지금은? AI 전성시대!
1.Colab과 Jupyter Notebook

1. Google Colab 1) 필요성 구글 Colab은 웹 브라우저에서 파이썬 프로그램을 실행 밎 저장할 수 있는 무료 서비스로, Jupyter 노트북의 개발환경이 된다. 쉽게 말해, Colab은 코드를 실행하기 위한 브라우저 상의 Editor인 셈이다. 물론,
2.Binary Classification
머신러닝에서 여러 가지 Class(종류) 중 하나를 구별해 내는 과정을 분류라고 부른다. 특히 그 중에서도 2개의 종류 중 하나를 고르는 기초적인 분류를 이진 분류라고 한다. 이번 포스팅에서는 도미와 빙어를 구분하는 이진 분류 모델을 만들어볼 것이다.도미와 빙어를 구분
3.Training Set과 Test Set
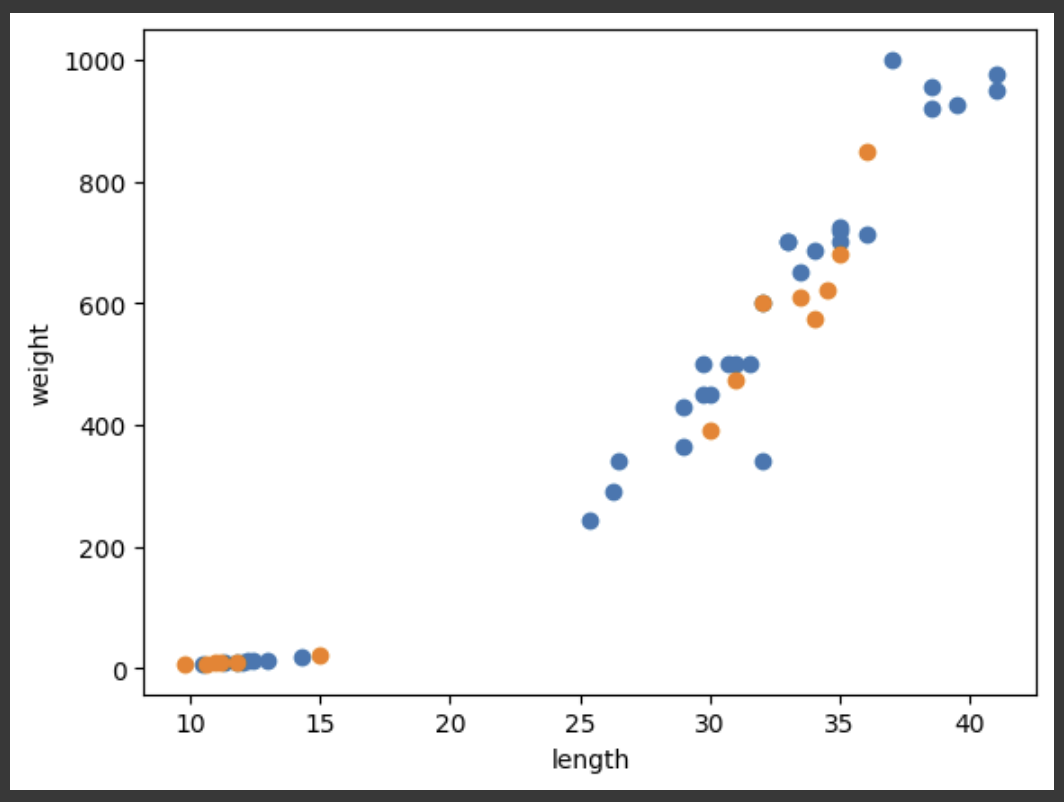
머신 러닝 알고리즘은 크게 지도학습과 비지도학습으로 구분된다.① 지도학습훈련을 위한 데이터 Set이 필요하며, 이를 훈련 데이터라고 부른다.훈련 데이터는 특성 데이터 Set과 정답 데이터 Set으로 구분되는데, 이를 각각 Input과 Target이라 부른다.이전 시간에
4.Data Preprocessing
이전 포스팅에서는 zip() 메서드와 List Comprehension을 이용하여, 생선의 length와 weight를 하나의 리스트로 병합하였다. 그러나 지금부터는 Numpy의 column_stack 메서드를 이용하여 Features 데이터를 통합할 것이다. 주의해야
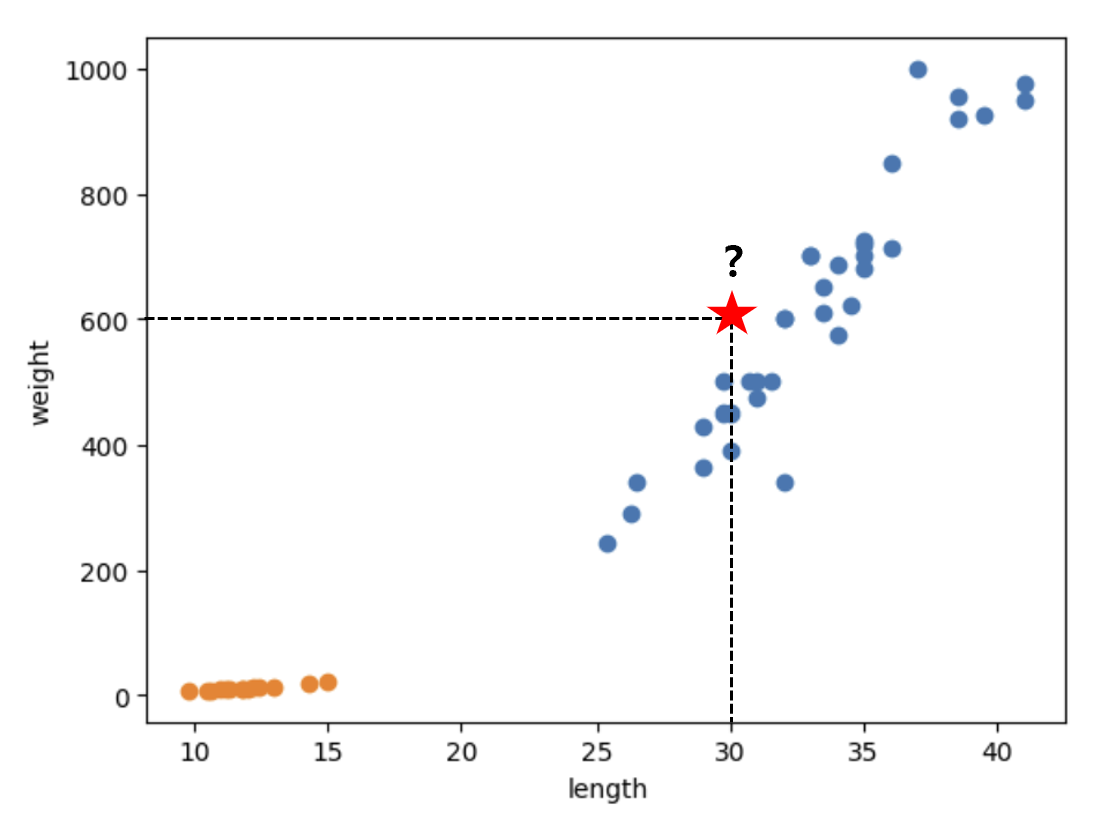
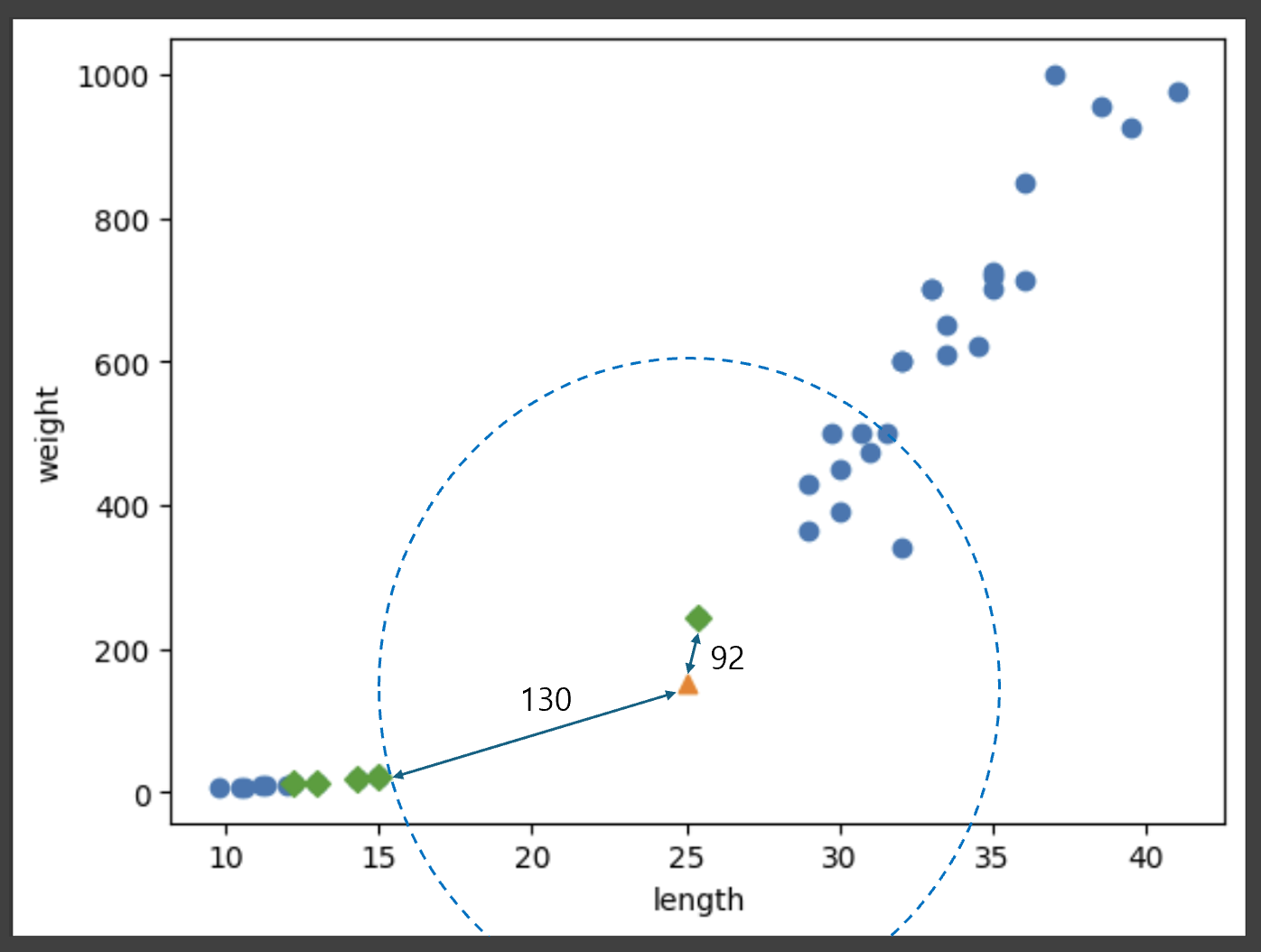
5.K-Nearest Neighbors Regression
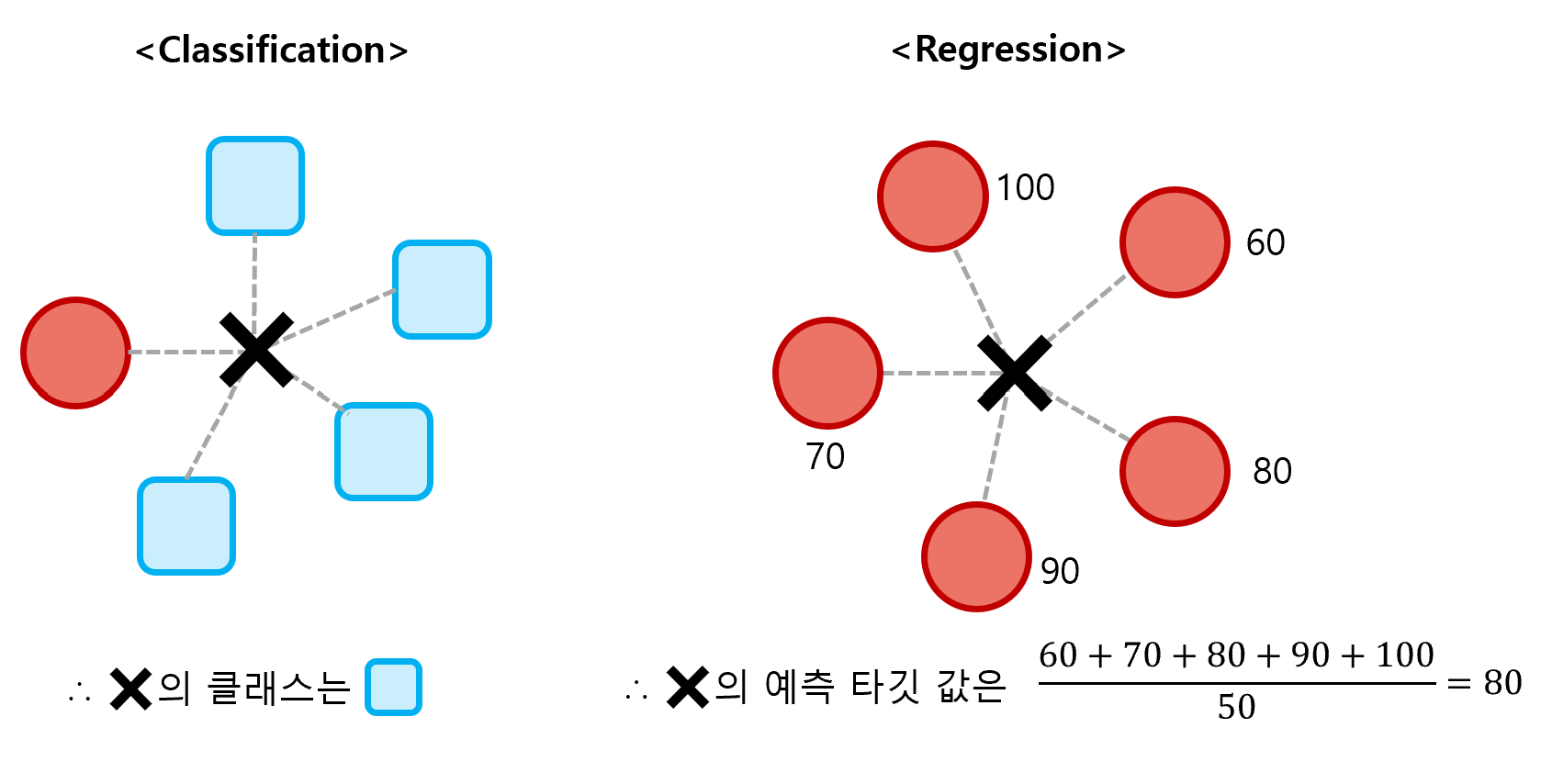
1. 회귀 머신 러닝 알고리즘은 지도학습과 비지도학습, 강화학습으로 나뉜다. 또한, 지도학습은 다시 Calssification(분류)과 Regression(회귀)으로 나뉜다. 여기서 회귀란, 여러 개의 독립 변수가 종속 변수에 미치는 영향을 분석하여 특정 수치를 예측하
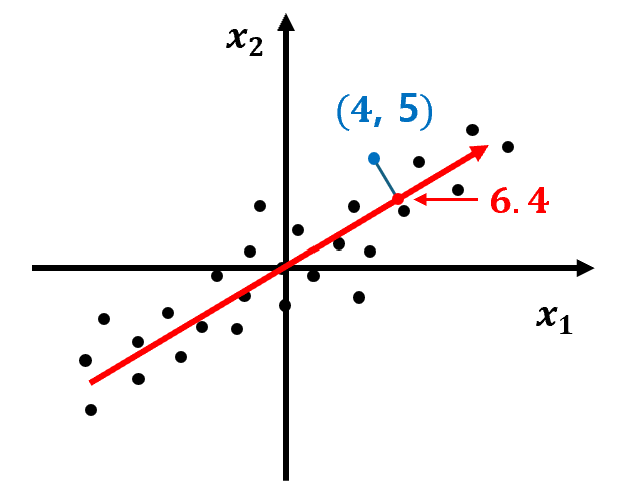
6.Linear Regression
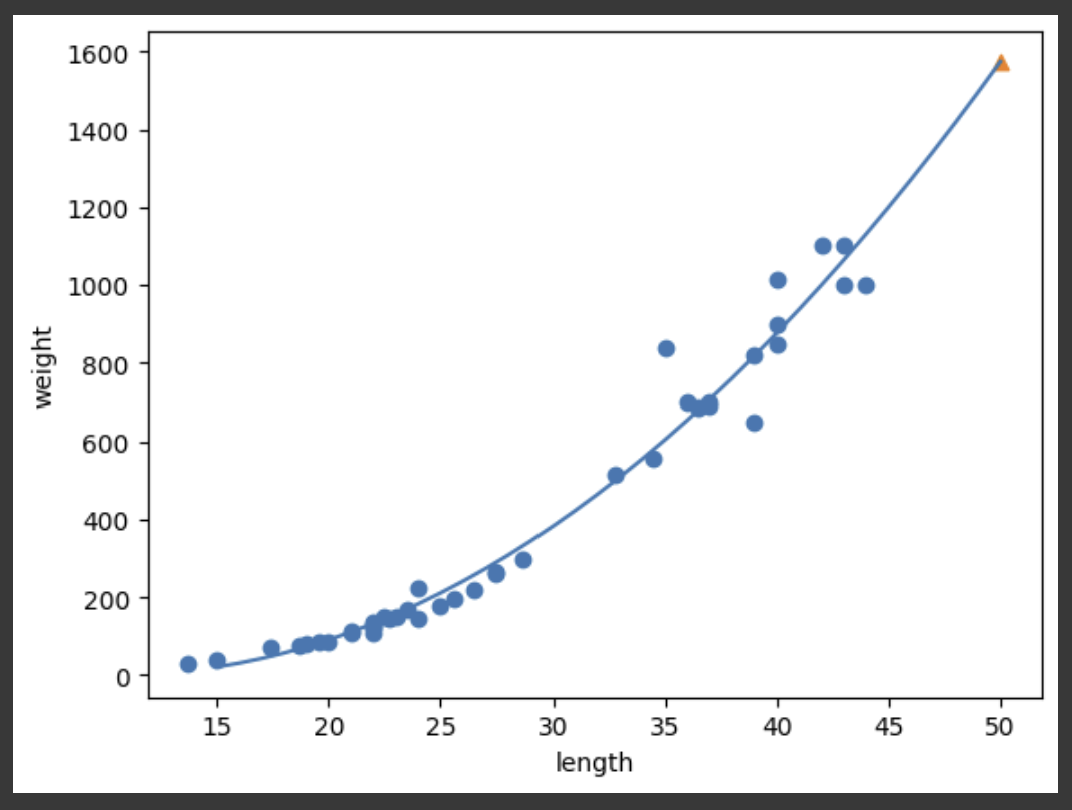
1. KNN 회귀 분석의 한계 지난 시간에 만든 KNN 회귀 모델을 이용하여 길이가 50cm인 농어의 무게를 예측해보자. KNN 회귀 모델은 50cm 농어의 무게를 약 1033g으로 예측하였다. 과연 이 예측이 충분히 합리적일까? 이 모델이 어떠한 근거로 1033g이
7.Multiple Regression과 Regularization
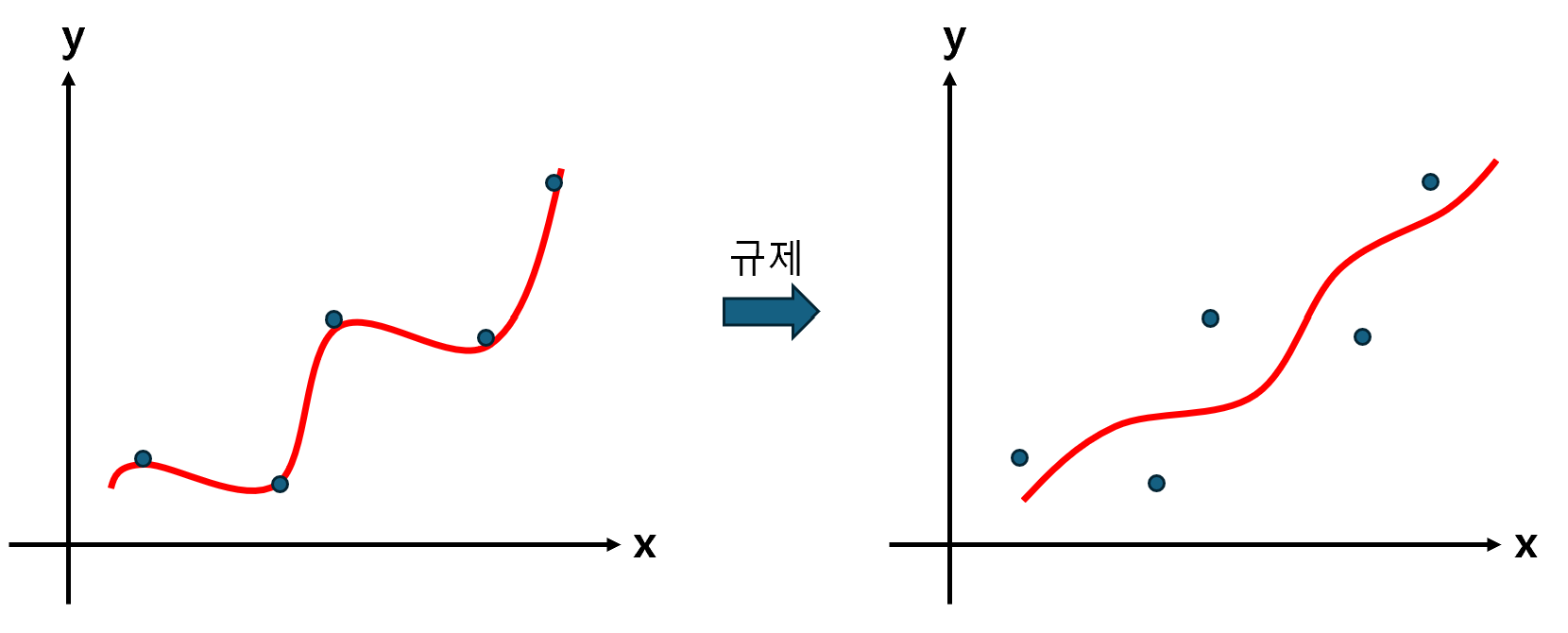
1. 선형 회귀 모델의 과대 적합 및 과소 적합 해결하기 1) 아이디어 지난 포스팅에서 설계한 다항 선형 회귀 모델의 과소 적합 문제를 해결해보자. 문제를 해결하려면 과대 적합과 과소 적합이 왜 발생하는지부터 명확히 알아야 한다. 먼저 과대 적합은, 모델이 훈련 Se
8.Logistic Regression
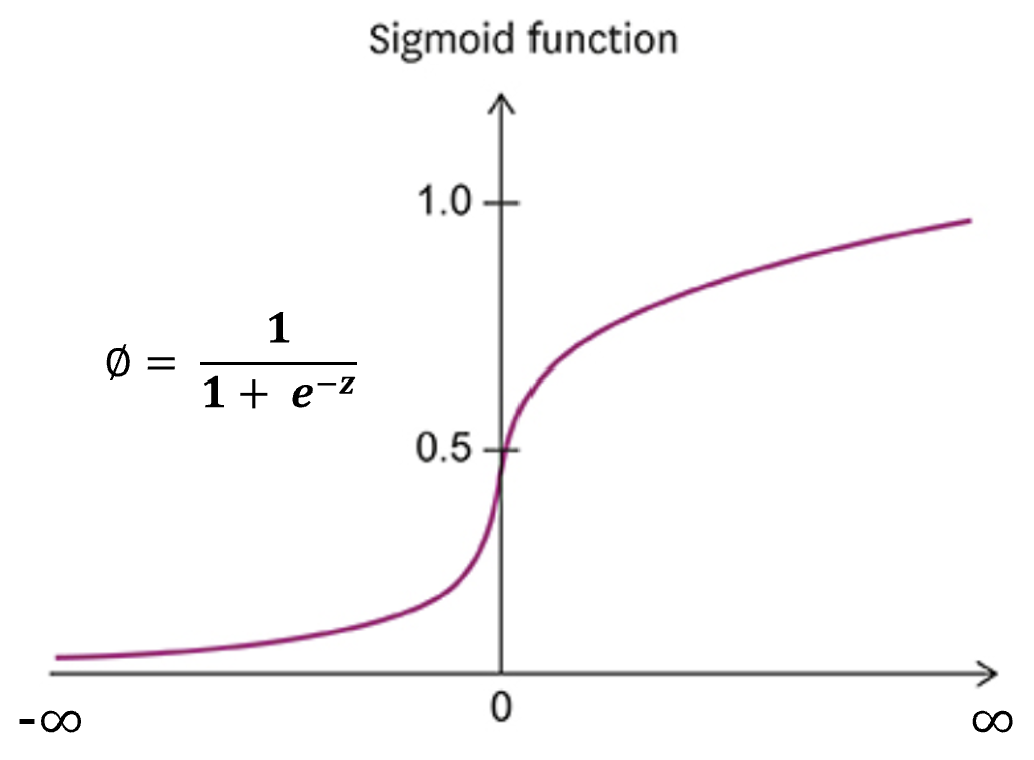
타깃 데이터에 3개 이상의 클래스가 포함되어 있는 분류 문제를 Multi-Class Classification(다중 분류)이라고 한다. 사실 다중 분류라 할지라도, 지난 포스팅에서 배운 이진 분류와 크게 다르지 않기 때문에 바로 관련 문제를 풀어보기로 하겠다.랜덤 박스
9.Stochastic Gradient Descent
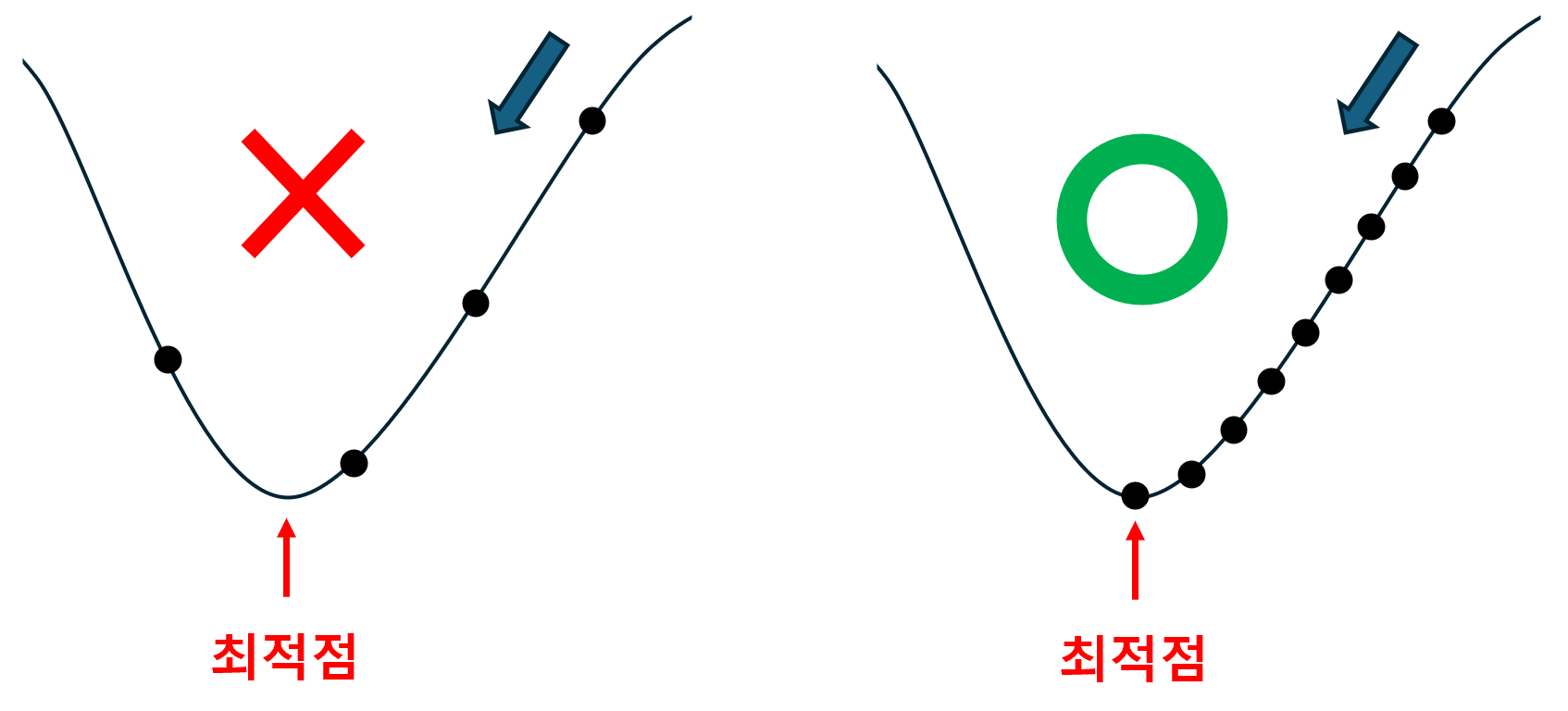
1. Stochastic Gradient Descent 1) 필요성 지금까지는 데이터 Set이 이미 충분히 모였다고 가정한 후에, 실습을 진행하였다. 그러나, 현실에서는 아직 데이터가 충분히 준비되지 않은 상황이 발생할 가능성이 있다. 만약 데이터가 충분히 준비될 때까
10.Decision Tree
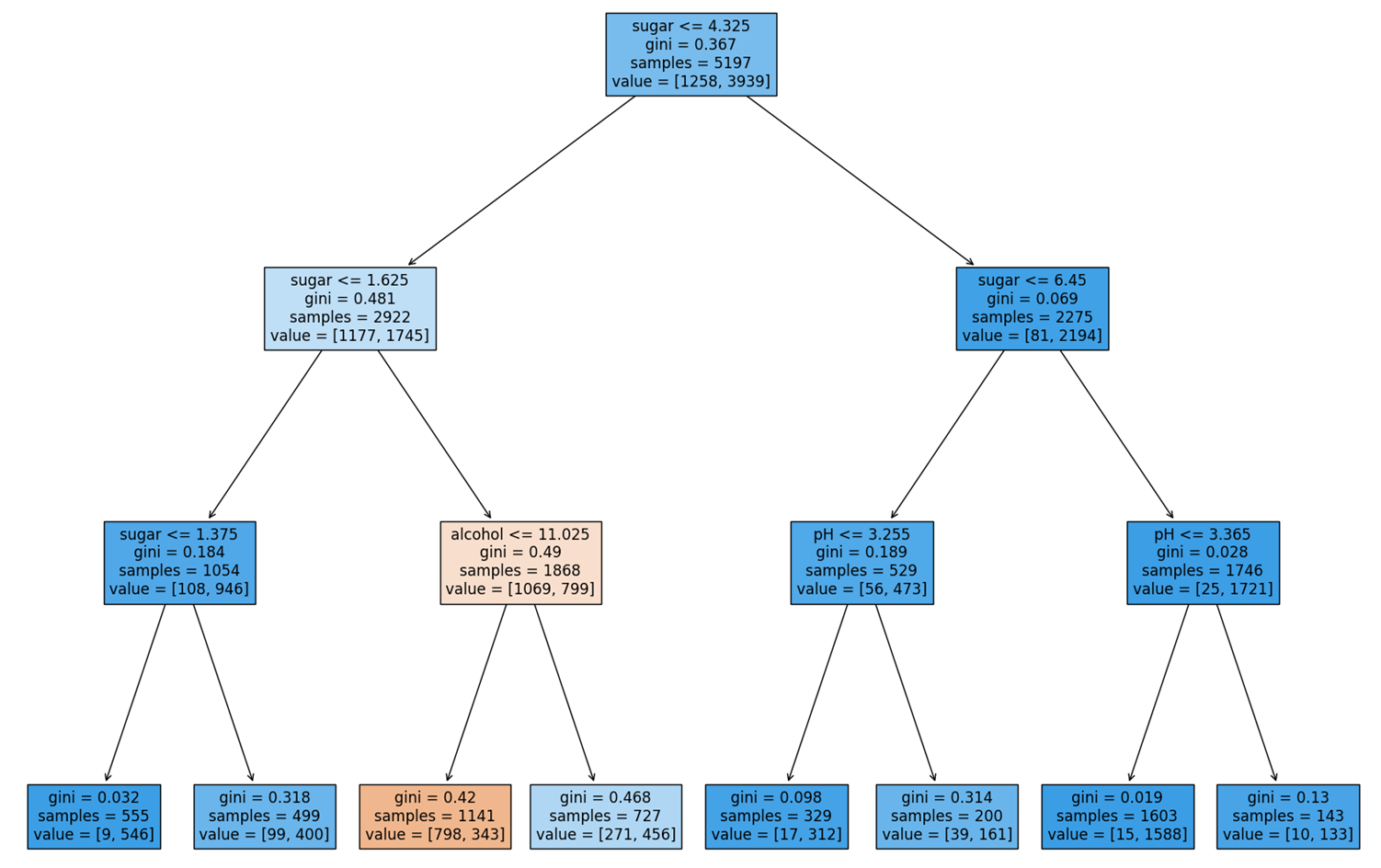
이번 포스팅에서는 알코올 도수, 당도, pH 값으로 레드 와인과 화이트 와인을 구분해 볼 것이다. 이 문제도 Logistic Regression을 이용하여, 손쉽게 해결할 수 있을 것으로 보인다.① Pandas 라이브러리를 이용해 데이터 Set을 불러온다.② 불러온 데
11.Cross Validation과 Grid/Random Search
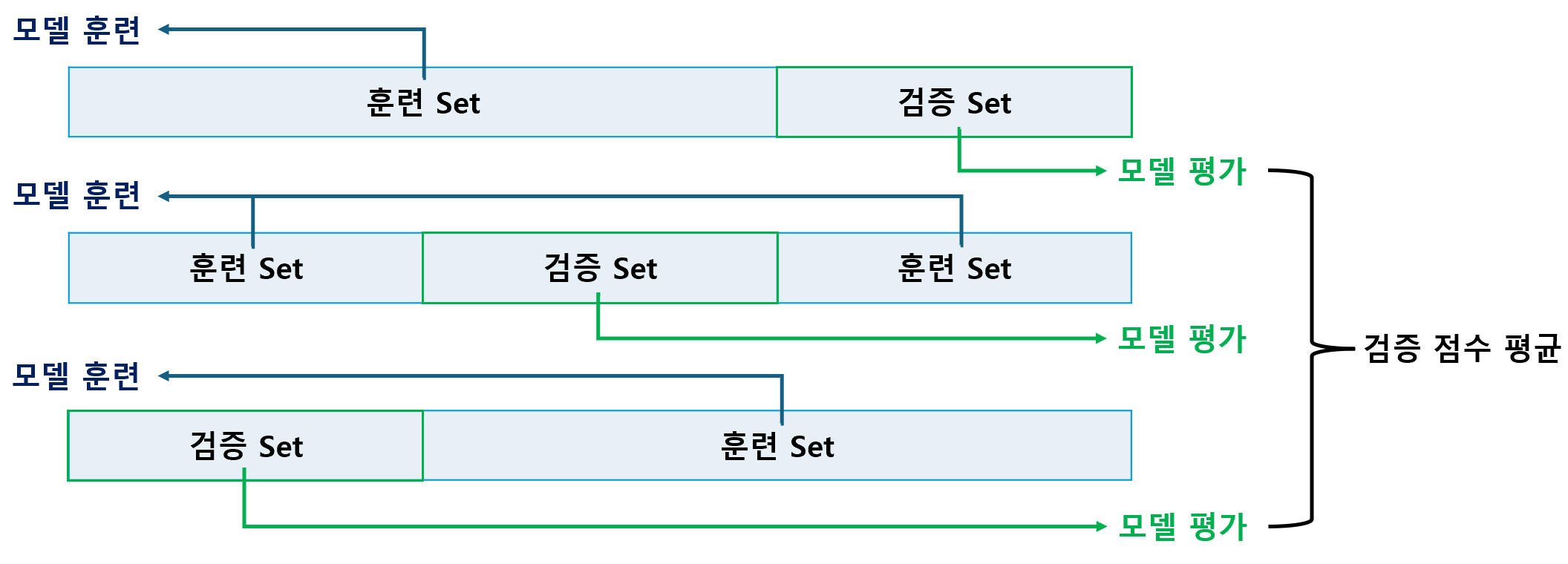
1. 검증 Set 1) 개념 지금까지는 훈련 Set으로 모델을 훈련시킨 후, 테스트 Set으로 모델을 평가하였다. 이 때, 테스트 Set을 이용해 모델의 성능을 평가하는 이유는 모델의 일반화 성능을 가늠하기 위함이다. 그러나, 계속해서 동일한 테스트 Set으로 성능을
12.Ensemble Learning
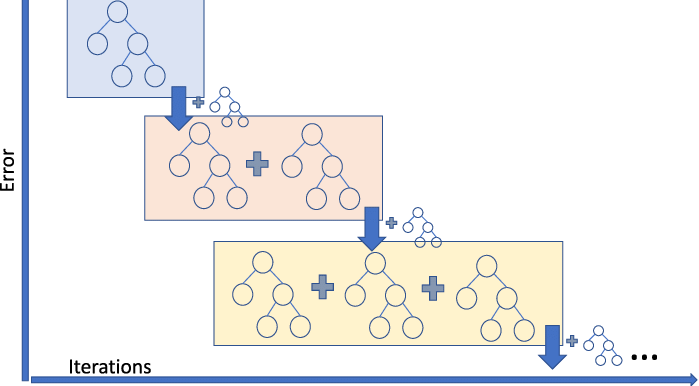
머신 러닝에서 사용되는 데이터는 Structured Data(정형 데이터)와 Unstructured Data(비정형 데이터)로 구분할 수 있다. 여기서 정형 데이터는 CSV나 데이터베이스에 저장하기 쉬운 형태의 데이터를 의미하고, 비정형 데이터는 CSV나 데이터베이스에
13.Clustering Algorithm
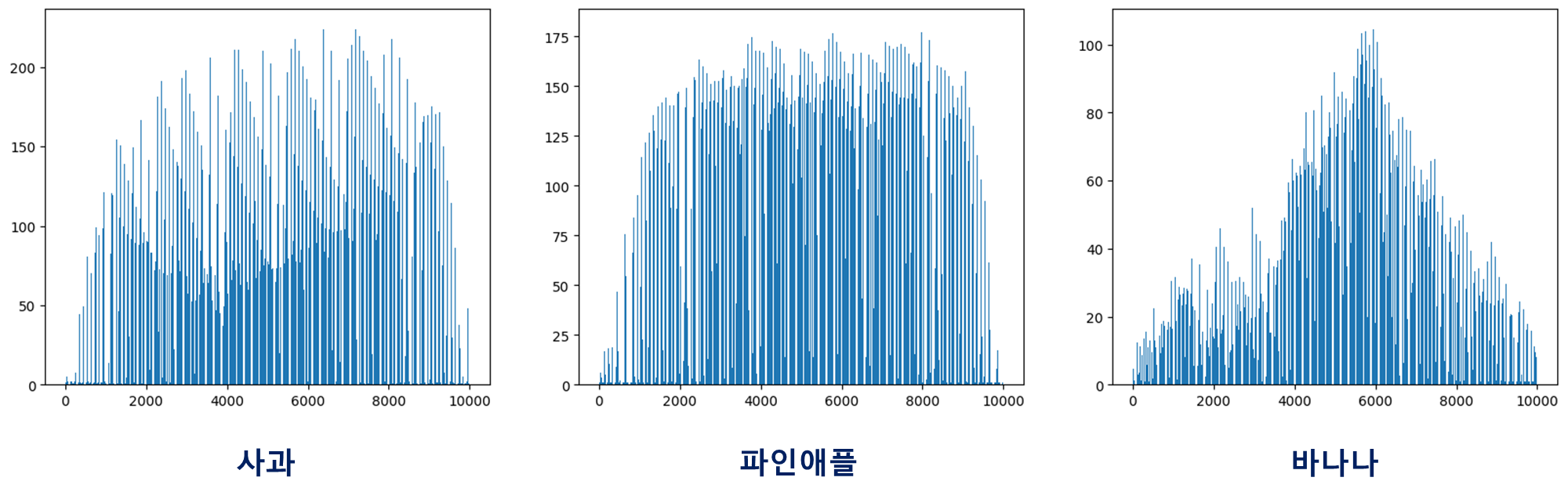
Unsupervised Learning(비지도 학습)은 Target 없이 Input만 사용하는 알고리즘을 말한다. 즉, 사람이 가르쳐주지 않아도 머신러닝 모델이 알아서 데이터의 구조와 규칙성을 찾아내는 것이다.예를 들어 사람들이 업로드한 과일 사진들을, 과일의 종류별로
14.K-Means Clustering

1. K-Means 1) 개념 K-Means 군집 알고리즘을 사용하면, 타깃 데이터 없이도 평균을 계산할 수 있다. 먼저 아래와 같은 과일 Sample이 주어졌다고 하자. 이 과일 Sample을 이용하여, K-Means 알고리즘의 동작 방식을 알아보기로 하자. ①
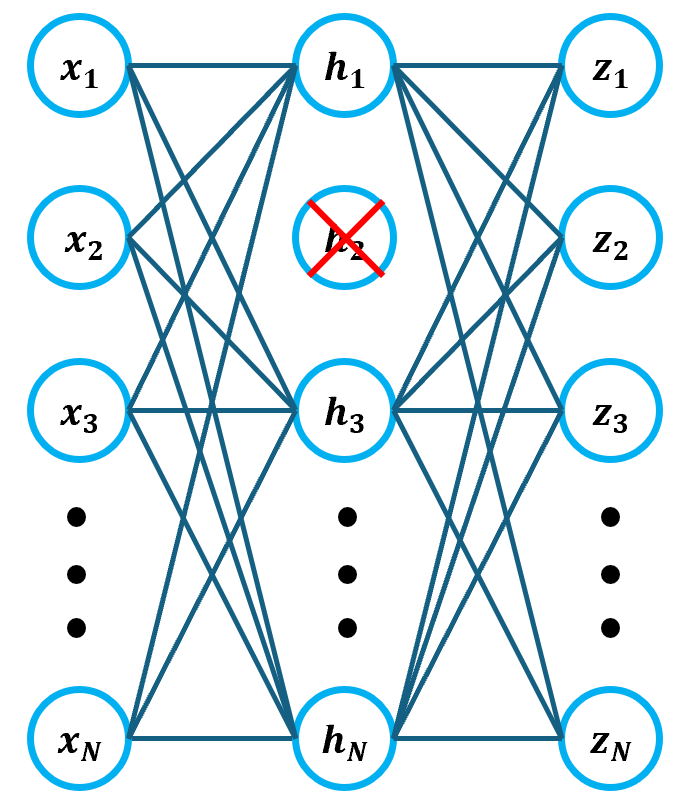
15.PCA를 활용한 Dimensionality Reduction
사진을 Clustering 하는 모델을 이용하여 사용자가 업로드하는 사진들을 분류할 수 있게 되었다. 그러나 시간이 지나 너무 많은 사진이 등록되면 저장 공간이 부족해지는 문제가 생길 수 있다. 그러므로 Clustering에는 영향을 주지 않으면서, 사진의 용량을 줄여
16.Artificial Neural Network
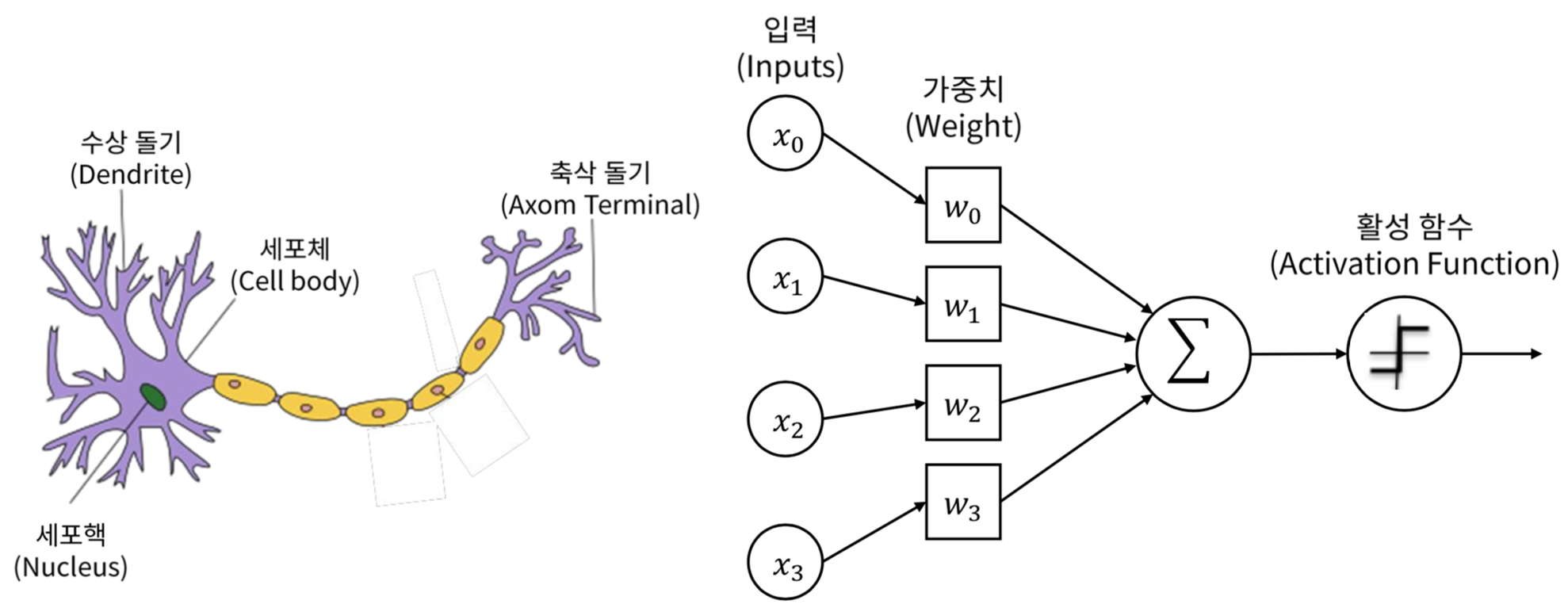
1. MNIST 1) 개념 MNIST는 딥러닝에서 자주 사용되는 대규모 데이터 Set으로, 그 안에는 손으로 그린 0부터 9까지의 숫자 이미지가 포함되어 있다. MNIST는 아래와 같은 특징을 갖는다. 28 X 28 픽셀 크기의 흑백 이미지이다. 각 이미지는 매핑되는
17.Deep Neural Network
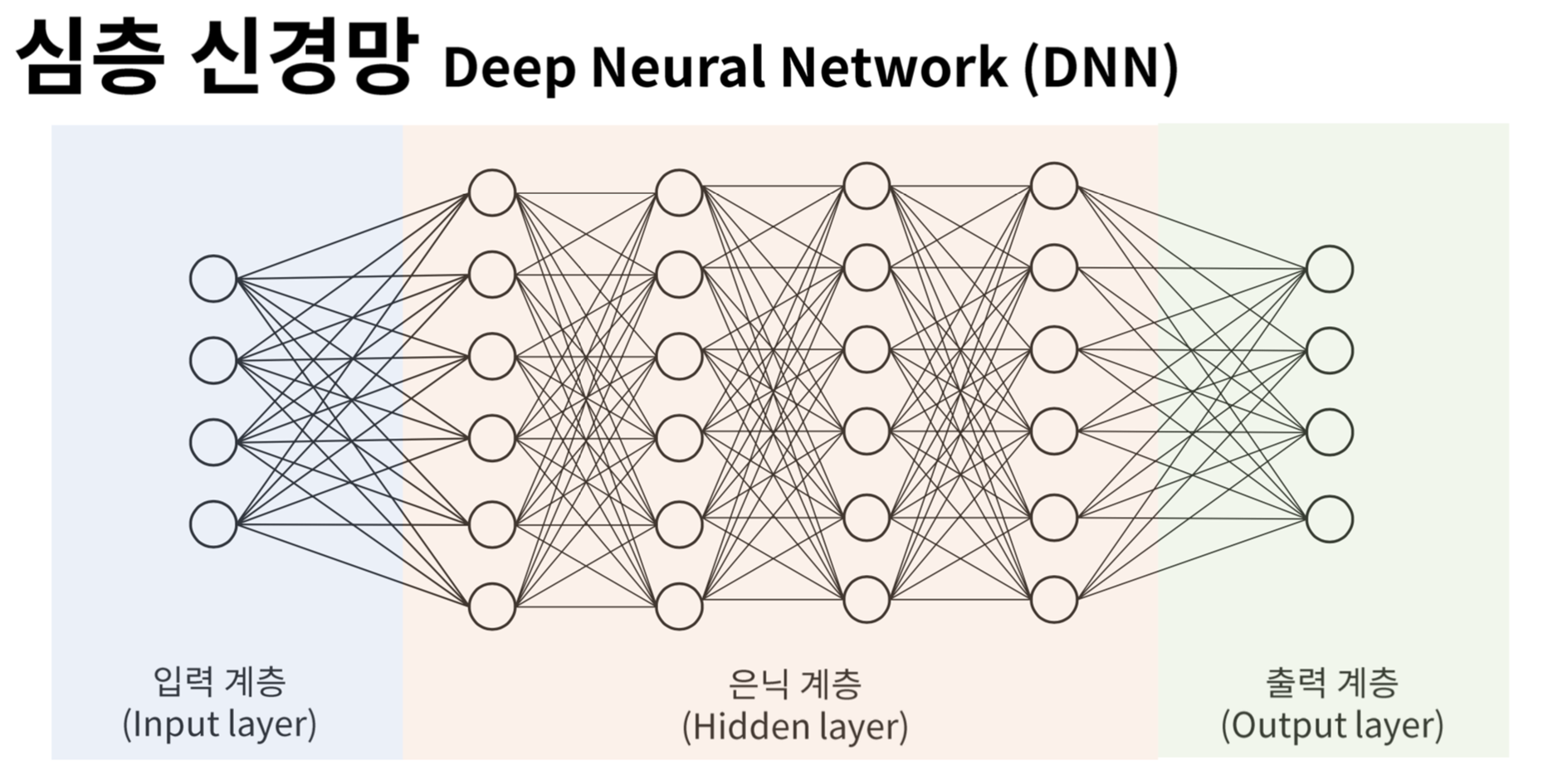
1. Deep Neural Network 1) 개념 Deep Neural Network(심층 신경망)는 ANN의 확장 형태로, 여러 개의 Hidden Layer(은닉층)를 포함하는 인공 신경망을 의미한다. 여기서 은닉층은 입력층과 출력층 사이의 모든 층을 말하는 것으로
18.Training Neural Network
1. Loss Curve fit() 메서드로 모델을 훈련할 때, 아래와 같은 메시지가 출력된 것을 기억할 것이다. 이 메시지의 정체는 Keras의 fit() 메서드가 반환한 History 클래스의 객체이다. History 객체에는 훈련 과정에서 계산한 지표인 loss
19.Convolution Neural Network
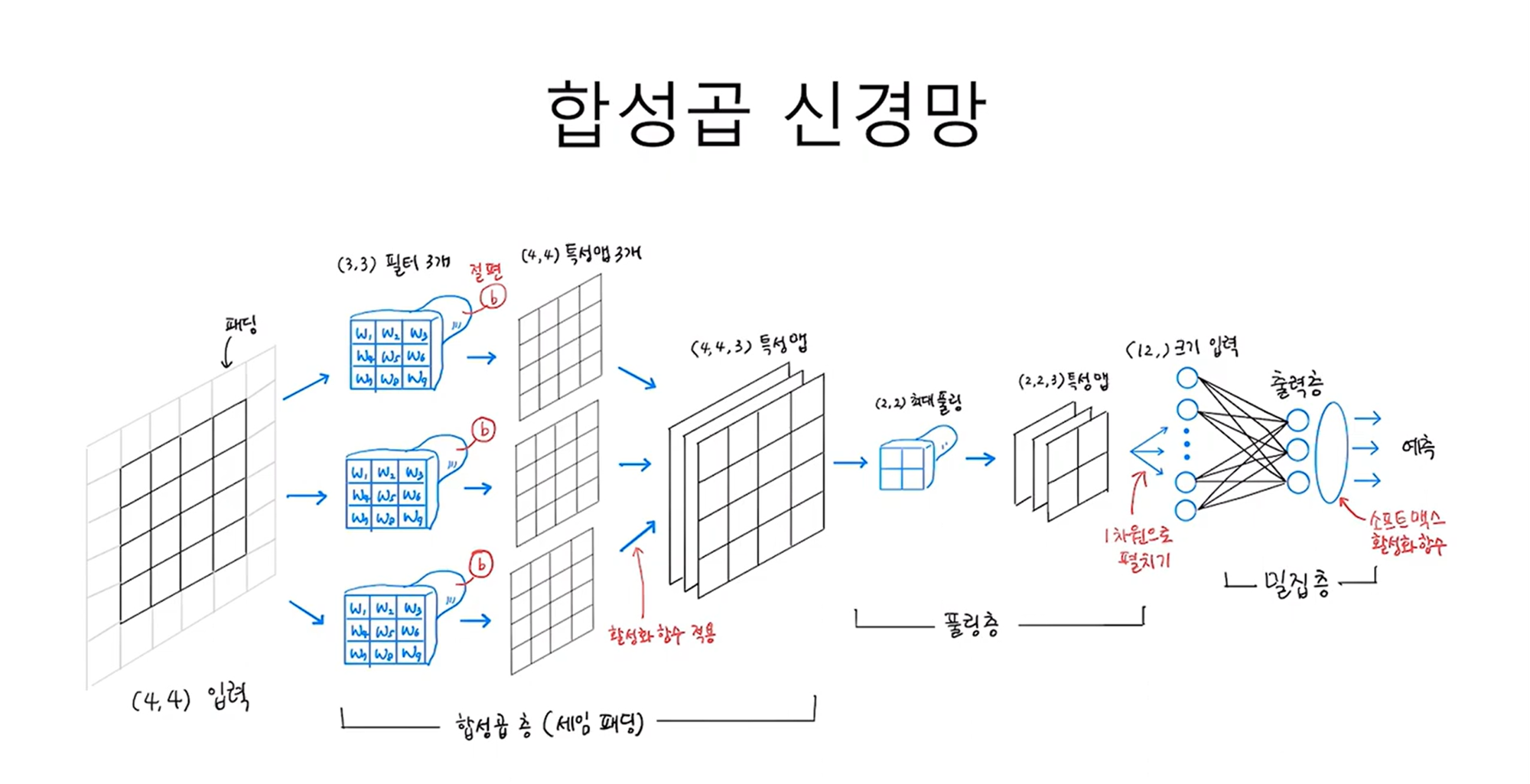
1. Convolution Convolution(합성곱)은 입력 데이터에서 중요한 특성만 골라내기 위해 수행하는 연산을 말한다. 기존에 만들었던 ANN이나 DNN의 밀집층에는 입력-출력 쌍의 개수만큼 가중치가 존재했다. 즉, 가중치가 모든 입력에 대해 곱해진다는 것이다
20.CNN을 활용한 Image Classification
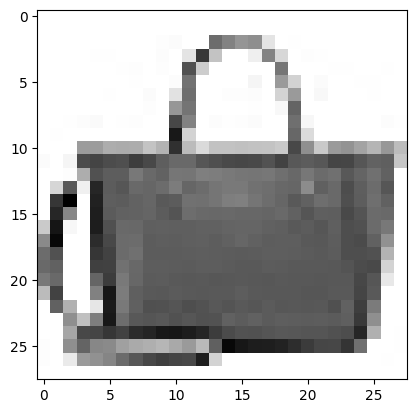
Fashion MNIST 데이터 Set을 불러온 후, 특성 데이터를 Convolution Layer가 기대하는 3차원 배열로 변환한다.① Sequential 클래스의 객체를 만들고, 첫번째 Convolution Layer인 Conv2D 클래스를 추가한다.32개의 필터를
21.CNN Visualization

1. Weight Visualization 필터가 학습한 가중치를 시각화함으로써, CNN이 어떤 특징을 학습했는지 확인할 수 있다. ① 지난 포스팅에서 작성한 코드를 먼저 실행시켜 모델을 저장한 후, 아래의 코드를 이용해 해당 모델을 불러온다. ② model.lay