1. Logistic Regression을 이용한 분류의 한계
이번 포스팅에서는 알코올 도수, 당도, pH 값으로 레드 와인과 화이트 와인을 구분해 볼 것이다. 이 문제도 Logistic Regression을 이용하여, 손쉽게 해결할 수 있을 것으로 보인다.
1) 데이터 준비 및 모델 훈련
① Pandas 라이브러리를 이용해 데이터 Set을 불러온다.
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')② 불러온 데이터에서 첫 5개의 Sample을 확인한다.
- 타깃(class) 값 0은 레드 와인, 1은 화이트 와인을 의미한다.
wine.head()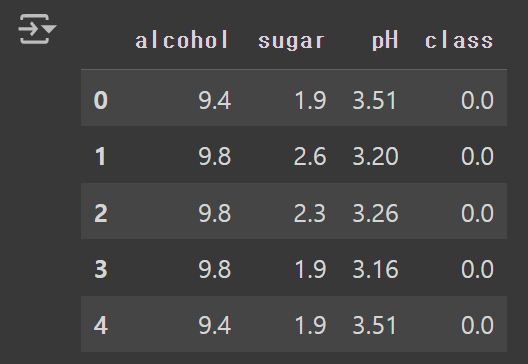
③ info() 메서드를 사용하여 각 열의 데이터 타입과 데이터 누락 여부를 확인할 수 있다.
- 6497개의 Sample이 존재한다.
- 4개의 열 모두 실수형 데이터를 갖는다.
- Non-Null Count가 Sample의 수와 동일한 것으로 보아, 데이터 누락은 발생하지 않은 것 같다.
wine.info()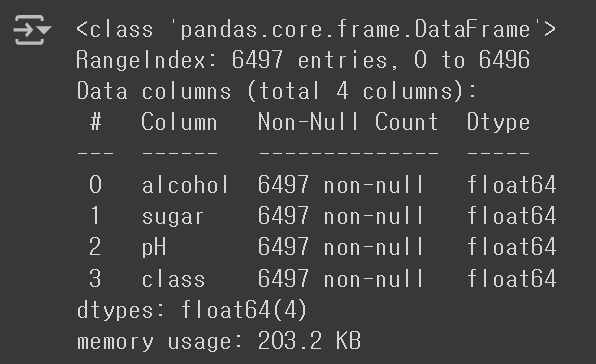
④ describe() 메서드를 사용하면, 열에 대한 간략한 통계 값을 알아낼 수 있다.
- count: Non-Null Count
- 25%: 1사분위수(하위 25%에 해당하는 값)
wine.describe()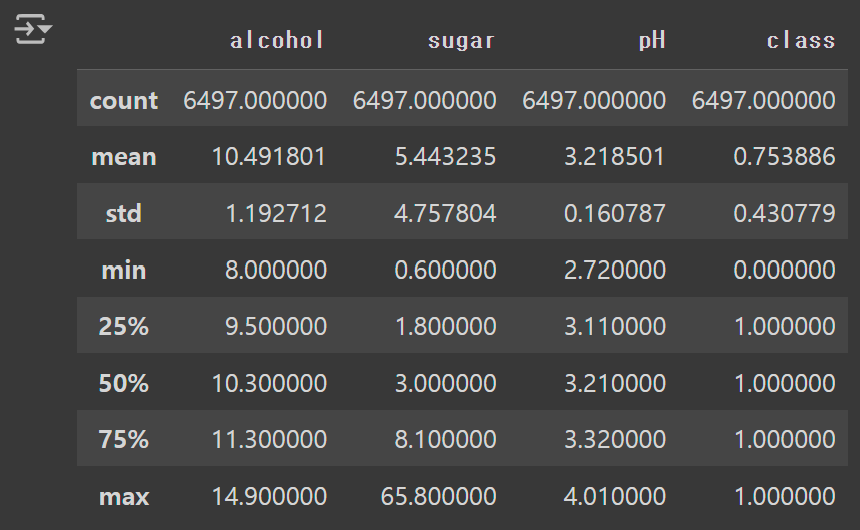
⑤ 'class' 열은 타깃 데이터로, 나머지 열은 입력 데이터로 사용한다.
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()⑥ 훈련 Set과 테스트 Set을 구분한다.
- 이번에는
test_size매개변수를 이용하여, Sample의 20% 정도만 테스트 Set으로 사용하기로 한다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)⑦ 알코올 도수, 당도, pH 값의 스케일이 다르므로, 데이터 전처리를 수행한다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)⑧ 표준화된 데이터를 이용하여, Logistic 회귀 모델을 훈련시킨다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))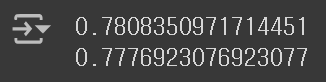
비록 낮은 점수가 나왔지만, 이 문제는 규제를 완화하기 위해 매개 변수 C의 값을 높이거나, 다른 특성을 추가하는 방법 등으로 어렵지 않게 해결할 수 있다. 여기서는 과소 적합을 해결하는 일이 별로 중요하지 않으므로, 무시하고 넘어가기로 하겠다.
2) Logistic Regression을 이용한 분류의 한계
Logistic Regression을 이용하여 분류 모델을 만들 때의 가장 큰 문제는 모델을 설명하기 어렵다는 것이다. 그 이유는 모델이 어떻게 이진 분류를 수행했는지를, 오직 모델이 학습한 선형 방정식의 계수로 설명해야 하기 때문이다.
print(lr.coef_, lr.intercept_) 
이 모델은 (알코올 도수) * 0.51 + (당도) * 1.67 + (pH 값) * -0.69 + 1.82의 값이 0보다 크면 양성 클래스(화이트 와인), 0보다 작으면 음성 클래스(레드 와인)로 판단한다. 하지만, 계수의 의미가 명확하지 않아, 처음 보는 사람이 이해하기에 어려울 수 밖에 없다.
그저 알코올 도수와 당도는 높을수록 화이트 와인일 가능성이 높아지고, 반대로 pH 값은 높을수록 레드 와인일 가능성이 높아진다는 추상적인 내용만 이해할 수 있을 뿐이다. 아무래도 예측 결과에 대해 명확히 설명할 수 있는, 다른 모델을 고려해보아야 할 것 같다.
2. Decision Tree Classifier
1) 사용법
예측에 대한 이유를 설명하기 쉬운 대표적인 모델로, Decsion Tree(결정 트리)가 있다. 결정 트리는 Yes/No로 구분되는 여러 개의 질문을 통해 분류를 수행하므로, 데이터를 잘 구분할 수 있는 질문일수록 분류 정확도가 향상된다.
사이킷런에서 결정 트리 알고리즘을 제공하는 클래스는 DecisionTreeClassifier이며, 그 사용법은 아래와 같다.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaeld, test_target))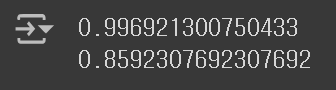
※ random_state를 사용한 이유
결정 트리 알고리즘은 최적의 분할 방법을 찾기 위해 특성의 순서를 섞는 과정을 수행한다. 이 때, 약간의 무작위성이 발생하기 때문에 이를 통제하기 위해 사용한 것일 뿐, 실전에서는 사용할 필요가 없다.
훈련 Set에서의 점수가 매우 높게 나오기는 했지만, 과대 적합의 양상이 나타나고 있다. 그렇다면, 결정 트리에서 발생하는 과대 적합은 어떻게 해결할 수 있을까? 해결 방법을 알아보기 위해 먼저, 완성된 결정 트리를 그려보기로 하자.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10, 7)) # 그림의 크기를 가로 10인치, 세로 7인치로 설정
plot_tree(dt)
plt.show()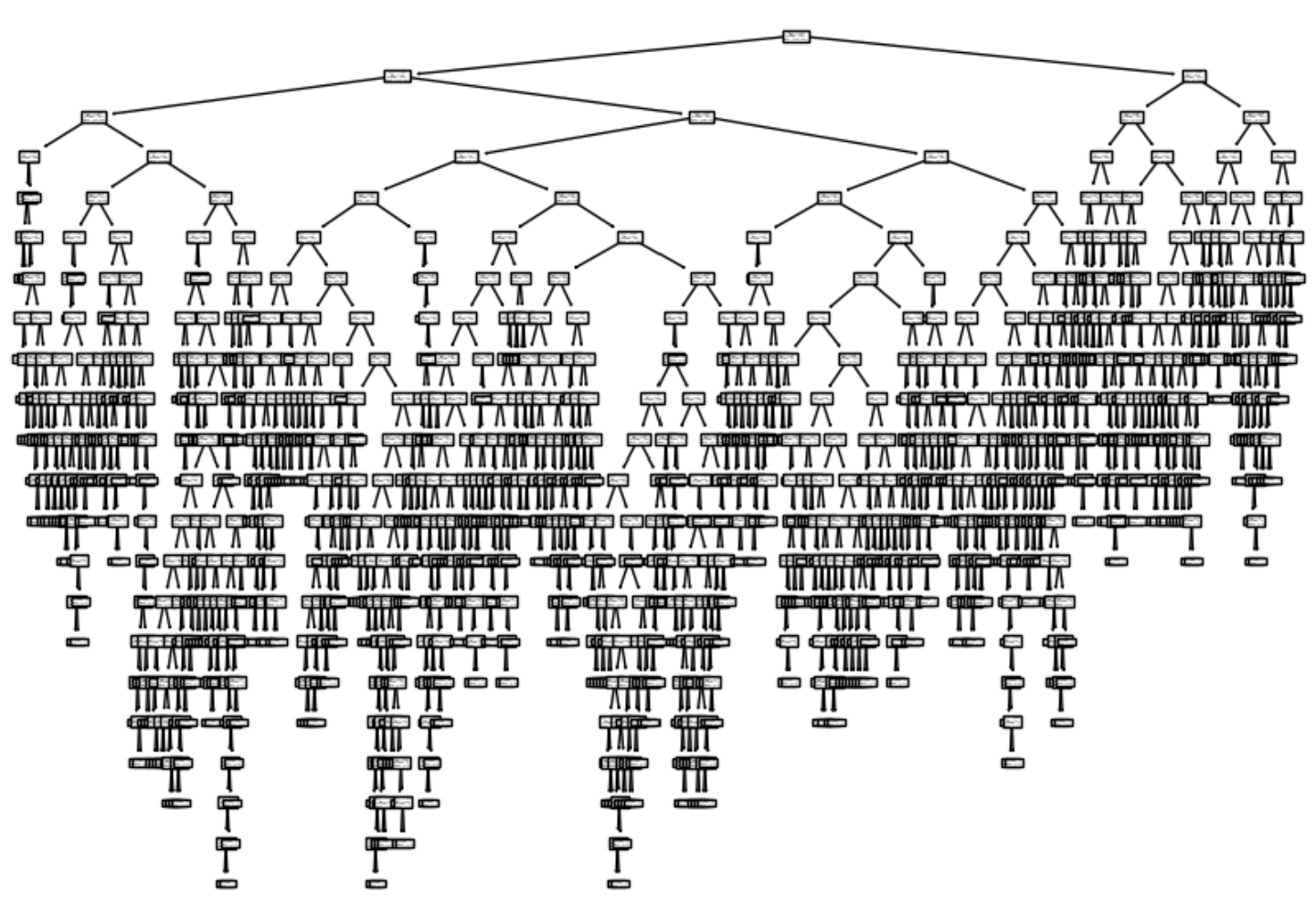
너무 복잡해서 결정 트리를 제대로 알아볼 수가 없다. 결정 트리를 알아보기 쉬우려면 아래의 매개변수를 plot_tree() 메서드에 전달해야 한다.
- max_depth: 설정된 깊이까지만 트리를 출력한다. 참고로, 트리의 깊이는 0부터 시작한다.
- filled: 노드를 구분하기 쉽도록 배경색을 칠한다.
- feature_names: x[n] 형태로 표시되는 특성의 레이블을 지정한다.
plot_tree(dt, max_depth=1, filled=True, feature_names=['alchol', 'sugar', 'pH'])
plt.show()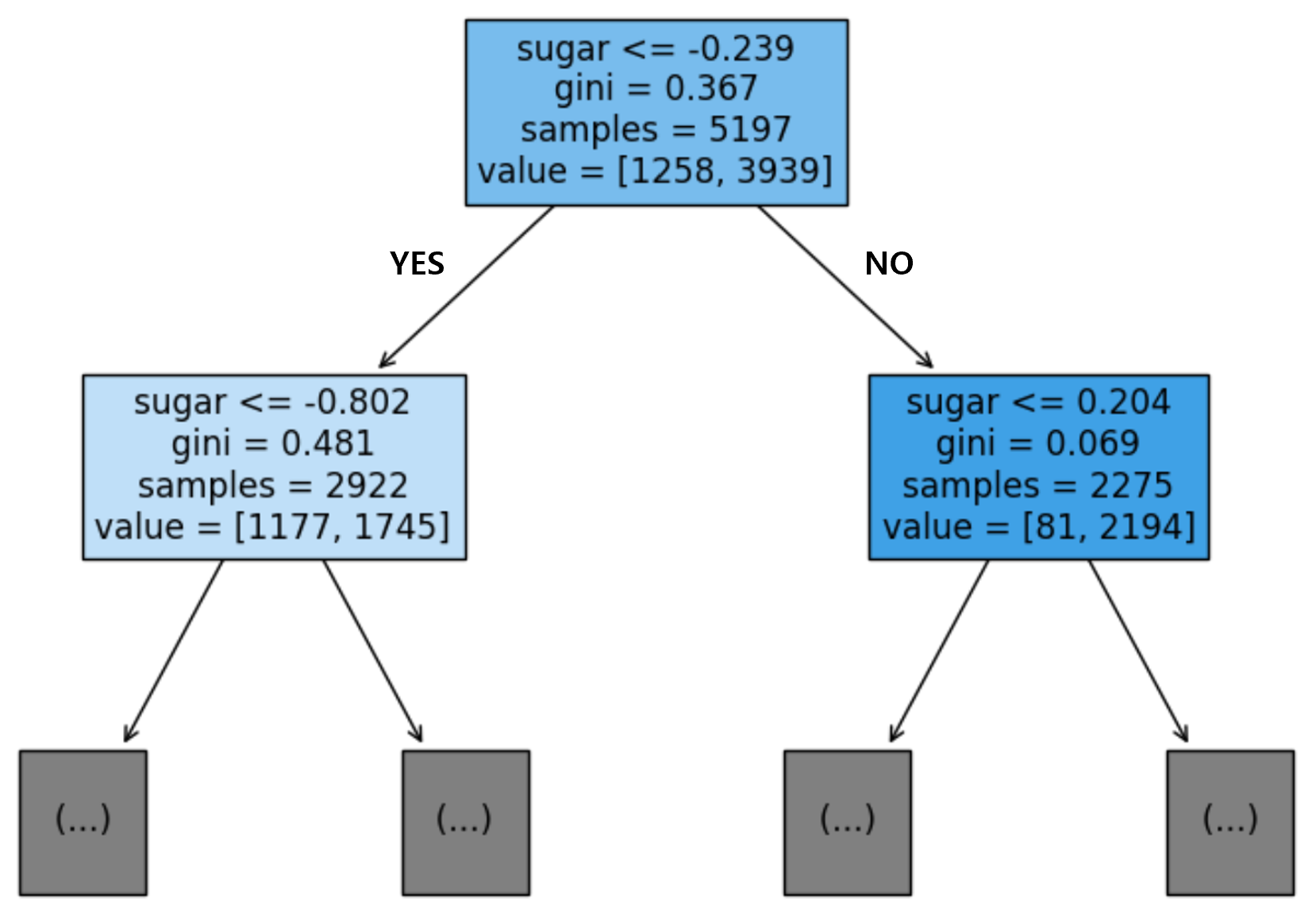
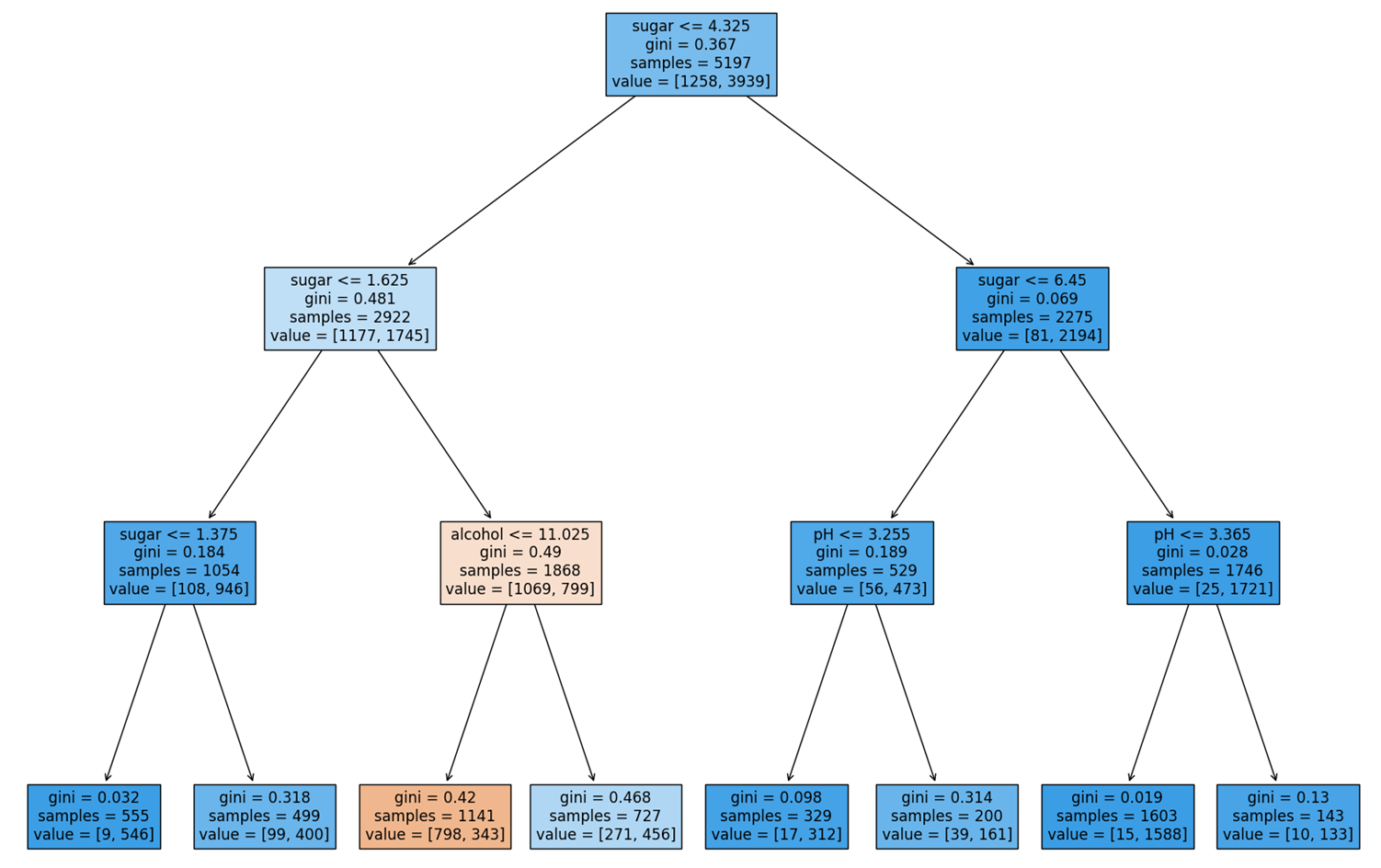
당도가 0.239 이하인지 여부를 통해 왼쪽 가지와 오른쪽 가지로 분기된다. 결정 트리에서 왼쪽 가지는 Yes, 오른쪽 가지는 No를 의미한다. 또한, samples는 각 노드에 할당된 Sample의 개수를 의미하며, value는 samples 중 [음성 클래스, 양성 클래스]의 개수를 의미한다.
위 그림에서 NO에 해당하는 노드를 보면, 양성 클래스의 비율이 크게 증가했음을 알 수 있으며, 노드의 배경색이 진해진 것을 확인할 수 있다. 이처럼 filled 매개변수를 True로 지정하면, 특정 클래스의 비율이 높아질수록 배경색이 점점 진해진다.
Decision Tree에서 예측을 수행하는 과정은 매우 간단하다. 여러 개의 질문을 통해 어떤 Sample X가 리프 노드에 도달했을 때, 그 리프 노드에서 더 높은 비율을 가진 클래스로 X를 분류하는 것이다.
그런데, 아직 설명하지 않은 것이 하나 있다. 바로 결정 트리의 노드에 있는 gini라는 값이다. 과연 이 값은 무엇을 의미하는 것일까?
2) Gini Impurity
gini는 Gini Impurity(지니 불순도)를 의미하는 것으로, DecisionTreeClassifier의 criterion 매개 변수의 기본 값이다. 여기서 criterion 매개 변수는 데이터를 분할하는 기준을 지정하는 역할을 수행한다. 즉, 위 결정 트리의 루트 노드에서 사용된 "sugar <= -0.239"라는 기준이 바로 지니 불순도에 의해 계산된 값이라는 것이다. 이 때, 지니 불순도는 아래와 같은 방법으로 계산된다.

위 수식을 이용해 루트 노드의 gini 값을 계산해보면, gini = 1 - {(1258 / 5197)² + (3939/5197)} = 0.367이 나오는 것을 확인할 수 있다. 당연한 이야기겠지만, 결정 트리는 한번의 질문으로 불순도를 최대한 낮출 수 있는 질문을 선택해야 한다.
실제로 어떤 질문을 수행했음에도, 두 클래스의 비율이 여전히 비슷하다면 지니 불순도는 최악의 값인 0.5에 가까워진다. (이진 분류에서 지니 불순도의 최대 값이 0.5이다.) 반면, 어떤 질문을 통해 완벽하게 분류를 수행했다면, 해당 노드는 지니 불순도가 0인 순수 노드가 된다.
결정 트리는 부모 노드와 자식 노드 간의 불순도 차이가 최대화되도록 트리를 성장시키는데, 이 때의 불순도 차이를 Inforamtion Gain(정보 이득)이라고 부른다. 정리하자면, 위 결정 트리는 지니 불순도를 기준으로 계산된 정보 이득이 최대가 되도록 노드를 분할한 것이다.
사실 지니 불순도뿐 아니라 criterion을 'entropy'로 지정하여 엔트로피 불순도를 사용할 수도 있다. 엔트로피 불순도는 밑이 2인 로그를 사용하는 방식인데, 대부분의 경우 지니 불순도와 엔트로피 불순도의 차이가 크지 않기 때문에 여기서도 지니 불순도를 계속해서 사용하기로 하겠다.
3. 결정 트리의 과대 적합 해결하기
설명이 길어졌는데, 다시 본론으로 돌아와서 결정 트리의 과대 적합 문제를 해결하는 방법에 대해 알아보기로 하자. 위 모델에서 과대 적합이 발생한 이유는 결정 트리의 최대 깊이 제한을 설정하지 않았기 때문이다.
당연히 트리가 매우 깊어지면, 훈련 Set의 모든 데이터를 완벽하게 분류할 수 있게 되므로, 훈련 Set에서의 성능이 매우 높게 평가될 것이다. 그러나, 이로 인해 훈련 Set에 너무 특화된 트리가 형성되다보니 테스트 Set에서의 성능이 크게 저하되었다.
따라서, 결정 트리의 최대 깊이 제한을 3으로 지정한 후 다시 모델의 성능을 평가해보기로 하자.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))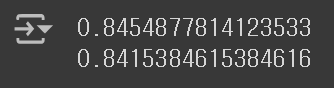
트리의 최대 깊이를 제한함으로써, 훈련 Set에 너무 특화된 트리가 만들어지는 문제가 해결되었다. 결정 트리가 어떻게 구성되었는지 확인해보자.
plt.figure(figsize=(20, 15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()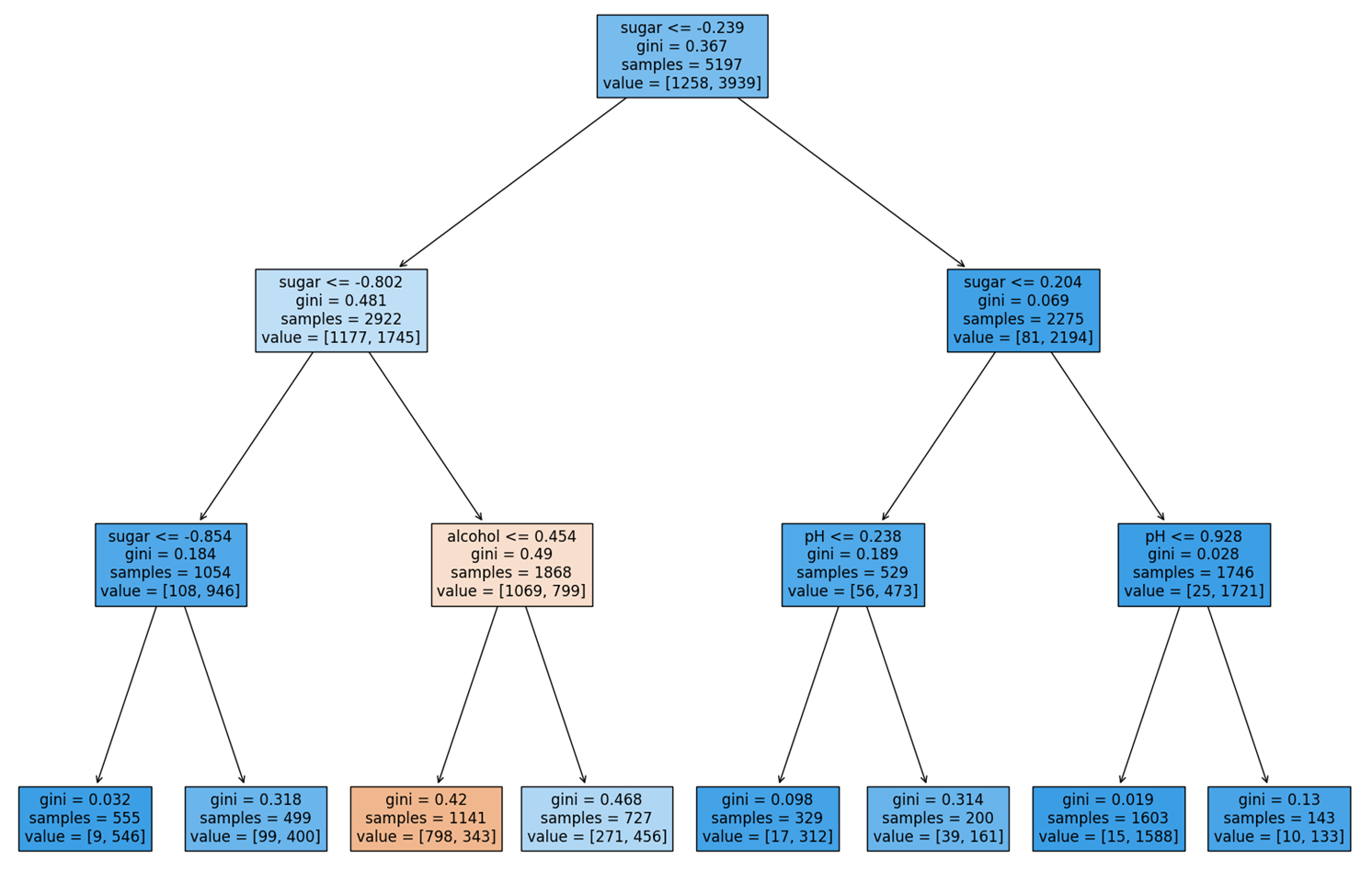
Sample이 어떠한 과정을 통해 분류되었는지를, 훨씬 더 명확하게 이해할 수 있게 되었다. 그런데 아직도 문제가 남아있다. 표준화 된 알코올 도수, 당도, pH 값으로 인해 여전히 처음 보는 사람이 이해하기 어렵다는 것이다.
4. 결정 트리 알고리즘의 장점
1) 특성 스케일에 무관한 알고리즘
사실, 결정 트리 알고리즘에서 사용되는 특성 값은 전처리가 필요하지 않다. 즉, 원래의 데이터를 가지고 바로 결정 트리를 생성할 수 있다는 것이다.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
전처리 수행 여부와 무관하게 동일한 점수가 나오는 것을 통해, 특성 데이터의 스케일은 결정 트리에 아무런 영향을 미치지 못한다는 것을 알 수 있다. 전처리를 수행하지 않은 데이터를 이용해 결정 트리를 다시 그려보자.
plt.figure(figsize=(20, 15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()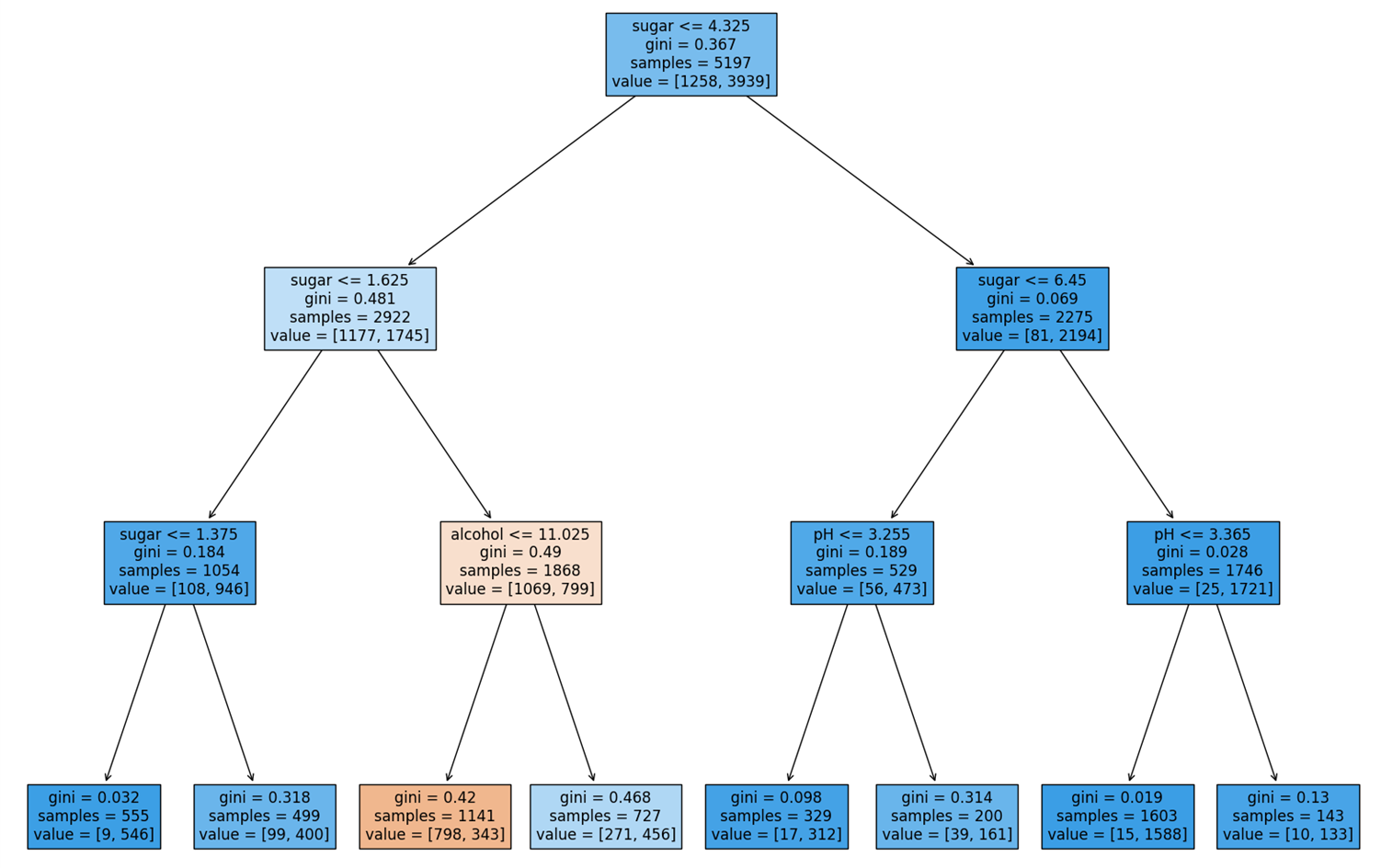
위 트리를 해석해보면, 당도가 1.625보다 크고 4.325보다 작으면서 알코올 도수가 11.025 이하이면 레드 와인으로, 나머지는 화이트 와인으로 분류된다. 이처럼 결정 트리는 누구나 쉽게 이해할 수 있는 분류 모델을 만드는 데에 매우 유리하다.
2) 특성 중요도 계산
DecisionTreeClassifier는 또한 특성의 중요도를 계산하는 기능도 제공한다. 아무래도 루트 노드에 사용된 당도가 가장 중요한 특성일 것 같은데, 실제로 그러한지 확인해보자.
print(dt.feature_importances_) # [0.12345626 0.86862934 0.0079144 ] 출력예상대로, 두번째 특성인 당도의 중요도가 가장 높고, 그 다음으로 알코올 도수, pH의 순이다. 특성 중요도를 사용하면, 중요한 특성을 파악하거나 불필요한 특성을 제거하는 데에 많은 도움을 받을 수 있다.
