1. Dimensionality Reduction
1) 개념
사용자가 업로드하는 사진들을 Clustering 하는 모델이 있다고 해보자. 만약 시간이 지남에 따라 너무 많은 사진이 업로드 될 경우, 저장 공간이 부족해지는 문제가 생길 수 있다. 그러므로 Clustering에는 영향을 주지 않으면서, 사진의 용량을 줄일 수 있어야 하는데, 이 때 Dimensionality Reduction(차원 축소)을 사용할 수 있다.
다중 회귀에 대해 배울 때, 데이터의 특성이 곧 차원이 된다는 사실을 배운 적이 있다. 즉, 여기에서 말하는 차원은 곧 특성의 개수이다. 지난 포스팅에서 사용했던 과일 사진을 생각해보자. 과일 사진은 10000개의 특성(픽셀)으로 구성되어 있으므로, 10000개의 차원을 형성할 것이다.
하지만, 알다시피 10000개의 특성의 중요도는 제각기 다르며, 반드시 그 중에서 해당 데이터를 가장 잘 나타내는 특성이 존재하기 마련이다. 즉, 데이터를 가장 잘 나타내는 일부 특성만 선택하는 방식으로 데이터의 크기를 줄이면, Clustering 성능에 거의 영향을 주지 않으면서도 메모리를 절약할 수 있게 되는 것이다.
또한, 일부 차원 축소 알고리즘은 축소된 차원에서 다시 기존 차원으로 손실을 최소화하면서 복원하는 기능도 제공한다. 그리하여 이번 포스팅에서는 차원 축소를 통해 메모리 공간을 절약하는 방법과, 축소된 차원에서 기존 차원으로 복원하는 방법에 대해 배워보기로 하겠다.
2) Principal Component Analysis
대표적인 차원 축소 알고리즘 중 하나로, Principal Component Analysis(PCA, 주성분 분석)가 있다. 아래의 예시를 통해 PCA의 동작 방식에 대해 알아보기로 하자.
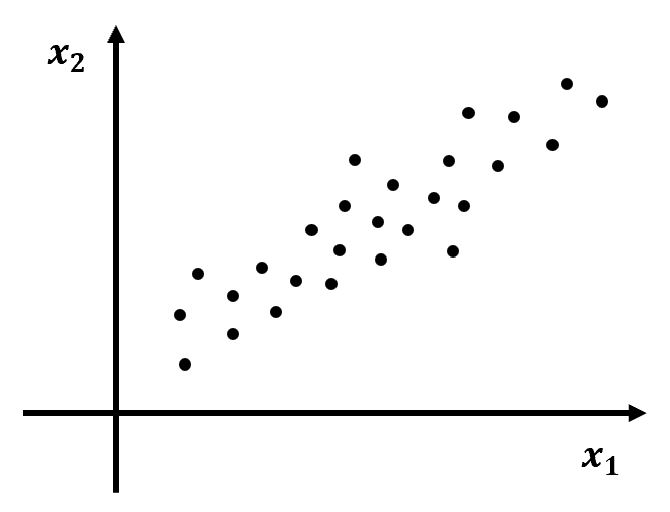
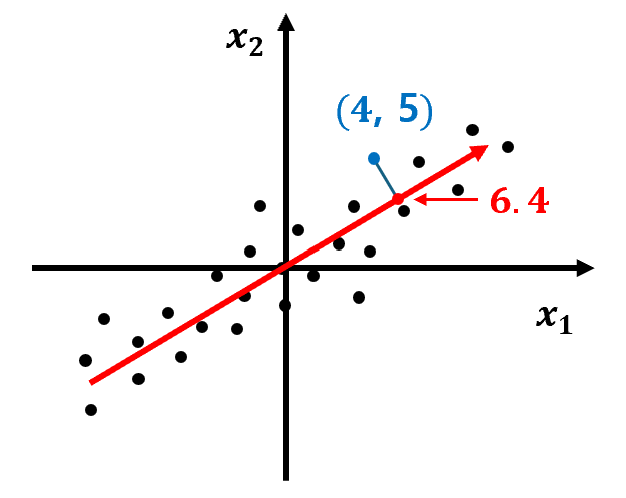
① 아래와 같이 두 가지 특성 x1, x2를 갖는 데이터 Set이 주어졌다고 하자.
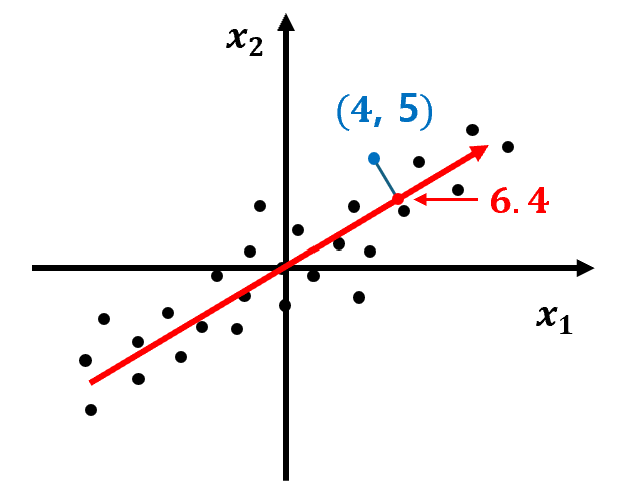
② 데이터의 분포를 가장 잘 표현하는 화살표(벡터)를 찾는다.
- 화살표의 방향에는 의미가 없다.
- 분산이 커지는 방향이 데이터의 분포를 가장 잘 표현하는 방향이 된다.
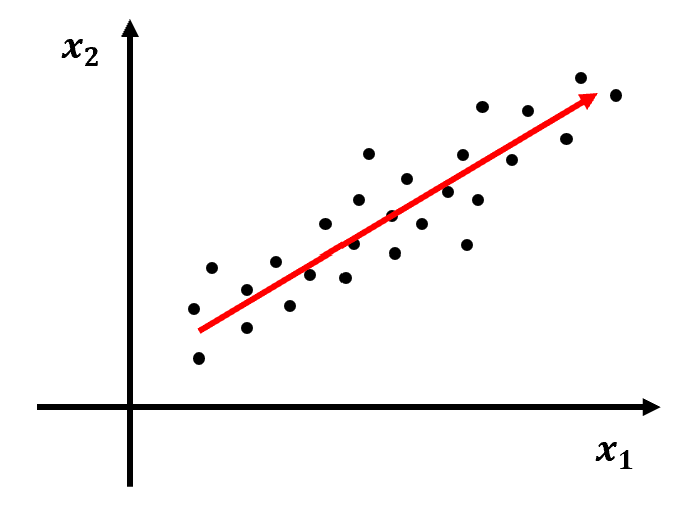
③ 데이터 Set과 벡터를 원점으로 평행 이동한다.
- 이 때, 벡터가 (2, 1)로 표현된다고 하자.
- 이 벡터를 Principal Component(주성분)라고 부른다.
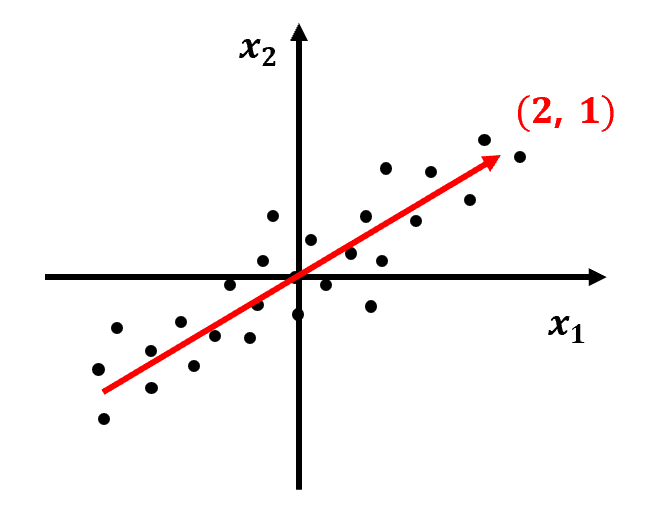
④ 원본 데이터를 주성분 벡터에 대해 정사영하면, 한 차원 낮은 결과를 얻게 된다.
- 2차원 데이터인 (4, 5)를 주성분 벡터에 정사영하면, 6.4라는 1차원 결과 값을 얻게 된다.
- 투영된 데이터는 기존 Sample의 특성을 유지하면서도, 더 간결한 형태를 가지게 된다.
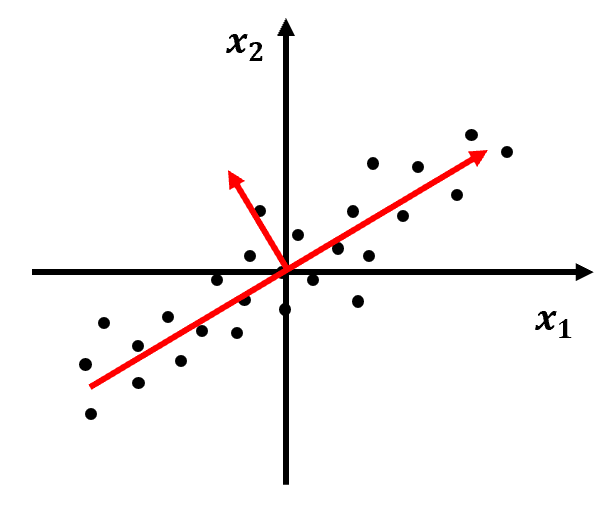
⑤ 첫번째 주성분 벡터를 찾았다면, 다음으로 첫번째 주성분 벡터에 수직이면서 데이터의 분포를 가장 잘 표현하는 두번째 주성분 벡터를 찾는다.
- 주성분 벡터의 개수는 특성의 개수와 동일하다.
- 즉, 2차원 데이터에 대해서는 2개의 주성분 벡터만 그릴 수 있다.
2. PCA 클래스
1) 차원 축소하기
① 사과, 바나나, 파인애플의 흑백 사진이 담긴 파일을 Colab에 다운로드하고, 파일에서 데이터를 로드한다.
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
import numpy as np
import matplotlib.pyplot as plt
fruits = np.load('fruits_300.npy')② 사이킷런에서는 PCA라는 클래스를 통해 주성분 분석 기능을 제공한다.
- n_components 매개변수를 이용해 주성분 벡터의 개수를 지정할 수 있다.
- 이 때, 주성분 벡터의 개수가 축소 차원의 수를 결정한다.
from sklearn.decomposition import PCA
fruits_2d = fruits.reshape(-1, 100 * 100)
pca = PCA(n_components=50)
pca.fit(fruits_2d)③ PCA 클래스가 찾은 주성분은 components_ 속성에서 확인할 수 있다.
- 총 50개의 주성분 벡터를 찾았음을 확인해 볼 수 있다.
print(pca.components_.shape) # (50, 10000) 출력④ 주성분 벡터의 차원은 원본 데이터의 차원과 동일하므로, 주성분 벡터를 이미지로 그려볼 수 있다.
- 주성분의 순서는 데이터의 분포를 가장 잘 나타내는 순서이며, 이미지 또한 이 순서대로 나타난다.
draw_fruits(pca.components_.reshape(-1, 100, 100))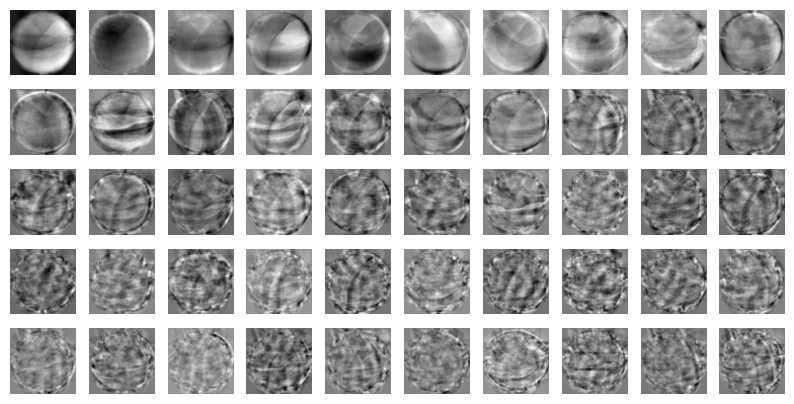
⑤ 이제 주성분 벡터를 이용하여 10000개의 특성(차원)을 50개의 특성(차원)으로 축소해보자.
fruits_pca = pca.transform(fruits_2d)
print(fruits_pca.shape) # (300, 50) 출력기존에 (300, 10000) 크기였던 fruits_2d 배열의 크기가 (300, 50)으로 축소되었다. 다시 말해, fruits_2d 배열 대신 fruits_pca를 저장하면, 무려 200배의 메모리 공간을 절약할 수 있게 되는 것이다.
2) 차원 복원하기
당연히 원본 데이터를 주성분에 투영하는 과정에서 어느 정도의 손실이 발생할 수 밖에 없다. 하지만, 데이터의 전반적인 분포를 잘 나타내는 벡터에 투영한 것이므로, 원본 데이터의 상당 부분을 재구성할 수 있다.
① 차원 복원을 위해 PCA 클래스에서는 inverse_transform() 메서드를 제공한다.
- 50개의 차원으로 축소된 데이터가 다시 10000개의 차원으로 복원되었다.
fruits_inverse = pca.inverse_transform(fruits_pca)
print(fruits_inverse.shape) # (300, 10000) 출력② 복원된 결과를 이미지로 확인해보자.
- 50 차원의 데이터로 10000 차원의 데이터를 복원한 것임에도, 충분히 잘 복원되었음을 확인할 수 있다.
fruits_reconstruct = fruits_inverse.reshape(-1, 100, 100)
for start in [0, 100, 200]:
draw_fruits(fruits_reconstruct[start : start + 100])
print('\n')
3) Explained Variance
50개의 특성만으로도 거의 완벽한 복원 결과를 얻을 수 있었던 이유는, 50개의 특성이 분산을 잘 보존하도록 변환되었기 때문이다. 이 때, 50개의 특성이 분산을 얼마나 잘 보존하였는지를 설명하는 지표로 Explained Variance(설명된 분산)를 사용한다.
PCA 클래스의 explained_variance_ratio_ 속성을 이용하면, 각 주성분의 Explained Variance 값을 확인할 수 있다. 즉, 50개의 주성분의 Explained Variance 값을 모두 더하면, 분산의 몇 %정도를 보존하고 있는지 알아낼 수 있는 것이다.
print(np.sum(pca.explained_variance_ratio_)) # 0.9215423498234566 출력50개의 특성에서 무려 분산의 92% 정도를 유지하고 있기 때문에, 높은 품질의 복원 데이터를 얻을 수 있었던 것이다. 그렇다면, 주성분의 개수는 어떻게 결정할 수 있을까? 적절한 주성분의 개수를 알아내는 방법은 주성분 개수 변화에 따른 Explained Variance의 변화를 그래프로 그려보는 것이다.
plt.plot(pca.explained_variance_ratio_)
plt.show()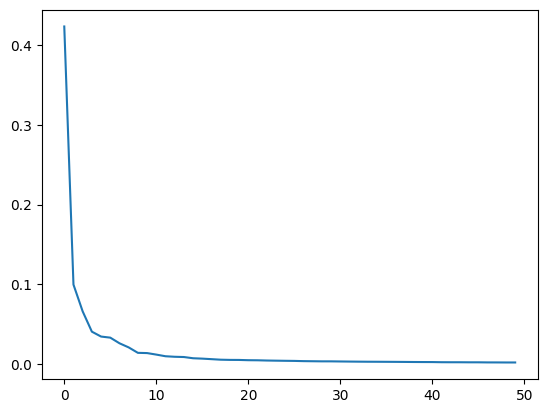
10개의 주성분이 분산의 대부분을 표현하고 있다. 따라서, 메모리 용량이 중요한 상황이라면, 10개의 주성분만 사용하여 데이터를 크게 압축하는 방법을 고려해 볼 수 있을 것이다. 아래는 10차원으로 축소한 후 복원한 결과를 이미지로 나타낸 것이다. 실제로도 50차원으로 축소했을 때와 거의 비슷한 복원 성능을 보이고 있음을 확인할 수 있다.

참고로, PCA의 n_components에 0과 1 사이의 실수를 전달하여, 유지하고자 하는 Explained Variance 만큼의 주성분을 찾을 수도 있다.
pca = PCA(n_components=0.5) # 50% 정도의 분산을 유지할 수 있도록 주성분의 개수를 지정
pca.fit(fruits_2d)
print(pca.n_components_) # 2 출력(2차원 데이터로 축소)3. 차원 축소의 활용
1) 훈련 데이터 전처리
차원 축소는 주로 비지도 학습에서 사용하는 알고리즘이지만, 지도 학습 모델의 훈련 데이터를 전처리하기 위한 목적으로도 자주 사용된다. 지금부터는 지도 학습 모델의 성능에서 차원 축소가 어떻게 활용될 수 있는지에 대해 알아보기로 하자.
① Logistic Regression 모델과 target 데이터를 만든다.
- 사과를 0, 파인애플을 1, 바나나를 2로 지정하여 타깃 데이터를 구성한다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
target = np.array([0] * 100 + [1] * 100 + [2] * 100)② 원본 차원을 가지고 있는 fruits_2d 데이터를 이용하여, Logistic 회귀 모델의 검증 점수를 확인해보자.
- 특성의 개수가 많다보니(과대적합의 영향으로) 모델의 성능이 매우 높게 평가되었다.
- 모델을 훈련시키는 데에는 약 1.94초 정도가 소요되었다.
from sklearn.model_selection import cross_validate
scores = cross_validate(lr, fruits_2d, target)
print(np.mean(scores['test_score']))
print(np.mean(scores['fit_time']))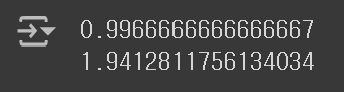
③ 이번에는 50차원으로 축소한 fruits_pca를 사용하여, Logistic 회귀 모델의 검증 점수를 확인해보겠다.
- 분명 더 적은 수의 특성을 사용했음에도, 모델의 성능이 향상되었으며, 훈련 시간도 크게 단축되었다.
scores = cross_validate(lr, fruits_pca, target)
print(np.mean(scores['test_score']))
print(np.mean(scores['fit_time']))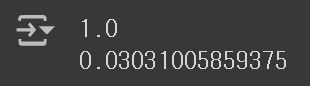
2) 데이터 시각화
4개 이상의 특성을 가진 데이터는 수학적 개념으로만 설명될 수 있을 뿐, 실제 시각화는 불가능하다. 이 때, 차원 축소를 이용하여 데이터의 차원을 3차원 이하로 축소하게 되면, 데이터를 시각화하는 일이 가능해진다.
이 내용을 지난 시간에 배운 K-Means 알고리즘과 Clustering에 적용해보자. 먼저 fruits_2d의 차원을 2차원으로 축소한 후, K-Means 알고리즘을 이용해 Clustering을 수행해보겠다.
from sklearn.cluster import KMeans
pca = PCA(n_components=2)
pca.fit(fruits_2d)
fruits_pca = pca.transform(fruits_2d) # 2차원으로 축소
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_pca)
for label in range(3):
draw_fruits(fruits[km.labels_ == label])
print('\n')
지난 시간에 fruits_2d를 학습한 모델과 거의 유사한 Clustering 성능을 보이고 있다. 다만 여기서 중요한 것은, 사과와 파인애플 사이의 Clustering이 완벽히 수행되지 못한 이유를 시각적으로 확인할 수 있게 되었다는 것이다. Clustering의 결과를 산점도로 나타내보면 아래와 같은 결과가 나타난다.
for label in range(3):
data = fruits_pca[km.labels_ == label]
plt.scatter(data[:, 0], data[:, 1])
plt.legend(['apple', 'banana', 'pineapple'])
plt.show()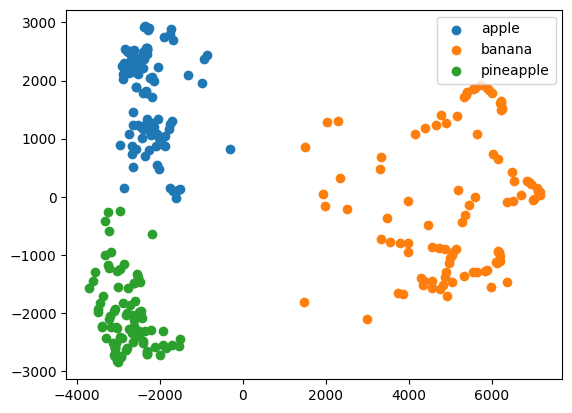
사과와 파인애플을 Clustering 할 때, 약간의 혼동이 발생한 이유는 두 Cluster의 경계가 가깝게 붙어있었기 때문이다. 이처럼 데이터를 시각화하면, 예측 실패의 원인을 파악하는 데에 도움이 될 수 있다.
즉, 차원 축소는 메모리 효율 증가, 지도 학습 모델의 성능 향상 및 훈련 시간 단축, 데이터 시각화 등에 매우 유용한 도구로써 활용될 수 있다.
