LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
foundation model in robotics
목록 보기
4/14
- https://openaccess.thecvf.com/content/ICCV2023/papers/Song_LLM-Planner_Few-Shot_Grounded_Planning_for_Embodied_Agents_with_Large_Language_ICCV_2023_paper.pdf
- https://github.com/OSU-NLP-Group/LLM-Planner/
-
-
-
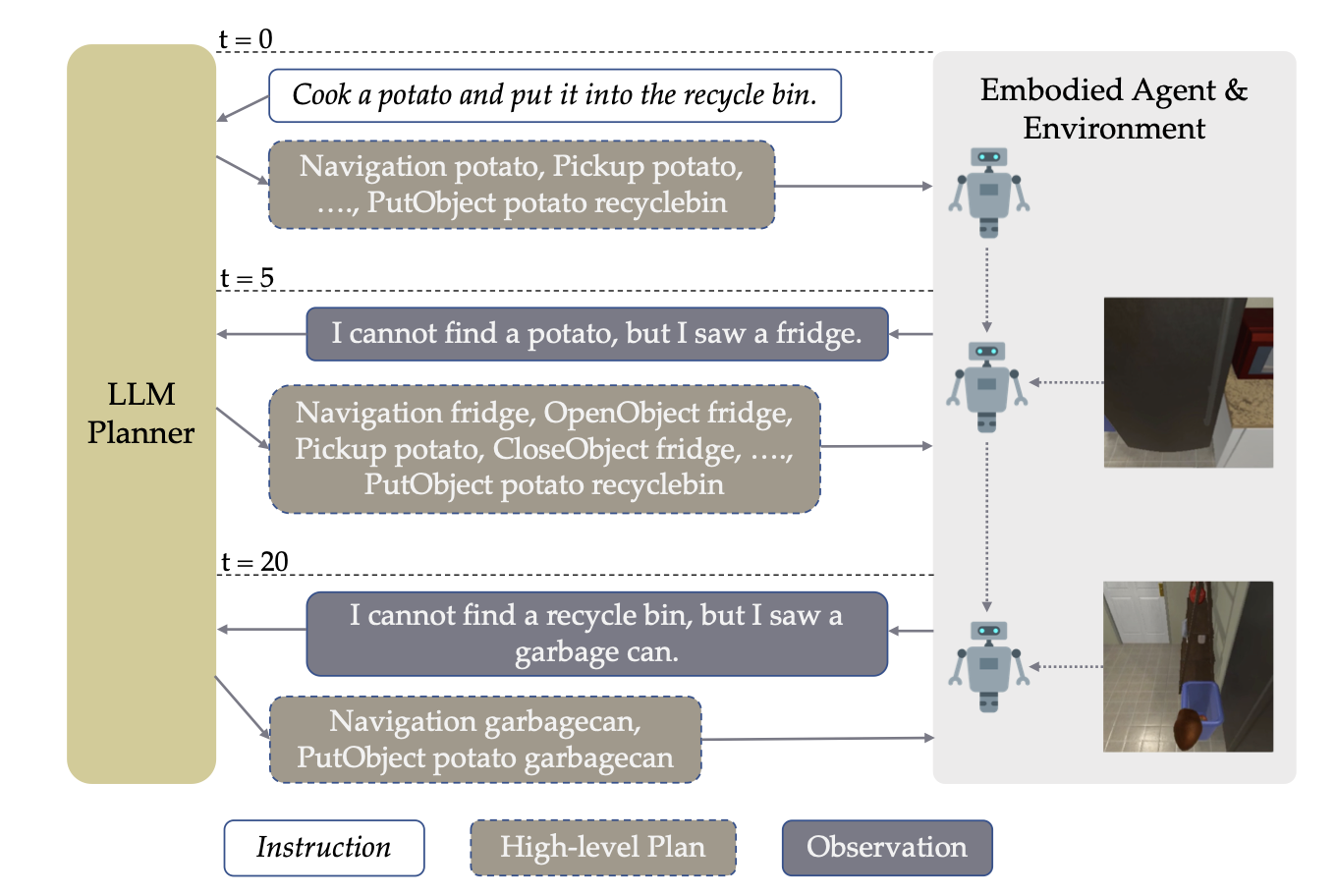
LLM planner가 생성한 HLP(하이레벨 플레닝, 에: sequence of sub-goals ([감자 찾으러 갔다가, 감자 잡고, 전자레인지로 가]) 수행 시간이 너무 오래걸리면,
-
로봇은 LLM에게
지금까지 관찰했던 사진들+HLP 중 지금까지 수행 완료한 것들정보를 추가로 주면서, 다시 HLP 해달라고 요청! -
LLM은 common sense knowledge가 좋기 때문에, 새로운 환경에 대한 적응력이 좋다.!
- 예
- LLM: 감자 찾아와!
- 로봇: 감자를 잘 못찾겠어요 ㅠ 대신 냉장고는 찾았어요!
- LLM: (오호? 냉장고는 음식물을 저장하는 곳이지. 그럼 감자도 냉장고안에 있을 가능성이 높군). 냉장고 열어서 감자 있나 찾아봐!
- 로봇: 오! 감자 있어요! 집을꼐요.
- 예
1. Abstract
- https://arxiv.org/pdf/2212.04088
- 눈이 달린 로봇이,
복잡한 task에 대한 자연어 지시를 받았을 때, 이에 대한 high level planning을 생성하기 위해 LLM을 쓴다. - 우리의 논문의 포인트는
로봇이 처음 가보는 다양한 환경에서도, 금방 적응을 잘 한다는 것이다! (다양한 테스크 수행 능력을 금방 적응하여 키운다!)환경에 대한 사전 정보를 모아야 하는 노력을 최소화 할 수 있다!- LLM 호출을 적게 하면서도, 원하는 목표를 달성할 수 있다!
- 로봇이 환경을 눈으로 보면서 준 피드백을 통해, re-planning을 수행한다!
- ALFRED dataset(다양한 환경, 다양한 task에 대한 Visual-Language Navigaiton dataset) 으로 검증한 결과 혁신 달성!
- 여기서 pair은
자연어 지시 - High Level Planning조합- 자연어 지시: 컵을 들어서, 쓰레기 통에 버려줘
- High Level Planning: 컵을 찾으러 돌아다녀. 컵 근처로 가. 컵을 집어. 쓰레기통을 찾으러 돌아다녀. 쓰레기통으로 가. 컵을 쓰레기통에 버려.
- LLM-planner은,
자연어 지시 - High Level Planning조합 데이터를 매우 쪼금 학습에 이용해도, 새로운 task에 대한 수행 능력이 좋았다.- 심지어 여기서 말하는 학습은 prompt-tuning!
- 여기서 pair은
2. Introduction
- 많은 양의
자연어 지시 - High Level Planning로 각 task 수행을 학습하는 방법은, 학습 비용이 너무 비쌉니다.- 예: 건물 내 쓰레기통을 전부 찾아서 하나씩 비우고 오는 task를 학습할 때, 아래 pair가 Input output이 되도록 학습하는 것. (다른 task를 학습하고 싶으면, 데이터셋을 또 모아서 학습시켜야함..)
자연어 지시:건물 내 쓰레기통을 전부 비워줘!High Level Planning:건물 내 쓰레기통을 발견할 때까지 순찰합니다.+찾았으면 가서 집습니다.->집은 채로 중앙 쓰레기통 장소를 찾습니다.->중앙 쓰레기통 장소에 쓰레기를 비웁니다.->쓰레기통을 원래 자리로 되돌려 놓으러 갑니다.->무한 반복
- 예: 건물 내 쓰레기통을 전부 찾아서 하나씩 비우고 오는 task를 학습할 때, 아래 pair가 Input output이 되도록 학습하는 것. (다른 task를 학습하고 싶으면, 데이터셋을 또 모아서 학습시켜야함..)
- LLM-based planner은 새로운 task에 대해, few-shot으로 적응하는 능력이 좋다.
2.1. 과거 연구 한계점 보자!
- SayCan 연구
- [action, object] pairs를 이미 가지고 있다고 가정
- LLM에게, 어떤 action을 선택하는게 좋을지 ranking을 매겨달라고 함.
- 예:
- 지시어:
캔을 쓰레기통에 버려! - 사전 정보
- 캔: 액체를 비우다. 집다. 찌그러뜨리다. 던지다.
- LLM planner:
- 캔 액체를 비운 후, 찌그러뜨린 후, 집어!
- 지시어:
- 한계점
- action, object pair를 가지고 있지 않은 새로운 물체를 보았을 떄, 대응 불가. (다른 환경에 갔을 때!)
- 복잡한 환경에서, 많은 물체가 있는 환경에서, LLM call통해 모든 물체마다 admissible skill중 뭐가 최선일지 평가해야 하기 떄문에, 비용이 많이 듭니다.!
- 다른 연구들은, 환경에 대한 feedback없이,
지시어 -> LLM -> high level planning을 거친다는 것이 문제였음. - HLP에 대해, 환경 관찰 기반 feedback을 진행한 연구들도 있는데, LLM이 출력한 HLP를 현재 환경에서 실현 가능한 actions로 전환(내가 preset 중에)시키는 별도 network를 학습시켰음.
- 이는 LLM 출력 HLP가, 실현가능한 preset actions와 매칭이 된다는 가정을 전제
- 하지만, LLM 출력 HLP가 실현가능한 preset actions와 매칭 안되는 경우도 있음(다양하고 복잡한 환경에서)
- 우리 연구에서 low-level planner의 역할
LLM-planner가 HLPs를 주면 ->이 각 HLP subgoal을 sequence of 사전정의된 actions로 변환- 예
- HLP: 감자 찾으러 가
- sequence of 사전정의된 action:
- 공간 탐색 알고리즘 실시
- 감자 detection 알고리즘 실시
- 감자 detection이 되면, goal을 감자가 있는 곳으로 변경
- 이 과정은 시뮬레이터 안에서, 합성된 데이터 셋들을 통해 학습됩니다. 궁금하면 [28, 3] 논문을 보세요
- In-context 학습 페러다임 사용
- pre-trained large network 에, 새로운 도메인의 예제를 통한 학습 (적은 데이터)
- 예: GPT3에,
자연어 지시-HLPpair 몇개를 통해 적응시킴.- (GPT3 parameter update가 필요 없음)
- prompt engineering을 한다는 뜻
- HLP 생성 성능을 높이기 위해 아래와 같은 세부 기술들 사용
in-context example retrieval- 특정 지시어를 받았을 때, 바로 HLP을 하는게 아니라,
- 이전에 비슷한 지시어로 성공적인 HLP를 제공했던 예제들을 DB에서 "검색"하여, LLM의 추가 입력으로 사용!
- 구체적으로, 각 instruction을 bert-based ebemdding vector로 치환한 후, 코사인-유사도가 높은 지시어들을 예제로 정해서 LLM prompt에 같이 넣어줌! (중요)
logit biases- 로봇이 관찰한 물체의 logit을 인위적으로 증가시키는 방법
- 그래서, 특정 물체가 들어간 HLP (subgoal) 선택 확률을 인위적으로 높인다.
2. Related Work
2.1. Vision-and-Language Navigation
- R2R dataset
navigation-only VLN datasets- VLN 세팅에서, 주행만을 위해 action sequence를 출력하는 Transformer model은 성능이 이미 좋습니다.
- 최근에는 BERT의 variants를 이용해서 더 나은 language 이해 성능을 확보 [18, 24, 26, 11]
- 언어와 시각적 표현을 결합시켜 학습
- ALFRED dataset
그러나 더 복잡한 VLN 문제 상황도 있습니다.(혹은 embodied instruction following in datasets)- 이런 복잡한 VLN 문제에서는 계층적 planning model(high-level planning과 low-level planning을 분리) 이 더 효과적임이 증명되었습니다.(특히, 데이터가 부족한 상황에서 계층적 계획 모델이 유리)
- 이러한 models는 pretrained language models(e.g. BERT)를 사용해서 high-level planning을 수행합니다.
- 그리고, 이 high-level plan에서 구체화된 target objects를 찾아서 로봇에게 guide를 주기 위해, semantic map을 만듭니다.
- 최근연구는, ALFRED 데이터셋의 10%만 이용해서 학습 (
natural language subtasks를 생성하는 법)했습니다. - 그리고
생성된 각 subtask를 primitive actions와 매칭시킵니다. - 우리는 이러한 modular approach를 한걸음 더 나아가서, few-shot setting에서 LLM을 사용하는 것을 제안합니다.
2.2. Prompting for VLN
- LLM을 의사 결정에 쓰는 2가지 토픽
- 보조 도우미로써 쓰기
- planner로써 쓰기
2.2.1. LLM as an Auxiliary Helper
- main model을 돕기 위해, 상대적인 정보들을 생성하는데에 LLM을 쓴다.
- 예: LLM이, goal object에 가장 근접한 위치를 생성한다.
- LM-Nav
- 대규모 언어 모델(LLMs)에
원시 내비게이션 지시사항("왼쪽으로 돌아 깡통이 있는 쪽으로 가세요.") +3개의 맥락 예제(context examples)를 제공->주요 지형지물(landmarks) 목록을 생성하도록 함 - 이 landmark 목록은 비전-언어 모델이 이미지와 지형지물 사이의 관계를 파악하고, 이 두 요소 사이의 결합 확률 분포를 추론하는 데 사용
- 맥락 예제(In-context Examples):
- 이는 주어진 문제에 대한 이전 사례나 예제를 제공하는 것을 의미
- 맥락 예제는 모델이 현재 상황을 더 잘 이해하고 적절한 반응을 생성할 수 있게 도움
- LM-Nav에서는 세 가지 예제가 제공되어, 모델이 어떻게 지시사항을 해석하고 실행해야 하는지에 대한 이해를 돕습니다.
- 대규모 언어 모델(LLMs)에
2.2.2. LLM as a Planner
- LLM이 환경에서 (directly or in-directly하게 low-level planner로) 실행가능한 plan을 생성
- 과거 대부분의 연구는
환경에서 수행가능한 actions를 미리 알 수 있다는 가정하에, 문제를 풂.
- 과거 대부분의 연구는
- 어떤 연구에서는
AI 모델이 환경 내에서 수행할 수 있는 행동의 목록을 예측하도록 훈련시키려고 시도- 이는 로봇이나 AI 시스템이 주어진 상황에서 취할 수 있는 적절한 행동을 판단하도록 돕는 방식
- 기존 연구의 문제점
- 행동 목록의 접근성:
- 실제 환경, 특히 관찰이 제한된 환경에서는 AI가 모든 가능한 행동을 예측하거나 이해하는 것이 어려울 수 있습니다.
- 예를 들어,
모든 객체나 장애물을 정확히 인식하지 못할 수 있습니다.
- 행동 목록의 접근성:
- 목록의 길이 문제:
- 환경의 복잡성이 증가함에 따라,
즉 객체의 수가 많아짐에 따라 AI가 고려해야 할 행동의 수도 기하급수적으로 증가합니다. 이는 처리해야 할 데이터의 양이 많아져 시스템에 부담을 줄 수 있습니다.
- 환경의 복잡성이 증가함에 따라,
2.3. 본 논문의 제안
- LLM-Planner의 접근 방식:
- LLM-Planner는 생성 모델을 사용
- 이는 고정된 행동 목록을 사전에 정의하는 대신, 현재 환경에 대한 구체적인 지식 없이도 높은 수준의 계획을 생성할 수 있다는 의미
- 계획은 새로운 관찰이 이루어질 때마다 동적으로 수정 및 세분화
- 이는 AI가 환경의 변화에 유연하게 반응할 수 있게 만들어 주며, 더 효과적으로 작업을 수행할 수 있도록 합니다.
- 현재 환경에 대한 기초 지식 확보:
- LLM-Planner는
사전 훈련된 비전 detection 모델을 사용하여, 대규모 언어 모델(LLM)을 현재 환경에 "그라운딩(grounding)" (시각 정보를 통해 re-planing 성능을 높인다.) - 여기서 '그라운딩'이란, 모델이 현재의 시각적 환경 정보를 이해하고 그 정보를 기반으로 작업을 수행할 수 있도록 준비하는 과정을 의미
- LLM-Planner는
- 적은 양의 레이블 데이터 사용:
- 이 모든 과정은 많은 양의 레이블이 붙은 데이터 없이도 수행될 수 있습니다.
- 이는 LLM-Planner가 기존 데이터에 과도하게 의존하지 않고도 효과적으로 학습하고 적용할 수 있음을 의미
3. Preliminaries
3.1. Vision-and-Language Navigation
Embodied instruction following은vision and language navigation(VLN)과 유사- task 정의
Language Instruction I가 주어졌을 때, agent는 환경 E에서 task를 완수하기 위해,sequence of primitive actions를 수행
- task 정의
Embodied instruction following- 좀 더 interaction actions가 추가되었고, time horizion이 더 깁니다.
- ALFRED dataset (AI2-Thor simulator 기반)
- 지시 I는 아래와 같이 구성되어 있음
- high-level goal I_H
- list of step-by-step instructions I_L
- 지시 I는 아래와 같이 구성되어 있음
- VLN task: (I, E, G) -> G: goal test
vision and language navigation(VLN)- Room2Room dataset 과 같은 task
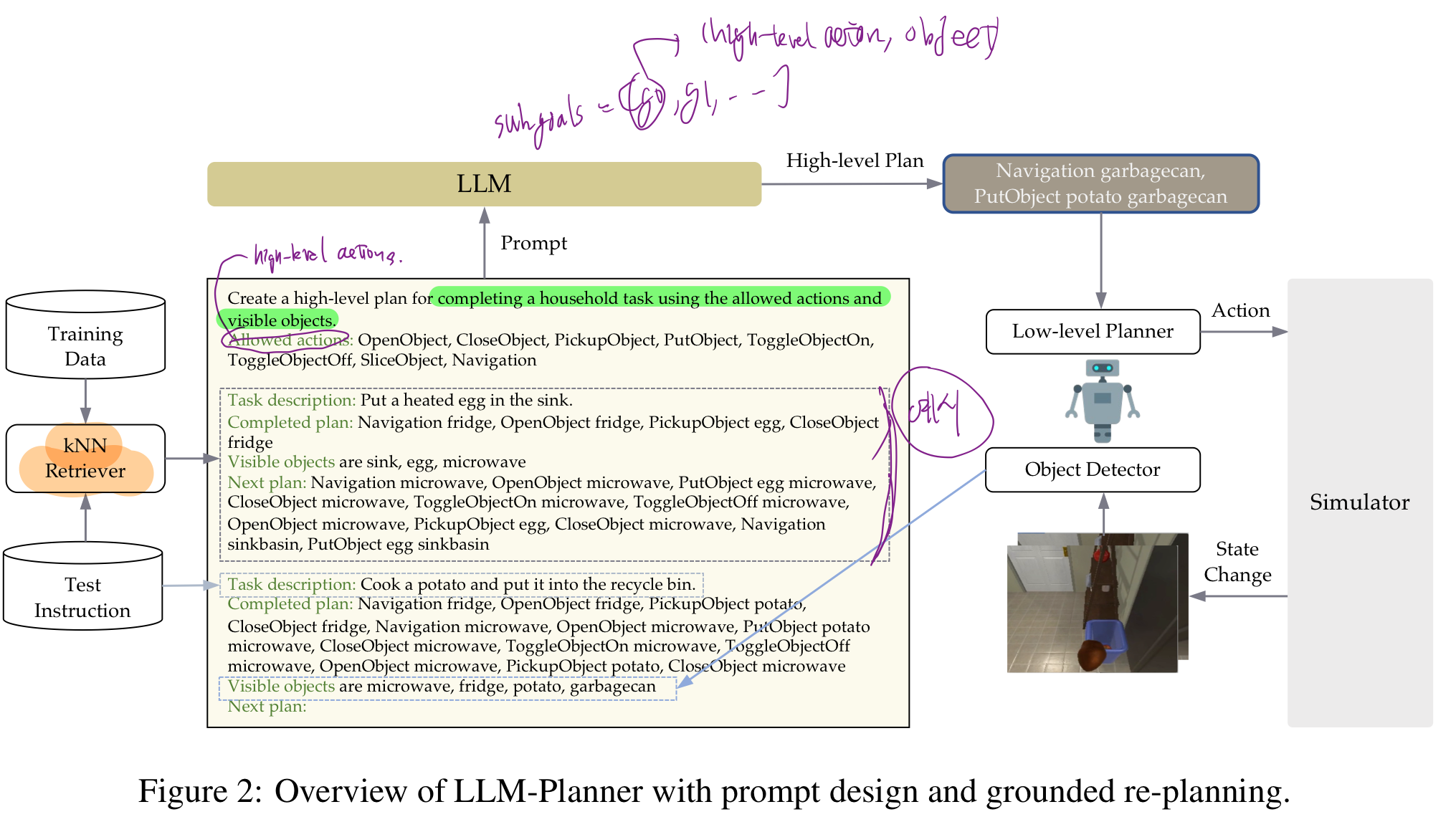
- high-level planner
- 목적:
instruction I->high level plan L_h = [g_0, g_1, ..., g_T]- 여기서 subgoal
g_i=(high-level action, object)high-level action- primitive actions의 집합 (ALFRED dataset에서 single goal-condition을 수행할 수 있도록 하는)
- ALFRED의 interaction actions에
Navigationaction을 추가하였다.- Navigation, PickupObject, PutObject, OpenObject, CloseObject, ToggleOnObject, ToggleOffObject, SliceObject
- 여기서 subgoal
- 예:
Putting a sliced tomato on the black table->L_h = [ (Navigation, fridge), (Open, fridge), (Pickup, tomato), ...]
- 목적:
- low level planner
- 목적: subgoal
g_i=(high-level action, object)-> Primitive actionsL_l = [a_0, a_1, ..., a_Ti] - 모든 primitive actions는 deterministic 하거나, 시뮬레이터의 synthetic data로부터 학습되었다.
- 예
- (Navigation, fridge) -> semantic 지도에서, 냉장고를 찾아서, path planning해서, 로봇이 따라가게 함.
- (Open, fridge) -> 로봇 팔을 이용해서, 냉장고 문을 여는 전략 학습
- 목적: subgoal
3.2. In-Context Learning/Prompting
- 프롬프트: 대규모 언어 모델(Large Language Models, LLMs)에게 특정 작업을 수행하도록 요청하거나 유도하는 데 사용되는 입력 문구
- 따라서 프롬프트 디자인은 모델의 응답을 최적화하고, 특정 작업에 맞게 조정하는 데 중요한 역할
- 인컨텍스트 학습(프롬프팅)은
특정 프롬프트(질문 혹은 요청)를 디자인하여, 아래의 방법으로, 대규모 언어 모델을 다양한 하위 작업에 적응시킬 수 있는 방법예시 몇 개를 보여주는 것특정 작업에 맞는 질문이나 명령을 구성하여 모델의 출력을 조정하는 것
- 이 과정에서
모델의 파라미터는 전혀 업데이트되지 않습니다.
3.3. True Few-shot Setting
- Few-shot learning이란, 매우 적은 수의 훈련 데이터를 사용하여 모델을 훈련시키는 방법
- 그러나 많은 연구에서는
비록 훈련 데이터는 적게 사용하지만, 프롬프트 디자인과 모델 선택을 위해 큰 validation 데이터 세트를 사용 최근 연구들은 이러한 큰 검증 세트가 언어 모델의 효능을 과대평가하는 주요 원인이라는 것을 보여주었습니다.- 우리 설정에서는 별도의 검증 세트를 사용하는 대신, 매우 제한된 훈련 세트에 대해
교차 검증을 실시하여 프롬프트 디자인과 모델 선택을 수행합니다. - 이러한 접근 방식은 검증 데이터 세트에 의존하지 않고, 훈련 데이터만을 사용하여
모델의 일반화 능력을 더 정확하게 평가할 수 있게 해 줍니다. - 결과적으로, 진정한 소수샷 설정은 언어 모델의 실제 성능을 보다 현실적으로 측정하고, 과대평가 없이 모델을 선택할 수 있는 방법을 제공
4. LLM-Planner
4.2. Prompt Design
- 고수준 계획(High Level Planning, HLP)의 최종 품질은, 프롬프트에서의 작은 디자인 선택에 민감하게 영향을 받을 수 있음
- 이는 HLP가 어떻게 제시되는지(예를 들어, 텍스트 형태나 구성), 때로는 구두점의 선택 등과 같은 세밀한 부분까지 포함됩니다.
- 연구자들은 프롬프트의 핵심 구성 요소를 식별하고, 다양한 디자인 선택을 체계적으로 비교할 필요가 있습니다.
- 이를 위해, True Few-Shot Setting 아래에서
leave-one-out cross-validation (LOOCV)방법을 사용합니다.
- LOOCV는 교차 검증의 한 형태로, 데이터 세트에서 단 하나의 데이터 포인트를 제외한 나머지를 사용하여 모델을 훈련시키고, 제외된 단일 데이터 포인트를 사용하여 모델을 검증하는 방식
- 이 방식은 제한된 데이터로부터 모델의 일반화 능력을 평가하는 데 특히 유용하며, 디자인 선택이 최종 HLP 품질에 미치는 영향을 정밀하게 분석할 수 있도록 도와줍니다.
- 이를 통해, 가장 효과적인 프롬프트 디자인을 결정할 수 있습니다.
- When we provide only the high-level goal instruction to GPT-3, we use the format “Task description: [high-level goal instruction].”
- When we include the step-by-step instructions, we include another line “Step-by- step instructions: [step-by-step instructions]” following the goal instruction.
4.3. In-context Example Retrieval
- 우리가 수행하는 task가 "cook a potato"라면,
- "cooking an egg"를 위한 HLP를 보여주는 in-context example이 더 도움이 된다.
- "clean a plate" 보단,
- 우리는 frozen BERT-base model[7]을 이용해서
- 각 training example과 current test example("cook a potato")간 유사도를 평가합니다.
- 구체적으로는, 지시어에 대한 BERT embedding 간 euclidean-distance를 계산합니다.
- K개의 가상 유사한 examples를 찾는데, K는 hyperparameter로써 true few-shot setting에서 튜닝할 것입니다.
4.4. Grounded Re-planning
- Re-planning을 하지 않으면, 아래와 같은 위험성이 생김
- action 수행에 실패(예: 벽에 부딪힌다거나, object와의 상호작용에서 실패)
- 현재 subgoal을 수행하는데에 너무 오랜 시간이 걸림
- 로봇이 관찰한 물체들에 대해 logit biases를 추가함으로써, LLM-Planner이 관찰 물체에 더 우선순위를 둬서 HLP를 생성하도록 합니다.
- re-planning이 일어나는 조건 2가지
agent가 action을 실시하는데 실패기준 시간 이상 흘렀을 때

4.5. Integration with Existing VLN models
- 아래 2가지가 있으면 됨.
- 물체를 관찰할 수 있는 카메라가 달린 로봇
- predicted HLP를 low-level actions로 변환할 수 있는 low-level planner
5. Experiments
5.1. Dataset
- ALFRED dataset 썼음
- 7개의 task type -> 4703 tasks
- 예: 단일 물체를, 새 장소에 옮기기
- 용기에 가열된 물체 조각을 넣기
- 207개의 환경
- 115개 물체
- 7개의 task type -> 4703 tasks
5.2. Metrics
5.3. Implementation Details
- 21023 training examples 중, 100개만 사용 (7개 task type에서 골고루 가져옴)
- kNN retriever로 아래 것 사용
pretrained BERT-base-uncased model (Huggingface Transformers Library[40])- 100개 예시 중, 9개의 in-context examples를 선택함.
- LLM으로 아래 것 사용
public GPT-3 API text-davinci-003 [4]
- temperature: 0, logit bias: 0.1 to all allowable output tokens.
- object detector은 아래의 것을 씀
- HLSM의 perception model
- 신뢰도 80% 이상인 것만 활용함
- baseline model
HLSM[3]/ FILM[28]- hierarchical planning model이고, ALFRED leaderboard에서 높은 성능
5.6. Fine-grained Analyses
- 그림 3에서 보듯이,
트레이닝 예시가 많아질수록 HLP 정확도는 일반적으로 향상되지만, 250개의 트레이닝 예시를 넘어서면 수익이 감소하기 시작합니다.메인 실험에서 트레이닝 예시를 더 많이 사용하면 (예: 250개) 상당한 향상을 기대할 수 있습니다.
- 또한,
인컨텍스트 예시로 9개가 일반적으로 좋은 수라는 것을 발견했습니다.- 인컨텍스트 예시를 더 추가하는 것이 성능을 약간 향상시킬 수는 있지만, 추가 비용을 정당화하기에는 충분히 의미 있는 수준은 아닐 수 있습니다.
- 예상할 수 있듯이,
트레이닝 예시가 적을 때는 인컨텍스트 예시가 더 유용합니다. 왜냐하면 검색할 유용한 예시가 적기 때문이죠.
6. Conclusion
- 우리의 연구는 지시 따르기 작업을 위한 인간 주석의 필요성을 대폭 줄일 수 있습니다.
- 앞으로의 유망한 방향으로는 Codex[5]와 같은 다른 LLM을 탐구하고, 더 나은 프롬프트 디자인, 그리고 더 발전된 기반 및 동적 재계획 방법을 개발하는 것이 포함됩니다.
0. 개인 의문점 정리
- 위 논문 내용을 사용할 수 있으려면, 아래 전제가 필요
- 특정 물체의 위치를 저장된 semantic map을 통해 알고 있어야 함.
- 아니면, 특정 물체를 찾기 위한 순찰 알고리즘을 가지고 있어야 함.
- 허용 가능한 actions(HLP를 위한)을 사전에 잘 정의해야 함
- 예: 물체를 찾아. 물체를 향해 주행해. 사진을 찍어. 적재함을 열어.
- 궁금점
- kNN retriever은 지시어 간 유사도로 고르는 것은 알겠는데, 고른 후 Completed plan과 Visible Objects, Next Plan은 어떤 기준으로 선택하지?

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.