- 2022년 7월 arXIv 첫 등재, 현재 175회 인용됨.
- https://proceedings.mlr.press/v205/shah23b/shah23b.pdf
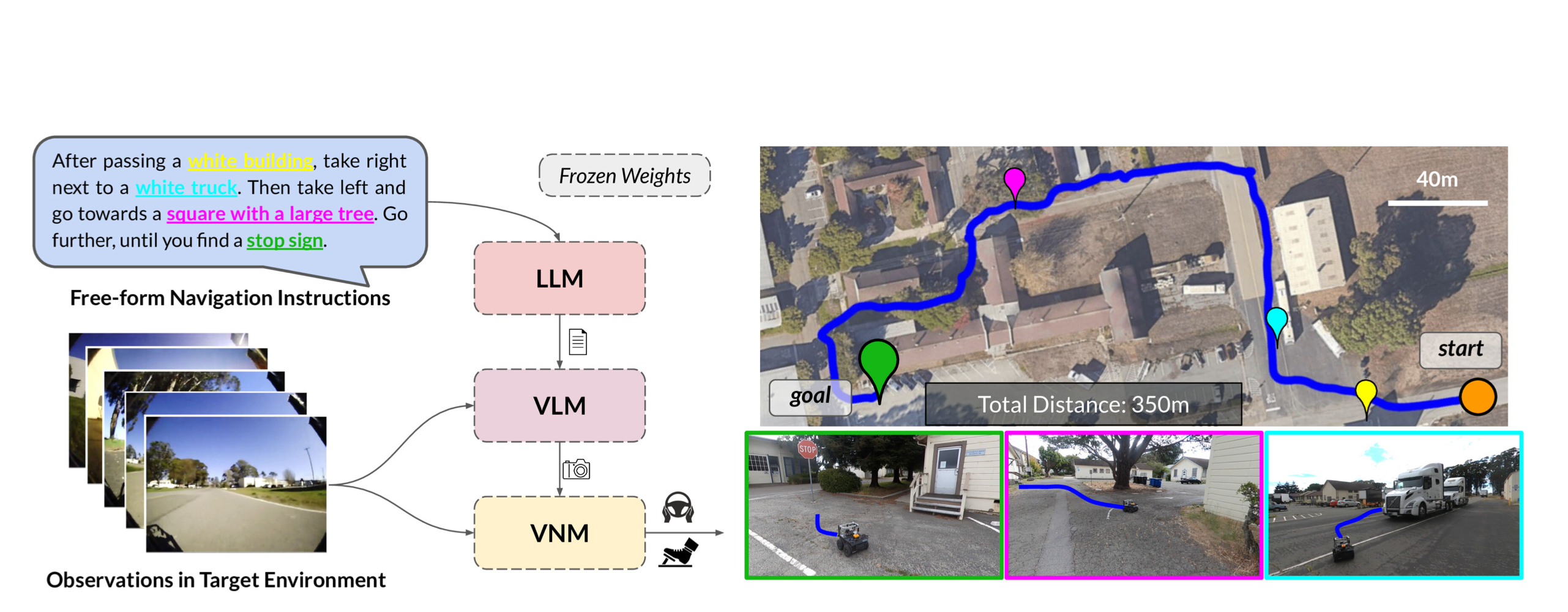
개요
- LM-Nav[13]은 환경 관찰을 위한 이미지를 노드로 저장하고, 이미지 간의 근접성을 에지로 나타내는 그래프 기반 접근법을 사용하는 알고리즘
- 환경 내 이미지(예: 특정 방의 사진)를 노드로 표현
- 이 방식은 GPT-3을 이용하여, 복잡하고 다양한 언어 지시를 정확하게 파싱 -> 관련 랜드마크로 변환
- 이후, CLIP을 이용해어 생성된 랜드마크 목록들이 어떤 노드와 일치하는지 결정하고, 그래프 상에서 해당 노드로의 경로를 계획
- 이 과정을 통해, 알고리즘은 사용자의 언어 지시를 구체적인 그래프 상의 경로로 변환
0. Abstract
4. Method
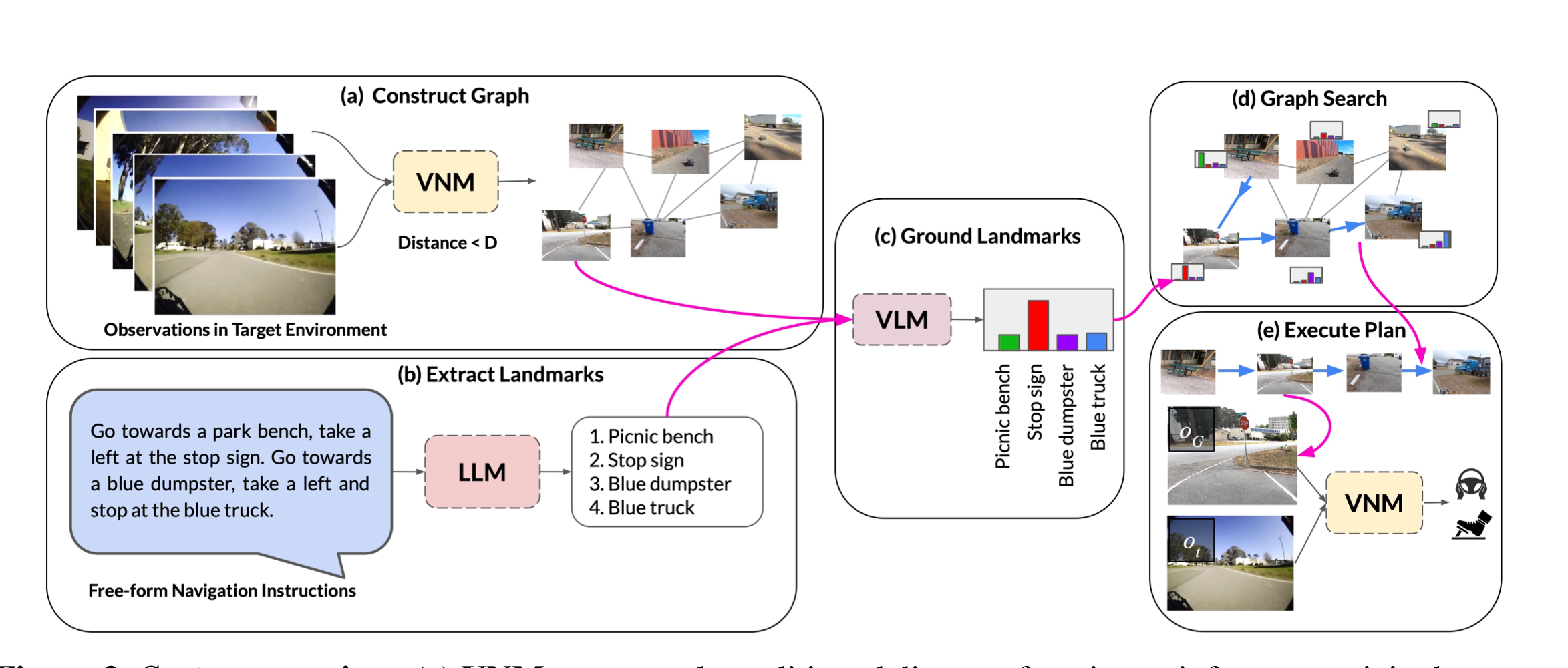

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.