RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
foundation model in robotics
목록 보기
13/14
1. 개요
- 로봇공학에서의 새로운 transformer 모델인 Robotics Transformer 2(RT2)에 대해 설명하고 있습니다.
- RT2는
로봇의 다양한 작업 수행 능력을 향상시키기 위해 설계되었으며, 특히동적 환경에서의 인식과 조작 기능을 중점적으로 다룹니다. - 더 빠르고 정확하게 로봇이 환경을 인식하고 적응할 수 있게 돕습니다.
- RT-2가 인터넷 규모의 학습을 통해 다양한 새로운 능력을 획득할 수 있음을 보여줍니다.
- 새로운 물체에 대한 일반화 능력의 상당한 향상,
- 로봇 학습 데이터에 존재하지 않는 명령(예: 물체를 특정 숫자나 아이콘 위에 놓기)을 해석하는 능력,
- 사용자 명령에 대한 기본적인 추론을 수행하는 능력(예: 가장 작은 또는 가장 큰 물체를 집거나 다른 물체와 가장 가까운 물체를 집기)
- 또한, 체인 오브 소트(Chain of Thought) 추론을 통합하면 RT-2가 다단계 의미 추론을 수행할 수 있게 되며,
- 예를 들어
- 즉석에서 망치로 사용할 물체(돌)를 선택하거나
- 피로한 사람에게 가장 적합한 음료(에너지 드링크)를 선택하는 등의 작업을 수행
- 예를 들어
2. 그림들
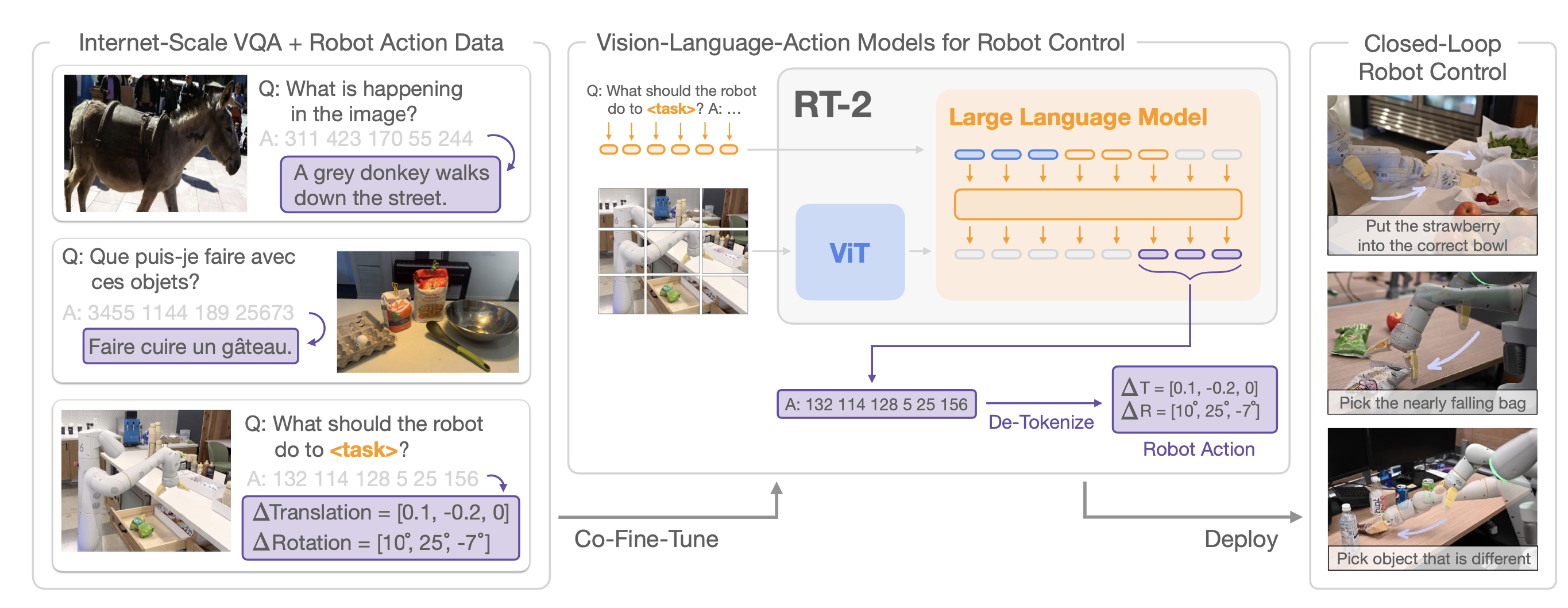
- RT-2는 비전-언어 모델(VLM)을 로봇 제어에 통합하여, 로봇이 인터넷에서 학습한 언어적/시각적 지식을 활용할 수 있도록 설계되었습니다.
- RT-2는 이미 대규모 인터넷 데이터를 통해 학습된 비전-언어 모델을 활용
- RT-2 모델은
로봇의 action 데이터를 웹에서 학습한 비전-언어 데이터와 함께 공동 fine-tuning 함
- 이 모델은 로봇의 action을 텍스트 토큰으로 표현하여, 일반적인 언어와 같은 형식으로 학습하고 예측할 수 있도록 합니다.
- 로봇 행동의 텍스트화:
- 예를 들어,
로봇이 특정 물체를 집어 올리거나특정 위치에 물체를 놓는 행동을 텍스트 토큰으로 표현
- 예를 들어,
- 출력 제약 조건:
- RT-2 모델은 로봇 제어 작업을 위해
특정 유효한 액션 토큰만을 출력하도록 제한 - 이 제약은 모델이 로봇 제어 작업을 수행할 때 정확하고 안전한 행동을 하도록 보장
- RT-2 모델은 로봇 제어 작업을 위해
- 추론 중에는 텍스트 토큰이 로봇 동작으로 디토큰화되어 closed loop control을 가능하게 합니다.
2.1. 로봇의 action을 텍스트 토큰으로 표현
- 기존의 로봇 제어 시스템에서는 로봇의 행동이 일반적으로
연속적인 실수 값으로 표현- 예를 들어, 로봇 팔의 위치는 3차원 공간에서의 좌표 (x, y, z)와 회전 각도 (yaw, pitch, roll) 등으로 표현되며, 이는 보통 수치적으로 제어됩니다.
- 그러나 이러한 방식은 자연어 처리(NLP) 모델이나 비전-언어 모델과의 직접적인 통합이 어렵습니다.
- 왜냐하면 NLP 모델은 언어를 처리하는 데 최적화되어 있으며, 일반적으로 텍스트(토큰)로 데이터를 주고받기 때문입니다.
2.1.1. 로봇 행동의 이산화와 텍스트 토큰화
- 이 문제를 해결하기 위해 RT-2 모델은 로봇의 연속적인 행동을 이산화(discretization) 합니다.
- 이는 연속적인 실수 값을 유한한 수의 구간으로 나누어 이산화된 값으로 변환하는 과정을 의미
- 예를 들어, 로봇 팔의 x축 방향 이동을 0에서 1 사이의 값으로 표현한다고 가정합시다.
- 이 값을 256개의 구간으로 나누어 각 구간을 0에서 255 사이의 정수로 표현할 수 있습니다.
- 이렇게 이산화된 값들은 각각 하나의 고유한 텍스트 토큰으로 대응됩니다.
- 예를 들어:
- 로봇 팔의 x축 이동이 0.75인 경우, 이 값은 192로 이산화됩니다(256개의 구간 중 75%에 해당).
- 이 192라는 정수 값은 NLP 모델에서 사용할 수 있는 특정 텍스트 토큰, 예를 들어 "token_192"로 변환됩니다.
2.2.2. 로봇 행동의 텍스트 토큰 표현
- 이산화 과정을 거쳐 변환된 로봇의 모든 동작(예:
x, y, z 위치, 회전 각도, 그리퍼의 개폐 상태등)은 각각 고유한 텍스트 토큰 시퀀스로 변환됩니다. - 이런 방식으로 표현된 로봇 행동은 마치 자연어 문장처럼 텍스트로 이루어진 시퀀스가 됩니다.
- 예를 들어:
- 로봇이 물체를 집어 올리는 행동을 표현할 때, 이 행동은 여러 개의 텍스트 토큰(예: "pick_token_x", "pick_token_y", "pick_token_z", "rotate_token_yaw" 등)으로 이루어진 문장으로 표현됩니다.
2.2.3. 구체적 예시
- RT-2 모델이 학습하는 과정에서, "로봇이 컵을 책상 위에 올려놓아라"라는 명령을 받았다고 가정합시다.
- 이 명령은 비전-언어 모델에서 텍스트로 표현됩니다.
- 이때 모델은 학습된 내용을 바탕으로 해당 명령을 수행하기 위해 필요한 로봇의 연속적인 동작을 예측하게 됩니다.
- 각 동작은 이산화된 후에 텍스트 토큰으로 변환되어 로봇이 이를 기반으로 동작을 수행하게 됩니다.
- 예를 들어:
- 명령: "책상 위에 컵을 올려놓아라"
- 예측된 동작: "move_to_token_x", "move_to_token_y", "move_to_token_z", "grip_open_token", "place_token" 등
- 이러한 동작들은 최종적으로 로봇이 수행할 수 있는 저수준의 제어 명령으로 변환됩니다.
- 이 과정을 통해 RT-2 모델은 로봇 행동을 언어화하여 비전-언어 모델이 쉽게 이해하고 예측할 수 있는 형태로 만들며, 이를 통해 더 정교하고 일반화된 로봇 제어가 가능해집니다.
2.3. 출력 제약 조건
2.3.1. 출력 제약 조건(Output Constraint)의 필요성
- 예를 들어, 로봇이 물체를 집는 작업을 수행하는 중에 잘못된 위치로 이동하거나 잘못된 동작을 수행하면, 물체를 떨어뜨리거나 주변 환경을 손상시킬 수 있습니다.
- 따라서 RT-2 모델은 특정한
유효한 액션 토큰만을 출력할 수 있도록 제약을 가하여, 이러한 위험을 최소화합니다.
2.3.2. 출력 제약 조건의 구현
2.3.2.a. 유효한 액션 토큰의 정의
- 유효한 액션 토큰은 로봇이 수행할 수 있는 모든 가능한 동작을 나타내는 토큰의 집합
- 예를 들어, 로봇 팔의 움직임은 특정한 좌표 범위 내에서만 이루어질 수 있으며, 그리퍼(gripper)는 닫힘 또는 열림 상태만 가질 수 있습니다.
- 이러한 모든 가능한 동작을 미리 정의하여, 로봇이 실제로 수행할 수 있는 행동만이 텍스트 토큰으로 표현되도록 합니다.
2.3.2.b. 출력 제약 적용
- 모델이 학습되고 추론할 때, 생성된 텍스트 토큰이 유효한 액션 토큰 집합 내에 있는지 검증합니다.
- 만약 유효하지 않은 토큰이 생성되려고 하면, 이 토큰이 생성되지 않도록 제약을 가합니다.
- 예를 들어, 그리퍼의 움직임을 나타내는 토큰이 "닫기" 또는 "열기" 외의 다른 값을 가질 수 없도록 하는 것입니다.
2.3.3. 기술적 구현 예시
- 기술적으로, 이 제약은 디코딩(decoding) 단계에서 적용
- 디코딩 단계에서 모델은 연속적인 토큰을 생성하는데, 이 과정에서 유효한 토큰 집합 내의 토큰만을 선택하도록 알고리즘이 설계됩니다.
- 이를 위해 일반적으로
- 빔 서치(beam search),
- 탑-k 샘플링(top-k sampling), 또는
- 탑-p 샘플링(top-p sampling)과 같은 기법들이 사용됩니다.
- 이 기법들은 모델이 가장 가능성이 높은 토큰을 선택하도록 유도하며, 이때 유효하지 않은 토큰이 선택되지 않도록 제한을 가합니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.