1. Unsupervised Learning
Unsupervised Learning(비지도 학습)은 Target 없이 Input만 사용하여 모델을 학습시키는 방법을 말한다. 즉, 사람이 가르쳐주지 않아도 머신러닝 모델이 알아서 데이터의 구조와 규칙성을 찾아내는 것이다.
예를 들어 사람들이 업로드한 과일 사진을, 과일의 종류별로 구분해야 하는 상황을 생각해보자. 이러한 상황에서 Supervised Learning 알고리즘을 사용하면, 아래와 같은 문제가 발생할 수 있다.
- 사진은 다양한 환경(조명, 배경, 각도 등)에서 촬영될 수 있기 때문에, 모델이 일관된 예측을 하기 어렵다.
- 데이터의 다양성을 모두 반영하여 타깃을 만드는 일은, 현실적으로 불가능에 가깝다.
지도 학습의 가장 큰 단점은 동일한 타깃 내에서도 다양한 데이터가 존재할 수 있을 때, 라벨링 작업의 비용이 높아진다는 것이다. 그러므로 이와 같은 상황에서는, 타깃 데이터 없이 분류를 수행할 수 있는 비지도 학습 모델을 사용해야 한다.
2. Clustering Algorithm
비지도 학습의 대표적인 알고리즘으로 Clustering(군집화)이 있다. 여기서 Clustering이란, 비슷한 Sample들을 각각의 그룹으로 모으는 작업을 말한다.
그런데 정말 타깃 데이터가 없어도, 모델이 비슷한 Sample을 군집화 할 수 있을까? 이 내용에 대해 알아보기 위해, 지금부터 과일 사진을 종류별로 Clustering 하는 모델을 만들어보도록 하겠다.
1) 데이터 준비
① 사과, 바나나, 파인애플의 흑백 사진이 담긴 파일을 Colab에 다운로드한다.
- 이 파일은 Numpy 배열의 기본 저장 포맷인 npy 형태로 저장되어 있기 때문에, 데이터를 읽기 위해선 먼저 Colab에 파일을 다운로드해야 한다.
- 코드 셀에 '!'로 시작하는 명령은 자동으로 리눅스의 Shell 명령어로 인식된다.
- -O 옵션을 통해 저장할 파일의 이름을 지정할 수 있다.
!wget https://bit.ly/fruits_300_data -O fruits_300.npy② 좌측 파일 탭에서 다운로드된 파일을 확인할 수 있다.
③ 파일에서 데이터를 로드한다.
import numpy as np
import matplotlib.pyplot as plt
fruits = np.load('fruits_300.npy')④ shape 메서드를 통해 fruits 배열의 크기를 확인해보자.
- 300은 Sample의 개수를 의미하고, 100은 각각 이미지의 가로 픽셀의 개수와 세로 픽셀의 개수이다.
print(fruits.shape) # (300, 100, 100) 출력⑤ 첫번째 Sample의 첫번째 행을 출력해보자.
- Numpy 배열에는 0 ~ 255 사이의 정수 값(픽셀 값)이 포함되며, 0에 가까울수록 어둡게, 255에 가까울수록 밝게 나타난다.
print(fruits[0][0][:])
⑥ 위에서 출력된 숫자의 의미를 알아보기 위해 첫번째 Sample의 이미지를 그려보도록 하자.
- Matplotlib의
imshow()메서드를 사용하면, Numpy 배열로 저장된 이미지를 그릴 수 있다. - 흑백 이미지를 그릴 때에는 cmap 매개변수의 값을 gray로 지정해야 한다.
- 머신 러닝 모델 학습에 사용되는 이미지는 반드시 물체를 밝은색으로 표현해야 한다.
plt.imshow(fruits[0], cmap='gray')
plt.show()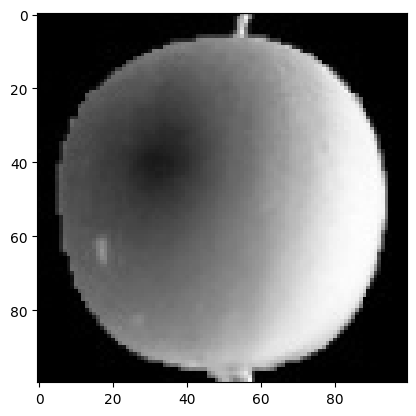
※ 물체를 밝은 색으로 배경을 어두운 색으로 만드는 이유
알고리즘이 어떤 출력을 만들 때, 곱셈을 수행하는 일은 매우 빈번하기 때문에, 물체의 픽셀 값이 0일 경우, 알고리즘이 제대로 동작하지 않을 수 있다. 반면, 픽셀의 값이 높아지면, 그만큼 출력 값의 변화도 커지기 때문에 알고리즘이 더 잘 동작하게 된다. 따라서, 머신 러닝 모델이 학습하는 사진은, 관심 대상(물체)이 밝게 표현되어 있어야 한다.
⑦ 사람이 보기에 편한 이미지는 배경이 밝고, 물체가 어두운 이미지이므로, 흑백을 반전시키도록 하겠다.
- cmap 매개변수를 gray_r로 지정하면 흑백이 반전된다.
plt.imshow(fruits[0], cmap='gray_r')
plt.show()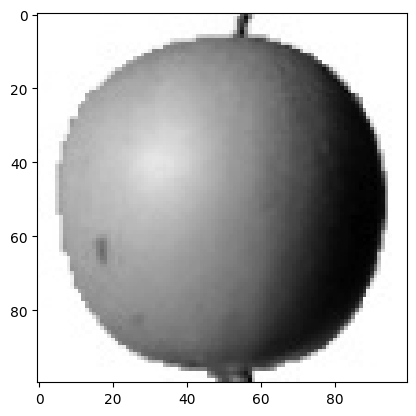
⑧ 파인애플과 바나나 이미지도 확인해보자.
- Matplotlib의
subplots()메서드에 행과 열을 전달하여, 여러 개의 그림을 배열 형태로 표시할 수 있다. - 참고로, fig는 이미지를 나타내는 객체이다.
fig, axs = plt.subplots(1, 2)
axs[0].imshow(fruits[100], cmap='gray_r')
axs[1].imshow(fruits[200], cmap='gray_r')
plt.show()
# fig.savefig('result.png') # 이미지 저장
2) 픽셀 값 분석
주어진 사진의 픽셀 값을 이용해 사진을 Clustering 해보자.
① 계산의 편의성을 위해 100 X 100 사이즈의 이미지 배열을 사이즈가 10000인 1차원 배열로 변환하도록 하겠다.
- 첫번째 차원의 크기는 -1을 이용하여 자동으로 계산하고, 두번째 차원의 크기는 10000으로 지정한다.
- fruits 배열에는 사과, 파인애플, 바나나 사진이 각각 100개씩 담겨있다.
apple = fruits[0:100].reshape(-1, 100 * 100)
pineapple = fruits[100:200].reshape(-1, 100 * 100)
banana = fruits[200:300].reshape(-1, 100 * 100)② 이제 apple, pineapple, banana 배열에 들어 있는 Sample의 픽셀 평균 값을 계산해보도록 하겠다.
- axis를 0으로 지정하면 행방향(세로), 1로 지정하면 열방향(가로)으로 계산을 수행한다.
print(apple.mean(axis=1))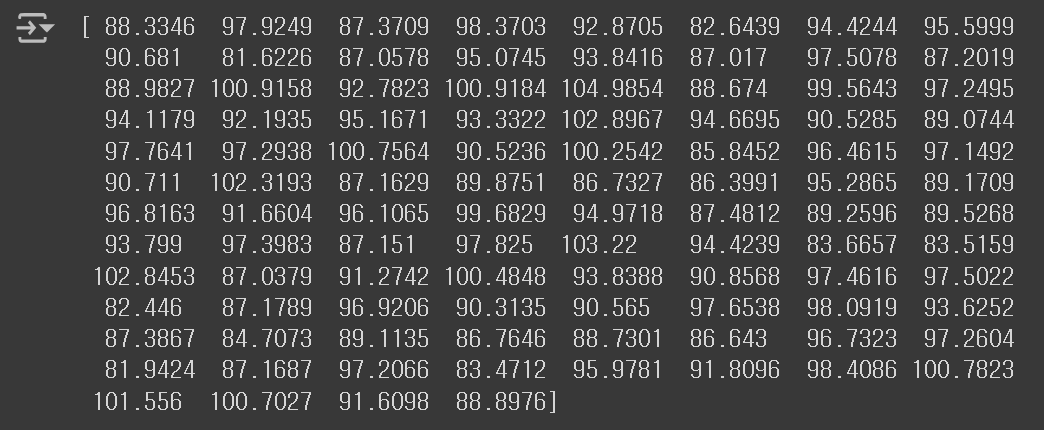
③ 평균 값 분포를 한 눈에 알아보기 위해, Histogram으로 나타내보자.
- alpha 매개변수는 투명도를,
legend()메서드는 범례를 의미한다.
plt.hist(np.mean(apple, axis=1), alpha=0.8)
plt.hist(np.mean(pineapple, axis=1), alpha=0.8)
plt.hist(np.mean(banana, axis=1), alpha=0.8)
plt.legend(['apple', 'pineapple', 'banana'])
plt.show()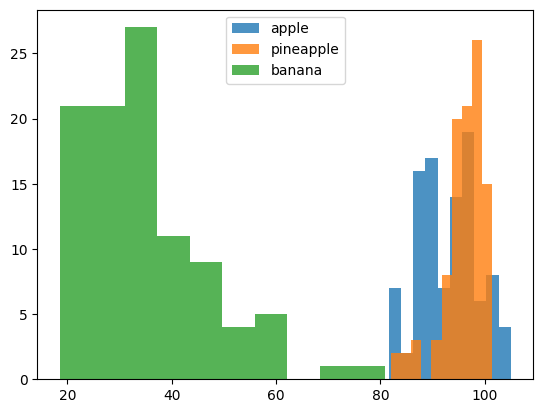
바나나는 전체 픽셀 값의 평균만으로도 사과나 파인애플과 확실히 구분된다. 이는 바나나가 사진에서 차지하는 영역이 적어, 평균 값이 낮게 계산되었기 때문이다. 그러나, 사과나 파인애플은 형태도 비슷하고, 사진에서 차지하는 영역도 비슷해, 픽셀 평균만으로 구분하기는 쉽지 않다.
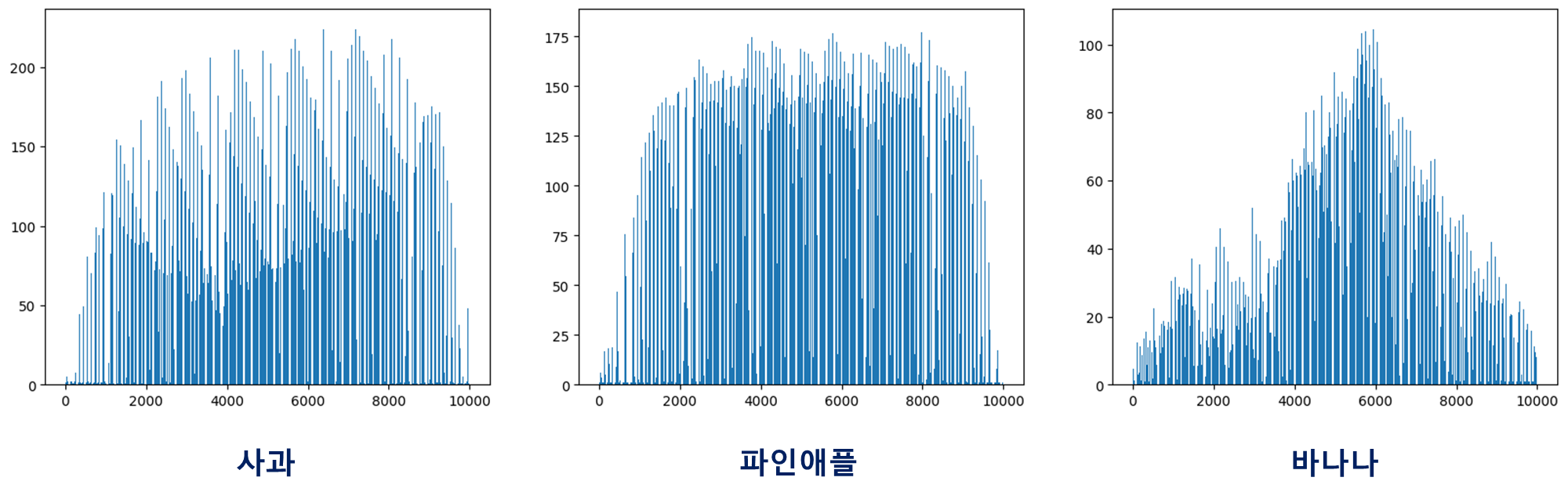
이 때, 각 픽셀별로 평균 값을 구해보면 어떨까? 세 과일 모두 모양이 다르므로, 픽셀 값이 높은 위치가 조금씩 다를 것이다. 그러므로 각 픽셀별로 사과, 파인애플, 바나나 Sample의 픽셀 값 평균을 막대 그래프로 그려보기로 하자.
막대 그래프의 범위는 0부터 9999까지이며, 나타낼 값은 100개의 Sample에 대해 각 픽셀 값의 평균이다. 즉, axis를 0으로 지정하여 평균을 구하면 되는 것이다.
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].bar(range(10000), np.mean(apple, axis=0))
axs[1].bar(range(10000), np.mean(pineapple, axis=0))
axs[2].bar(range(10000), np.mean(banana, axis=0))
plt.show()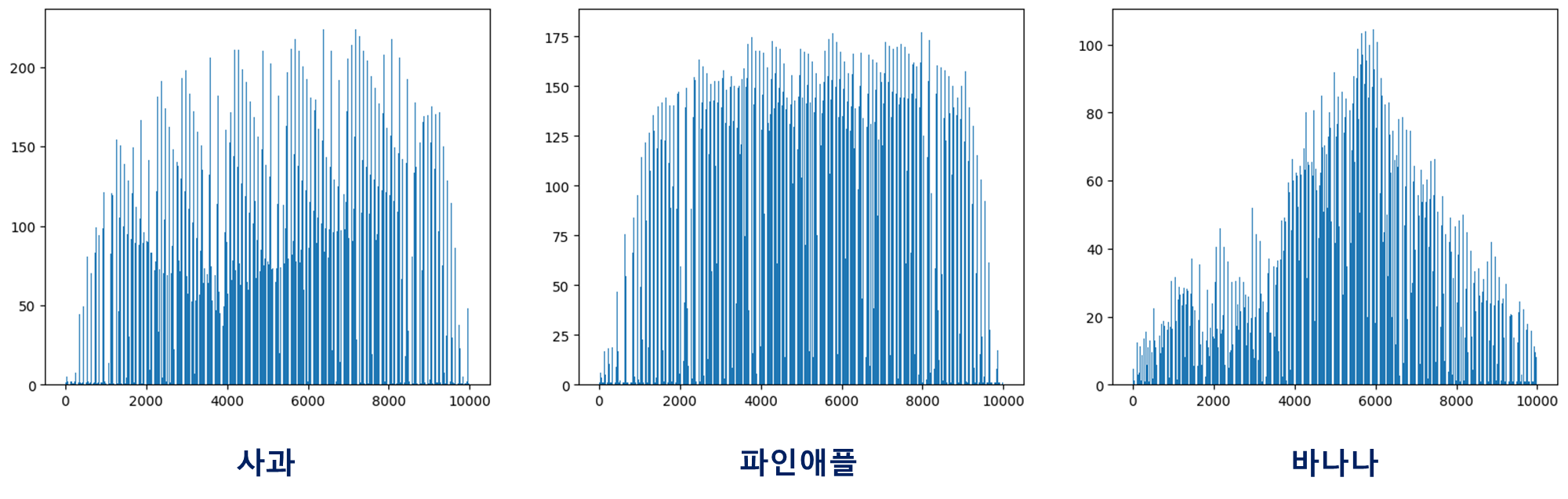
각 픽셀의 평균 값을 다시 이미지로 변환해보면 아래와 같다.
apple_mean = np.mean(apple, axis=0).reshape(100, 100)
pineapple_mean = np.mean(pineapple, axis=0).reshape(100, 100)
banana_mean = np.mean(banana, axis=0).reshape(100, 100)
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].imshow(apple_mean, cmap='gray_r')
axs[1].imshow(pineapple_mean, cmap='gray_r')
axs[2].imshow(banana_mean, cmap='gray_r')
plt.show()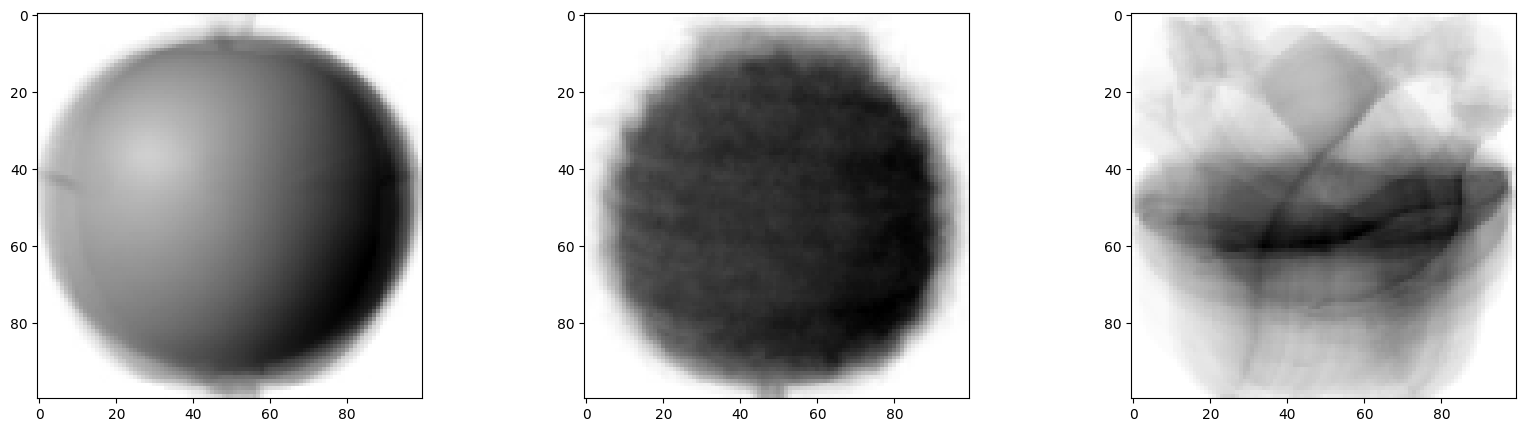
예상대로, 세 과일의 픽셀별 평균 값에는 분명한 차이가 있다. 따라서, 어떠한 사진이 주어질 때마다, 위 이미지 중에서 가장 가까운 이미지를 고르면, 사과, 파인애플, 바나나를 구분할 수 있을 것이다.
3) 평균과 가까운 이미지 고르기
평균 이미지를 만들었으니, 이제 평균 이미지와 가까운 사진을 선택하는 일만 남았다. 예를 들어 주어진 Sample 중 apple_mean과 가장 가까운 사진을 선택하는 상황을 가정해보자.
평균과 가까운 값을 구할 때에는, 절대값 오차를 사용한다. 여기서 절대값 오차란, 모든 Sample에서 apple_mean을 뺀 값에 절대값을 취한 것을 말한다. 결과적으로, 절대값 오차가 제일 적은 100개의 Sample을 선택하면, 대체적으로 사과 이미지를 선택하게 될 것이다.
abs_diff = np.abs(fruits - apple_mean) # 절대값 오차
abs_mean = np.mean(abs_diff, axis=(1, 2)) # 절대값 오차의 평균
apple_index = np.argsort(abs_mean)[:100] # 절대값 오차가 낮은 순서대로 100개의 Sample을 선택
fig, axs = plt.subplots(10, 10, figsize=(10, 10))
# 10 X 10 격자 형태로 이미지 출력
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[apple_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off') # 서브플롯의 좌표축을 숨김
plt.show()
놀랍게도, 선택된 100개의 Sample이 모두 사과 이미지이므로, 과일을 종류별로 Clustering 하는 데에 성공한 것 같다. 그런데, 이와 같은 과정을 진정한 비지도 학습이라고 할 수 있을까?
비지도 학습은 분명 타깃 데이터가 없어야 하는데, 이번 실습에서는 '사과', '파인애플', '바나나'라는 명확한 타깃이 존재했고, 해당 타깃 값을 이용하여 각 Sample의 평균 값을 구했다. 또한, 사과와 파인애플, 바나나가 100개씩 있다는 사실을 이용하여, apple_mean과 가장 가까운 100개의 Sample을 선택하기도 했다.
하지만, 실제 비지도학습은 타깃 데이터가 몇 종류인지, 각 종류별로 몇 개의 데이터가 존재하는지 알 수 없는 경우가 대부분이므로, 위 과정은 엄밀한 의미의 비지도 학습으로 보기는 어렵다.
그런데, 정말 타깃 데이터에 대한 아무런 정보가 없어도, 군집을 형성하고 평균을 계산할 수 있을까? 이 방법에 대해서는 다음 포스팅에서 알아보기로 하겠다.
