
1. 논문 개요
- 가정 내 로봇이 다양한 물체를 조작하고 이동하는 문제를 다루고 있습니다.
- Open-Vocabulary Mobile Manipulation(OVMM)의 중요성:
- 이 개념은
이전에 본 적이 없는 환경에서 임의의 물체를 선택하고, 지정된 위치에 배치하는 로봇의 능력 - 로봇이 인간의 가정 환경에서 유용하게 사용되기 위해서는 인식, 언어 이해, 내비게이션, 조작 등 여러 가지 하위 문제를 해결해야 하며,
- 이 문제들을 통합하는 것이 매우 중요
- HomeRobot OVMM 벤치마크:
- 이 논문에서는
HomeRobot이라는 OVMM 벤치마크를 소개 - 이 벤치마크는 로봇이 가정 내 환경에서 물체를 선택하고 목표 위치로 이동시키는 작업을 시뮬레이션 및 실제 환경에서 수행할 수 있도록 함
- 실제와 시뮬레이션 환경:
- HomeRobot은 다양한 3D 장면에서 시뮬레이션을 수행하며,
- 또한 저렴한 로봇 플랫폼인
Hello Robot Stretch를 사용하여- 실제 환경에서도 실험을 수행할 수 있는 소프트웨어 스택을 제공
- 기본 정책 및 실험 결과:
- 논문에서는
강화 학습 기반 접근법과휴리스틱(모델 기반) 접근법을 구현하여- 시뮬레이션과 실제 환경에서 실험을 수행
- 실험 결과를 바탕으로 미래 연구 방향을 제시
3. Open-Vocabulary Mobile Manipulation
3.1 시뮬레이션 데이터셋

- Habitat Synthetic Scenes Dataset (HSSD) [19]
- 200개 이상의 인간이 작성한 3D 가정 장면으로 구성
- 18,000개 이상의 실제 세계 객체 3D 모델을 포함하고 있습니다.
- 대부분의 실제 주택처럼 이 장면들은 가구와 기타 물건들로 어수선하게 배치되어 있으며, 현실 세계와 유사하게 내비게이션 및 조작이 어렵습니다.
- 우리는 HSSD [19]의 하위 집합인 60개의 장면을 사용했으며,
- 이 장면들에는 재배치 지원을 위해 추가 메타데이터 및 시뮬레이션 구조가 작성되었습니다.
- 우리의 실험에서는 이들을 훈련, 검증 및 테스트 세트로 나누어 각각 38, 12, 10개의 장면으로 구성하였으며, 이는 원래 HSSD 논문 [19]의 분할을 따릅니다.
3.1.1. Objects and Receptacles.
- 우리는 AI2-Thor [59], Amazon-Berkeley Objects [60], Google Scanned Objects [61] 및 HSSD [19] 데이터셋에서 객체를 모아
- 다양한 실제 세계 로봇 문제의 대규모 데이터셋을 생성
- 총 2,535개의 객체를 129개의 카테고리로 주석을 달았으며,
- HSSD 데이터셋 [19]에 나타나는 21가지의 다른 Receptacles 카테고리를 식별
- 우리는 먼저 Receptacles 위의 안정적인 영역을 자동으로 레이블링한 다음,
- 잘못된 또는 접근할 수 없는 수용체를 제거하기 위해 이를 수동으로 정제하고 처리하여
- 최종 가구 Receptacles 객체 세트를 구성
- 또한, 객체 배치의 물리적으로 정확한 절차적 배치를 지원하기 위해 충돌 프록시 메시를 자동으로 생성하고, 많은 경우 수동으로 수정했습니다.
3.1.2. 에피소드 생성.
- Open-Vocabulary Mobile Manipulation의 경우, 이 작업은 특히 어려운데,
- 이는 객체를 내비게이션할 수 있고,
로봇이 접근할 수 있는 위치에 배치해야 하기 때문입니다. 로봇의 팔이 이 위치에 도달할 수 있으며, 내비게이션이 가능한, 접근 가능한 목표 수용체로 이동할 수 있어야 합니다.
- 이는 객체를 내비게이션할 수 있고,
- 전체 에피소드 생성 세부 사항은 App. D.2를 참조
3.1.3. 훈련 및 검증 분할.
- 훈련 에피소드는
- 관찰된 범주의 관찰된 인스턴스(SC,SI)에서 나온 객체들로 구성
- 대조적으로, 검증 및 테스트 에피소드는
- 관찰된 범주의 관찰되지 않은 인스턴스(SC,UI)와
- 관찰되지 않은 범주의 관찰되지 않은 인스턴스(UC,UI)를 사용
- 카테고리의 3분의 2는 무작위로 관찰된 것으로 지정되었으며, 관찰된 카테고리의 3분의 2는 무작위로 관찰된 인스턴스로 표시되었습니다.
- 분할은 Table 2에 있으며, 카테고리별 객체 분포는 App. Fig. 6에 나와 있습니다.
3.2 실제 세계 벤치마크
- 실험 아파트의 다양한 레이아웃 이미지는 Fig. 2에 포함되어 있으며, 작업 실행은 Fig. 16에 나와 있습니다.

4. The HomeRobot Library
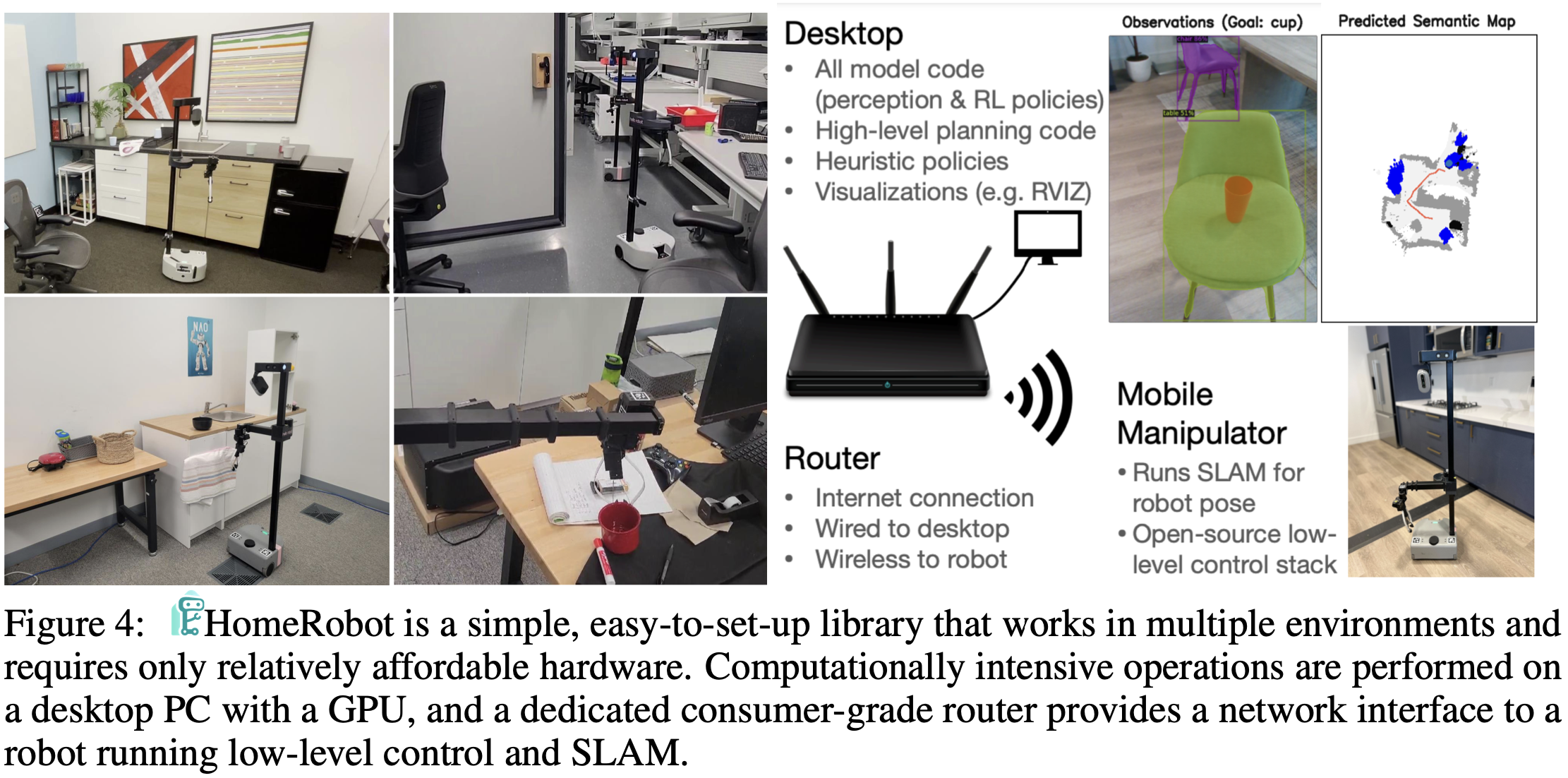
- Hello Robot(실험에서 쓴 로봇)의 Stretch [22]를 지원하는
- 내비게이션 및 조작 기능을 구현한 HomeRobot 라이브러리를 오픈소스로 공개
- 우리의 설정에서는 사용자가 모바일 조작기와 NVIDIA GPU가 장착된 워크스테이션에 접근할 수 있다고 가정
- mobile manipulator는
- 저수준 컨트롤러와 위치 추정 모듈을 실행하고,
- 데스크탑은
- 고수준 인식 및 계획 스택을 실행(그림 4).
- 로봇과 데스크탑은 상용 라우터를 사용하여 연결됩니다.
- 우리 스택의 주요 기능은 다음과 같습니다:
- 전이 가능성:
- 각 작업에 대해 시뮬레이션 및 실제 환경 간 통합된 상태 및 동작 공간을 제공하여
- 고수준 동작 공간(예: 미리 만들어진 잡기 정책) 또는 저수준 연속 관절 제어로 로봇을 쉽게 제어할 수 있습니다.
- 모듈성:
- 고수준 상태(예:
의미론적 지도,분할된 포인트 클라우드) 및 고수준 동작(예: 목표 위치로 이동, 목표 객체 집기)을 지원하는 인식 및 동작 구성 요소.
- 고수준 상태(예:
- 기본 에이전트:
- 이러한 기능을 사용하여 OVMM(개방형 어휘 모바일 조작) 기본 기능을 제공하는 정책.
- 전이 가능성:
4.1 기본 에이전트 구현
- 중요하게도, 우리는 연구자들이 개방형 어휘 모바일 조작 과제를 효과적으로 탐구할 수 있도록 하는 baseline과 tool을 제공
- HomeRobot에는 두 가지 유형의 기준선이 포함되어 있습니다:
- 모션 플래닝 [2] 및
단순 규칙을 사용한 manipulation을 사용하는 휴리스틱 기준선 - 강화 학습 기준선
- 모션 플래닝 [2] 및
- 또한,
객체 목표 내비게이션[1, 2],스킬 학습[24],연속 학습[25],이미지 인스턴스 내비게이션[26]과 같은- 다양한 기능을 테스트하는 최근 발표된 논문의 예제 프로젝트를 구현
- 우리는 일련의 스킬을 순차적으로 호출하는 고수준 정책인 OVMMAgent를 구현했습니다. 이 스킬들은 다음과 같습니다:
- FindObj/FindRec:
- 시작 수용체에서 객체를 찾거나 목표 수용체를 찾습니다.
- Gaze:
- 객체를 잡을 수 있을 만큼 충분히 가까이 이동하고, 객체를 잘 볼 수 있도록 머리를 방향 조정합니다.
- Gaze 동작의 목표는 잡기 성공률을 높이는 것입니다.
- Pick:
- 객체를 집습니다. 우리는 Habitat에서 그리퍼 상호작용을 시뮬레이션하지 않기 때문에, 이를 위한 고수준 동작을 제공합니다.
- 그러나 우리의 라이브러리는 다양한 학습된 잡기 스킬과 호환되며 잡기 정책 학습을 지원합니다.
- Place:
- 환경에서 위치로 이동하고 객체를 목표 수용체 위에 놓습니다.
- 구체적으로, OVMMAgent는
FindObj, Gaze, Pick, FindRec, Place를 그 순서대로 호출하는 state machine로,- Pick은 실제 로봇 라이브러리에서 제공하는 잡기 정책
- 다른 스킬들은 아래에 제시된 접근 방식을 사용하여 생성
- 휴리스틱:
- 우리는 기존의 학습된 모델과 휴리스틱만을 사용한 버전을 구현하며,
- 모바일 조작에서 이러한 모델이 큰 효과를 발휘한 이전 작업(e.g. [62])을 참고
- 여기서 DETIC [63]은
- 각 스킬에 적합한 개방형 어휘 객체 세트를 위한 마스크를 제공
- 각 에피소드에 대해 시작 수용체, 객체, 목표 수용체가 주어집니다.
- 그림 16은 실제 환경에서 휴리스틱 내비게이션 및 배치 정책이 실행되는 예시를 보여줍니다(App. E).
- 강화 학습(RL):
- 우리는 Habitat [21]의 수정된 버전에서 DDPPO [64]를 사용하여
- 깊이, 진실된 의미론적 분할 및 고유 수용성 센서(즉, 관절, 그리퍼 상태)를 제공받아 동작을 예측하는 정책으로 네 가지 스킬을 훈련시켰습니다.
- 시뮬레이션에서 RGB가 제공되지만, 우리의 기준선 정책은 이를 직접적으로 사용하지 않으며,
- 대신 테스트 시 Detic [27]의 예측된 분할에 의존
- 우리는 Habitat [21]의 수정된 버전에서 DDPPO [64]를 사용하여

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.