VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
foundation model in robotics
목록 보기
9/14
0. 그림들
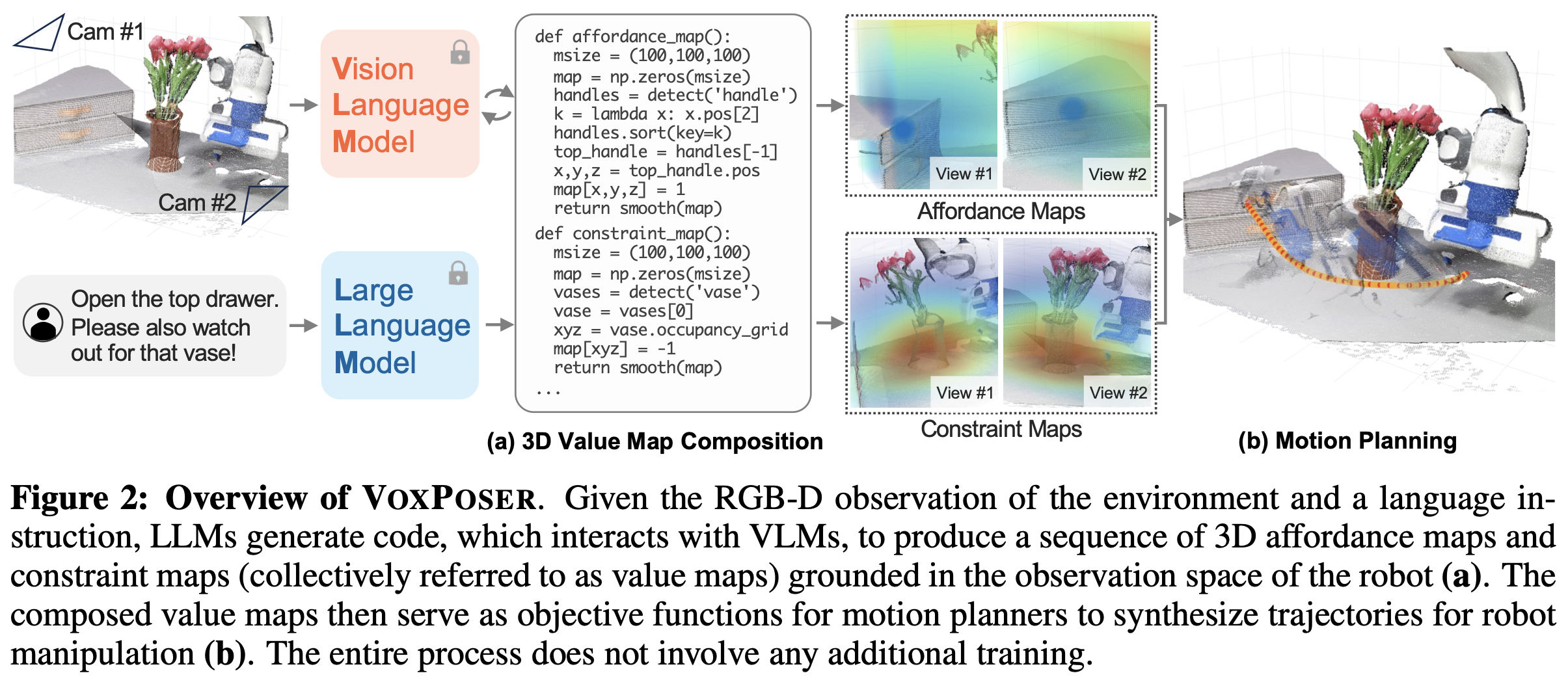
- LLM: 위 input 지시어의
affordance와 constraint를 출력 - VLM:
affordance와 constraint를 3D value map에 grounding함.- 위 두 과정은 code interface를 사용하며, 추가적인 학습이 필요 없다.
- value map은
affordance maps와constraint maps를 의미함. - 위 value map은 robot manipulation의 trajectory를 합성하기 위한 motion planner의
objective function으로 쓰임!

- input:
- RGBD observation
- 지시어 Open the top drawer, and watch out for the vase!
- 3D value map
- manipulator이 open-set 지시와 open-set object 환경에서,
- trajectory를 도출할 수 있음.

1. abstract
- 대부분의 연구는 여전히 사전 정의된 모션 프리미티브에 의존하여 환경과의 물리적 상호작용을 수행하는데, 이는 여전히 LM 로봇 도입의 주요 병목 현상으로 남아 있습니다.
- 이 연구는: 로봇 궤적, 즉 6자유도 end-effector 경로의 밀집된 시퀀스를 합성하는 것을 목표로 합니다.
- 우리가 구성한 값 지도는 로봇의 움직임을 계획하는 시스템에 입력으로 사용되어, 실시간으로 환경을 모니터링하고 변화에 대응할 수 있는 로봇의 경로를 사전 학습 없이 즉시 생성할 수 있게 합니다. (iterative하게 경로를 수정함)
- 제안된 시스템은 로봇이 물체를 많이 만지거나 조작해야 하는 상황에서도 효율적으로 동적 모델을 학습할 수 있습니다.
- 이를 통해 로봇은 실시간으로 얻는 경험을 바탕으로 더 나은 성능을 발휘할 수 있습니다.
- 즉, 로봇이 작업을 수행하면서 얻는 데이터를 활용하여, 상황에 맞게 동작을 조정하고 개선할 수 있다는 것을 보여줍니다.
- Videos and code at: https://voxposer.github.io
3. Method
3.1. Problem Formulation
- free-form language instruction L (e.g., “open the top drawer”).
- 위 논문은, L → (l1 , l2 , . . . , ln ) 가 완료된 상황을 가정한다.
- 즉, “grasp the drawer handle”, “pull open the drawer” 와 같이, sub-task로 나눠진 후의 상황을 가정함.
- 이 과정은, high-level planner (e.g., an LLM or a search-based planner) 이 수행함.
- 이 과정은 해당 논문의 범위를 벗어난다.
- 이 논문의 목표는, 로봇 r이 각 sub-instruction li을 받았을 때, manipulation에 필요한
motion trajectory τir를 생성하는 것이다. - 논문에서,
motion trajectory τir은 end-effector waypoints의 dense waypoints를 의미- 각 waypoint는
6-DoF end-effector pose,end-effector velocity, andgripper action을 포함 (Operational Space Controller [117]에서)
- 각 waypoint는
- 그러나, 이러한 trajectory말고도, joint space trajectories와 같은 것도 가능하다!!
- 문제 정의는 아래와 같다. (아래 objective function을 최소화하는
motion trajectory τir를 찾는 것.) 
3.2. Grounding Language Instruction via VoxPoser
- 많은 작업이 로봇의 관찰 공간에서 V 의 복셀 값 지도로 특징지어질 수 있다.
- “entity of interest”: e
- its trajectory: τe
- F task는 e가 Vi 를 통과하는 동안의 값을 누적하여 계산
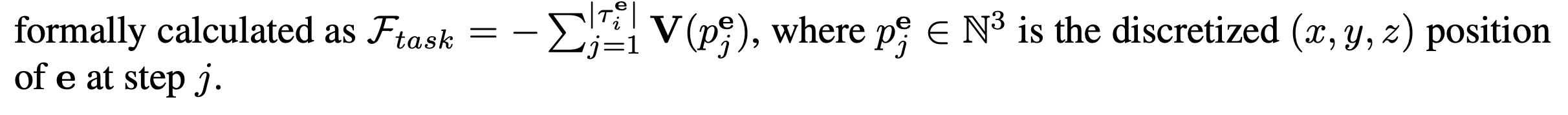
- 위 식에서 F_task의 정의
- l_i를 완료하는 정도를 평가.
- 환경 상태의 변화가, 주어진 지시를 얼마나 잘 수행했는지를 평가
- 예: 문을 열어라. task를 얼마나 잘 수행했는지?
- 지시가 코드의 주석으로 주어질 때, LLM은
- 1) 관련 객체의 공간-기하학적 정보를 얻기 위해 인식 API(예: 개방형 어휘 탐지기 [13–15])를 호출하고,
- 2) NumPy 연산을 생성하여 3D 배열을 조작하며,
- 3) 관련 위치에 정확한 값을 지정하도록 할 수 있습니다.
- 우리는 이 접근 방식을 VOXPOSER라고 부릅니다.
- 아래 식을 얻기 위해, LLM을 프롬프트하고 + 파이썬 인터프리터를 통해 코드를 실행합니다.
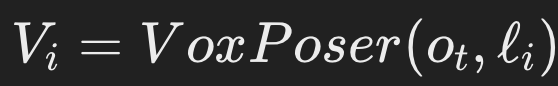
- 여기서 ot는 RGBD observation입니다. (시간 t에서)
- 또한, V가 종종 희소하기 때문에, 우리는 스무딩 연산을 통해 복셀 지도를 밀집화하여 모션 플래너가 최적화하는 궤적을 더 부드럽게 만듭니다.
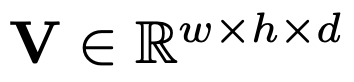
3.2.1. Additional Trajectory Parametrization
- 아래 글: V가 총 4개

- SE(3): Special Euclidean Group in 3 Dimensions
- 3차원 공간에서의 회전과 병진을 포함한 전체적인 위치 및 자세 변환을 나타내며,
- 이는 로봇의 특정 부위가 공간에서 어디에 있고 어떤 방향을 향하고 있는지를 표현
- SO(3): Special Orthogonal Group in 3 Dimensions
- 3차원 공간에서의 순수 회전만을 나타내며, 이는 로봇의 특정 부위가 어떤 방향을 향하고 있는지를 표현
3.3. Zero-Shot Trajectory Synthesis with VoxPoser
- 우리는 제안된 목표를 사용하여 궤적을 무작위로 샘플링하고 점수를 매기는 간단한 영차(zeroth-order) 최적화를 사용합니다.
- 최적화는 모델 예측 제어(MPC) 프레임워크에서 구현되며,
- 현재 관찰을 사용하여 매 단계마다 궤적을 반복적으로 재계획하여
- 동적 방해가 있는 상황에서도 궤적을 견고하게 실행할 수 있습니다.
- LLM을 루프에 포함시키더라도, 생성된 코드가 작업 ℓi 동안 동일하게 유지되기 때문에 폐쇄 루프 실행이 가능
- 이를 통해 현재 작업에 대한 출력을 캐시할 수 있음
- 이때 학습된 모델이나 물리 기반 모델을 사용할 수 있습니다.
- 이 뜻은, MPC가 action에 따른 미래 환경 변화나 reward를 예측할 때, 학습된 모델이나 물리기반 모델을 사용할 수 있다는 뜻이다.
- 그러나 VoxPoser는 관찰 공간에서 "밀집된 보상"을 효과적으로 제공하고, 우리는 매 단계마다 재계획할 수 있기 때문에,
- 전체 시스템이 간단한 휴리스틱 기반 모델을 사용하더라도
- 이미 이 연구에서 고려한 다양한 조작 작업을 수행할 수 있다는 것을 발견했습니다.
- 일부 값 지도는 로봇이 아닐 수도 있는 "관심 대상"에 대해 정의되므로,
- 우리는 작업 비용을 최소화하기 위해 필요한 로봇 궤적을 찾기 위해 동적 모델도 사용합니다
- (즉, 원하는 객체 움직임을 달성하기 위해 로봇과 환경 간의 상호작용).
3.4. Efficient Dynamics Learning with Online Experiences

4. Experiments and Analysis
4.0. 구현 세부 사항
4.0.1. LLMs and Prompting
- Code as Polices의 프롬프트 구조를 따름
- https://velog.io/@jk01019/Code-as-Policies-Language-Model-Programs-for-Embodied-Control
- 각 언어 모델 프로그램(LMP)이 고유한 기능(예: 인식 호출 처리)을 담당하는 코드를 재귀적으로 호출
- 각 LMP에는 5-20개의 예제 쿼리와 해당 응답을 프롬프트의 일부로 포함시킵니다.
- OpenAI API의 GPT-4 [2]를 사용
- TODO: 부록에서 프롬프트 예제 찾아서 기록하기
4.0.2. VLMs and Perception
- bounding box를 먼저 찾은 후, SAM을 이용하여 sementic mask를 찾는 방식으로 수행함.
마지막으로 비디오 추적기 XMEM [119]을 사용하여 마스크를 추적- XMEM: 딱히 볼만한 논문은 아님
4.0.3. Value Map Composition

- 위 글에서 high-level LMP 중 하나인 composer에 대한 설명
- TODO: 이 설명이 조금 애매한 것 같은데, 자세한 확인 필요

4.0.4. Motion Planner

4.0.5. Dynamics Model
- 모든 작업에서 알려진 로봇 동적 모델을 사용하여, 말단 효과기가 웨이포인트를 따르도록 motion planning에 사용
- 대부분의 고려된 작업에서 "관심 대상"이 로봇인 경우 환경 동적 모델은 사용되지 않습니다(즉, 장면이 정적이라고 가정함).
- 그러나 우리는 매 단계마다 최신 관찰을 반영하기 위해 재계획합니다.
- "관심 대상"이 객체인 작업의 경우 접촉 지점, 밀기 방향, 밀기 거리로 매개변수화된
평면 밀기 모델만 연구- 입력 포인트 클라우드를 밀기 방향으로 밀기 거리만큼 번역하는 휴리스틱 기반 동적 모델을 사용
- 우리는
무작위 샷팅을 사용하여 행동 매개변수를 최적화- 행동 매개변수
- 로봇이 특정 동작을 수행할 때 필요한 구체적인 값을 의미
- 예: 밀기를 몇 m 밀어야 하는가?
- 행동 매개변수
- 그런 다음 사전 정의된 밀기 프리미티브를 행동 매개변수에 따라 실행
- 그러나 행동 매개변수가 로봇의 말단 효과기나 관절 공간에 정의된 경우 프리미티브는 필요하지 않습니다.
- 이 경우 더 부드러운 궤적을 얻을 수 있지만 최적화에 더 많은 시간이 소요됩니다.
- 우리는 또한 섹션 4.3에서 학습 기반 동적 모델을 사용하여 VoxPoser가 온라인 경험에서 이점을 얻는 방법을 탐구합니다.
4.0.6. 보충 설명
- 프리미티브(primitive)란 로봇이 수행할 수 있는 기본 동작이나 행동 단위
- 이는 복잡한 작업을 수행하기 위해 조합될 수 있는 작은 단위의 동작
- 프리미티브는 특정 동작을 반복적으로 수행하기 위해 사전에 정의된 움직임이나 동작을 의미
- 예시:
- 그리퍼 열기/닫기: 로봇 팔의 그리퍼를 여는 동작이나 닫는 동작.
- 직선 이동: 로봇의 말단 효과기가 특정 방향으로 직선 이동하는 동작.
- 회전: 로봇 팔이 특정 각도로 회전하는 동작.
- 밀기: 로봇이 특정 방향으로 물체를 밀거나 당기는 동작.
4.0.6.1. 프리미티브를 실행하는 경우와, 프리미티브가 필요 없는 경우의 구분
- 프리미티브를 실행하는 경우:
- 로봇이 수행할 작업이 이미 정의된 기본 동작들로 이루어진 경우.
- 작업이 비교적 단순하고, 특정한 프리미티브를 연속적으로 실행하면 되는 경우.
- 예를 들어, "서랍을 열어라"라는 작업에서 로봇이 서랍 손잡이를 잡고, 뒤로 당기는 동작을 수행해야 하는 경우.
- 프리미티브가 필요 없는 경우:
- 로봇이
수행할 작업이 복잡하거나,특정 동작을 미리 정의하기 어려운 경우 - 작업이 다양한 상황에서 수행될 필요가 있으며,
실시간으로 궤적을 최적화해야 하는 경우. - 예를 들어, "책상 위의 여러 물체를 정리하라"라는 작업에서 로봇이 각각의 물체를 다양한 위치로 옮겨야 하는 경우.
- 로봇이
4.0.6.2. 프리미티브를 실행하는 경우와 프리미티브가 필요 없는 경우의 최적화 과정
- 프리미티브를 사용하면 실행 속도가 빠르고 간단하지만, 복잡한 작업에서는 실시간 최적화가 더 유연하고 효과적일 수 있습니다.
프리미티브를 실행하는 경우: 최적화 과정:
-
프리미티브 선택:
- 작업에 필요한 프리미티브를 선택합니다.
- 예를 들어, "서랍을 열어라"라는 작업에서는 "손잡이 잡기", "뒤로 당기기" 프리미티브를 선택합니다.
-
매개변수 설정:
- 각 프리미티브를 실행하기 위한 매개변수를 설정합니다.
- 예를 들어, "뒤로 당기기" 프리미티브의 경우, 당기는 방향과 거리를 설정
-
프리미티브 실행:
- 설정된 매개변수에 따라 프리미티브를 순차적으로 실행합니다.
- 각 프리미티브는 사전에 정의된 동작을 수행합니다.
프리미티브가 필요 없는 경우: 최적화 과정:
-
작업 분석:
- 수행해야 할 작업을 분석하고, 작업에 필요한 모든 매개변수를 정의합니다.
- 예를 들어, 물체를 특정 위치로 옮기기 위해 필요한 위치와 방향, 속도 등을 정의합니다.
-
경로 계획 및 최적화:
- 말단 효과기나 관절 공간에서 실시간으로 궤적을 계획하고 최적화합니다.
- 이 과정에서는 목표 위치와 회전, 속도 등을 포함한 전체 경로를 계산합니다.
-
실시간 재계획:
- 환경 변화나 예기치 않은 방해 요소를 반영하여 궤적을 실시간으로 재계획합니다.
- 매 단계마다 최신 관찰 데이터를 기반으로 최적의 경로를 업데이트합니다.
4.1. VoxPoser for Everyday Manipulation Tasks
- 실제 일상 조작 작업에 대해 검증
- 빠른 재계획 기능 덕분에, 이동하는 대상/장애물 및 로봇이 닫은 서랍을 다시 여는 등의 외부 방해에도 견고합니다.
- 우리는 또한 간단한 프리미티브 목록(예: 위치로 이동, 그리퍼 열기)을 매개변수화하기 위해
LLM을 사용하는 Code as Policies [75]의 변형과 비교 - 순차적 정책 논리를 연결하는 것과 비교하여,
- 공동 최적화 방식으로 다른 제약 조건을 고려하면서 공간적으로 구성할 수 있는 능력이 더 유연한 공식임을 발견했으며,
- 이는 더 많은 조작 작업을 가능하게 하고 더 견고한 실행을 초래
1. 순차적 정책 논리 (Sequential Policy Logic)
- 정의: 순차적 정책 논리는 작업을 여러 단계로 나누어 각 단계마다 고정된 규칙이나 프리미티브를 실행하는 방식
- 예시:
- "서랍을 열어라"라는 작업을 수행하기 위해
- 먼저 "서랍 손잡이를 잡기",
- 그 다음 "서랍을 당기기"와 같은 순서로 단계를 정의합니다.
- 각 단계는 독립적으로 실행됩니다.
- "서랍을 열어라"라는 작업을 수행하기 위해
2. 공동 최적화 방식 (Joint Optimization)
- 정의:
- 공동 최적화 방식은 전체 작업을 한 번에 최적화하여,
- 여러 제약 조건을 동시에 고려하면서 작업을 수행하는 방식
- 예시:
- "서랍을 열어라"라는 작업에서 "서랍 손잡이를 잡고" "당기는 동작"을 동시에 최적화하여, 가장 효율적인 궤적을 생성
- 작업 전체를 고려하여 한 번에 최적화
4.2. Generalization to Unseen Instructions and Attributes
-
시뮬레이션에서의 일반화를 연구
-
일반화에 대한 엄격한 정량적 평가를 제공하기 위해, 우리는 실제 로봇 설정을 반영하는 시뮬레이션된 블록-월드 환경을 설정했음
- 2766개의 고유 지시가 포함된 13개의 매우 무작위 작업을 특징으로 함
- 120: https://openaccess.thecvf.com/content_CVPR_2020/papers/Xiang_SAPIEN_A_SimulAted_Part-Based_Interactive_ENvironment_CVPR_2020_paper.pdf
- 121: https://openaccess.thecvf.com/content/ICCV2021/papers/Mo_Where2Act_From_Pixels_to_Actions_for_Articulated_3D_Objects_ICCV_2021_paper.pdf
-
각 작업은, 사전 정의된 목록에서 선택된 무작위 attribute을 포함하는 템플릿 지시(예: “객체 [obj]을/를 [pos]로 밀기”)를 포함
-
세부 사항은 부록 A.5에 있습니다.
-
"객체 [obj]을/를 [pos]로 밀기" 같은 지시가 프롬프트에 포함될 수 있습니다.(또는 supervised baseline의 학습 데이터에 나타날 수 있음).
- baseline 모델을 훈련시킬 때 사용하는 학습 데이터에도 동일한 지시와 속성이 포함될 수 있습니다.
- 예를 들어, "책을 책장으로 옮겨라"라는 지시가 학습 데이터에 포함되어 있다면, 모델이 이를 학습하고 수행 방법을 배우게 됩니다.
-
작업은 2개의 범주로 그룹화됩니다.
- "객체 상호작용"은 객체와의 상호작용이 필요한 작업이며,
- 예: 물체 집기, 서렵 열기, 물체 밀기
- "공간적 구성"은 특정 객체 근처에서 더 천천히 이동하는 등 공간적 제약이 포함된 작업
- "객체 상호작용"은 객체와의 상호작용이 필요한 작업이며,
-
baseline으로,
- 예: 장애물 회피, 정밀한 이동, 속도 제어
-
LLM은 어포던스와 제약 조건에 대해 명시적으로 추론함으로써 더 잘 일반화됩니다.
-
한편, 원시 프리미티브 매개변수를 직접 지정하는 것보다,
- 값 지도 구성을 통해 LLM 지식을 로봇 인식에 반영하는 것이 더 유연하고 더 나은 일반화를 제공
4.3. Efficient Dynamics Learning with Online Experiences
- VoxPoser가 더 어려운 작업의 효율적인 학습을 어떻게 가능하게 하는지 시연
- 우리는 시뮬레이션된 환경에서 문, 냉장고, 창문을 여는 것과 같은 접촉의 복잡성을 포함하는 작업에 대해 VoxPoser가 온라인 경험을 통해 어떻게 이점을 얻을 수 있는지 조사
- 구체적으로, 우리는 먼저 탐험의 prior로 작용하는,
- end-effector 웨이포인트 시퀀스로 표현된 k개의 제로샷 궤적을 VoxPoser를 사용하여 합성합니다
- (예: “문을 열기 위해 먼저 손잡이를 눌러야 한다”).
- 그런 다음, 에이전트가 데이터 수집과 모델 학습을 번갈아 가면서 반복적인 절차를 통해 MLP 동적 모델을 학습합니다.
- 여기서 말하는 모델:
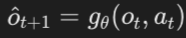
- 여기서 말하는 모델:

- 제로샷으로 합성된 궤적은 일반적으로 의미가 있지만 불충분합니다.
- 그러나 이러한 궤적을 탐험의 prior로 사용하여, 3분 이내의 온라인 상호작용을 통해 효과적인 동적 모델을 학습할 수 있으며, 이는 높은 최종 성공률로 이어집니다.
- 반면, 우선순위 없이 탐험하는 경우 모두 최대 12시간을 초과합니다.
4.4. Error Breakdown
- 이 섹션에서는 VoxPoser의 각 구성 요소에서 발생하는 오류를 분석하고, 전체 시스템을 어떻게 개선할 수 있는지 논의
- 우리는 시뮬레이터에서 실제 인식 및 동적 모델에 접근할 수 있는 시뮬레이션에서 실험을 수행
- "동적 오류"는 동적 모델에서 발생하는 오류를 의미
- 예: 로봇이 상자를 오른쪽으로 10cm 밀려고 하지만, 동적 모델이 상자의 마찰력이나 무게를 잘못 예측하여 상자가 5cm만 이동하게 되는 경우
- "인식 오류"는 인식 모듈에서 발생하는 오류를 의미
- 예: 로봇의 카메라가 컵을 테이블 왼쪽에 있다고 인식했지만, 실제로는 테이블 오른쪽에 있는 경우
- "명세 오류": 저수준 모션 플래너 또는 프리미티브에 대한 비용이나 매개변수를 지정하는 모듈에서 발생하는 오류를 의미
- 예: LLM에 의해 지정된 잘못된 값 지도
- 모션 플래너가 서랍 손잡이를 당기기 위해 너무 작은 힘을 지정하여, 로봇이 서랍을 충분히 당기지 못하고 서랍이 열리지 않는 경우.
- "동적 오류"는 동적 모델에서 발생하는 오류를 의미
- 그림 4에서 보이듯이, VoxPoser는 일반화 및 유연성 덕분에 가장 낮은 "명세 오류"를 달성합니다.
- 또한
더 견고한 인식 파이프라인과물리적으로 현실적인 동적 모델을 사용하는 것이 전체 성능 향상에 기여할 수 있음을 발견했습니다.
5. Conclusion, Limitations, & Future Works
- 이 연구에서는 일상적인 조작 작업을 위해 LLM 및 VLM에서 추출한 어포던스 및 제약 조건을 3D 지각 공간에 기반하여 일반적인 프레임워크인 VOXPOSER를 제시합니다.
- 이는 개방형 지시 및 객체에 대한 뛰어난 일반화 이점을 제공합니다.
- 설득력 있는 결과에도 불구하고, VoxPoser에는 몇 가지 한계가 있습니다.
- 첫째, 외부 인식 모듈에 의존하므로
전체적인 시각적 추론이나세밀한 객체 기하학의 이해가 필요한 작업에 제한적 - 둘째, 효율적인 동적 학습에 적용 가능하지만, 접촉이 많은 작업을 동일한 수준으로 일반화하려면 범용 동적 모델이 여전히 필요합니다.
- online 학습한 동적 모델은 특정 작업에 최적화되어 있을 수 있으며,
- 다양한 접촉이 포함된 작업에서는 일반화 능력이 부족할 수 있습니다.
- 범용 동적 모델이 필요하지만, 이를 구현하는 것은 여전히 도전 과제입니다.
- 셋째, 우리의 모션 플래너는 말단 효과기 궤적만 고려하지만 전체 팔 계획도 가능하며 더 나은 설계 선택이 될 가능성이 큽니다.
- 말단 효과기 궤적만 고려하면 팔 전체의 움직임을 최적화하지 못할 수 있으며, 복잡한 작업에서는 팔의 다른 부분이 장애물에 부딪힐 수 있습니다.
- 전체 팔 계획을 고려하면 더 나은 성능과 안전성을 제공할 수 있습니다.
- 마지막으로, LLM을 위한 수동 프롬프트 엔지니어링이 필요합니다.
- 첫째, 외부 인식 모듈에 의존하므로
- 우리는 또한 여러 흥미로운 미래 작업을 봅니다. 예를 들어,
- 최근의 다중 모달 LLM의 성공은 VoxPoser에 직접 시각적 기반을 제공하는 데 사용할 수 있습니다.
- 로봇이 "책상 위의 빨간 컵을 집어라"라는 명령을 받았을 때,
- 다중 모달 LLM은 카메라로 촬영한 책상 이미지를 분석하여 빨간 컵의 위치를 파악하고,
- 그 위치를 기반으로 로봇의 움직임을 계획할 수 있습니다.
- 정렬 및 프롬프트를 위한 개발된 방법은 프롬프트 엔지니어링 작업을 줄이는 데 사용될 수 있음
- 최근 연구에서는 자동화된 프롬프트 생성 및 정렬 방법이 개발되고 있습니다.
- 예를 들어, 사용자의 의도를 학습하여 자동으로 최적의 프롬프트를 생성하거나,
- 모델의 출력을 사용자의 기대와 맞추기 위해 정렬 알고리즘을 사용하는 방법
- 마지막으로, VoxPoser가 합성한 값 지도와 최적으로 상호작용하는 더 발전된 Trajectory Optimization 방법이 개발될 수 있습니다.
- 최근의 다중 모달 LLM의 성공은 VoxPoser에 직접 시각적 기반을 제공하는 데 사용할 수 있습니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.