
0. Examples
# move the robot in a 2m by 1m rectangle around the office chair.
traj = parse_position('a 2m by 1m rectangle around the office chair with 4 points')
say('ok - moving in a 2m by 1m rectangle around the office chair')
for pos in traj:
goto_pos(pos, speed=0.5)
# a 2m by 1m rectangle around the office chair with 4 points.
office_chair_name = parse_loc_name('the office chair', f'objects = {get_loc_names()}')
office_chair_pos = get_loc_pos(office_chair_name)
shape_2d = make_rectangle(width=2, height=1, center=office_chair_pos)
points_2d = get_points_from_polygon(shape_2d)
points_3d = np.c_[points_2d, np.zeros(len(points_2d))]
ret_val = points_3d1. abstract
- 우리는 코드 작성 LLM이 ->
자연어 명령을 주어 -> 로봇 정책 코드를 작성하는 데 쓰일 수 있음을 발견 - 구체적으로, 정책 코드는 아래 기능을 수행하는 함수나 피드백 루프를 표현할 수 있다.
perception 출력(예: object detector 로부터)을 처리제어 프리미티브 API를 매개변수화
- 여러
예제 언어 명령(주석으로 포맷된)과해당 정책 코드(몇 가지 샷 프롬프트를 통해)를 입력으로 제공하면,- LLM은
새로운 명령을 받아 API 호출을 재구성하여새로운 정책 코드를 자율적으로 생성가능
- LLM은
- NumPy, Shapely와 같은 서드 파티 라이브러리를 참조함으로써, 이러한 방식으로 사용되는 LLM은 아래 특징을 가진 로봇 정책 코드를 작성할 수 있다.
- (i) 공간-기하학적 추론을 수행하고,
- (ii) 새로운 지침에 일반화하며,
- (iii) 맥락에 따라 모호한 설명(“더 빠르게”)에 대해 정확한 값(예: 속도)을 처방
- 이 논문은 코드 as 정책을 제시하며, 아래의 기능을 표현할 수 있는 언어 모델 생성 프로그램(LMP)의 로봇 중심 형식
- 반응형 정책(예: 임피던스 제어기)
- 웨이포인트 기반 정책(비전 기반 피킹 및 배치, 경로 기반 제어)
- 우리의 접근 방식의 핵심은 계층적 코드 생성 프롬프트(정의되지 않은 함수를 재귀적으로 정의)로, 더 복잡한 코드를 작성할 수 있으며
- HumanEval [1] 벤치마크에서 39.8%의 문제를 해결
- 코드와 비디오는 https://code-as-policies.github.io
2. Introduction
- policy code는 아래의 것들을 표현 가능 (그림 1 참조)
- perception output(예: open vocabulary object detectors[2], [3])을 처리
- 제어 기본 API를 매개 변수화하는 함수
- 피드백 루프
- 몇 가지 예시 언어 명령어와 해당 정책 코드(회색으로 표시된 소수 샷 프롬프트를 통해)가 제공되면,
- LLM은 새로운 명령어(녹색으로 표시)를 입력하고
- API 호출을 자동으로 재조합하여 새로운 정책 코드를 생성할 수 있습니다. (highlighted)

- 코드 작성 모델은 다양한 산술 연산뿐만 아니라
언어에 기반한 피드백 루프도 표현할 수 있습니다. - 이 모델은 새로운 지시문에 일반화 될 뿐만 아니라
- 수십억 줄의 코드와 주석에 대해 훈련 받았으므로
- 문맥에 따라 모호한 설명("더 빠르게" 및 "왼쪽으로")에 대해 정확한 값(예: 속도)을 처방 할 수도 있습니다.

- 코드를 정책으로 표현하면 LLM의 여러 가지 이점을 물려받을 수 있습니다:
- 자연어를 해석할 수 있는 능력뿐만 아니라, "say(text)"를 사용 가능한 액션 기본 API로 사용하여
인간-로봇 대화 및 Q&A에 참여할 수 있는 능력:
- 자연어를 해석할 수 있는 능력뿐만 아니라, "say(text)"를 사용 가능한 액션 기본 API로 사용하여
- 우리는 코드를 정책으로 표현하는 방법인 Code as Policies(CaP)를 제시
- 실제 시스템에서 실행되는 언어 모델 생성 프로그램(LMP)의 로봇 중심 표현 방식
- 파이썬 기반의 LMP는 다음을 사용하여 복잡한 정책을 표현할 수 있습니다:
- 런타임에 새로운 행동을 구성하기 위한 고전적인 논리 구조(예: 시퀀스, 선택(if/else), 루프(for/while))
- 공간 기하학적 추론을 위한 포인트 보간(NumPy), 모양 분석 및 생성(Shapely) 등의 써드파티 라이브러리
- LMP는 계층적일 수 있습니다:
- 새로운 함수를 재귀적으로 정의하도록 프롬프트되고
- 시간이 지남에 따라 자체 라이브러리를 축적
- 동적 코드베이스를 자체적으로 설계할 수 있음
- 우리는 LLM이 자연어 명령어를 자율적으로 해석하여 아래의 것들을 나타내는 LMP를 생성할 수 있음을 여러 로봇 시스템에서 입증
- reactive low-level policies(예: PD 또는 임피던스 컨트롤러)
- 웨이포인트 기반 정책(에: Vsion-based pic and place, trajectory based controller)
- 우리의 주요 기여는 다음과 같습니다:
- (i) 코드를 정책으로 표현: LLM을 사용하여 로봇 코드를 작성하는 방법,
- (ii) 계층적 코드 생성 방법으로, 로봇공학과 표준 코드 생성 문제 모두에서 39.8%의 P@1로 인간 평가에서 최첨단을 이룸(HumanEval에서)[1],
- (iii) 로봇공학 코드 생성 문제에 대한, 향후 언어 모델을 평가하기 위한 새로운 벤치마크,
- (iv) generalization 메트릭을 향상시키는 방법과 스케일링 법칙(더 큰 모델이 더 나은 성능을 발휘)을 준수하는 방법을 분석하는 ablation
- 한계점은 5장에서 논의합니다.
3. Related work
- 언어는 비전문가가 로봇과 상호작용할 수 있는 인터페이스 역할을 할 뿐만 아니라 새로운 작업에 대한 일반화를 구성적으로 확장하는 수단으로도 사용됩니다[9], [17].
- 이전 연구에서 생성된 계획은 로봇이 물체를 약간 오른쪽으로 움직일 수 있는 기술이 존재한다고 가정
- 우리의 접근 방식은 아래의 점에서 다릅니다:
- LLM을 사용하여 로봇에서 실행할 정책 코드(계획 내에 중첩된)를 바로 생성
계획의 모든 step를 매핑하는 미리 정의된 polices이 필요 없다는 점
- CaP는 데이터를 수집하고 미리 정의된 고정된 수의 사전 정의된 기술 또는 언어 조건부 정책을 학습할 필요를 덜어줌
코드 생성
- 우리는 이러한 연구를 확장하여
- (i) 코드 작성 LLMs가 추가 훈련 없이 공간적 관계를 인코딩하는 등의 새로운 추론 기능을 가능하게 하고,
- (ii) (재귀적 요약[57]에서 영감을 받은) 계층적 코드 작성이 최첨단 코드 생성을 향상시킨다는 것
- 또한 로봇공학 도메인에서 향후 언어 모델을 평가하기 위한, 코드-젠 벤치마크도 제시
4. Method
- 여기서는
LLM이 생성하는 프로그램을 언어 모델 프로그램(LMP)이라고 부릅니다. - 이러한 LMP를 사용하여 언어로 된 지시문을 실제 로봇을 제어하는 코드로 변환할 수 있습니다.

입력 지시문은 사람이 제공하거나 다른 LMP가 작성할 수 있는 주석(녹색) 형식으로 제공- LLM(highligted)의 예측 출력은 자동 회귀적으로 생성된 유효한 파이썬 코드([11], [12])
- LMP는 아래의 목적을 위해 몇 가지 예시로 프롬프트됩니다.
- 객체 탐지 결과를 처리하거나, trajectory를 구축하거나, 제어 기본 요소를 시퀀싱하는 데 사용할 수 있는 다양한 서브프로그램을 생성하기 위해
- LMP는 아래의 방식으로 계층적으로 생성될 수 있습니다.
- 알려진 함수(예: perception 모듈을 사용한
get_obj_names())를 구성하거나 - 정의되지 않은 함수를 정의하기 위해 다른 LMP를 호출
- 알려진 함수(예: perception 모듈을 사용한

- 여기서 put_first_on_second는 기존의 오픈 어휘 픽 앤 플레이스 기본 요소(예: CLIPort[36])입니다.
- 새로운 구현체의 경우, 이러한 활성 함수 호출은
- 에이전트의 액션 공간(예: set_velocity)을 나타내는 사용 가능한 제어 API로 대체할 수 있음
- LMP에 의해 정의된 함수는 시간이 지남에 따라 점진적으로 누적될 수 있으며, 새로운 LMP는 이전에 구축된 함수를 참조하여 정책 로직을 확장할 수 있습니다.
- LMP를 실행하려면 먼저 import 문, __로 시작하는 특수 변수 또는 exec 및 eval에 대한 호출이 없는지 확인하여 실행해도 안전한지 확인합니다.
- 그런 다음, 아래의 것들로 파이썬의 exec 함수를 호출합니다.
- input string로써의 code와,
- code 실행의 범위를 형성하는 두 개의 dictionary
- (i) globals, 생성된 코드가 호출할 수 있는 모든 API 포함, (예: 로봇 제어 API)
- (ii) locals, exec 중에 정의된 변수와 새 함수로 채워질 빈 사전을 사용하여
- LMP가 값을 반환할 것으로 예상되는 경우, exec가 완료된 후 해당 값을 locals 사전에서 얻습니다.
- exec 함수는 직접 값을 반환하지 않지만, 실행 중에 생성된 변수나 함수는 locals 사전에 저장됩니다. 이 사전에서 필요한 값을 추출합니다.
A. Prompting Language Model Programs
- LMP를 생성하기 위한 prompt는 2가지 요소가 필요
Hints
- import statements (LLM에게 어떤 API를 쓸 수 있는지 알려줌)
- type hints: 그 API들을 어떻게 쓸 수 있는지

Examples
- 예시는 자연어 지시문이 코드로 변환되어야 하는 방법에 대한 몇 가지 샷 "데모"를 나타내는 지시문-코드 쌍
- 여기에는 산술 연산 수행, 다른 API 호출 및 프로그래밍 언어의 기타 기능이 포함
- 지시문은 해당 솔루션 코드 블록 바로 앞에 주석으로 작성
- 프롬프트에 새 지시문과 응답을 점진적으로 추가하여 LMP "세션"을 유지할 수 있으며, 이를 통해 나중에 "마지막 작업 취소"와 같이 이전 지시문을 참조할 수 있음
B. Example Language Model Programs(low-level)
- LMP는 아마도
다음 섹션에서 간단한 순수 파이썬 지시문에서 로봇 작업을 완료할 수 있는 더 복잡한 지시문까지의 예를 통해 가장 잘 이해할 수 있을 것입니다. - 별도의 언급이 없는 한 이 논문에 있는 모든 예제와 실험은 temparture 0(즉, deterministic greedy token decoding)의 OpenAI Codex 코드-다빈치-002를 사용
- 이 논문에 사용된 모든 예제와 실험은 OpenAI의 Codex 모델 중 code-davinci-002 버전을 사용했습니다.
- 코드를 생성할 때 모델의 temperature 매개변수를 0으로 설정하여, 모델이 항상 같은 입력에 대해 동일한 출력을 생성하도록 하였습니다.
- 이는 모델이 매 단계에서 가장 가능성이 높은 다음 토큰을 선택하는 결정론적 방식으로 코드를 생성함을 의미합니다.
- OpenAI Codex:
- OpenAI가 개발한 코드 생성 모델
- 자연어를 입력으로 받아 프로그래밍 코드를 출력하는 데 특화
- code-davinci-002:
- Codex는 여러 버전이 있으며, code-davinci-002는 그 중 하나
- "davinci"는 OpenAI의 가장 강력한 모델 계열 중 하나
- "002"는 해당 모델의 특정 버전을 나타냅니다.
- Deterministic greedy token decoding:
- "Greedy token decoding"은 모델이 매 단계에서 가장 가능성이 높은 다음 토큰을 선택하는 방식을 가리킵니다.
- 예를 들어, 텍스트를 생성할 때 가능한 모든 다음 단어들 중에서 확률이 가장 높은 단어를 선택하여 텍스트를 이어나갑니다.
- 여기서 프롬프트(회색)는 파이썬을 작성하고 있음을 나타내는 힌트와 함께 시작됩니다.
- 그런 다음 반환 값의 형식을 지정하는 예제를 하나 제공하여 ret_val이라는 변수에 할당
- 입력 지시문은 녹색이며 생성된 출력은 강조되어 있습니다:

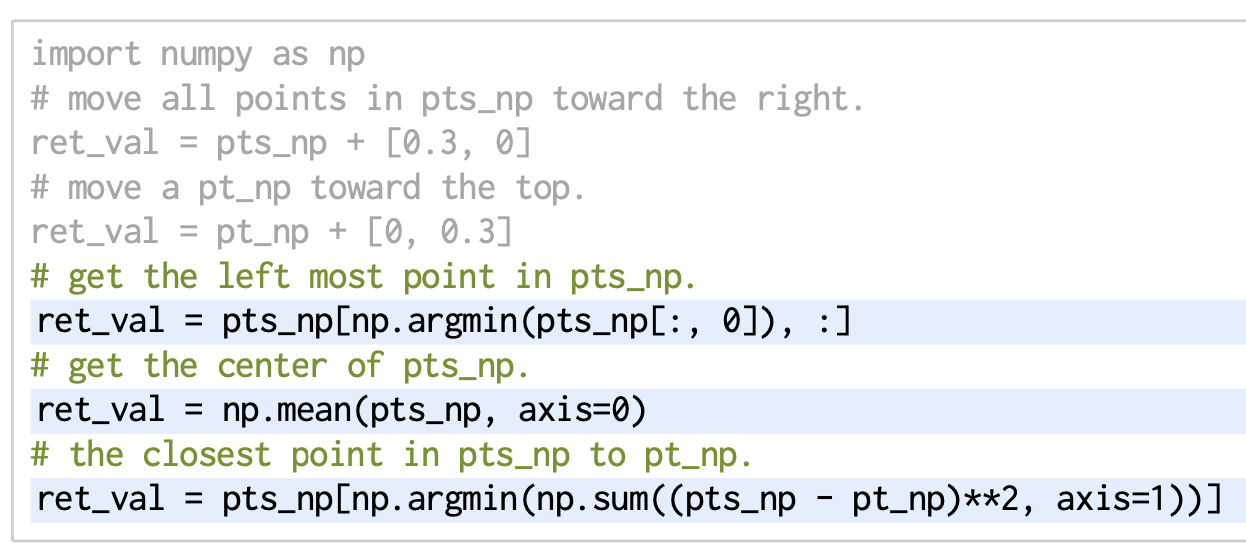
Third-party libararies.
- 파이썬 코드 작성 LLM은 많은 인기 있는 라이브러리에 대한 지식을 저장
- 예를 들어 NumPy를 사용하여 좌표를 이용한 공간 추론을 유도하는 것
- 여기서 힌트에는 import 문이 포함되어 있으며, 예제는 기본 방향을 정의
- 변수 이름은 pts_np와 pt_np가 NumPy 배열임을 나타내기 위해 중요
- 2D 벡터로 수행되는 연산은 점이 2D라는 것을 의미합니다. 예:
First-party libraries
- LMP는 또한 의미 있는 이름을 가지고 힌트/예제에 제공된 경우,
- 훈련 데이터에서 찾을 수 없는 퍼스트 파티 라이브러리(perception or control primitive API)도 사용할 수 있습니다.
- 예를 들어(B.2의 전체 프롬프트):

- 힌트는 로봇 도메인에서 사용할 두 가지 함수를 가져옵니다:
- 하나는
open vocabulary object detector[2]를 사용하여 이름으로 객체의 2D 위치를 얻는 함수이고, 다른 하나는객체 이름 또는 2D 위치를 대상으로 하여 첫 번째 객체를 두 번째 대상 위에 놓는 함수입니다. - LMP가 새로운 지시문에 적응할 수 있는 능력에 주목하세요.
- 첫 번째는 "조금"을 사용하여 이동 크기를 수정하고, 두 번째는 "같은 색상"으로 객체를 연관시킵니다.
Language Reasioning
- 언어 추론은 코드 작성 LLM(B.1의 전체 프롬프트 참조)을 사용하여 객체 이름을 자연어 설명("바다색 블록"), 카테고리("그릇") 또는 과거 컨텍스트("다른 블록")와 연관시키는 등의 작업을 몇 가지 샷으로 프롬프트할 수 있습니다:

C. Example Language Model Programs(high-level)
Control flows
- 프로그래밍 언어는 if-else 및 루프 문 같은 제어 구조를 사용할 수 있습니다.
- 이전에 우리는 LMP가 리스트 내포 형태로 for-루프를 표현할 수 있음을 보여주었습니다.
- 여기서는 LMP가 while-루프를 작성하여 간단한 피드백 정책을 형성하는 방법을 보여줍니다.
- 프롬프트(B.2와 동일)에는 이러한 예제가 포함되어 있지 않습니다:

LMPs can be composed
- LMP는 중첩된 함수 호출을 통해 구성할 수 있습니다.
- 이를 통해 LLM의 최대 입력 토큰 길이 내에서
- 기능 정확도와 범위를 개선하기 위해 개별 프롬프트에 더 많은 몇 가지 샷 예제를 포함할 수 있습니다.
- 다음은(B.4의 전체 프롬프트) 객체 이름을 언어 설명과 연관시키는 또 다른 LMP인 parse_obj를 사용하는 응답을 생성합니다:

- parse_obj LMP(부록 B.5의 전체 프롬프트):

LMPs can hierarchically genearte functions
- LMP는 향후 재사용을 위해 계층적으로 함수를 생성할 수 있습니다:
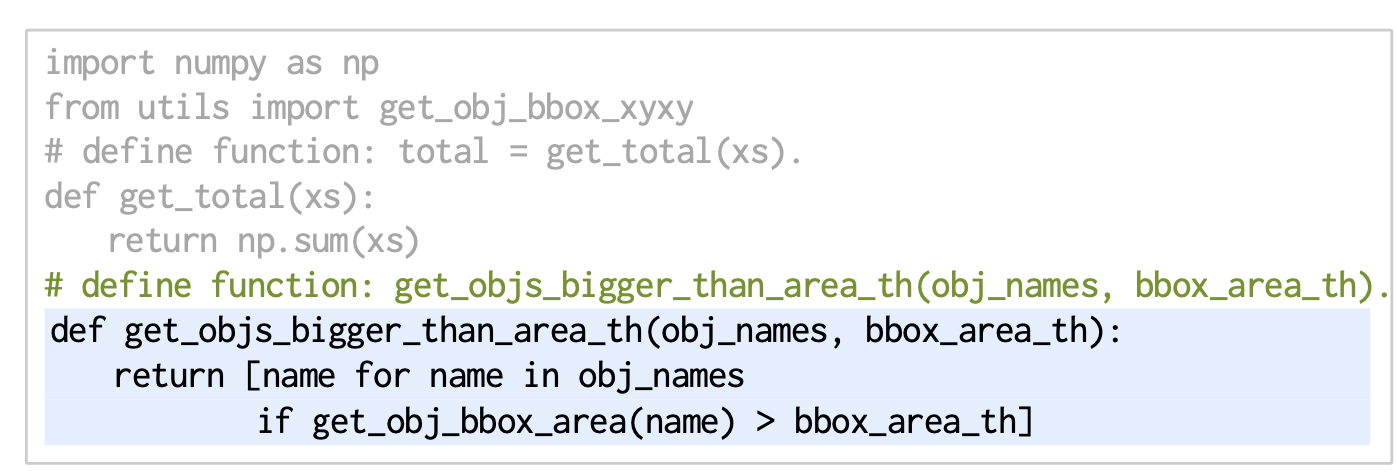
- 함수 생성은 LMP가 생성한 코드를 파싱하고,
아직 정의되지 않은 함수를 찾아 해당 함수를 생성하는 데 전문화된 또 다른 LMP를 호출하여 구현할 수 있습니다. - 이를 통해 프롬프트와 LMP가 생성한 코드 모두에서 아직 정의되지 않은 함수를 호출할 수 있습니다.
- 프롬프트 엔지니어는 더 이상 예제에 모든 구현 세부 사항을 제공할 필요가 없으며, 코드 로직의 "개략적인 스케치"만으로도 충분합니다.
- High-level LMP는 좋은 추상화 관행을 따르고, 모든 코드 로직을 한 수준으로 "평탄화"하는 것을 피할 수도 있습니다.
- 그 결과로 생성된 코드는 읽기 쉬워질 뿐만 아니라, IV-A에서 보여주듯이 코드 생성 성능도 향상됩니다.
- 아직 정의되지 않은 함수를 찾는 것도 생성된 함수의 본문 내에서 수행됩니다.
- 위의 예제에서 get_obj_bbox_area는 제공된 API 호출이 아닙니다. 대신 필요에 따라 생성할 수 있습니다:

- 프롬프트는 get_obj_bbox_xyxy가 정확히 무엇을 반환하는지 명시하지 않았지만, 이름에서 축에 정렬된 바운딩 박스의 최소 및 최대 xy 좌표를 포함하고 있음을 알 수 있으며, LLM은 이를 추론하고 올바른 코드를 생성할 수 있습니다.
- 파이썬에서는 코드 블록의 추상 구문 트리를 파싱하고 주어진 범위에 존재하지 않는 함수를 확인하여 계층적 함수 생성을 구현합니다.
- 우리는 이러한 정의되지 않은 함수를 작성하고 범위에 추가하기 위해 함수 생성 LMP를 사용
- 이 과정은 생성된 함수 본문에 대해 반복되며, 깊이 우선 방식으로 새로운 함수를 계층적으로 생성
Combining control flows, LMP composition and hierarchical function generation
- 다음 예제는 LMP가 이러한 기능을 결합하여 보다 복잡한 지시에 따르고 탁상 조작 도메인에서 작업을 수행하는 방법을 보여줍니다.
간결함을 위해 프롬프트는 생략되었지만 이전 프롬프트와 유사합니다.- 고수준 LMP는 고수준 정책 동작을 생성하고, parse_obj를 사용하여 언어 설명으로 객체 이름을 얻습니다:

- 그런 다음, parse_obj는 get_objs_bigger_than_area_th(아직 정의되지 않은 함수)를 사용하여 쿼리를 완성합니다.
- 이 함수는 parse_obj 프롬프트의 힌트에 import 문으로 제공되지만 구현되지 않았습니다.
- 계층적 함수 생성은 위에서 보여준 것처럼 이후에 이 함수를 생성합니다.

- 부록 A에서는 프롬프트 엔지니어링에 대해 자세히 설명합니다.
D. 언어 모델 프로그램을 정책으로 사용
- 로봇 정책의 맥락에서 LMP는 자연어 지시문을 기반으로 perception model(들)의 고수준 출력(state)을 프로그래밍적으로 조작하고, 저수준 제어 API(액션)의 매개변수를 결정하는 데 사용할 수 있는 인식-제어 피드백 로직을 구성할 수 있습니다.
- 사용 가능한 인식 및 제어 API에 대한 사전 정보는 예제와 힌트로 안내할 수 있습니다.
- 이러한 API는 LMP를 실제 로봇 시스템에 "매핑"하며, 인식 및 제어 알고리즘의 개선은 LMP 기반 정책의 성능 향상으로 이어질 수 있습니다.
- 예를 들어, 아래의 실제 실험에서는 ViLD [3] 및 MDETR [2]과 같은
오픈 어휘 객체 검출 모델을 사용하여 객체 위치와 바운딩 박스를 얻습니다. - LMP 기반 정책의 장점은 다음과 같습니다:
- (i) 보이지 않는 자연어 지시문으로 지정된 새로운 작업과 행동에 policy code와 parameter를 적응시킬 수 있습니다.
- (ii) 오픈 어휘 인식 시스템 및/또는
saliency 모델을 기반으로 새로운 객체와 환경에 일반화할 수 있습니다. - (iii) 추가 데이터 수집이나 모델 훈련이 필요하지 않습니다.
- 생성된 계획과 정책은 코드로 표현되기 때문에 해석 가능하며, 쉽게 수정하고 재사용할 수 있습니다.
- LMP를 사용하여 고수준 사용자 상호 작용을 수행하면 -> 상식적 지식을 갖춘 자연어를 파싱하고, 이전 컨텍스트를 고려하고, 다국어 기능을 제공하며, 대화에 참여하는 등 LLM의 장점을 활용할 수 있습니다.
- 이어지는 실험 섹션에서는 다양한 로봇과 다양한 작업에 걸쳐
LMP의 여러 인스턴스를 구현하여 이 접근 방식의 유연한 기능과 사용 편의성을 보여줍니다.
5. Experiments
- 우리 실험의 목표는 다음과 같습니다:
- (i) 계층적 코드 생성(다양한 언어 모델에 걸쳐)을 사용하는 것이 어떤 영향을 미치는지 평가하고 일반화 방식을 분석
- (ii) (시뮬레이션 실험) 언어 지시에 의한 조작 작업에서 Code as Policies(CaP)를 baseline과 비교
- (iii) 다양한 로봇 시스템에서 CaP를 시연하여 유연성과 사용 편의성을 보여주기
- 이러한 실험을 재현할 수 있는 동영상과 Colab 노트북은 웹사이트에서 확인할 수 있습니다.
A. Hierarchical LMPs on Code-Generation Benchmarks
- 우리는 두 가지 코드 생성 벤치마크인 (i)
로봇 테마의 RoboCodeGen과 (ii)표준 코드 생성 문제로 구성된 HumanEval [1]에서 코드 생성 접근 방식을 평가
RoboCodeGen
- 이전의 코드 생성 벤치마크와 몇 가지 주요 차이점이 있는, 37개의 함수 생성 문제로 구성된 새로운 벤치마크를 소개
- (i) 공간 추론(예: 점 집합에 가장 가까운 점 찾기), 기하학적 추론(예: 하나의 바운딩 박스가 다른 바운딩 박스에 포함되어 있는지 확인), 제어(예: PD 제어)에 대한 질문이 있는 로봇 주제
- (ii) 타사 라이브러리(예: NumPy)를 사용하는 것은 허용되고 권장
- (iii) 제공된 함수 헤더에는 docstrings나 명시적인 타입 힌트가 없으므로, LLM은 일반적인 관습을 추론하고 사용해야 합니다.
- (iv) 계층적 코드 생성으로 생성할 수 있는 아직 정의되지 않은 함수를 사용하는 것도 허용됩
- 벤치마크 질문의 예는 부록 E에서 확인할 수 있습니다.
- OpenAI API1에서 액세스할 수 있는 네 가지 LLM을 평가합니다.
- 표준 벤치마크와 마찬가지로 [1], 평가 지표는 인간이 작성한 단위 테스트를 통과하는 생성된 코드의 백분율. 표 1을 참조하세요.
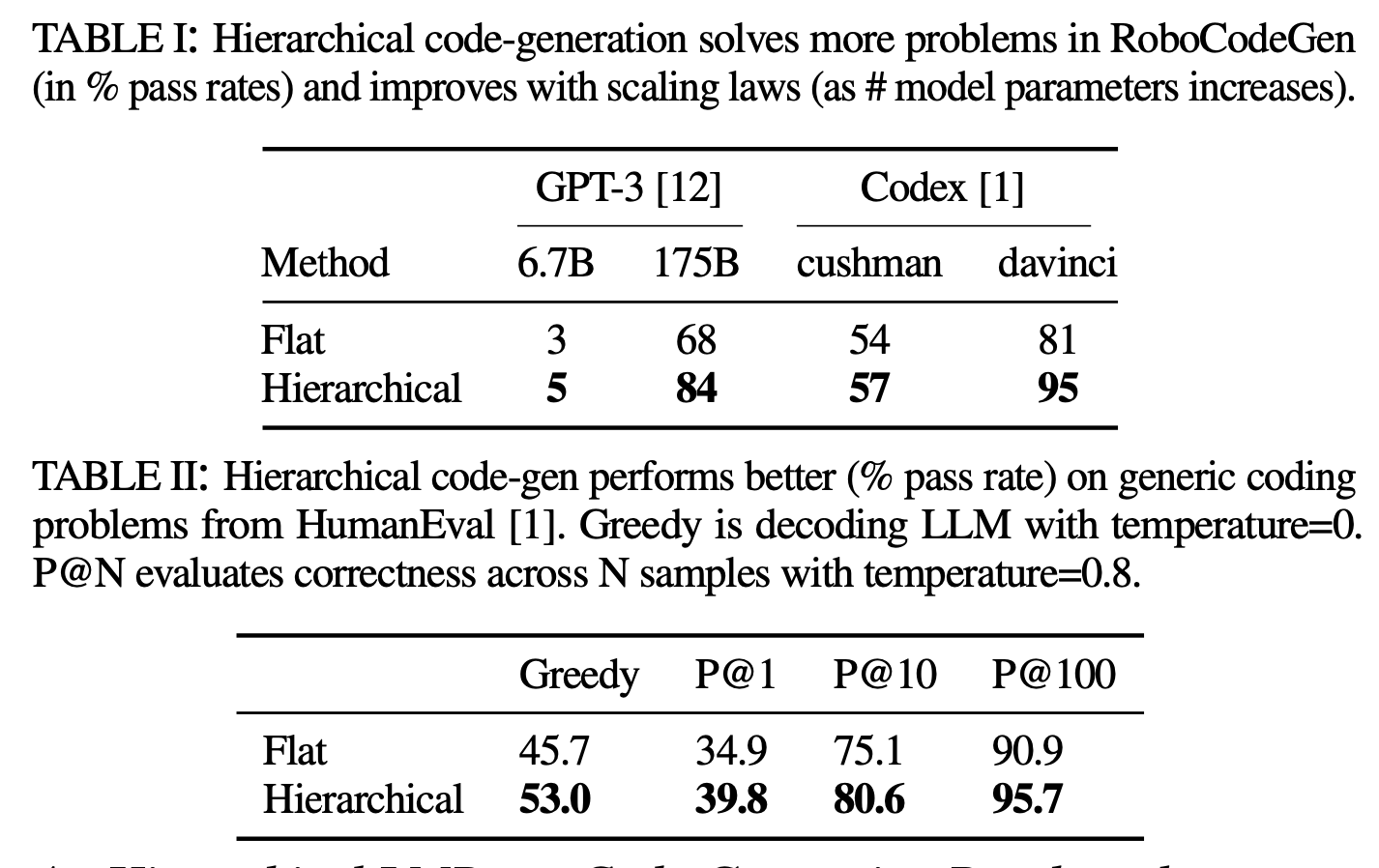
도메인 특정 언어 모델(Codex 모델)은 일반적으로 더 나은 성능을 보입니다.- 각 모델 패밀리 내에서 더 큰 모델의 성능이 향상됩니다.
- Cushman은 Codex 모델의 초기 버전 중 하나입니다. 이는 더 작고, 더 빠르며, 상대적으로 덜 복잡한 모델
- Davinci는 Codex 모델의 더 발전된 버전입니다. 이는 더 크고, 더 복잡하며, 더 강력한 성능을 제공합니다.
- 계층적 접근 방식은 LLM이 복잡한 함수를 계층적 부분으로 분해하고, 각 부분에 대해 코드를 별도로 생성할 수 있도록 함으로써 전반적으로 더 나은 성능을 보입니다.
- 또한 [23]에서 제안한 다섯 가지 일반화 유형에 따라 코드 생성 성능이 어떻게 달라지는지 분석합니다.
- 계층적 접근 방식은 -> 예제에 있는 것보다 더 많은 논리 계층을 가진 더 긴 코드가 필요한 새로운 지시문이 있을 때 생산성을 가장 많이 향상시킵니다.
- 그러나 이러한 개선은 두 개의 다빈치 모델에서만 나타나며 cushman에서는 나타나지 않습니다.
- 이는 계층적 코드 생성이 추가적인 개선을 가져올 수 있기 전에, 일정 수준의 코드 생성 능력을 먼저 달성해야 함을 시사합니다.
- 더 많은 결과는 부록 E.2에 있습니다.
B. CaP: Drawing Shapes via Generated Waypoints
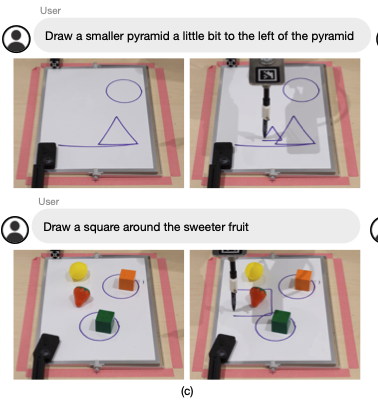
- 이 도메인에서는 실제 UR5e 로봇 팔을 사용하여 2D 웨이포인트를 생성하고 따르는 방식으로 다양한 도형을 그리도록 합니다.
- 인식을 위해 LMP는 오픈 어휘 객체 검출기 MDETR [2]을 사용하여 구현된 객체 위치를 감지하는 API를 제공받습니다.
- 액션을 위해서는 end-effector trajectory following API가 제공됩니다. 다음과 같은 네 가지 LMP가 있습니다:
- (i) 사용자 명령어 파싱, 세션 유지 및 액션 API 호출,
- (ii) 언어 설명에서 객체 이름 파싱,
- (iii) 언어 설명에서 웨이포인트 파싱,
- (iv) 새 함수 생성.
C. CaP: Pick & Place Policies for Table-Top Manipulation

- 탁상 조작 도메인에서는 UR5e 로봇 팔을 사용하여 탁자 위에 있는 다양한 플라스틱 장난감 객체를 집고 놓는 작업을 수행합니다.
- 로봇 팔에는 흡착식 그리퍼와 핸드 내 Intel Realsense D435 카메라가 장착
- MDETR [2]을 통해 객체의 존재, 위치, 바운딩 박스를 감지하는 인식 API를 제공
- 또한 객체를 집어서 대상 위치에 놓는 스크립트화된 기본 기능도 제공
- 프롬프트는 이전 도메인과 유사하지만 궤적 파싱 대신 위치 파싱을 수행
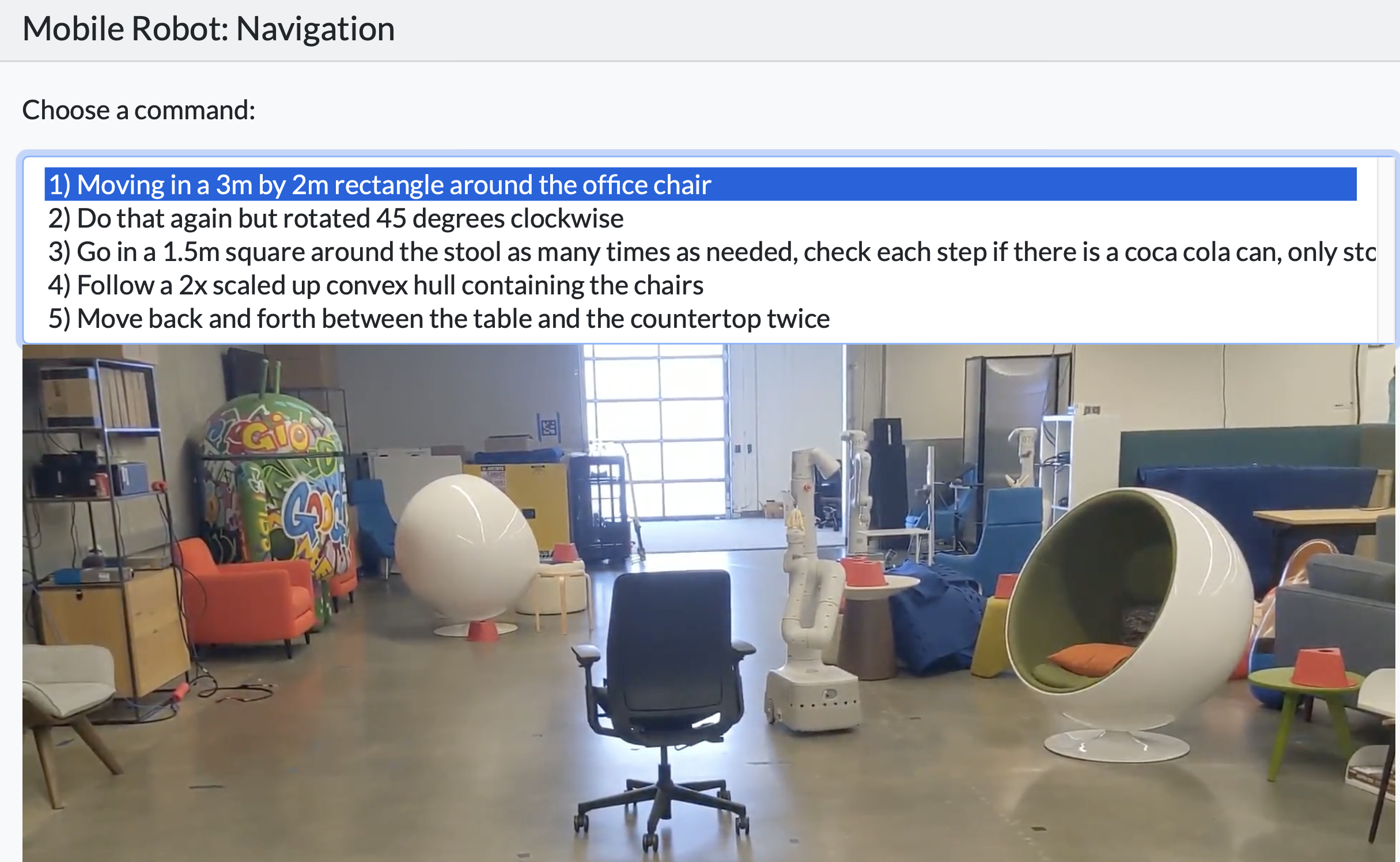
E. CaP: Mobile Robot Navigation and Manipulation

- 이 도메인에서는 이동 기지와 7 자유도 팔을 가진 로봇이 실제 주방에서 네비게이션 및 조작 작업을 수행하도록 한다.
- 인식을 위해 LMP는
ViLD [3]를 통해 구현된 객체 탐지 API를 제공받는다. - 작업을 위해 로봇은 이름과 좌표를 통해 위치로 네비게이션하고 객체를 잡는 API를 제공받는다.
Discussion and limitations
- CaP는 로봇 스택의 특정 레이어에서 일반화된다:
- interpreting natural language instructions,
- processing perception outputs,
- then parameterizing low-dimensional inputs to control primitives.
- CaP는 인식과 제어가 분리된 시스템에 적합,
end-to-end training에 필요한 데이터 수집 규모 없이, 미리 학습된 LLM에서 획득한 일반화를 제공- 우리의 방법은 또한 코드 작성과 관련이 없는 LLM 기능도 상속받는다.
- 예를 들어 비영어권 언어 또는 이모지를 사용하는 지시 지원
- CaP can also express cross-embodied plans that perform the same task differently depending on the available APIs.
- 그러나 이 능력은 기존 LLM에서는 취약하며, 도메인-특정 코드로 훈련된 더 큰 모델이 필요할 수 있다.
- 현재 CaP는 아래의 것들에 의해 제한된다.
- (i) what the perception APIs can describe
- 예: "궤적이 울퉁불퉁한지" 또는 "더 C자형인지"를 설명할 수 있는 시각-언어 모델 없음
- (ii) 사용할 수 있는 control primitives
- (i) what the perception APIs can describe
- 프롬프트를 과포화시키지 않고 조정할 수 있는 이름이 있는 원시 매개변수는 소수에 불과하다.
- 이 문장은 "모델이 과도한 정보를 주지 않고 조정할 수 있는 기본 매개변수의 수가 매우 적다"는 뜻입니다.
- 즉, 프롬프트에 너무 많은 매개변수를 포함시키면 모델이 이를 효과적으로 처리하지 못하기 때문에, 모델이 다룰 수 있는 매개변수의 수가 제한적이라는 의미입니다.
- CaP는 주어진 예시보다 훨씬 길거나 복잡한 명령을 해석하거나 다른 추상화 수준에서 작동하는 데 어려움을 겪는다.
- 테이블 위 도메인에서는 LMP가 "블록으로 집을 짓는" 작업을 수행하는 것이 어려울 것이다, 왜냐하면 복잡한 3D 구조를 구축하는 예시가 없기 때문이다.
- 우리의 접근 방식은 또한 주어진 지시가 실행 가능하다고 가정하며, 사전에 응답이 올바를지 여부를 판단할 수 없다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.