- https://openaccess.thecvf.com/content/CVPR2023/papers/Peng_OpenScene_3D_Scene_Understanding_With_Open_Vocabularies_CVPR_2023_paper.pdf
- https://github.com/pengsongyou/openscene
1. 논문 개요
- CLIP을 활용하여
3D 포인트와텍스트및이미지 픽셀을 공동 임베딩(co-embedding)하는 방식- 새로운 종류의 질의에 대해 효과적으로 응답할 수 있는 모델을 제공
레이블이 없는 3D 데이터로 작업하는 데 중점을 둔 내용
1.1. 논문의 주요 내용
-
- 기존 3D 장면 이해 방법의 한계:
- 기존의 3D 장면 이해 접근법은
레이블이 있는 3D 데이터셋에 의존하여 특정 과제를 수행하도록 학습 - 그러나 이러한 방법은 학습된 데이터셋에 제한적이며, 새로운 과제나 드문 객체에 대한 이해가 어려움
-
- OpenScene의 제안:
- OpenScene은 레이블이 없는 데이터로부터
CLIP 피처 공간에서 3D 포인트를 공동 임베딩하여 3D 장면을 이해하는 제로샷(zero-shot) 방법을 제안
- 이를 통해 사용자는 텍스트 질의를 통해 3D 장면에서 원하는 객체나 특징을 검색하고 시각화할 수 있음
-
- 모델 구조:
- 이 모델은 다중 뷰(fusion)와 3D 컨볼루션을 결합하여 3D 포인트의 밀집 피처를 추출하고, 이를 기반으로 다양한 질의에 응답할 수 있음
- 예를 들어, 'soft'와 같은 단어로 3D 장면에서 소파나 침대와 같은 부드러운 표면을 찾을 수 있습니다.
2. 그림들
2.1. Fig 1.
-

-
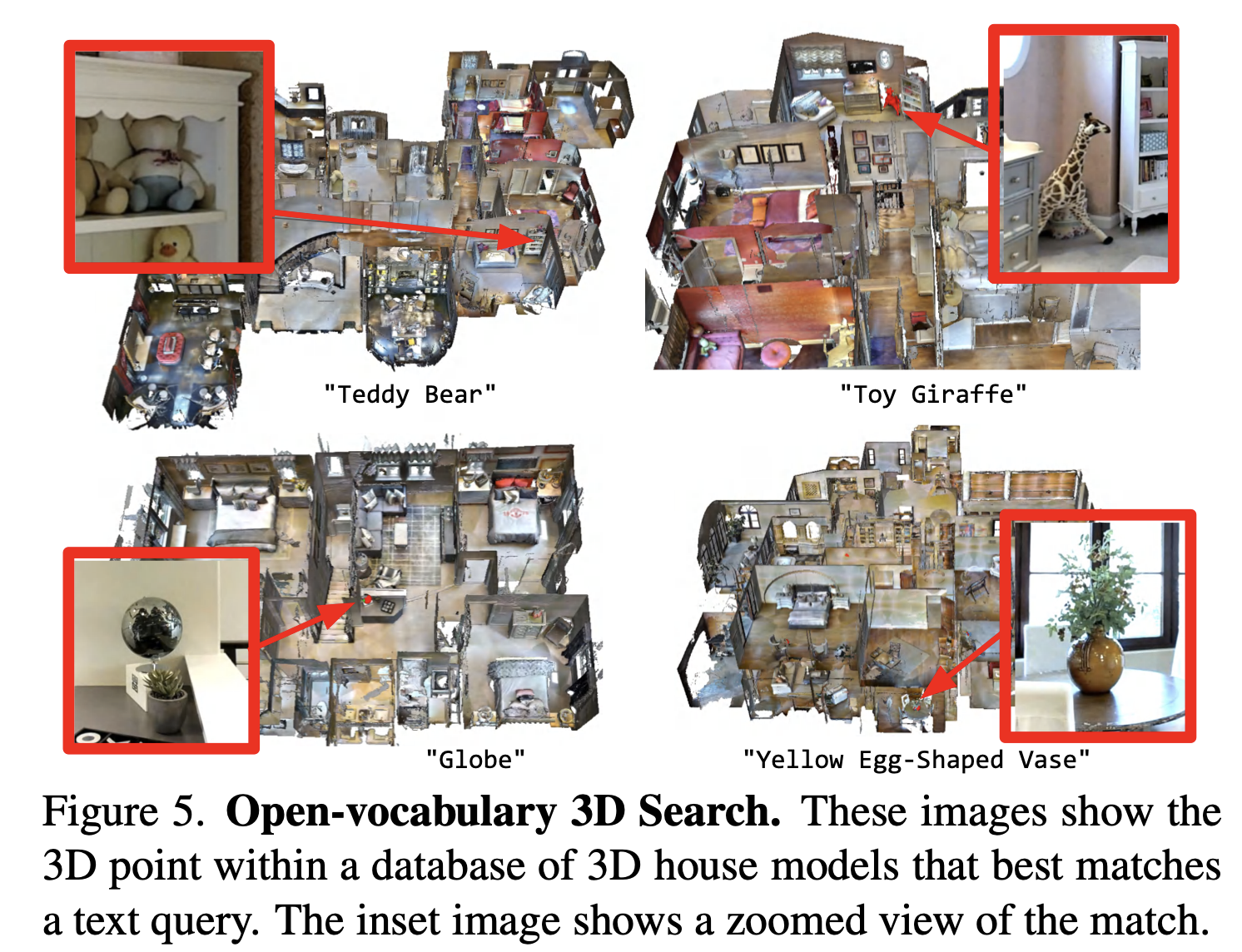
-
OpenScene은 언어 기반의 특징을 사용하기 때문에,
- "부드러운", "주방", 또는 "작업"과 같은 예제 쿼리에 대해 라벨이 없는 3D 데이터로도 다양한 질문에 답할 수 있습니다.
-
사용 예
- 금속 재질이나, 유리 등을 판별하는데 쓸 수 있을수도 있다.
- 특정 공간을 찾을 수 있다. (주방, 업무 공간 등)
2.2. Fig 2.
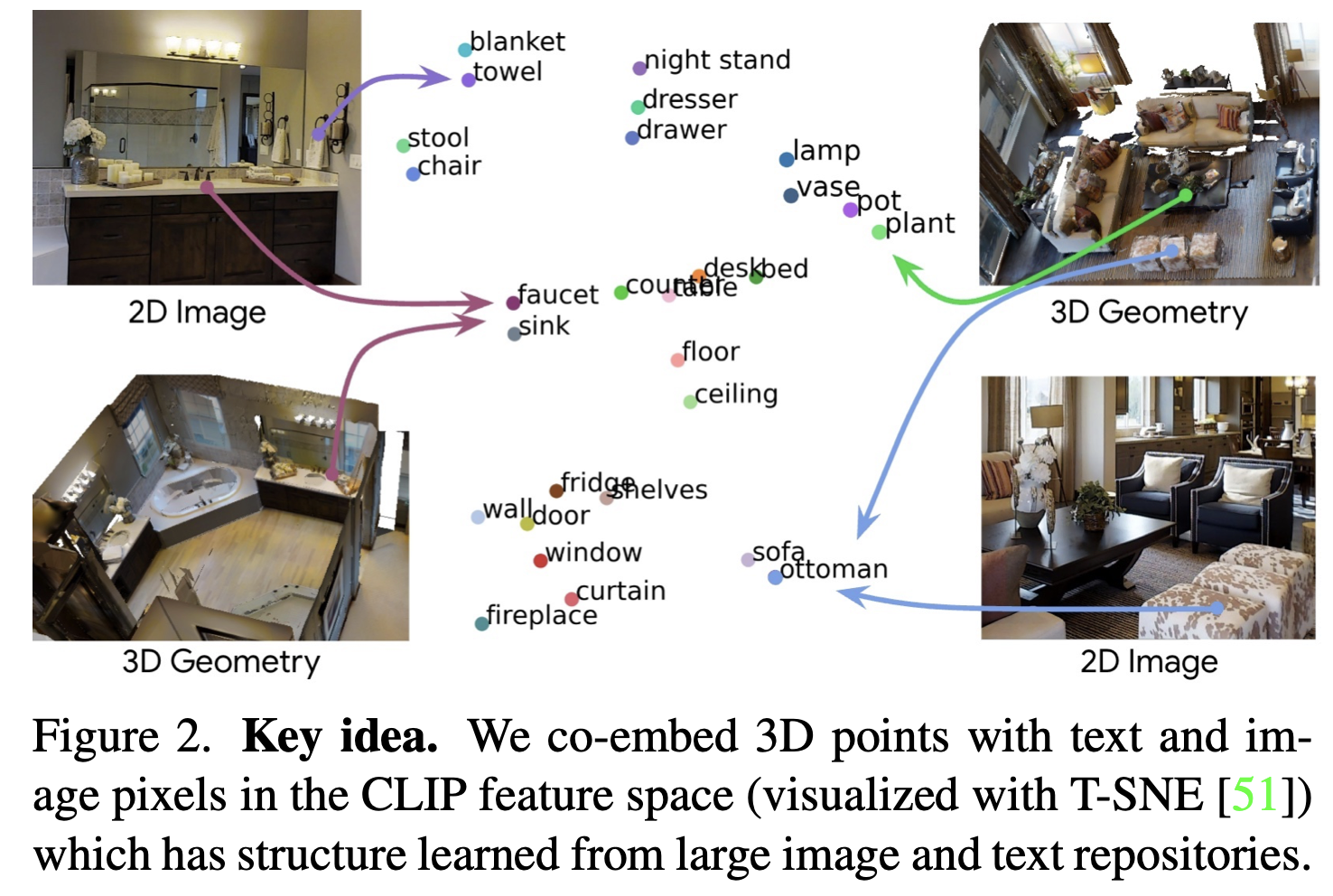
- OpenScene 모델은
3D 포인트와 이3D 포인트에 대응되는 이미지의 픽셀 정보, 그리고해당 픽셀에 대응하는 텍스트 레이블(예: "chair")을 CLIP 모델의 피처 공간에 임베딩 - T-SNE라는 기술을 사용해,
- CLIP 피처 공간에서 임베딩된 3D 포인트, 이미지 픽셀, 그리고 텍스트를 시각화했다는 뜻
- T-SNE (t-distributed Stochastic Neighbor Embedding)
- 고차원의 데이터를 저차원으로 변환해 시각화하는 데 사용되는 기법
- 고차원 데이터의 구조를 2D 또는 3D 공간에서 시각적으로 이해하기 쉽게 만드는 데 사용
2.3. Fig 3.
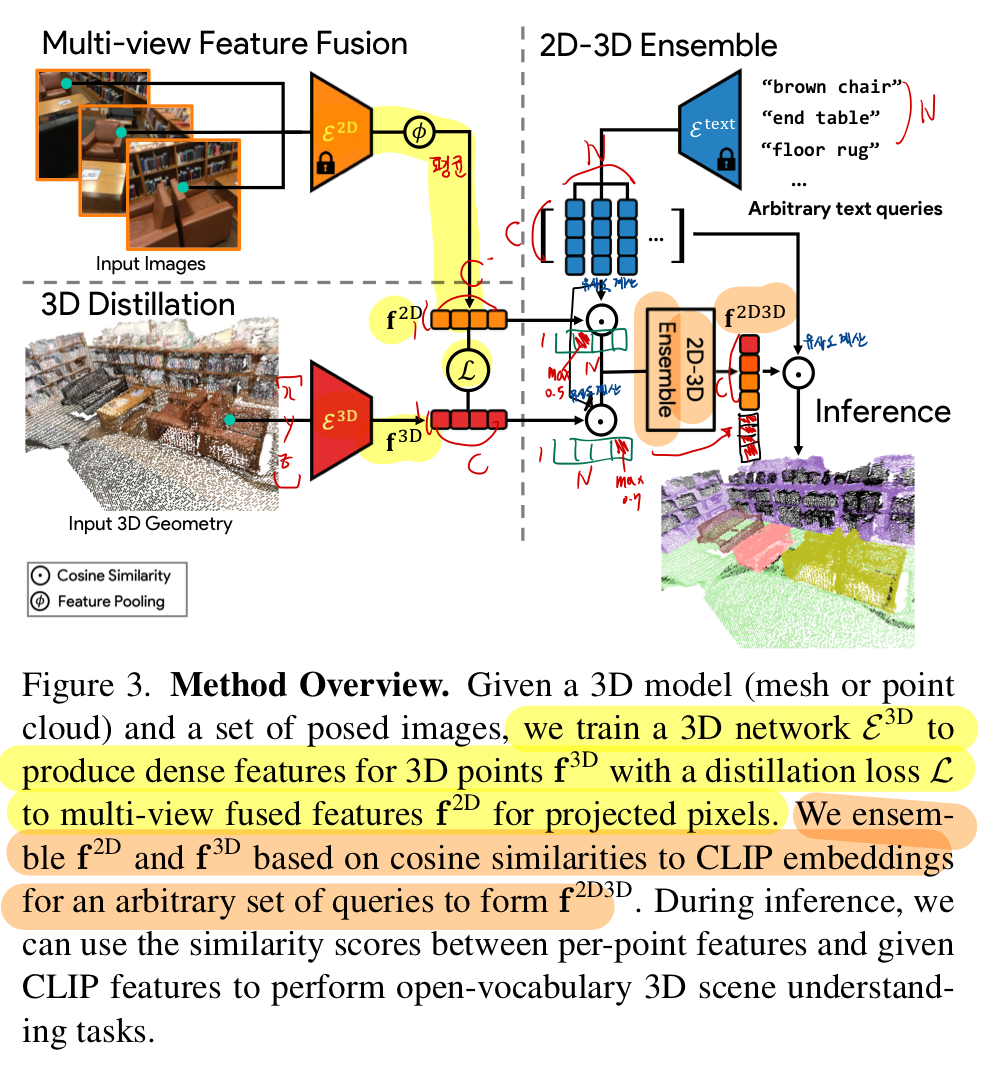
3.1. Image Feature Extraction (이미지 피처 추출):
- 입력된 이미지는 OpenSeg 또는 LSeg와 같은 사전 훈련된 2D 비전-언어 모델을 사용하여 각 픽셀의 임베딩을 계산
- Multi-view Feature Fusion (다중 뷰 피처 융합):
- 3D 포인트 클라우드의 각 포인트는 여러 이미지의 픽셀들과 연결
- 이 단계에서는 3D 포인트가 여러 이미지에서 어떻게 나타나는지 정보를 통합하여
2D 이미지 임베딩의 평균 값을 사용해 단일 3D 포인트 피처를 생성
3.2. 3D Distillation (3D 디스틸레이션):
- 이미지에서 생성된 피처를 3D 포인트 네트워크에 전달하여 3D 포인트 클라우드만을 입력으로 받아 동일한 피처를 생성하도록 학습
- 여기서 중요한 것은, 이 3D 네트워크는 오직 3D 포인트만을 이용해 훈련된다는 점
- 클립 기반 이미지 피처와의 차이를 최소화(코사인 유사도 손실 함수)하도록 훈련
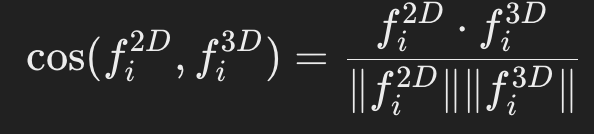
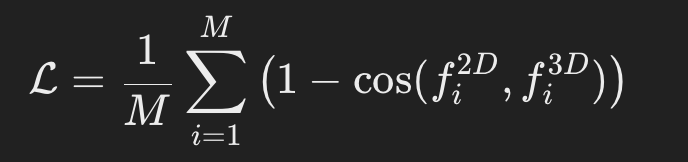
3.3. 2D-3D Feature Ensemble (2D-3D 피처 앙상블):
- 2D 이미지로부터 추출된 피처와 3D 포인트 네트워크에서 생성된 피처를 결합하여 최종 피처를 만듭니다.
- 이 앙상블 방법은 2D 피처와 3D 피처 각각의 강점을 최대한 활용할 수 있게 해줍니다.
- 예를 들어, 2D 피처는 작은 객체나 복잡한 표면을 잘 인식할 수 있고, 3D 피처는 공간적 구조를 잘 인식합니다.

3.4. Inference (추론):
- 최종 피처를 활용해 사용자가 입력한 텍스트 질의와 각 3D 포인트의 피처 간의 유사도를 계산하여 장면 이해 작업을 수행
- 예를 들어, "의자"라는 텍스트 질의에 대해 장면 내에서 의자와 유사한 피처를 가진 3D 포인트들을 찾아내는 방식입니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.