Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning
foundation model in robotics
목록 보기
8/14
- robot-vila.github.io.
- https://arxiv.org/pdf/2311.17842
- 읽어볼 논문
- RT-2: https://arxiv.org/pdf/2307.15818 (380회 인용)
- PaLM-E: https://arxiv.org/pdf/2303.03378 (950 회 인용)
- GPT4-V
- RAVENS 시뮬레이션 환경
- manipulation을 위한 시뮬레이션 환경
- https://proceedings.mlr.press/v155/zeng21a/zeng21a.pdf
- https://transporternets.github.io
0. Abstract
- LLM은
lack of world groundinganddependence on external affordance models(환경 정보를 인지하기 위한 모델)의 제약으로 인해, 추론능력이 떨어짐- affordance model
- open vocab detector 같은 것
의자: 앉을 수 있다, 손잡이: 잡을 수 있다와 같은 정보를 제공해주는 model
- affordance model
- 논문에서 제안하는, vision-language models (VLMs)을 이용한
long-horizon robotic planning은a sequence of actionable steps을 출력- perceptual data를 직접적으로 reasoning & planning process에 사용
- 또한, flexible multimodal goal specification을 지원하고,
- visual feedback이 가능합니다.
- VILA는 시각적 피드백을 효과적으로 활용하여 동적 환경에서 견고한 closed loop 계획을 가능하게 함
1. Introduction
- "콜라 캔 가져와" 명령을 받았을 떄
- 사람은,
- 아래 과정 수행
- 콜라캔이 보이면, 바로 가져오고,
- 콜라캔이 보이지 않으면, 냉장고나 저장공간을 탐색합니다.
- scene을 이해하면서, 동시에 상식을 사용해서 생각을 함.
- 아래 과정 수행
- 그동안의 LLM +
affordance model은- 아래와 같은 역할
- LLM: 장님이 생각하고 사고 함
affordance model: 장님이 하고 싶은 목표와 마음은 모르는, 시각 안내자.
- task에 관련이 있는 시각 정보들을 우선순위로 제공해야하는데, 그러지 못함.
- 예: 콜라캔은 냉장고와 저장공간에 있을 가능성이 크다는 사실
- 아래와 같은 역할
- 최근 GPT-4V(ision)로 대표되는 비전-언어 모델(VLM)
- 로봇 비전-언어 계획(VILA)을 소개
- VILA는 독립적인 어포던스 모델을 사용하지 않고, 실행 가능한 단계의 순서를 생성
- VILA의 주요 특성
- 시각적 세계에 근거한 상식 지식의 깊은 이해.
- VILA는 공간 레이아웃(예: 앞에 장애물로 가로막힌, Marvel Model 꺼내기) 또는 객체 속성(예: 여러 모양이 다른 접시를 안정적으로 쌓기)을 이해해야 하는 복잡한 작업에서 뛰어남
- 기존 연구들은, 눈 감고 상상하는 agent이므로, Marvel Model 앞에 어떤 장애물이 가로막고 있는지 알 수가 없음!!
- 다목적 goal specification (specification: 어떤 것을 자세히 설명하거나 정의한 내용)
- VILA는 유연한 multi modal 목표 명세 접근 방식을 지원
- 언어 목표
- 다양한 형태의 이미지 목표
- 언어와 이미지를 조합한 목표
- 예:
이 주어진 사진이 보이는 곳으로 가서, 쓰레기 비우고 와.
- VILA는 유연한 multi modal 목표 명세 접근 방식을 지원
- 우리는 다양한 개방형 지침과 객체를 포함한 16가지 실제 일상 조작 작업에서 VILA를 체계적으로 평가
- VILA는 SayCan [2] 및 Grounded Decoding [40]과 같은 LLM 기반 계획자보다 일관되게 큰 차이로 우수한 성능을 보임
- 더 포괄적이고 엄격한 비교를 위해 우리는
RAVENS 환경 [93]을 기반으로 한16가지 시뮬레이션 작업으로 평가를 확장했으며, 이 환경에서도 VILA는 뚜렷한 향상을 보여줌
2. related work
2.1. 비전-언어 모델.
- VLMs를 구축하는 일반적인 접근 방식은
사전 훈련된 시각 인코더의 feature을LLMs의 입력 임베딩 공간과 정렬하기 위해cross- modal connector를 사용하는 것 [3, 53, 52, 10, 47, 36, 90, 97, 5, 81].- TODO: 이 부분에 대해 더 공부해보기.
2.2. Pre-Trained Foundation Models For Robotics.
- 최근 대형 사전 훈련된 기본 모델을 로봇 공학에 적용한 발전은 세 가지 범주로 분류 가능
2.2.1. Pre-Trained Vision Models
- 많은 기존 접근 방식은, 대규모 이미지 데이터셋 [28, 15]에서
사전 훈련된 비전 모델을 사용하여 visuomotor control tasks 을 위한 visual representations을 생성 - 그러나 로봇 시스템은 인식 모듈뿐만 아니라, 제어 정책도 포함
- 높은 수준의 의미론을 포착하는 시각적 표현에만 의존하는 것은
제어 정책의 일반화 가능성이나시스템의 전체적인 효과를 보장하지 못할 수 있음[35, 91, 30].
2.2.3. Pre-Trained Vision-Language Models:
- 많은 연구가 로봇 공학에서 비전-언어 모델(VLMs)의 적용을 탐구 [39, 19, 70, 96, 24].
- 특히, RT-2 [8]는 VLMs를 저수준 로봇 제어에 통합하는 것을 보여줌
- 이에 비해, 우리의 연구는 주로 고수준 로봇 계획에 중점을 둠
- PaLM-E [18]는 우리의 접근 방식과 유사하지만, 상당한 양의 로봇 공학 및 일반 비전-언어 데이터 [11, 54]로 훈련이 필요
- 이는 새로운 환경에 로봇을 도입하려면, 추가 데이터를 수집하고 모델을 다시 훈련해야 함을 의미
- 이에 강하게 대조적으로, 우리의 VILA는 개방형 세계의 제로-샷 모델로,
- 추가 훈련 데이터나 프롬프트 내의 맥락 예시 없이도 수행 가능
3. method
- III-C절에서는 VILA의 장점에 기여하는 고유한 특성을 설명합니다.
A. 문제 정의 (formulation of the planning problem)
- input
- a visual observation: x_t
- high-level language instruction: L
- (e.g. “stack these containers of different colors steadily”)
- arbitrarily long-horizon or under-specified.
- goal
- l_1, l_2, ... ,l_T
- sequence of text actions
- l_t: short-horizon language instruction (e.g. “pick up blue container”)
- sub-task/primitive skil에 포함되어 있는 instruction (내가 사전에 정의한)
- l_1, l_2, ... ,l_T
B. 로봇 플래너로서의 비전-언어 모델
- 기존 연구들이 썼던 affordance model들
- value function of RL policies
- object detection models
- action detection models
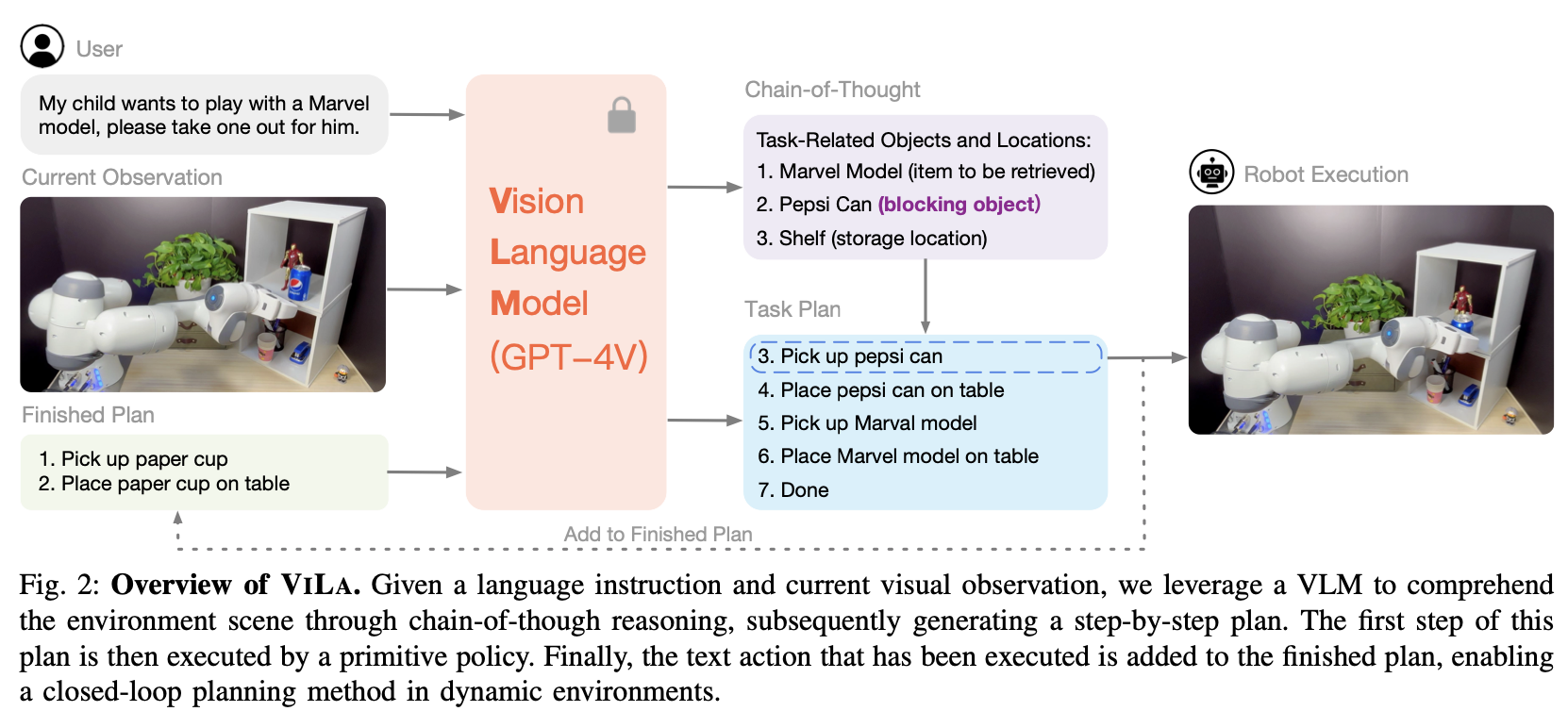
- Vision-Language Planning (ViLa)
- 환경의 현재 시각적 관찰 xt와 고수준 언어 목표 L를 주어진 상태에서, VILA는 VLMs를 프롬프트하여 단계별 계획 p{1:N} 을 생성
- 첫 번째 단계를 텍스트 동작
l_t = p_1로 선택하여 폐쇄 루프 실행을 가능하게 함 - 텍스트 동작 l_t가 선택되면, 동작과 관련된 해당 정책이 로봇에 의해 실행되고, VLM 쿼리가 l_t를 포함하도록 수정되며,
- 프로세스가 종료 토큰(예: "완료")에 도달할 때까지 다시 실행

- GPT-4V(ision): [61, 88]
- 더욱이, 우리는 GPT-4V를 동력으로 하는 VILA가
맥락 내 예시가 필요 없는 제로샷 모드에서도다양한 도전적인 계획 문제를 해결할 수 있음을 발견 - 이는 이전 접근 방식 [2, 37, 40]에서 요구되었던
프롬프트 엔지니어링 노력을 크게 줄여줌
- 더욱이, 우리는 GPT-4V를 동력으로 하는 VILA가
C. VILA의 흥미로운 특성
Visual world에서 상식의 이해
- 언어는
- 인간이 생성한 것이며 의미적으로 풍부하지만,
- 포괄적인 정보를 표현하는 데는 한계가 있음
- 이에 반해,
- 이미지는 저수준의 세밀한 특징을 지닌 자연 신호로,
- 단일 이미지로 장면의 전체 정보를 포착할 수 있음 (포괄적 정보 표현 가능)
- 복잡한 환경을 단순한 언어로 담아내기 어려울 때 이러한 차이(이미지의)가 특히 중요합니다.
Spatial Layout Understanding
- 언어만으로는 아래의 것들을 표현하기 어려움
- 공간의 위치
- 물체들의 공간적 관계
- 환경에서의 제약
- 혼잡한 장면에서 물체 A가 물체 B를 가리고 있다고 가정해봅시다.
- 물체 B에 도달하려면 먼저 물체 A를 옮겨야 합니다.
- 물체들 간의 이러한 미묘한 관계를 전달하기 위해서, 언어 설명에만 의존하는 것은 불충분
다용도의 goal specification
- 많은 복잡하고 장기적인 작업에서 -> 목표 이미지를 사용하여 원하는 결과를 나타내는 것이 단순히 언어 지시에만 의존하는 것보다 더 효과적일 때가 많습니다.
- 예를 들어, 로봇에게 책상을 정리하라고 지시할 때, 원하는 상태로 정리된 책상의 사진을 제공하는 것이 더 효율적일 수 있습니다.
- 마찬가지로, 음식 플레이팅 작업에서도 로봇이 이미지를 보고 그 배열을 재현할 수 있습니다.
- 우리 방법론은 input으로 목표 이미지 (x_g)를 포함가능 합니다.
- 이 특징은 목표와 시각적 관찰 이미지가 동일한 도메인에서 출처될 필요가 없다는 점에서
- 많은 기존의 목표 조건화 강화 학습(RL)/모방 학습(IL) 알고리즘 [58, 21, 17]과 다릅니다.
- 목표 이미지는 단지 작업의 필수 요소를 전달하면 되므로, 그 형태에 유연성을 제공합니다.
- 인터넷 사진
- 어린이의 그림
- 손가락으로 목표 위치를 가리키는 이미지
Visual Feedback
- (과거 연구들은) 환경 피드백을 오로지 LLMs에 의존하는 계획 방법에 통합하기 위한 노력의 일환으로, Huang 등 [38]은 모든 피드백을 자연어로 변환하는 방법을 연구했습니다.
- 시각적 피드백을 언어로 변환하면 시스템의 복잡성이 증가할 뿐만 아니라 + 중요한 정보를 잃을 위험도 있음
- 시각적 피드백을 통해 추론함으로써, VILA는 환경의 변화나 기술의 실패에 대응하여 로봇이 수정하거나 재계획할 수 있도록 합니다.
4. 실험 및 분석
A. realworld manipulation 작업
4.1.1. 실험 설정
- 1) 하드웨어:
- 실제 테이블탑 환경을 설정합니다.
- Franka Emika Panda robot (a 7-DoF arm) + a 1- DoF parallel jaw gripper
- 인식을 위해 삼각대에 장착된 Logitech Brio color camera를 사용하여 테이블탑을 향하도록 각도를 맞춥니다.
- 2) 작업 및 평가:
- VILA의 성능을 평가하기 위해 16개의 장기 manipulation 작업을 설계
- 이 작업은 세 가지 도메인에서 평가
- 시각적 세계에서의 상식 지식 이해(8개 작업),
- 목표 명세의 유연성(4개 작업),
- 시각적 피드백 활용(4개 작업)
- 그림 1에는 첫 번째 두 도메인에서 선택한 12개의 작업이 나와 있습니다.
- 각 작업에 대해
환경의 10가지 다양한 변형(장면 구성 및 조명 조건 변경 등)에서 모든 방법을 평가 - 각 작업에 대한 포괄적인 세부 사항은 부록을 참조

- 3) VLM 및 프롬프팅:
- OpenAI API의 GPT-4V를 VLM으로 사용
- 이전 접근 방식 [2, 40]과 달리,
- 프롬프트에 맥락 예시를 포함하지 않고 아래 2개 제공
- 고수준 언어 지시
로봇이 충족해야 하는 몇 가지 간단한 제약 조건만 사용(즉, 엄격한 제로샷).
- 전체 프롬프트는 부록에 나와 있습니다.
- 4) 원시 기술:
- composition(구성) 및 planning을 통해 복잡한 행동을 가능하게 하는
- 다섯 가지 범주의 원시 기술을 사용
- 여기에는 "물체 집기", "물체를 다른 물체에 놓기", "물체 열기", "물체 닫기", "물체를 다른 물체에 붓기"가 포함
- 저수준 원시 기술에 대한 추가 세부 사항은 부록에 있습니다.
- composition(구성) 및 planning을 통해 복잡한 행동을 가능하게 하는
- 5) baselines:
- 외부 어포던스 모델을 사용하여 LLM을 기반으로 하는 SayCan [2] 및 Grounded Decoding (GD) [40]과 비교
- 이러한 baselines을 구현하려면 LLM의 출력 토큰 확률에 접근해야 합니다.
- 그러나 현재 OpenAI API는 이러한 확률을 반환하지 않으므로, 대안으로 오픈 소스 Llama 2 70B [79]를 사용
- affordance 모델로는 Huang 등 [40]을 따르며, OWL-ViT [57, 56]를 사용
4.1.4. VILA는 시각적 피드백을 자연스럽게 활용할 수 있음
- 동적 작업에서 오픈 루프 변형이 계속적인 재계획이 필요한 작업에 어려움을 겪는 반면, 폐쇄 루프 VILA가 크게 뛰어남을 보여줍니다.
- VILA는 외부 방해로부터 효과적으로 복구할 수 있을 뿐만 아니라 실시간 시각적 관찰에 기반하여 전략을 조정할 수 있습니다.
- 예를 들어, 그림 6에 묘사된 바와 같이, VILA는 상단 서랍에서 스테이플러를 찾지 못하자 하단 서랍을 확인하여 스테이플러를 성공적으로 찾아 작업을 완료합니다.

B. 시뮬레이션된 테이블탑 재배열
실험 설정.
- 기준 방법과의 보다 엄격하고 공정한 비교를 제공하기 위해 시뮬레이션된 테이블탑 재배열 작업에서 실험을 수행합니다.
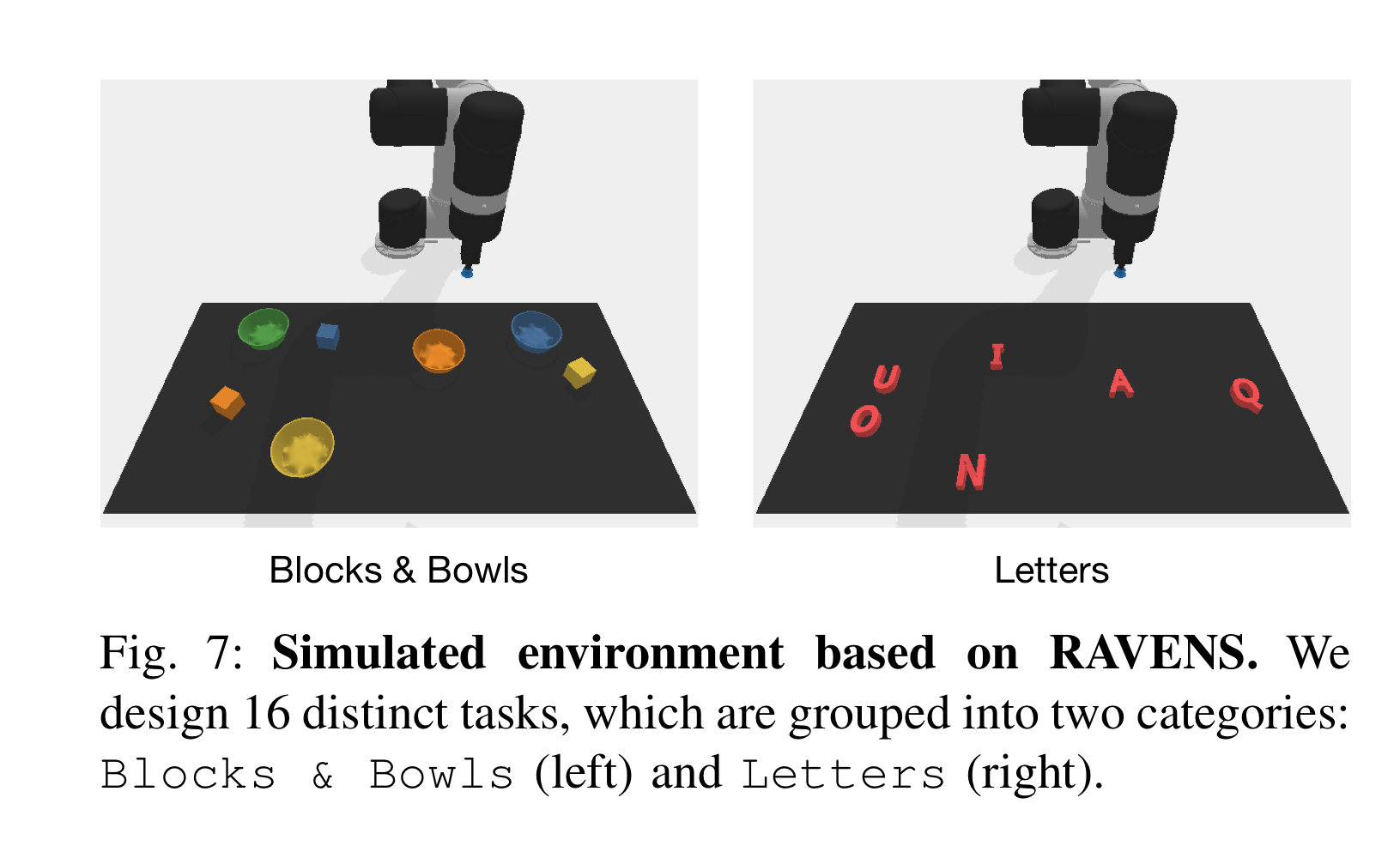
- Grounded Decoding [40] 설정을 따라, RAVENS 환경 [93]을 기반으로 16개의 작업을 개발
- 이 작업은 두 그룹으로 분류됩니다:
- few 샷 프롬프트나 지도 학습 기준 방법의 훈련에 사용되는 6개의 작업이 포함된 본 그룹
- 10개의 보지 못한 작업으로 구성된 그룹.
- 작업은 두 가지 유형으로 더 분류됩니다 (그림 7 참조):
- (i) 블록 및 그릇 (8개의 작업),
- 블록과 그릇을 재배열하거나 결합하는 작업 (예: "모든 블록을 일치하는 색상의 그릇에 넣으세요").
- (ii) 알파벳 글자 (8개의 작업),
- 알파벳 글자를 재배열하는 작업 (예: "테이블 위에 글자를 알파벳 순서대로 놓으세요").
- (i) 블록 및 그릇 (8개의 작업),
- 우리의 비교는 세 가지 기준 방법 범주를 포함합니다:
- (i) CLIPort,
계획 없이 고수준 언어 지침을 직접 받아들이는 언어 조건 모방 학습 에이전트- 우리는 두 가지 변형을 고려
- 단일 단계 집기 및 놓기 지침으로 훈련된 "Short"와
- 고수준 지침으로 훈련된 "Long".
- (ii) 어떠한 기반/어포던스 모델도 사용하지 않는 LLM 기반 플래너.
- 우리는 Llama 2와 GPT-4를 평가
- (iii) 계획 강화를 위해 LLM과 어포던스 모델을 통합하는 Grounded Decoding (GD).
- 여기서 Llama 2를 LLM으로 사용
- (i) CLIPort,
- TODO: 블록 및 그릇의 경우 어포던스는 CLIPort의 예측된 로짓에서 도출되고, 글자의 경우 시뮬레이션에서 얻은 실제 어포던스 값을 사용합니다.
6. prompt
You are highly skilled in robotic task planning, breaking down intricate and long-term tasks into distinct primitive actions.
If the object is in sight, you need to directly manipulate it. If the object is not in sight, you need to use primitive skills to find the object first. If the target object is blocked by other objects, you need to remove all the blocking objects before picking up the target object. At the same time, you need to ignore distracters that are not related to the task. And remember your last step plan needs to be "done". Consider the following skills a robotic arm can perform. In the descriptions below, think of [sth] as an object:
1. pick up [sth]
2. place [sth] in/on [sth]
3. pour [sth] into/onto [sth]
4. open [sth]
5. close [sth]
You are only allowed to use the provided skills. It's essential to stick to the format of these basic skills. When creating a plan, replace these placeholders with specific items or positions without using square brackets or parentheses. You can first itemize the task-related objects to help you plan.
[Initial Environment Image]
[Task Instruction]
[Reply from GPT-4V]
[Environment Image after Executing Some Steps]
This image displays a scenario after you have executed some steps from the plan generated earlier. When interacting with people, sometimes the robotic arm needs to wait for the person's action. If you do not find the target object in the current image, you need to continue searching elsewhere.
[Reply from GPT-4V]
새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.