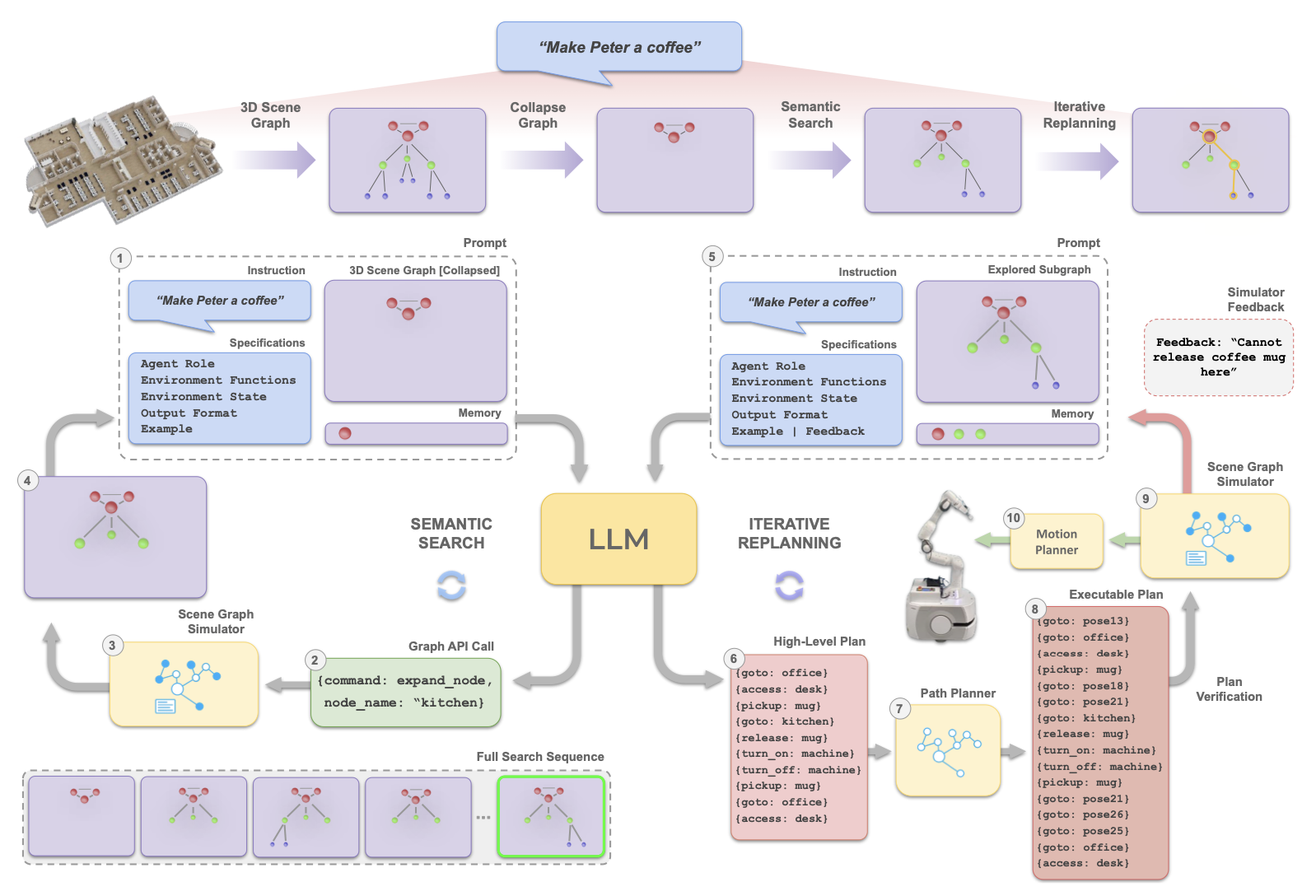
- SayPlan 시스템은 확장성을 유지하기 위해 두 단계로 진행
2.1.1. 첫 번째 단계
- LLM input:
collapsed 3D scene graph와작업 지시collapsed 3D scene graph- 상위 계층만 표시한 그래프 (예: 위 그림의 Room 만 표시한 그래프)
작업 지시커피를 만들어서 피터에게 가져다 줘!
- LLM의 역할
- 개요:
LLM(대규모 언어 모델)이 semantic search을 해서, 작업 해결에 필요한 아이템들이 있는 suitable subgraph 를 찾아냄 - 구체적 내용
- LLM은
작업 지시에 필요한collapsed graph의 nodes를 찾습니다.커피를 만들어서 피터에게 가져다 줘!- 커피를 만드려면 컵과 커피머신이 필요해.
- 피터의 컵은
오피스에 있을 가능성이 크니,expand_node(오피스)을 해서 하위 node들을 탐색해보자!- 하위 node에 컵이 있을만한 노드를 찾자! (
책상)- 책상의 하위 노드에 컵이 있는지 찾자!
- 하위 node에 컵이 있을만한 노드를 찾자! (
- 커피머신도
주방 node에 있을 가능성이 크다!expand_node(kitchen)을 해서 하위 node들을 탐색해보자!
- 위와 같은 로직으로, LLM이 task 수행에 필요한 node들(과 sub-node들)을 찾아내어 -> 최종적으로 적절한
explored subgraph를 만들어낸다.
- LLM은
- 개요:
2.1.2. 두번째 단계
- LLM input
- 1단계에서 얻은
explored subgraph와작업 지시
- 1단계에서 얻은
- LLM의 output
- high level plan
- 예
오피스로 가서->책상에 가서->컵을 잡고->주방으로 가서->커피머신을 켜고-> ...
- Path planner input
- high level plan
- Path planner Output
- Executable plan
- predefined 함수 call
- Executable plan
2.1.3. 마지막 단계
- 이 계획은
scene graph simulator 로부터의 피드백을 받아가며, - 실행 가능한 계획이 될 때까지 여러 번 다시 짜보는 과정을 거칩니다.
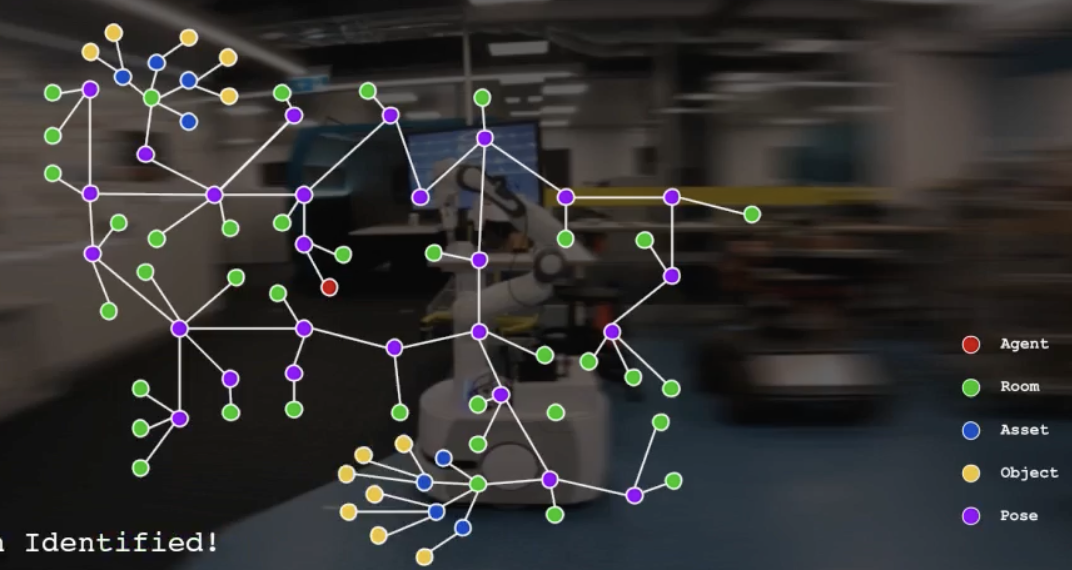
2.2. 3D Scene Graph(3DSG)
-
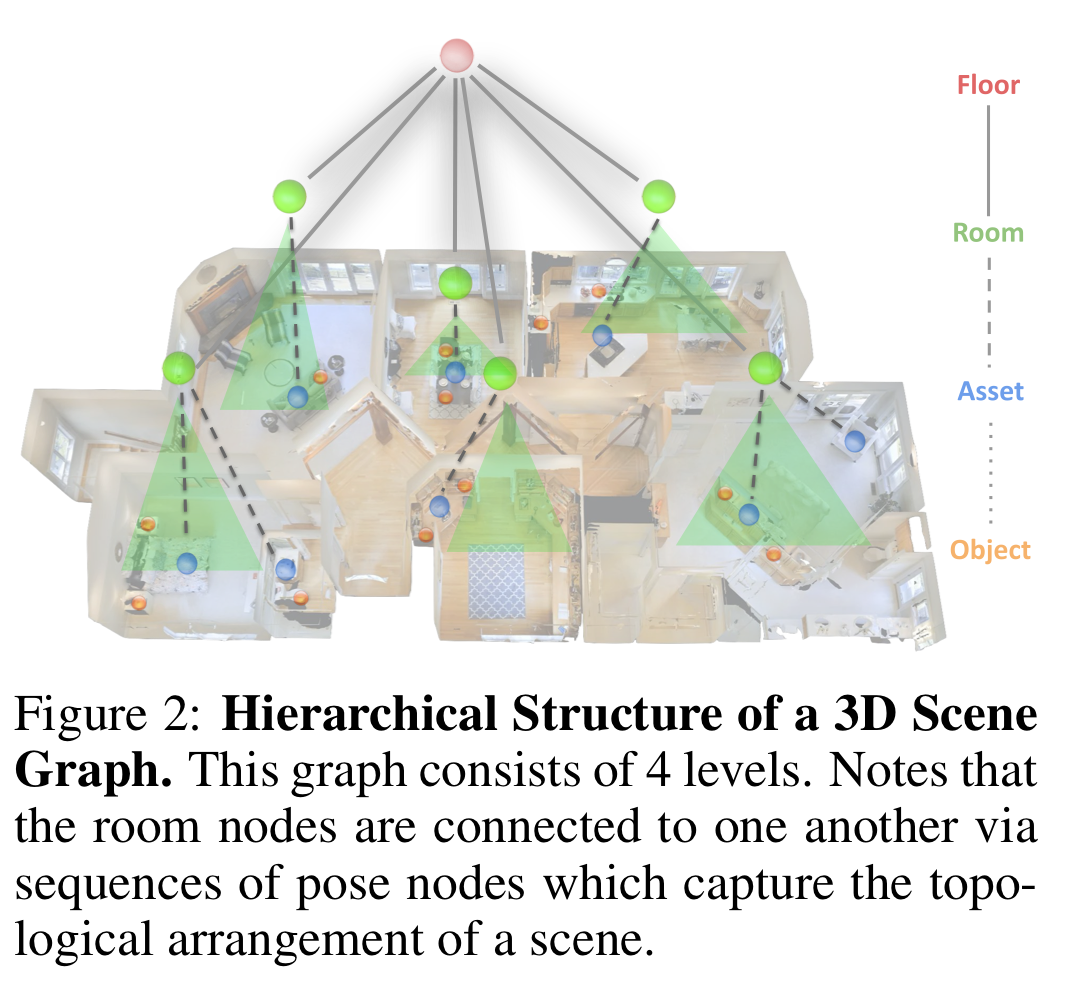
- floors
- rooms
- pose nodes와 연결되어 있음
- assets
- 정적 객체
- objects
- 동적 객체
-
assets과 objects 모두, 아래의 특징들을 포함함
- state, affordances, additional attributes
- 예: colour or weight, and 3D pose.
- state, affordances, additional attributes
-
위 그래프는 dynamic agent node도 포함합니다.
-
3DSG의 이 모든 정보는 JSON이라는 데이터 형식으로 저장될 수 있어서, LLM(대규모 언어 모델) 같은 프로그램이 이해하고 사용할 수 있습니다.
-
예: 단일 asset 노드
- {name: coffee_machine,
type: asset,
location: kitchen,
affordances: [turn_on, turn_off, release],
state: off,
attributes: [red, automatic],
position: [2.34, 0.45, 2.23]
}
- {name: coffee_machine,
-
그리고 NetworkX Graph object 로 3DSG가 표현될 수 있다.
2.3. Pseudo Code

-
1: G' ← collapseψ(G)
- 설명:
collapseψ(G)함수는 전체 3D Scene GraphG를 "축소"합니다. 즉, 이 과정에서 전체 그래프의 상위 수준(예: 층, 방)을 남기고 세부 정보를 제거하여 LLM이 다룰 수 있는 크기로 축소된 그래프G'를 만듭니다. 이 축소된 그래프는 LLM이 처리하기에 충분히 작으면서도 중요한 정보를 유지합니다.
- 설명:
-
Stage 1: Semantic Search
-
3: command, node_name ← LLM(P,G′,I)
- 설명: LLM은 입력된 프롬프트
P, 축소된 장면 그래프G', 작업 지시I를 바탕으로command와node_name을 생성합니다.command는 LLM이 다음에 수행해야 할 작업을 나타내며,node_name은 해당 작업이 적용될 그래프 노드의 이름입니다.
- 설명: LLM은 입력된 프롬프트
-
5: G' ← expandψ(node_name)
- 설명:
expandψ(node_name)함수는 지정된node_name노드를 확장합니다. 즉, 해당 노드와 연결된 하위 노드를 포함하는 세부 정보를 추가로 노출시켜G'그래프를 업데이트합니다. 예를 들어,node_name이 "부엌"이라면, 부엌 안의 물체들(예: 커피 머신, 냉장고 등)을 그래프에 추가합니다.
- 설명:
-
Stage 2: Causal Planning
- 설명: 이 단계에서는 실제 실행 가능한 계획을 생성하기 위해 LLM이 수행하는 과정이 포함됩니다.
-
8: feedback = ""
- 설명:
feedback변수를 초기화합니다. 이 변수는 LLM이 생성한 계획이 실행 가능한지 여부에 대한 피드백을 저장하는 데 사용됩니다.
- 설명:
-
9: while feedback != “success” do
- 설명: 이 반복문은
feedback이 "success(성공)"이 될 때까지 계속 실행됩니다. 즉, LLM이 생성한 계획이 실행 가능한 것으로 확인될 때까지 계속 반복됩니다.
- 설명: 이 반복문은
-
10: plan ← LLM(P,G′,I,feedback)
- 설명: LLM은 주어진 프롬프트
P, 축소된 장면 그래프G', 작업 지시I, 그리고 이전 피드백feedback을 기반으로 새로운 계획plan을 생성합니다. 이 계획에는 로봇이 수행할 고수준의 작업 순서가 포함됩니다.
- 설명: LLM은 주어진 프롬프트
-
11: full_plan ← φ(plan,G′)
- 설명:
φ(plan,G′)함수는plan을 사용하여 최적의 경로 계획을 계산하고, 이를full_plan으로 확장합니다. 이는 로봇이 목표 지점까지 어떻게 이동할지를 포함한 전체 계획을 의미합니다.
- 설명:
-
12: feedback ← verify_planψ(full_plan)
- 설명:
verify_planψ(full_plan)함수는full_plan을 시뮬레이터에서 실행해 보고, 이 계획이 실제 환경에서 실행 가능한지를 확인합니다. 계획이 실패하면 피드백을 반환하고, 성공하면 "success"라는 피드백을 반환합니다. - verify_plan:
- 생성된 계획을 3D Scene Graph(3DSG)로 캡처된 추상적인 그래프 수준에서 앞으로 시뮬레이션하여,
- 각 행동이 환경의 술어(predicates), 상태(states), 그리고 가능성(affordances)에 적합한지를 확인
- 예를 들어, 바나나를 포함한 냉장고가 닫혀 있을 경우, "바나나를 집을 수 없음"과 같은 텍스트 피드백을 반환
- 설명:
-
13: return full_plan
- 설명: 최종적으로, 실행 가능한 전체 계획
full_plan을 반환합니다. 이 계획은 로봇이 실행할 수 있도록 준비된 상태입니다.
- 설명: 최종적으로, 실행 가능한 전체 계획
3. Method
3.1. 의미 검색(Semantic Search)
- 3D Scene Graph(3DSG)을 사용하여 LLM 기반 계획을 세울 때 두 가지 중요한 점을 주목해야 합니다:
- 1) 대규모 환경의 3DSG는 포함된 방, 자산 및 객체의 수에 따라 무한히 커질 수 있어, LLM에 입력으로 전달하기에는 토큰 제한 때문에 비실용적이 됩니다.
- 2) 주어진 작업을 해결하기 위해 전체 3DSG의 일부분만 필요합니다. 예를 들어, 커피를 만들 때 화장실에 있는 치약에 대한 정보는 필요하지 않습니다.
- 이를 위해 의미 검색 단계에서는
- 주어진 작업 지시를 해결하는 데 필요한 환경 내의 항목만 포함된
- 작은,
작업별 하위 그래프 G′를 전체 3DSG에서 식별하려고 합니다.
- 먼저 G를 축소하여 상위 수준(예: 층 노드)만 노출시켜 초기 3DSG의 토큰 수를 약 80% 줄입니다.
- LLM은 이 축소된 그래프를 확장 및 축소 API 호출을 통해 조작하여 주어진 작업 지시 I에 기반한 원하는 하위 그래프를 식별합니다.
- 입력-출력 예제 세트를 사용한 인컨텍스트 학습(in-context learning)을 통해 달성되며,
- 체인 오브 소트(prompt chain-of-thought)을 활용해 LLM이 어떤 노드를 조작할지 결정하도록 합니다.
- 선택된 API 호출과 노드는 장면 그래프 시뮬레이터 내에서 실행되며, 업데이트된 3DSG는 LLM에 전달되어 추가 탐색이 이루어집니다.
- 확장된 노드가 작업과 관련 없는 항목을 포함하고 있는 것으로 확인되면, LLM은 토큰 제한을 관리하고 작업별 하위 그래프를 유지하기 위해 해당 노드를 축소합니다.
- 이미 축소된 노드를 다시 확장하는 것을 방지하기 위해,
- 이전에 확장된 노드 목록을 추가적인 메모리 입력으로 LLM에 전달하여 마르코프 결정 과정(Markovian decision-making process)을 촉진하고,
- 전체 상호작용 기록을 유지하지 않고도 SayPlan이 광범위한 검색 시퀀스를 처리할 수 있게 합니다.
- 모든 필요한 자산 및 객체가 현재 하위 그래프 G′에서 식별되면 LLM은 자동으로 계획 단계로 넘어갑니다.
- 부록 K 참고
3.2. 반복 계획 수정(Iterative Replanning):
- 앞서 식별된 하위 그래프 G′와 동일한 작업 지시 I를 바탕으로, LLM은 파이프라인의 계획 단계로 들어갑니다.
- 여기서 LLM은 주어진 작업 지시를 충족하는
- 노드 수준의 내비게이션(
goto(pose2)) 및 조작(pickup(coffee_mug)) 작업 시퀀스를 생성하는 작업을 수행
- 노드 수준의 내비게이션(
- 그러나 LLM은 완벽한 계획 에이전트가 아니며, 종종 환상을 일으키거나 오류가 있는 출력을 생성하는 경향이 있습니다.
- 특히 대규모 환경이나 장기적인 작업을 계획할 때 이러한 문제는 더욱 심화됩니다.
- 우리는 두 가지 메커니즘을 통해 LLM이 작업 계획을 생성하도록 돕습니다.
- 첫째,
- LLM의 계획 범위를 줄이기 위해 위치 수준의 경로 계획을 다익스트라(Dijkstra)와 같은 최적 path planner에 위임
- 예를 들어, [goto(meeting_room), goto(pose13), goto(pose14), goto(pose8), ..., goto(kitchen), access(fridge), open(fridge)]와 같은 일반적인 계획 출력을
- [goto(meeting_room), goto(kitchen), access(fridge), open(fridge)]로 단순화
- path planner는
고수준 위치 간 최적 경로를 찾는 작업을 처리하여 LLM이 작업의 필수 조작 부분(pickup(coffee_mug))에 집중할 수 있도록 함
- 둘째,
- 우리는 LLM의 자기 성찰(self-reflection) 능력을 활용하여
장면 그래프 시뮬레이터에서 생성된 계획이장면 그래프의 술어, 상태 및 가능성에 부합하는지 평가하는 텍스트 기반, 작업 무관 피드백을 사용하여생성된 계획을 반복적으로 수정
- 예를 들어,
- 로봇이 이미 무언가를 들고 있거나,
- 올바른 위치에 있지 않거나,
- 냉장고가 열리기 전에 바나나를 집으려 하면 pick(banana) 작업이 실패할 수 있습니다.
- 이러한 실패는 "바나나를 집을 수 없음"과 같은 텍스트 피드백으로 변환되어 LLM의 입력에 추가되고, 업데이트된 실행 가능한 계획을 생성하는 데 사용
- 이 반복 프로세스는 계획, 검증 및 피드백 통합을 포함하며 실행 가능한 계획이 얻어질 때까지 계속
- 검증된 계획은 low-level planner에게 전달되어 로봇 실행에 사용됩니다.
- 반복 계획 수정 중 LLM과 장면 그래프의 상호작용 예시: 부록 L
- 특정 구현 세부 사항: 부록 A

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.