1. R2R dataset
- https://bringmeaspoon.org
지시어 + 로봇 deseried 궤적(x,y pose + vision data 등) 조합의 데이터셋- 동기: 로봇과의 자연어 상호작용
- 5살짜리 아이에게 숟가락을 가져오라고 부탁하면, 숟가락이 나타날 가능성이 높습니다.
- 우리는 로봇도 같은 일을 할 수 있기를 원합니다.
- 우리의 시각-언어 내비게이션(VLN) 테스트 서버와 리더보드가 EvalAI에 올라왔습니다.
1.1. 방에서 방으로(R2R) 내비게이션

- R2R은 실제 건물에서 시각적으로 기반한 자연어 내비게이션을 위한 첫 번째 벤치마크 데이터셋
- 이 데이터셋은 자율 에이전트가 이전에 본 적 없는 건물에서 사람이 생성한 내비게이션 지시를 따르도록 요구
- 훈련을 위해,
각 지시는Matterport3D 시뮬레이터의 궤적과 연관- 22,000개의 지시가 있으며, 평균 길이는 29단어입니다.
1.2. Matterport3D 시뮬레이터
- https://niessner.github.io/Matterport/
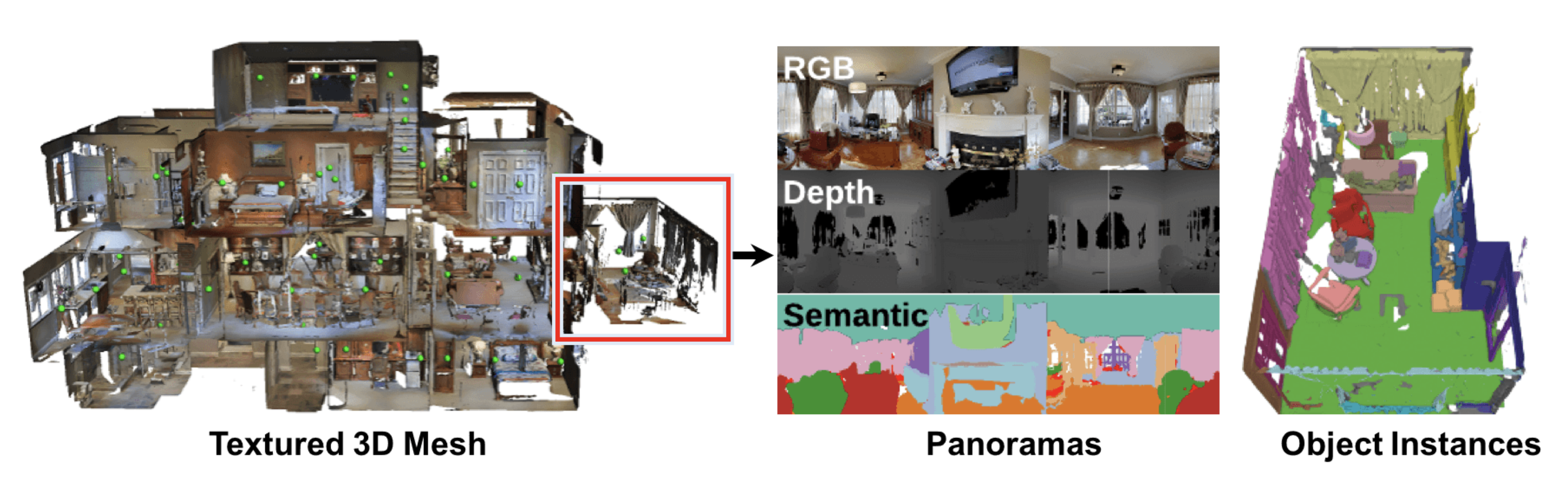
- Matterport3D 시뮬레이터: 실제 3D 환경과 상호작용하는 AI 에이전트의 개발을 가능하게 함
- 이는 주로 컴퓨터 비전, 자연어 처리 및 로보틱스의 교차점에서 심층 강화 학습 연구를 위해 의도
시뮬레이터의 시각적 이미지는 Matterport3D 데이터셋에서 나오며, 이는 90개의 대규모 건물에서 얻은 종합적인 파노라마 이미지 및 기타 데이터를 포함하고 있습니다.- Matterport3D 시뮬레이터는 GitHub에서 이용 가능합니다.
- 요약
- RGB-D 장면 이해 알고리즘을 훈련시키기 위해서는 크고 다양한 RGB-D 데이터셋에 대한 접근이 매우 중요
- 그러나 기존의 데이터셋은 여전히 제한된 수의 뷰나 제한된 공간 규모만을 커버하고 있음
- 본 논문에서는 90개의 건물 규모 장면에서, 194,400개의 RGB-D 이미지로부터 10,800개의 파노라마 뷰를 포함하는 대규모 RGB-D 데이터셋인 Matterport3D를 소개
- 이 데이터셋에는
surface reconstructions,camera poses, and2D and 3D semantic segmentations에 대한 annotaiton이 제공 - 정밀한 글로벌 정렬과 건물 전체에 걸친 포괄적이고 다양한 파노라마 뷰 세트는
keypoint matching, view overlap prediction, normal prediction from color, semantic segmentation, and scene classification을 포함한 다양한 지도 학습 및 자기 지도 학습 컴퓨터 비전 작업을 가능하게 합니다.
2. ALFRED dataset
- https://askforalfred.com
지시어-step-by-step 지시어조합

- ALFRED(Action Learning From Realistic Environments and Directives)는
가사 작업을 위한 일련의 행동들을,자연어 지시문과 자아중심 시각으로부터 매핑하는 학습을 위한 새로운 벤치마크 - 연구 벤치마크와 실제 응용 사이의 격차를 줄이기 위해 우리는 되돌릴 수 없는 상태 변화와 함께 긴 구성 롤아웃을 포함시키는 현상을 포함시켰습니다.
2.1. AI2Thor Simulator
- ALFRED dataset은 AI2Thor Simulator을 기반으로 합니다.
- https://ai2thor.allenai.org

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.