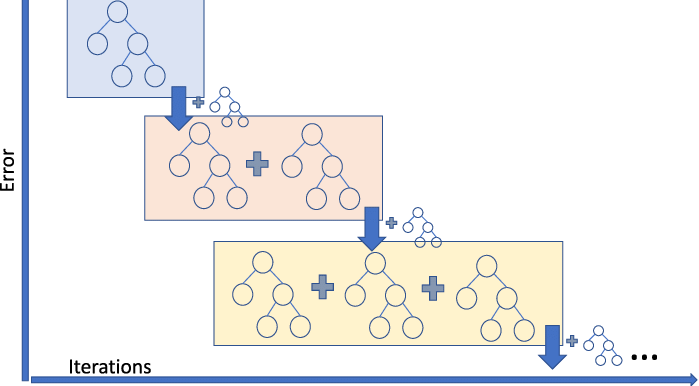
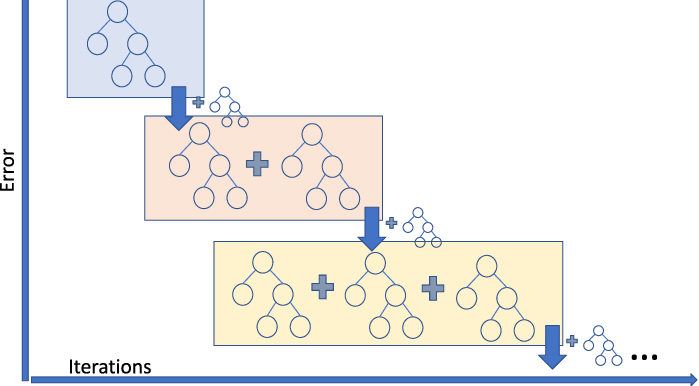
1. Ensemble Learning
머신 러닝에서 사용되는 데이터는 Structured Data(정형 데이터)와 Unstructured Data(비정형 데이터)로 구분할 수 있다. 여기서 정형 데이터는 CSV나 데이터베이스에 저장하기 쉬운 형태의 데이터를 의미하고, 비정형 데이터는 CSV나 데이터베이스에 저장하기 어려운 사진, 음악 등의 데이터를 의미한다.
지금까지 배운 모든 머신러닝 알고리즘을 포함하여 다양한 알고리즘에서 정형 데이터를 취급하지만, 그 중에서도 가장 뛰어난 성능을 보여주는 알고리즘이 바로 Ensemble Learning(앙상블 학습)이다.
2. Random Forest
1) 개념
Random Forest는 대표적인 앙상블 학습 방법 중 하나로, 안정적인 성능을 자랑한다. 이름에서도 알 수 있듯, Random Forest는 결정 트리를 랜덤하게 만들어 결정 숲을 만든다. 그리고 각 결정 트리의 예측을 종합해 최종 예측을 수행한다.
결정 트리를 랜덤하게 만드는 방법은 훈련 데이터를 랜덤하게 선택하는 것이다. 이 때, 랜덤 선택은 Bootstrap 방식으로 이루어지기 때문에, 하나의 Sample이 여러 번 중복 선택될 수도 있다.
※ Bootstrap
Bootstrap이란, 데이터 Set에서 중복을 허용하여 데이터를 Sampling 하는 방식을 말한다. 쉽게 말해, 가방 안에서 Sample을 뽑은 후에 해당 Sample을 다시 가방에 넣어 다음 Sample을 뽑는 것이다.
또한, 각 노드를 분할할 때에도 전체 특성 중 일부 특성을 랜덤하게 선택한 후, 이 중에서 최선의 분할 방법을 찾는다. 분류 모델인 RandomForestClassifier는 기본적으로 전체 특성 개수의 제곱근만큼의 특성을 선택한다. 다만, 회귀 모델인 RandomForestRegressor는 전체 특성을 모두 사용한다.
사이킷런의 Random Forest는 기본적으로 100개의 결정 트리로 구성된다. 이 Random Forest는 랜덤하게 선택된 훈련 데이터와 특성을 사용하기 때문에, 훈련 Set에 과대 적합되지 않으면서, 검증 Set과 테스트 Set에서 안정적인 성능을 발휘한다.
2) 사용법
그러면 지금부터 사이킷런의 RandomForestClassifier 클래스를 화이트 와인을 분류 문제에 적용해보자.
① 와인 데이터 Set을 불러오고, 이를 훈련 Set과 테스트 Set으로 구분한다.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)② RandomForestClassifier 모델을 생성하고, 교차 검증을 수행한다.
- 결정 트리를 100개 생성해야 하므로, n_jobs 매개변수를 -1로 지정한다.
- return_train_score를 True로 설정하면, 훈련 Set에 대한 점수도 함께 반환하므로, 과대 적합 여부를 판단하기에 용이하다.
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
과대 적합의 양상이 나타나고는 있지만, 여기서는 별로 중요한 내용이 아니므로 넘어가기로 한다.
3) 장점
Random Forest는 결정 트리의 앙상블이기 때문에 아래와 같은 장점이 있다.
① DecisionTreeClassifier에 사용되는 매개변수를 제공한다.
- criterion, max_depth, max_features, min_samples_split, min_impurity_decrease, min_samples_leaf 등을 동일하게 사용할 수 있다.
② DecisionTreeClassifier와 마찬가지로, 특성 중요도를 계산하는 기능을 제공한다.
- 결정 트리에서 구해진 특성 중요도와 다르게 나타나는 것이 일반적이다.
- 랜덤 선택으로 인해 하나의 특성에 과도하게 집중하는 경향이 사라지면서, 과대 적합이 줄어들고 일반화 성능이 높아진다.
rf.fit(train_input, train_target)
print(rf.feature_importances_) # [0.23167441 0.50039841 0.26792718] 출력③ Bootstrap Sample에 포함되지 않고 남은 OOB(Out of Bag) Samples를 이용해 모델의 성능을 평가한다.
- 이 때, OOB Sample은 검증 Set의 역할을 수행하게 된다.
- oob_score 매개변수를 True로 지정해야, OOB Samples를 통한 성능 평가 결과를 확인할 수 있다.
rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_) # 0.8934000384837406 출력3. Extra Trees
1) 개념
이번에 배워볼 Extra Trees 역시 앙상블 학습의 일종으로, Random Forest와 매우 비슷하게 동작한다. Extra Trees와 Random Forest의 공통점은 아래와 같다.
- 기본적으로 100개의 결정 트리를 훈련한다.
- 전체 특성 중 일부 특성을 랜덤 선택하여 노드를 분할한다.
- DecisionTreeClassifier에 사용되는 매개변수를 제공한다.
- 특성 중요도를 계산하는 기능을 제공한다.
하지만, Extra Trees는 Bootstrap Sample을 사용하지 않는다. 즉, 각 결정 트리는 모두, 전체 훈련 Set을 이용해 만들어진다는 것이다. 대신 노드를 분할할 때, 가장 좋은 분할을 찾지 않고 무작위로 분할을 수행한다.
당연히 하나의 결정 트리에서 특성을 무작위로 분할한다면, 성능이 낮은 모델이 만들어지겠지만, 많은 트리를 앙상블하기 때문에 생각보다 좋은 성능을 보여준다.
2) 사용법
사이킷런에서 제공하는 ExtraTreesClassifier 클래스를 이용해 교차 검증 점수를 확인해보자.
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
특성이 많지 않다보니, Random Forest와 비슷한 결과가 출력되었지만, 일반적으로는 Extra Trees의 성능이 조금 더 낮게 측정된다. 즉, Extra Trees로 Random Forest와 비슷한 성능을 얻으려면, 훨씬 더 많은 결정 트리를 훈련해야 하는 것이다. 이는 Extra Trees가 Random Forest보다 무작위성이 더 크기 때문이다.
하지만, 무작위성이 더 크다는 특징 덕분에, Extra Trees는 매우 빠른 계산 속도를 자랑한다. 노드의 최적 분할 방법을 찾는 데에 많은 시간을 소모하는 일반 결정 트리와 달리, Extra Trees는 노드를 랜덤하게 분할하기 때문에 훨씬 더 빠른 속도로 결정 트리를 구성할 수 있게 되는 것이다.
4. Gradient Boosting
1) 개념
Gradient Boosting은 여러 개의 Weak Learners를 순차적으로 결합하여 강력한 예측 모델을 만드는 앙상블 학습 방법을 말한다. 주로 깊이가 얕은 결정 트리를 Weak Learners로 사용하는데, 이는 깊이가 얕은 트리가 과대 적합에 강하고, 일반화 성능이 높기 때문이다. 실제로 사이킷런의 GradientBoostingClassifier는 기본적으로 깊이가 3인 결정 트리를 100개 사용한다.
Gradient Boosting의 기본 아이디어는, 이전 모델이 만든 오차를 새로운 모델이 보정하는 방식으로 모델을 개선하는 것이다. 즉, 이름에 붙은 "Gradient"에서도 알 수 있다시피, Gradient Boosting은 경사 하강법을 이용하여 트리를 앙상블에 추가한다.
참고로 여기서 말하는 경사는, 분류 모델에서는 Logistic 손실 함수를, 회귀 모델에서는 평균 제곱 오차(MSE) 함수를 의미한다.
2) 사용법
GradientBoostingClassifier을 이용해 와인 데이터 Set의 교차 검증 점수를 확인해보자.
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
확실히 과대 적합에 강한 모습을 보이고 있다. 그러나, 아직 모델의 성능이 낮게 평가되고 있으므로, 이를 조금 더 개선해야 할 것 같다.
Gradient Boosting 모델의 성능은 학습률 및 트리의 개수와 관련이 깊다. 전반적으로 학습률과 트리의 개수가 높아질수록 모델의 성능이 좋아질 수 있지만, 과대 적합의 양상이 점점 심해질 수 있다. (최적의 학습률과 트리 개수를 찾으려면, 교차 검증을 수행해야 한다.)
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2, random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
일반적으로 Gradient Boosting이 Random Forest보다 성능이 좋다. 그러나, 순서대로 트리를 추가해야 하는 특성상, 병렬 처리가 어려워 훈련 속도가 매우 느리다는 단점이 있다.
3) Histogram-Based Gradient Boosting
Gradient Boosting의 성능과 속도 상의 단점을 개선한 것이 바로 Histogram-Based Gradient Boosting(HGB)이다. 히스토그램 기반 Gradient Boosting은 정형 데이터를 취급하는 알고리즘 중에서 가장 인기가 많은 알고리즘이다.
HGB는 먼저 입력 특성을 256개의 구간(bin)으로 나눈다. 예를 들어 특성 데이터가 0에서 100 사이에 분포하는 경우, 각 구간의 크기는 100/256이 될 것이다. 이 때, 특별히 하나의 구간을 선택하여, 누락된 특성 값(Null)을 처리한다. 따라서, 누락된 값을 포함한 특성 데이터를 그대로 사용할 수 있다.
그러면 지금부터 와인 데이터 Set에 대해 HGBClassifier를 적용해보자. HGBClassifier는 트리의 개수를 지정하기 위해 n_estimators가 아닌 max_iter를 사용해야 한다.
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target, return_train_score=True)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
과대 적합을 잘 억제하면서, Gradient Boosting보다 더 우수한 성능을 보이고 있다. HGB를 통해서도 특성 중요도를 계산할 수 있는데, 이 때 사용되는 메서드는 permutation_importance()이다. 이 메서드를 이요해 훈련 Set과 테스트 Set에서의 특성 중요도를 계산해보면, 이 모델이 실전에 투입되었을 때, 어떤 특성에 영향을 많이 받을지 예상할 수 있게 된다.
from sklearn.inspection import permutation_importance
hgb.fit(train_input, train_target)
result_train = permutation_importance(hgb, train_input, train_target, n_repeats=10, random_state=42, n_jobs=-1)
print(result_train.importances_mean)
result_test = permutation_importance(hgb, test_input, test_target, n_repeats=10, random_state=42, n_jobs=-1)
print(result_test.importances_mean)
참고로, n_repeats 매개변수는 특성을 랜덤하게 섞을 횟수를 지정하기 위해 사용되었으며, 각 result에는 특성 중요도와 평균, 표준편차가 담겨 있다. 그중에서 특성 중요도의 평균 값을 출력해보니 두 경우 모두 당도의 중요도를 가장 높게 평가하였다. 마지막으로 HGBClassifier 모델의 성능을 테스트 Set을 이용해 평가해보자.
hgb.score(test_input, test_target) # 0.8723076923076923 출력단일 결정 트리보다 앙상블 트리에서의 성능이 조금 더 높게 나왔다. (지난 포스팅의 Random Search로 튜닝된 결정 트리에선 0.869점이 나왔다.) 이처럼 앙상블 모델은 과대 적합을 억제하면서도, 더 높은 수준의 예측 성능과 일반화 성능을 발휘한다.
