
1. K-Means
1) 개념
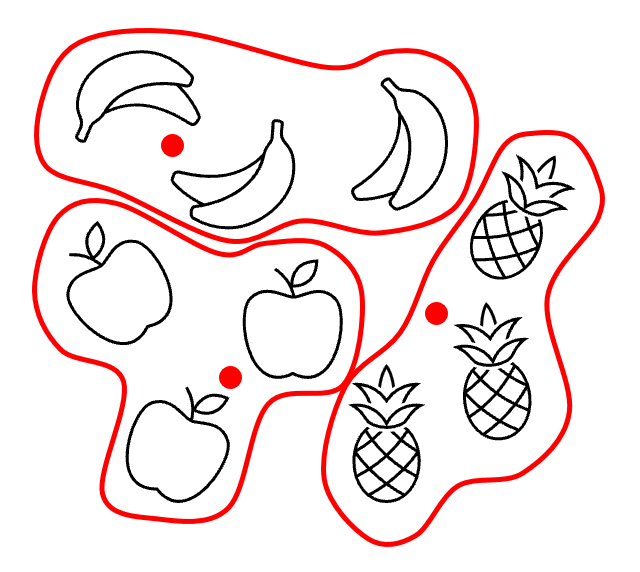
K-Means 군집 알고리즘을 사용하면, 타깃 데이터 없이도 평균을 계산할 수 있다. 먼저 아래와 같은 과일 Sample이 주어졌다고 하자.

이 과일 Sample을 이용하여, K-Means 알고리즘의 동작 방식에 대해 설명해보도록 하겠다.
① 무작위로 K개의 Cluster 중심을 정한다.
- 여기서는 K 값으로 3을 이용하도록 하겠다.

② 각 Sample에서 가장 가까운 Cluster 중심을 기준으로, Sample들을 Clustering 한다.

③ Cluster에 속한 Sample의 평균 값으로 Cluster 중심을 변경한다.
- 이 과정에 의해 Cluster의 중심은 비율이 높은 과일쪽으로 편향되게 된다.
④ Cluster 중심의 변화가 없을 때까지, 위 두 과정을 반복한다.

이번 포스팅에서는 K-Means 알고리즘을 이용해 사과, 파인애플, 바나나를 구분하는 비지도 학습 모델을 만들어 볼 것이다. 이 때 중요한 것은, 타깃 데이터에 대한 정보를 일절 사용하지 않는다는 것이다.
2) 사용법
① 사과, 바나나, 파인애플의 흑백 사진이 담긴 파일을 Colab에 다운로드한다.
!wget https://bit.ly/fruits_300_data -O fruits_300.npy② 파일에서 데이터를 로드한다.
import numpy as np
import matplotlib.pyplot as plt
fruits = np.load('fruits_300.npy')③ 사이킷런의 KMeans 클래스를 사용하여 모델을 생성 및 훈련한다.
- n_clusters 매개변수를 이용하여 K 값을 지정할 수 있다.
- 비지도 학습이므로,
fit()메서드에는 타깃 값을 사용하지 않는다. fit()메서드에 전달해야 하는 훈련 데이터는 2차원 배열이므로, 3차원 배열인 fruits 배열을 2차원 배열로 변환해야 한다.
from sklearn.cluster import KMeans
fruits_2d = fruits.reshape(-1, 100 * 100)
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_2d)④ Clustering 결과는 KMeans 객체의 labels_ 속성을 통해 확인할 수 있다.
- n_clusters의 값이 3이므로, labels_ 배열의 원소는 0, 1, 2로만 구성된다.
- 타깃에 대한 정보(사과, 파인애플, 바나나)에 대한 정보가 없기 때문에, 각 군집이 0번, 1번, 2번으로 구분된 것이다.
print(km.labels_)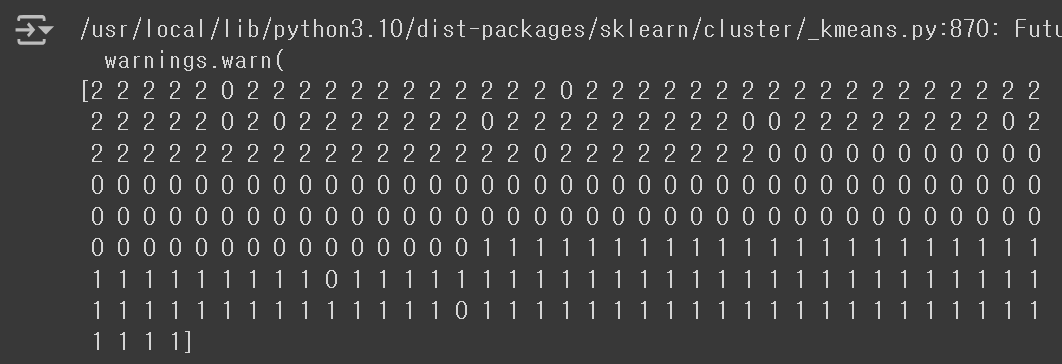
⑤ 각 군집에 모인 Sample의 개수를 확인해보자.
- 첫번째 군집에는 111개, 두번째 군집에는 98개, 세번째 군집에는 91개의 Sample이 모였다.
# km.labels_ 배열의 고유한 값에 대해 발생 빈도를 계산
print(np.unique(km.labels_, return_counts=True))
⑥ 각 군집이 어떤 과일을 모았는지 확인해보기 위해, 이미지를 그리는 함수를 정의하도록 하겠다.
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr)
rows = int(np.ceil(n / 10)) # 행의 개수
cols = n if rows < 2 else 10 # 열의 개수는 행이 1개이면 n개, 행이 2개 이상이면 10개
fig, axs = plt.subplots(rows, cols, figsize=(cols * ratio, rows * ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i * 10 + j < n:
axs[i, j].imshow(arr[i * 10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()⑦ 이제 km.labels_의 값을 이용하여 각 군집에 속한 과일 이미지를 출력해보자.
- 각 군집에 속한 과일 이미지를 출력하는 방법은 km.labels_ 배열의 각 레이블을 조건식으로 전달(Boolean Indexing)하는 것이다.
draw_fruits(fruits[km.labels_ == 0])
draw_fruits(fruits[km.labels_ == 1])
draw_fruits(fruits[km.labels_ == 2])
1번 군집과 2번 군집에서 바나나와 사과를 모으는 데에는 성공했지만, 아쉽게도 0번 군집에는 약간의 바나나와 사과가 포함되었다. 비록 Sample들을 완벽하게 Clustering 하지는 못했지만, 대체적으로 비슷한 Sample들을 잘 모은 것 같다. 이를 통해 알 수 있는 것은, 타깃 데이터가 없어도 모델이 Clustering을 충분히 잘 수행한다는 것이다.
3) Cluster 중심
K-Means 클래스가 최종적으로 찾은 Cluster 중심은 cluster_centers_ 속성에 저장된다. Cluster 중심은 Sample들의 평균 값으로 결정되므로, Cluster 중심을 이미지로 그려보면 지난 시간에 각 픽셀의 평균으로 그려본 이미지와 비슷하게 나올 것이다.
draw_fruits(km.cluster_centers_.reshape(-1, 100, 100), ratio=3)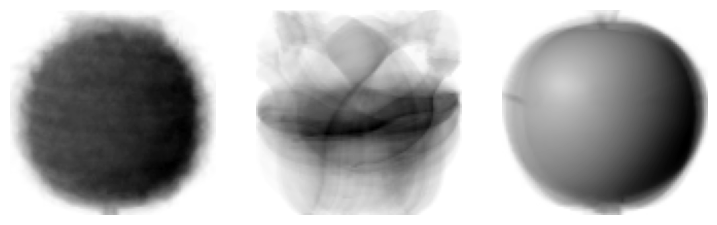
또한, K-Means 클래스는 각 Sample에서 Cluster 중심까지의 거리를 반환하는 transform() 메서드도 제공한다. 참고로, transform() 메서드는 2차원 배열을 기대하므로, 슬라이싱을 사용해 입력 인자를 전달해야 한다. 아래는 100번 인덱스의 Sample에서 각 Cluster 중심까지의 거리를 출력하는 코드를 나타낸 것이다.
print(km.transform(fruits_2d[100:101])) # fruits_2d[100]처럼 쓰면 1차원 배열이 되어 에러가 남
100번 Sample의 경우, 0번 레이블의 Cluster 중심과 가장 가까이에 위치해있다. 실제로 predict() 메서드를 사용해보면, 해당 Sample이 0번 Cluster에 속해 있다는 사실을 확인해 볼 수 있다.
print(km.predict(fruits_2d[100:101])) # [0] 출력즉, 100번 Sample은 파인애플일 가능성이 높다는 것이다. 정말 그러한지 이미지를 그려 확인해보도록 하자.
draw_fruits(fruits[100:101])
2. 최적의 K 찾기
비지도 학습은 타깃 데이터를 전혀 이용하지 않아야 하는데, 사실 우리는 약간의 편법을 사용하였다. n_clusters를 3으로 설정하는 과정에서 타깃이 3종류라는 정보를 활용했기 때문이다. 하지만, 실전에서는 타깃 데이터가 몇 종류인지 알 수 없기 때문에, 이와 같은 방식으로 Cluster의 개수를 지정하는 방법은 별로 실용적이지 않다.
따라서, K-Means 알고리즘을 제대로 활용하려면, 적절한 K 값을 찾는 방법에 대해서도 반드시 알고 있어야 하는데, 이 때 사용할 수 있는 방법이 바로 Elbow이다. Elbow 방법의 동작 원리를 설명하면 아래와 같다.
Sample과 Cluster 중심 사이의 거리를 제곱하여 더한 값을 Inertia(이너셔)라고 부른다. 당연히 Cluster의 개수가 늘어날수록, Cluster에 속하는 개체 수가 줄어들기 때문에 Inertia도 줄어든다. 이 때, Cluster의 개수 변화에 따른 Inertia의 변화를 관찰하면서 최적의 Cluster의 개수를 찾는 방법이 바로 Elbow 방법이다.
Cluster의 개수에 대한 Inertia의 값을 그래프로 그리면, 기울기의 감소폭이 꺾이는 지점이 발생한다. (이러한 그래프의 형태가 마치 팔꿈치의 모양과 비슷하다고 해서 Elbow라는 이름이 붙게 되었다.) 여기서 기울기의 감소는 Sample이 각 Cluster 안에서 분산된 정도가 감소하고 있음을 의미한다. 즉, 이 지점부터는 Cluster의 개수 증가가, Cluster 내 분산 감소에 큰 영향을 주지 못하고 있는 것이다. 따라서, 이 Elbow 부근의 값을 K 값으로 선정하면 된다.
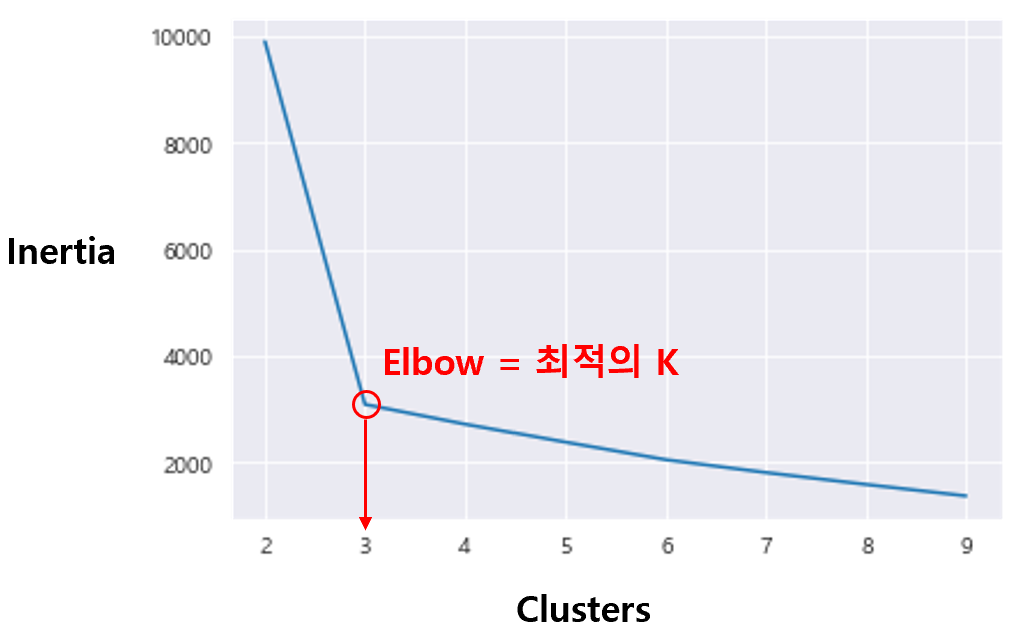
실제로, 과일 데이터 Set을 이용하여 Cluster-Inertia 그래프를 그려보자. Cluster의 값은 2 ~ 6 사이에서 조절하기로 하고, 이에 대응되는 Inertia의 값은 K-Means 클래스의 inertia_ 속성을 이용하여 계산하기로 한다.
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, n_init='auto', random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('Cluster')
plt.ylabel('Inertia')
plt.show()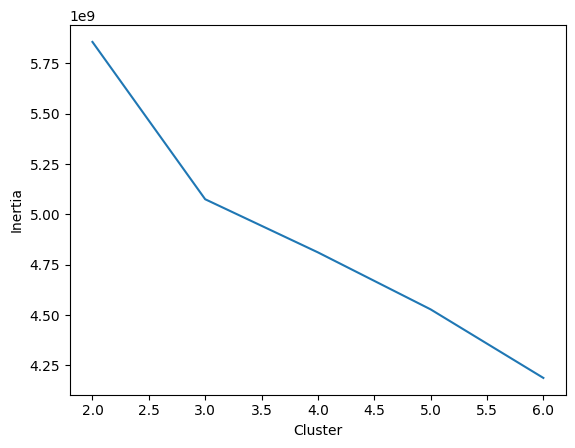
확실히 Cluster의 개수가 3인 지점에서 기울기의 감소 폭이 꺾이고 있음을 확인할 수 있다. 즉, 타깃 데이터를 모르는 상태에서도 Cluster의 개수를 3으로 지정할 수 있다는 것이다. 이로써, 타깃 데이터에 대한 정보를 일절 사용하지 않으면서도, 성공적으로 과일 사진을 Clustering 할 수 있게 되었다.
