이 논문으로 부터 얻은 것
Image goal navigation / 고급 라우팅 명령 (turn-by-turn directions)을 Input으로 활용하면, Localization 성능에 구애 받지 않는 주행 알고리즘 구현 가능- localization 알고리즘 사용 못하고, 공간에 대한 지도도 없는 상황에서, 공간 탐색 주행 알고리즘을 개발하기 위해서,
diffusion model로, exploration sub-goal 후보군들을 생성할 수 있겠구나!- Visual navigation을 통해, exploration 알고리즘을 개발해보는 것도 좋은 연구주제!
- visual navigation에서, exploration or 장거리 주행을 위해서는
위상 그래프를 구축하는구나.
- action space를 normalized relative waypoint로 가져가면,
- 로봇의 목표가 다양해도, 하나의 모델로 처리할 수 있겟구나.
- hz가 빠르지 않아도 괜찮겠구나.
- visual navigation에서, 이미지 해상도를 85 × 64 × 3 와 같이 매우 작게 가져가는구나.
- 목표 sub-goal 이미지: 0.5초에서 2.5초 미래의 목표 이미지 샘플링
- 카메라 센서 위치, 로봇 형태 등이 바뀌어도 하나의 모델로 주행하려면, 여러 데이터셋을 기반으로 goal-conditioned pre-train 학습을 하면 되겠구나!
0. abstract
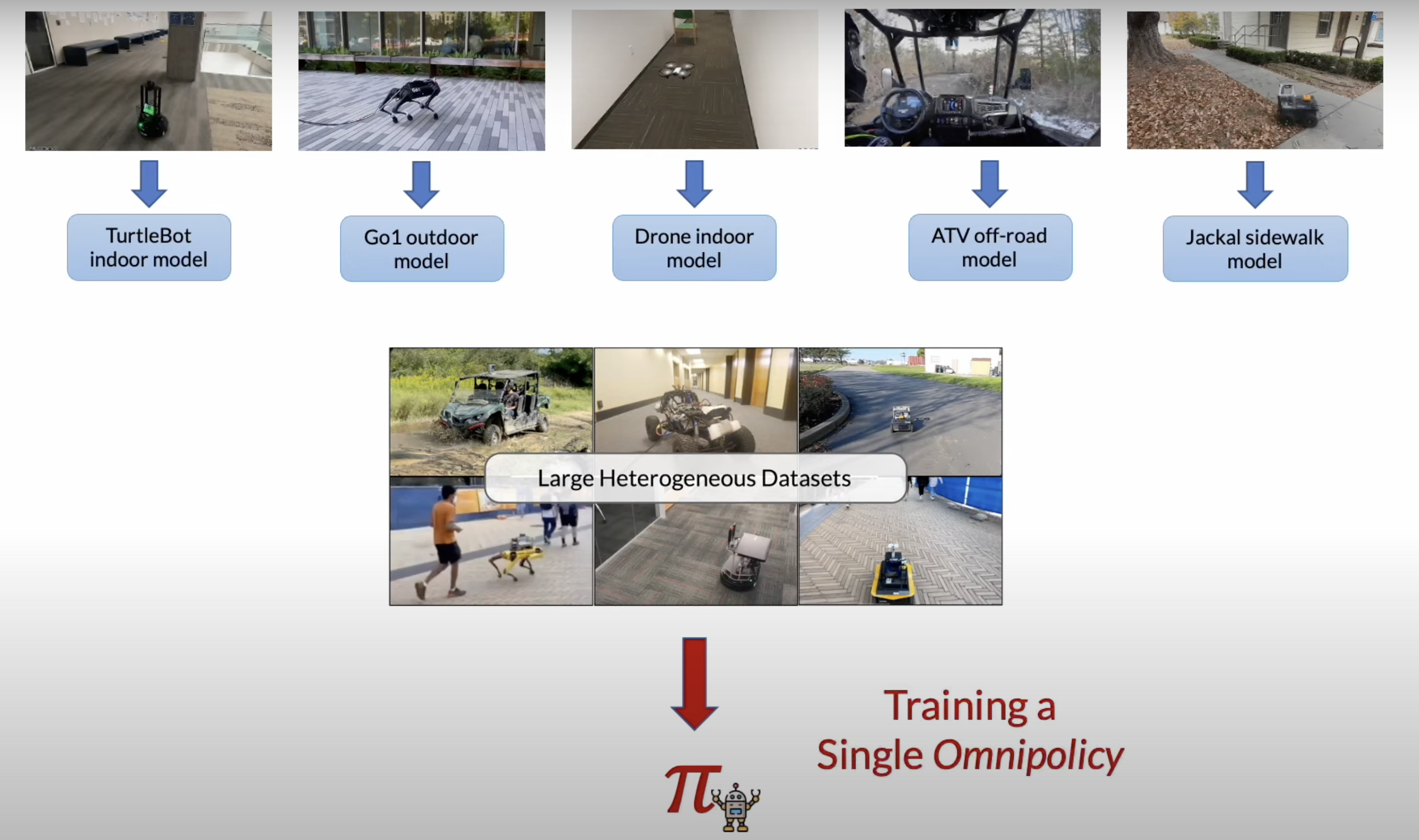
- 'Foundatation model' for visual navigation!
- 이 모델을 이용하면, 아래 new task들에 대해 zero(few) shot 적응이 가능!
- Coverage Mapping (Exploration)
- Image goal navigation [21]
GPS waypoints도달 [20]- 고급 라우팅 명령 (
turn-by-turn directions) - skill-conditioned-driving [22]
- 이 모델을 이용하면, 새롭고 유용한 설정(예: 카메라 센서 위치, 로봇 형태, 환경 등)에서 제로샷으로 사용될 수 있음
- 이 모델을 이용하면, 아래 new task들에 대해 zero(few) shot 적응이 가능!
- ViNT는 "어떤 내비게이션 데이터셋에서든 self-supervised manner로 사용할 수 있는" 일반적인 goal-reaching 목적으로 pre-train됨 (별도의 labelling이 필요없는 task로 pre-train)
- 즉, goal RGB image 주면, 로봇이 찾아가도록 훈련
- 이 때, 로봇은 최근에 관찰한 RGB images와 goal image를 input으로 사용합니다.
- ViNT는 다양한 로봇 플랫폼에서 수백 시간의 로봇 내비게이션을 포함하는 기존 내비게이션 데이터셋들에서 훈련됨
- ViNT는 새로운 환경에 대한 탐색 문제를 풀 때, diffusion-based subgoal proposals과 결합하여, 탐색에 효과적인 sub-goal 생성을 할 수 있어서,
- (장거리 휴리스틱을 갖추고 있을 때,) 킬로미터 규모의 탐색 문제를 해결할 수 있음
- 또한, ViNT는
프롬프트 튜닝에서 영감을 받은 기술을 사용하여, downstream task에 맞게 쉽게 Fine-tuning 할 수 있어요.- goal encoder를, 다른 task modality(e.g.,
GPS waypointsorturn-by-turn directions)의 encoding으로 대체함으로써, 동일한 목표 토큰의 공간에 내장됩니다.
- goal encoder를, 다른 task modality(e.g.,
1. 한계점 및 향후 연구
- 많은 대규모 모델들과 마찬가지로, ViNT는 추론 시간에 더 무거운 계산 부담
- 우리의 설계는 효율적인 추론을 가능하게 하려는 목표를 가지고 있지만, 우리의 Transformer 기반 모델은 여전히 상당히 더 비용이 많이 듭니다.
- 또한, ViNT는 우리의 실험에서 로봇들 사이에서 효과적으로 일반화하지만, 일정 수준의 구조적 유사성을 가정
- 예를 들어, 쿼드콥터의 고도를 제어하거나, action 표현의 다른 변화를 다루거나, LIDAR와 같은 새로운 센서를 수용할 수는 없습니다.
2. related work
2.1. 기존 연구의 한계점
- 다양한 동역학과 카메라 설정(예: 초점 거리, 시야 범위 및 외부 특성 등)을 가진 모바일 로보틱스 응용 프로그램의 경우, 현재 접근 방식은 대체로
- 단일 로봇 플랫폼을 대표하는 작은 실제 세계 데이터셋이나,
- 학습된 정책을 전달하기 위해 로봇과 환경 모델이 짝을 이루는 시뮬레이션에서 학습하는 방식에 의존
- 실제 세계 설정에서 배치된 로봇들에 대해 환경과 구현을 넘나드는 넓은 일반화를 연구한 과거 연구
- RT-1
- 다양한 high level 지시를 따름
- BUT, 다양한 작업에 잘 적응하는 능력은 없음
- I2O
- 시뮬레이션에서 실제 세계 환경으로의 인상적인 전환
- BUT, 다양한 작업에 잘 적응하는 능력은 없음
- GNM[19]
- Image goal navigation 분야에서, 다양한 RGB 센서 구성에서 잘 적응
- BUT, 다양한 작업에 잘 적응하는 능력은 없음
2.2. 본 논문이 제시하는 방향성
- 우리의 목표는 이러한 각각의 문제에 대한 전문가 솔루션을 훈련시키는 것이 아니라, 하나의 고용량 모델이 다양한 작업에 맞게 조정될 수 있는 방법을 보여주는 것
2.3. 본 논문에 대한 설명
- 여러 다른 실제 세계 로봇 시스템에서 수집된 데이터에서 navigation 행동을 학습하는 패러다임 제시
- visual navigation 연구의 대부분과 마찬가지로, 아래 3가지 기술 사용
환경의 공간 표현을 유지하기 위한 위상 그래프- 로봇이 환경을 인식하고 내부적으로 맵을 구성하는 방법과 관련
- 위상 그래프는 환경의 다양한 지점들(노드)과 그 지점들 사이의 연결(간선)을 추상화하여 표현한 것
- 예를 들어, 방과 복도를 노드로, 문을 통한 연결을 간선으로 표현 가능
low-level control를 위한 학습된 정책[23-28],새로운 환경에서 로봇을 안내하기 위해 학습된 휴리스틱을 사용[15, 29]- 로봇이 새로운 환경에서 탐색할 때, 이전에 학습한 휴리스틱을 적용하여 더 효과적으로 목표에 도달할 수 있음
- 예를 들어, 로봇은 더 넓은 공간을 향해 이동하는 경향이 있거나, 특정 장애물을 회피하는 방법을 학습할 수 있습니다.
3. method
3.1. pre-training 하는법 소개!
- image goal 내비게이션 모델은 최소한의 가정으로 훈련될 수 있으며,
- GT 위치 확인, semantic label, 또는 기타 메타데이터에 대한 요구 없이 비디오와 행동이 포함된 어떤 데이터든 활용할 수 있어요.
- 이는 다양한 로봇에서 출처를 가진 크고 다양한 데이터셋에서 실용적으로 훈련할 수 있게 해, 넓은 일반화를 촉진시켜요.
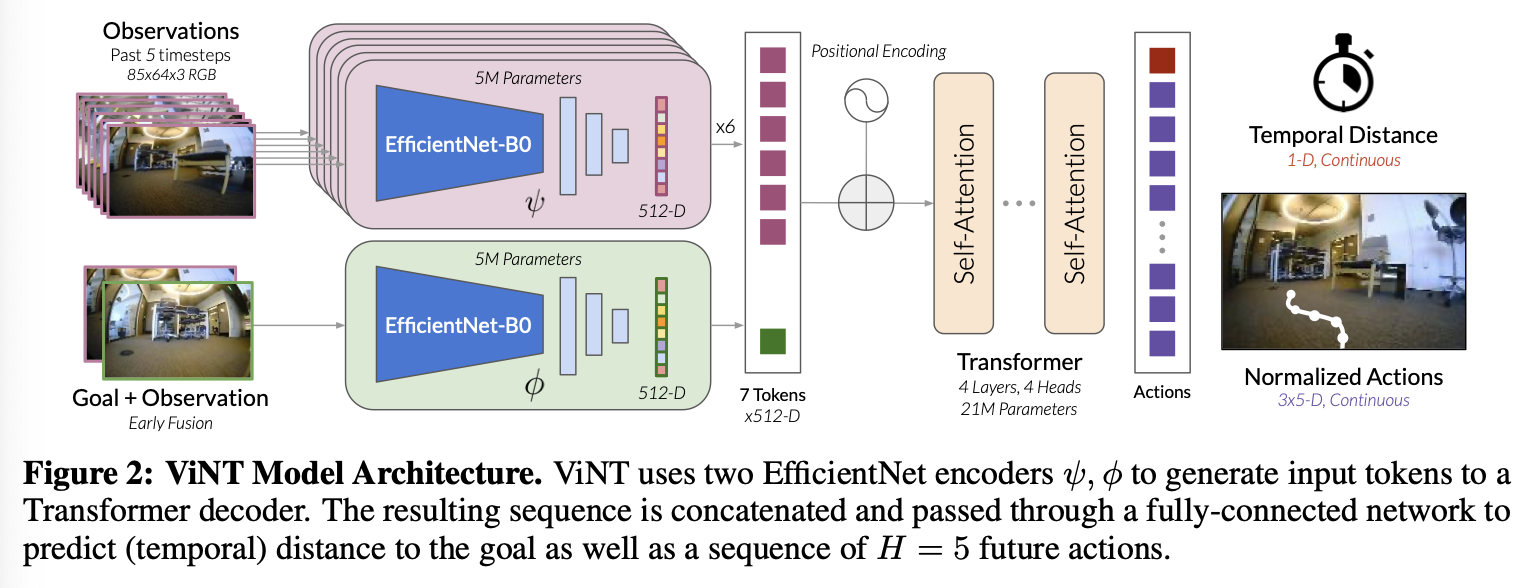
- 설명
- 31M parameter
- input
- 현재과 과거의 RGB image (보통 P = 5)
- 해상도: 85 × 64 × 3
- sub goal RGB image
- 목표 이미지: 0.5초에서 2.5초 미래의 목표 이미지 샘플링
- 현재과 과거의 RGB image (보통 P = 5)
- output
- the number of time steps needed to reach the subgoal (the dynamical distance)
- 부목표로 향하기 위한 미래 relative waypoint 좌표들 (H 길이 시퀀스)
- training objective

3.1.1. 훈련 데이터
- 다양한 동역학, 카메라 파라미터, 그리고 행동을 가진 다양한 환경과 로봇 플랫폼에서 온 이질적인 내비게이션 궤적들의 대규모 데이터셋을 사용하여 ViNT를 훈련
- 훈련 데이터셋에는 완전히 기존 데이터셋에서 가져온 100시간 이상의 실제 세계 궤적들이 포함되어 있어요.
- 이 데이터셋은
속도와 동역학이 다양한 8개의 독특한 로봇 플랫폼을 아우르고 있어요.데이터셋에 대한 더 자세한 정보는 부록 C에서 확인할 수 있어요.
3.1.2. 로봇 본체에 구애받지 않는 action space!!
- 다양한 크기, 속도, 그리고 동역학을 가진 로봇들에게 하나의 모델을 효과적으로 훈련시키기 위해, 우리는 Shah 등[19]이 제안한 로봇 본체에 구애받지 않는 action space을 ViNT에 적용
- low level control 를 추상화하기 위해서, ViNT는
relative waypoints 를 행동 공간으로 사용 - 로봇의 속도와 크기의 큰 변동을 고려해서, 이 웨이포인트들을 로봇의 최고 속도에 맞춰 스케일링하여 정규화해요.
- 배치 시에는 로봇별 컨트롤러를 사용하여 이 웨이포인트들을 비정규화하고 저수준 제어를 이용해 추적
3.2. pre-training 디테일
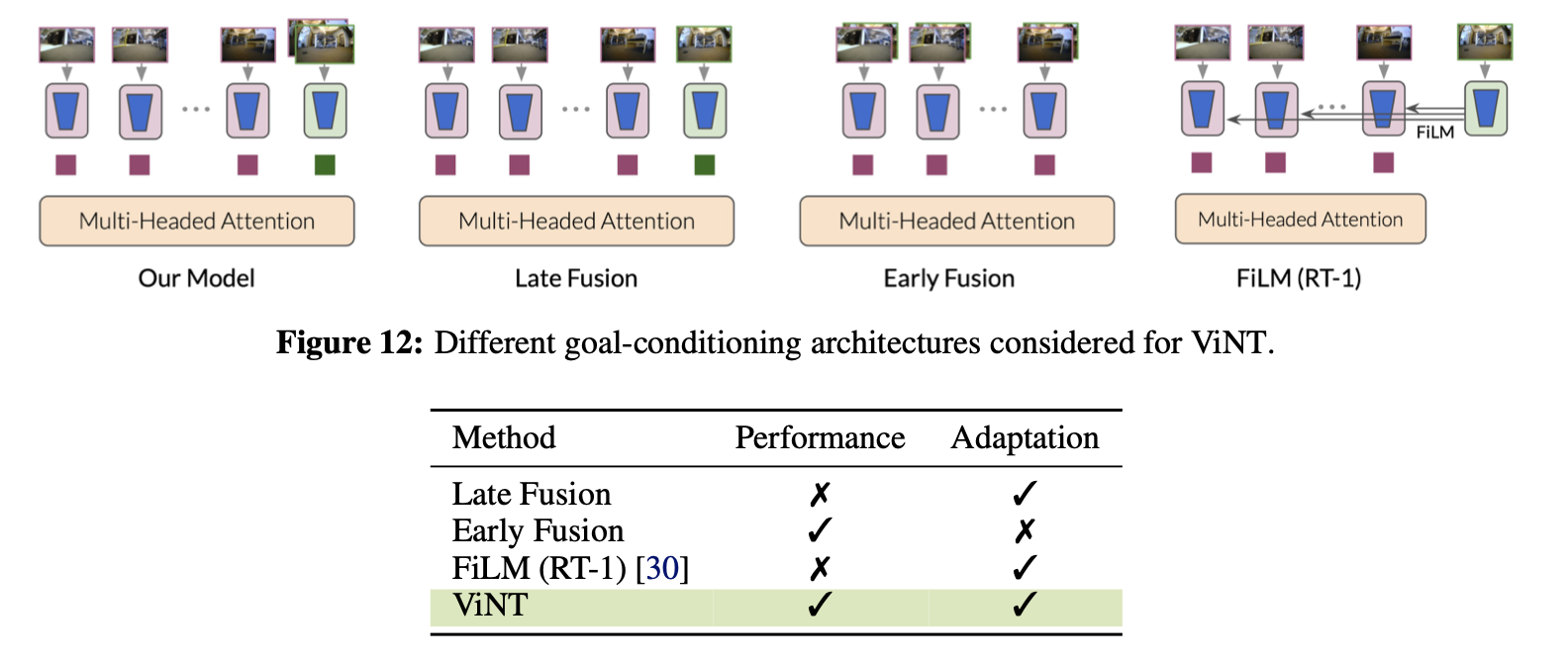
- 연구팀은 목표 이미지를 모델에 통합하는 세 가지 다른 방식을 고려했어요.
- 첫 번째는 '후기 융합'
- 관찰과 목표 이미지를 따로 분석한 다음 나중에 정보를 합치는 방식
- '후기 융합' 방식은 성능이 좋지 않았어요.
- 왜냐하면 이미지 기반 내비게이션에서 중요한 건 관찰 이미지와 목표 이미지 사이의 상대적인 특성이기 때문이에요.
- 두 번째는 '초기 융합'
- 성능이 좋았어요.
- 하지만 이 방식은 새로운 목표를 다루기 위해선 인코더를 처음부터 다시 학습해야 한다는 단점이 있었죠.
- 그래서 연구팀은 ViNT에서는 위 our models 방식을 제안했어요 (2가지 인코더)
- 하나는 관찰 이미지를 분석하는 인코더이고, 다른 하나는 목표 이미지와 현재 이미지를 함께 분석하는 인코더예요.
- 이렇게 하면, 새로운 목표에 맞추기 위해 두 번째 인코더를 교체하기만 하면 되니, 더 유연한 접근법이 가능해져요.
3.2.1. inference 시
- 시간 t에서 부목표 이미지 s가 주어지면,
모델을 4Hz로 실행하고, PD 컨트롤러를 사용하여 예측된 웨이포인트 a^를 뒤에 이어가며 추적해요.
3.3. downstream task: 장거리 내비게이션과 ViNT
- ViNT에 의해 사전 학습된 정책은, 탐색 허용 범위와 장애물에 대한 일반적인 이해를 포착하지만, 그 자체만으로는 적용 가능성이 제한적
- 많은 실용적인 작업들은 목표 이미지로 정의되지 않거나, ViNT가 직접 지원하는 것보다 훨씬 더 긴 지평선을 요구해요.
- ViNT 모델을 사용해,
로봇이 새로운 환경을 탐색하고 목표를 찾아가는 방법- '에피소드 메모리': 로봇이 짧은 기간 동안의 sub goal들을 추적하며 멀리 있는 목표지점에 도달할 수 있도록 도와주는 위상 그래프
- 이 위상 그래프는 서로 다른 위치들 사이의 연결성을 나타내는데, 로봇이 그 환경을 탐험하면서 만들어냄
- 새로운 환경에서는, 이 그래프를 기반으로 한 계획을 세우는 것을 넘어서,
- 로봇이 더 많이 탐험하고 새로운 경로를 발견하게 하는, 탐험적인 sub goal 제안을 추가할 수 있어요.
- 이런 방식으로, ViNT는 아직 본 적 없는 환경을 탐색하면서 목표로 가는 길을 찾아내는 데 도움을 받게 돼요.
- 이렇게 탐험적인 sub goal 제안을 통해, ViNT는 새로운 환경을 더 효과적으로 이해하고, 목표에 도달하기 위한 최적의 경로를 발견할 수 있는 능력을 키울 수 있어요.
- 우리는 여러 가지 제안 메커니즘을 고려하고,
현재 관찰을 기반으로, 다양한 미래 sub goal 후보를 샘플링하는,image diffusion model에 의해 최대 성능이 달성된다는 것을 발견- 이러한 sub-goal들은, 목표로 향하는 진전을 이루는 가장 좋은 sub-goal를 식별하기 위해, 목표 지향적 휴리스틱으로 점수를 매기는 물리적 A* 검색과 유사한 과정을 사용
- 위상 그래프에서 sub goal 새 노드들의 연결성은 ViNT가 예측한 거리에 의해 결정
- 탐험하는 동안, 우리는 로봇이 환경을 탐색함에 따라 이 위상 그래프를 실시간으로 구축
3.4. High-level 계획 및 탐색
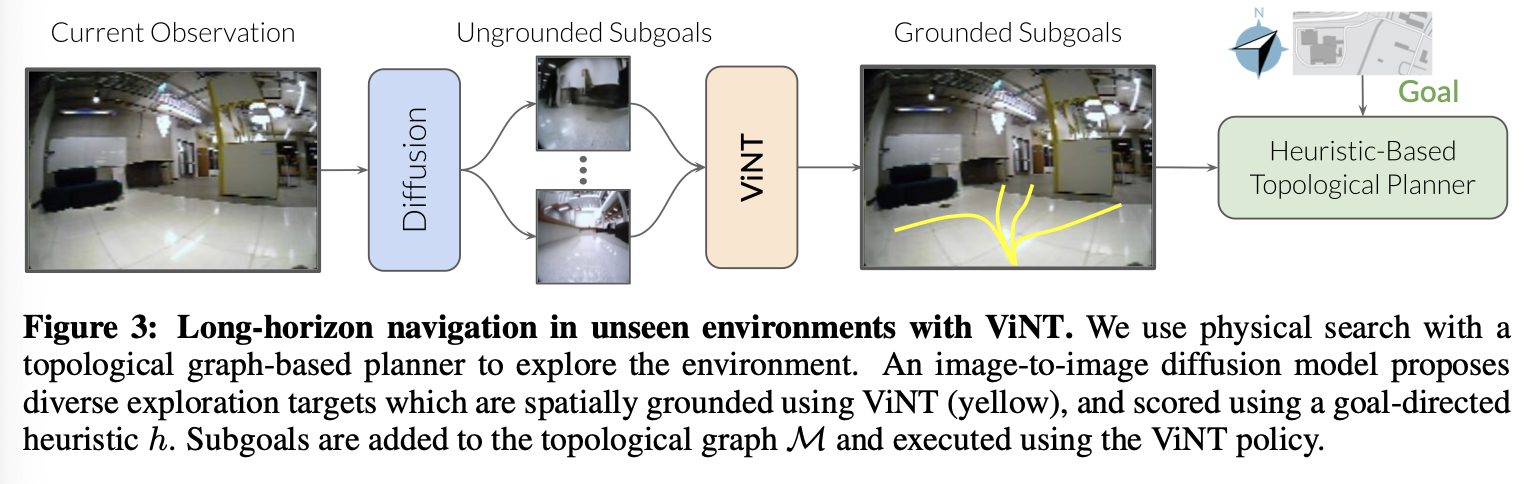
- 우리가 ViNT가 계획을 세울 수 있는 sub-goal 후보 ( o_{si} \in S )을 확보했다고 가정(나중에 이에 대한 설명 나옴)
- 우리는 이 sub-goal 후보들을 새로운 환경에서 목표 지향적 탐색을 위한 탐색 프레임워크에 통합
- 여기서 사용자는 멀리 떨어져 있을 수도 있는 고수준 목표 ( G )를 제공
- 우리는 이전 연구[29]를 대부분 따르지만, 배운 모델들을 ViNT와 diffusion model로 교체
3.4.1. sub-goal diffusion
- sub-goal를 생성하기 위해, 우리는 이미지 대 이미지 확산 모델을 사용
- 이 모델은 입력 이미지 (ot)를 받아서 (o{si} | o_t) 에서 샘플을 생성하는데,
- 여기서 (o_{si})는 (o_t)로부터 도달 가능한 후보 부목표 이미지들이에요.
- 확산 모델을 위한 훈련 쌍을 생성하기 위해, 우리는 먼저 훈련 데이터에서 (o_t)를 무작위로 균등하게 선택하고,
- 그 다음 (o_{si})를 (o_t)로부터 미래로 5에서 20 타임스텝 사이에서 선택
- 그러나, 이 sub-goal 생성물은 공간적으로 구체화되지 않은 것:
- 우리는 이 후보들을 ViNT를 사용하여 시간적 거리 (d(s_i, o_t))와 행동 롤아웃 (a(s_i, o_t))을 계산함으로써 구체화합니다.

- 이는 그림 6과 같이 구체화된 sub-goal들의 집합을 제공
- 확산 모델에 의해 생성된 샘플들이 반드시 실제 관찰과 일치하지는 않지만(그림 3 참조),
- 이들은 (o_t)로부터 충분한 상대적 특징들을 보존하여 그럴듯하며, 우리는 ViNT가 생성된 부목표들에 잘 일반화된다는 것을 발견
3.4.1.1. 디테일 (스킵해도 됨)
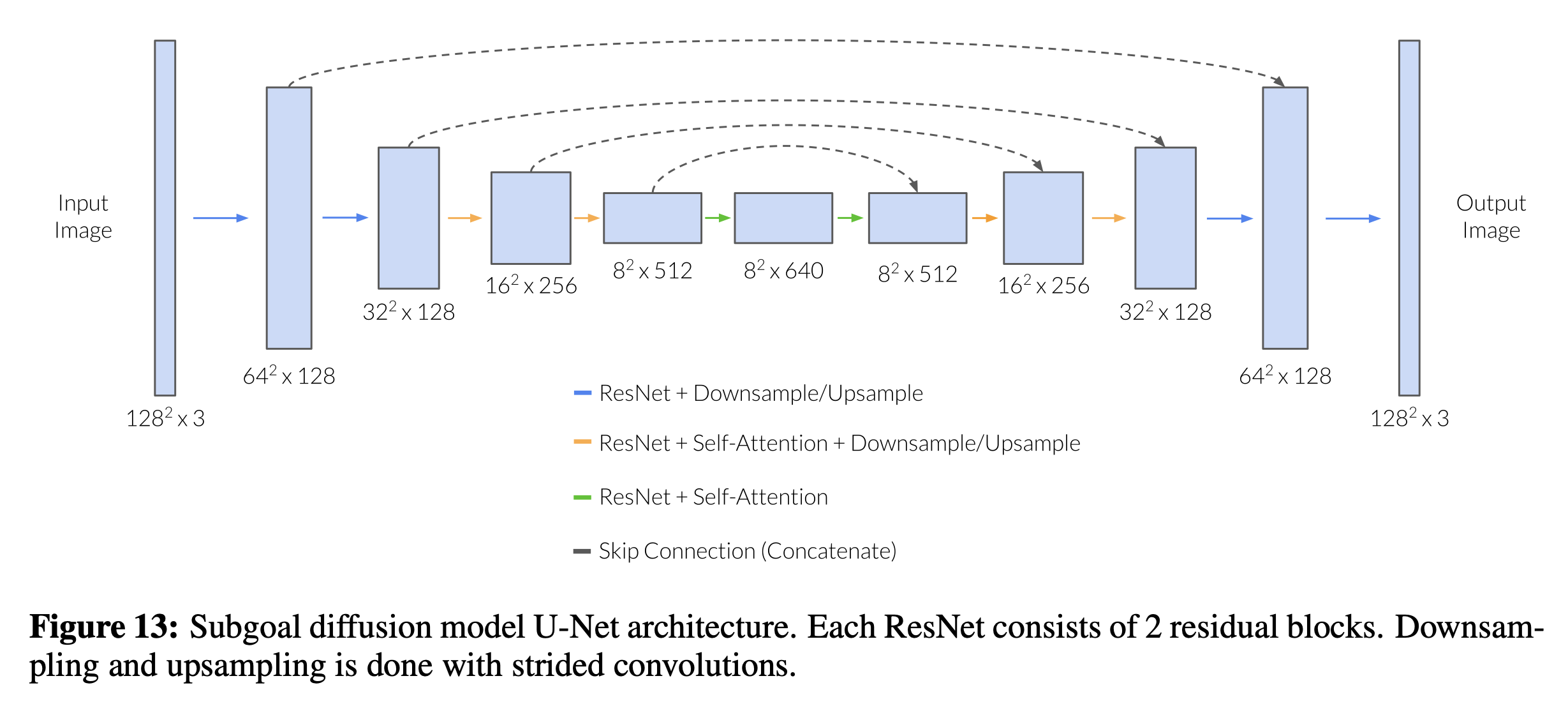
- Saharia et al. [39]을 따라서, 우리는 이미지 조건을 U-Net 입력에 대한 단순한 채널별 연결로 구현해요.
- 우리는 텍스트 입력에 대한 조건을 고려하지 않기 때문에, 텍스트 크로스-어텐션을 제거한 diffusers 라이브러리 [48]의 Flax U-Net 구현을 사용해요.
- 우리는 Kingma et al. [49]의
continuous-time diffusion formulation을 사용하는데, 배운 노이즈 스케줄 대신에fixed linear noise schedule을 사용해요. - 또한 Kingma et al. [49]와 달리, 우리는
unweighted training objective인 Ho et al. [38, Equation 14] 및 Kingma et al. [49, Appendix K]에서 Lsimple로 불리는 것을 사용해요. - 우리는
classifier-free guidance[50]를 사용하고 이것이 우수한 시각적 정확도를 가진 부목표를 생성하는 데 도움이 된다는 것을 발견했어요, 이는 이전 연구 [51]와 일관됩니다.
3.4.2. 위상 그래프를 통한 장거리 물리적 탐색
- 우리는 에피소드 메모리로 작용하는 온라인 위상 그래프 ( M )을 구성해요.
- 여기서 로봇은 목표를 찾아가며 점진적으로 ( M )을 구축해요.
- sub-goals 중 goal로 유도하기 위한 sub-goal을 선택하기 위해,
목표 지향적 휴리스틱( h(ot , o{si} , G, M, C ) )을 사용하여 sub-goal position들을 평가해요.- 로봇은 추가적인 맥락 ( C )
(예를 들어, 배치도나 위성 BEV 이미지[15, 29] )을 고려하여, 목표에 도달할 가능성에 따라 sub-goal 후보들을 평가
- 로봇은 추가적인 맥락 ( C )
- 우리의 실험에서는, 아래 두 가지 후보 검색 휴리스틱을 고려해요.
- 로봇과 목표의 위치에 기반한 기하학적(거리 기반) 휴리스틱
드론 BEV 이미지형태의 추가적인 맥락에 기반한 학습된 휴리스틱
- 그런 다음 로봇은
A*와 유사한 플래너를 사용하여 이 휴리스틱에 따라 최선의 sub-goal ( o_s^* )을 선택하고, - ( M )에 추가한 뒤 ViNT를 사용하여 그것을 향해 나아가요(그림 3).
3.4.3. Appendix (이해 완전히는 못한 부분)
- Shah와 Levine [29]과 같이, 우리는 표준 A* 알고리즘과 유사하게 물리적 탐색을 구현
- 여기서 우리는 가능한 방문하지 않은 sub-goal들의 열린 집합 Ω을 추적하고 Alg. 1을 따라요.
- 노드는 아래의 비용 함수 [f(s) = dM(o_t, s-) + d{pred}(s-, s) + h(s, G, C)]에 따라 방문됨
- 현재 상태 (o_t)에서 부모 노드 (s-)까지의 거리(그래프를 따라 측정됨),
- (s-)에서 (s)까지 예측된 거리,
- 장거리 탐색 힌트를 제공하는 휴리스틱 함수 (h) (A*의 그것과 유사함)
- 일반적으로, 휴리스틱은 sub-goal (s)와 장거리 목표 (G) 사이의 거리 개념을 제공하는 어떤 함수일 수 있고, 선택적으로 어떤 맥락 (C)를 포함할 수 있어요.
- 우리의 실험에서, 우리는 접근 방식의 유연성을 보여주기 위해 세 가지 휴리스틱을 고려했어요:
- 커버리지 탐색:
- 우리는 커버리지 탐색 에서는, 장거리 안내가 없으므로 (h(s) = 0)을 사용
- 위치 가이드:
- 야외에서 장거리 GPS 목표와 실내에서 2D 위치 목표를 위해, 우리는 유클리드 거리 (h(s) = |s - G|)를 사용
- 드론 기반 위성 가이드: (우리 domain에서 불가능)
- 커버리지 탐색:
4. ViNT: 다운스트림 태스크를 위해.
- 우리는 ViNT가 image goal로 내비게이션하는 것을 넘어서, 다양한 다운스트림 태스크에 적응할 수 있음을 보여줍니다.
4.1. Full Model Fine Tuning:
- ViNT는 새로운 환경과 "새로운 형태의 로봇"에 대해 강력한 제로샷 일반화를 보이지만, 동일한 목표를 사용하되 태스크 데이터를 사용하여 전체 모델을 fine tuning 함으로써 태스크 성능을 더욱 향상시킬 수 있습니다.
- ViNT는 내비게이션 데이터 1시간만으로 새로운 환경과 "새로운 형태의 로봇"을 마스터할 수 있으며, 처음부터 다시 훈련할 필요 없이 새 설정으로 원래 모델의 능력을 전달할 수 있습니다.
4.2. 새로운 모달리티에 적응하기
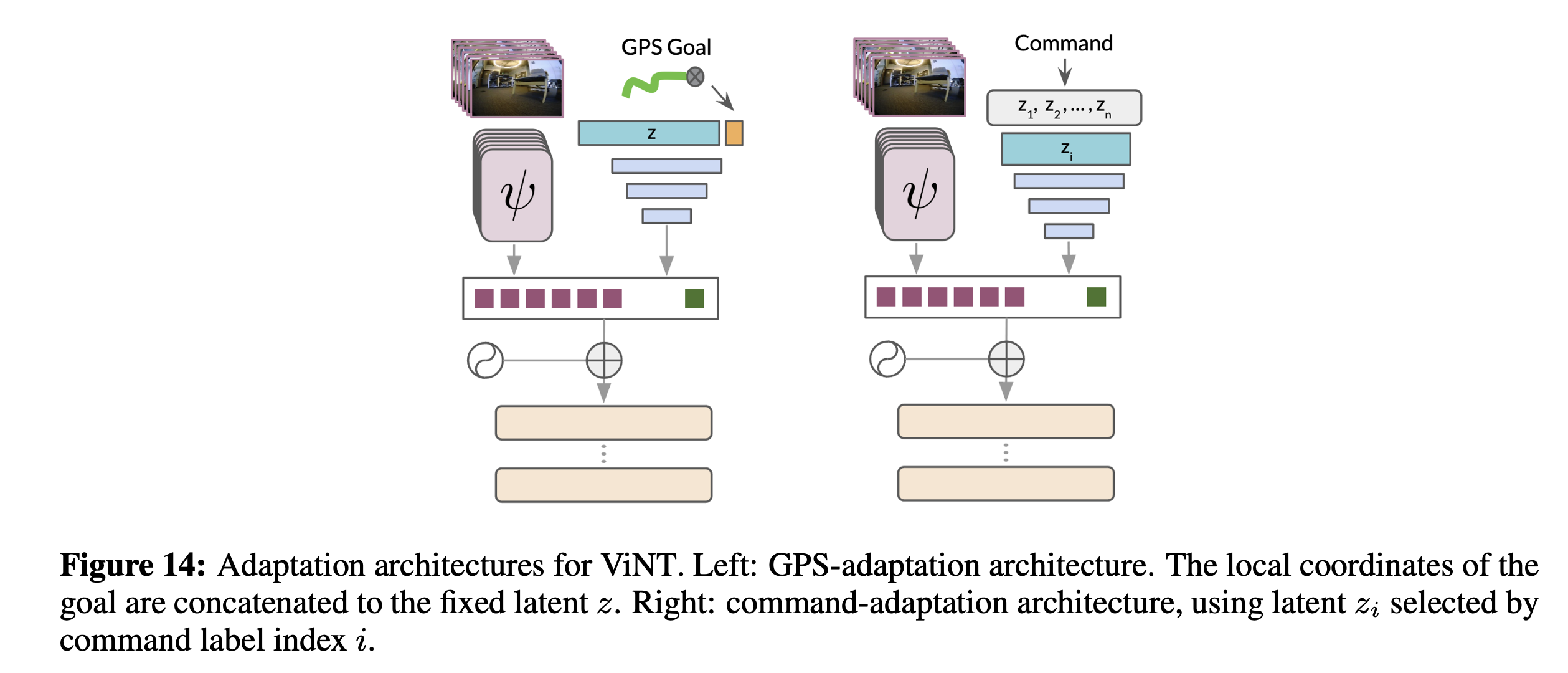
- ViNT는 원하는 목표 모달리티에서 ViNT 목표 토큰으로의 "소프트 프롬프트" 매핑을 학습함으로써 다른 일반적인 목표 지정 형태에 쉽게 적응할 수 있습니다.
- 여기서 "목표 모달리티"란 로봇이 달성하려는 목표를 지정하는 방식을 말하며, 예를 들어 이미지, 텍스트, 좌표 등 다양한 형태가 될 수 있어요.
- "소프트 프롬프트" 매핑은 이러한 다양한 형태의 목표를 ViNT 모델이 이해할 수 있는 형태, 즉 모델의 '목표 토큰'으로 변환하는 과정을 의미
- 이는 transformer 아키텍처의 다중 모달 입력을, 공유된 토큰 공간으로 투영하여 주의를 기울일 수 있는 능력을 기반으로 함
- 새로운 모달리티(예: 2D global postion나 고수준 라우팅 지시 사항[22])에서 sub-goal ( \sigma )가 주어지면,
- 우리는 이 부목표를 공유된 토큰 공간으로 매핑하는 작은 신경망 ( \tilde{\phi} )을 훈련시키고, ( \phi(o_t, o_s) )를 대체
- 우리는 수정된 목표를 사용하여 태스크 데이터 ( D_F )와 함께 ViNT를 미세 조정
4.2.1.구체적인 fine tuning 학습 방법
- 모든 CARLA fine tuning 실험에서, 태스크 데이터는 규칙 기반 오라클 에이전트를 사용하여 수집되었으며, 시작과 종료 위치는 최대 900미터 떨어져 무작위로 샘플링됨.
- 우리는 CARLA의 Town 01 환경에서 대략 4시간 분량의 181개 훈련 궤적을 수집했고, 보류된 Town 02 환경에서 추가로 1시간 분량의 52개 궤적을 수집했습니다.
4.2.2. goal pose oriented navigation:
- 아키텍처:
- GPS 스타일 목표에 적응하기 위해, 우리는 기존 ViNT에서 goal 인코더 블록을 제거
- 그 다음에는 크기가 3000인 고정 텐서를 학습하고, 이것을 로봇 중심 좌표 기준의 GPS 명령 목표와 연결
- 훈련:
- 훈련 중에는 미래 오도메트리 정보에서 목표를 샘플링
- self-supervision을 위한 미래 목표 좌표를 얻은 후, 우리는 이를 로컬 좌표로 변환하고 우리의 아키텍처로 전달하여, ViNT와 동일한 목표로 fine tuning
- 우리는 4 에포크 동안 0.0001까지 학습률 웜업을 사용하는 코사인 스케줄러를 사용합니다.
- 또한, 1.25초에서 1.75초 사이에서 목표 지점을 샘플링
- 이미지: 0.5초에서 2.5초 미래의 목표 이미지 샘플링
4.3. Command-Adaptation:
- 아키텍처:
- 이산 명령어 목표에 대해서, 우리는 GPS 스타일 목표와 비슷한 접근 방식을 사용
- 우리는 각 이산 명령어에 대해, 고정된 텐서를 학습하고,
- 명령어 인덱스를 사용하여 해당하는 잠재 변수를 선택한 다음,
- 최종 토큰을 예측하기 위해 2층 MLP로 전달합니다.
- 이 방식으로, 우리는 각각이 구별되는 명령어에 해당하는 잠재 변수들의 사전을 학습
- 훈련:
- 우리의 실험에서, 우리는 "왼쪽", "오른쪽", 그리고 "직진"을 우리의 이산 명령어로 사용
- 우리는 훈련 데이터가 이산 명령어로 라벨링되지 않았다고 가정하므로,
- 데이터셋 궤적을 (GPS 적응에서와 같이) 미래 위치를 샘플링한 후 그것의 측면 편차를 기반으로 명령어를 선택함으로써 사후적으로 해당하는 명령어로 라벨링
- 우리의 실험에서는 측면 좌표가 0.05보다 큰 샘플을 "왼쪽" 또는 "오른쪽"으로 분류하고, 나머지 샘플들을 "직진"으로 라벨링

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.