1. KNN 회귀 분석의 한계
지난 시간에 만든 KNN 회귀 모델을 이용하여 길이가 50cm인 농어의 무게를 예측해보자.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
knr = KNeighborsRegressor(n_neighbors = 3)
knr.fit(train_input, train_target)
knr.predict([[50]])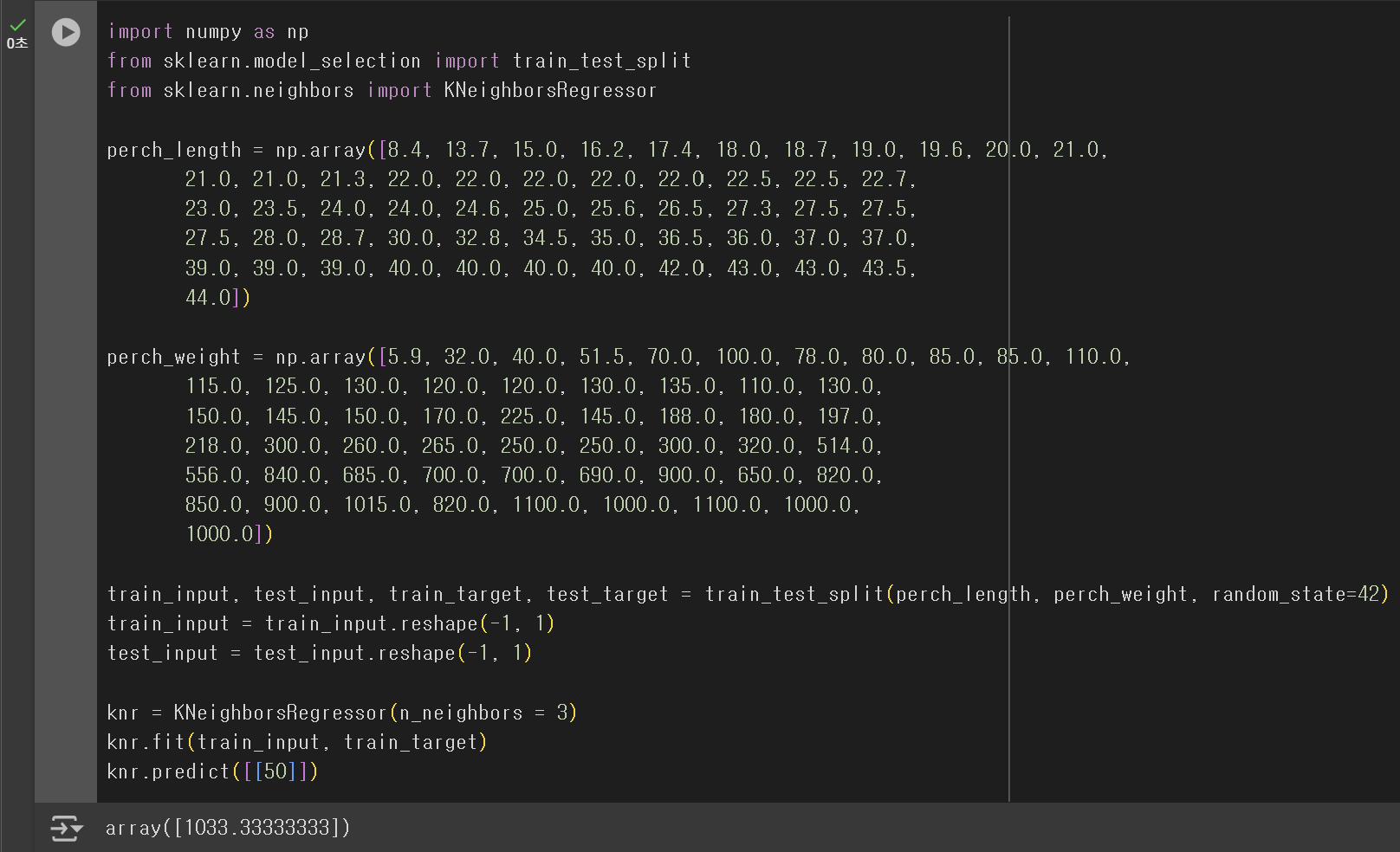
KNN 회귀 모델은 50cm 농어의 무게를 약 1033g으로 예측하였다. 과연 이 예측이 충분히 합리적일까? 이 모델이 어떠한 근거로 1033g이라는 결과를 도출했는지 알아보기 위해 Scatter Flot을 그려보기로 한다.
import matplotlib.pyplot as plt
...
# 새로운 농어 데이터의 최근접 이웃
distances, indexes = knr.kneighbors([[50]])
plt.scatter(train_input, train_target) # 훈련 Set
plt.scatter(train_input[indexes], train_target[indexes], marker='D') # 최근접 이웃
plt.scatter(50, 1033, marker="^") # 새로운 농어 데이터
plt.xlabel('length')
plt.ylabel('weight')
plt.show()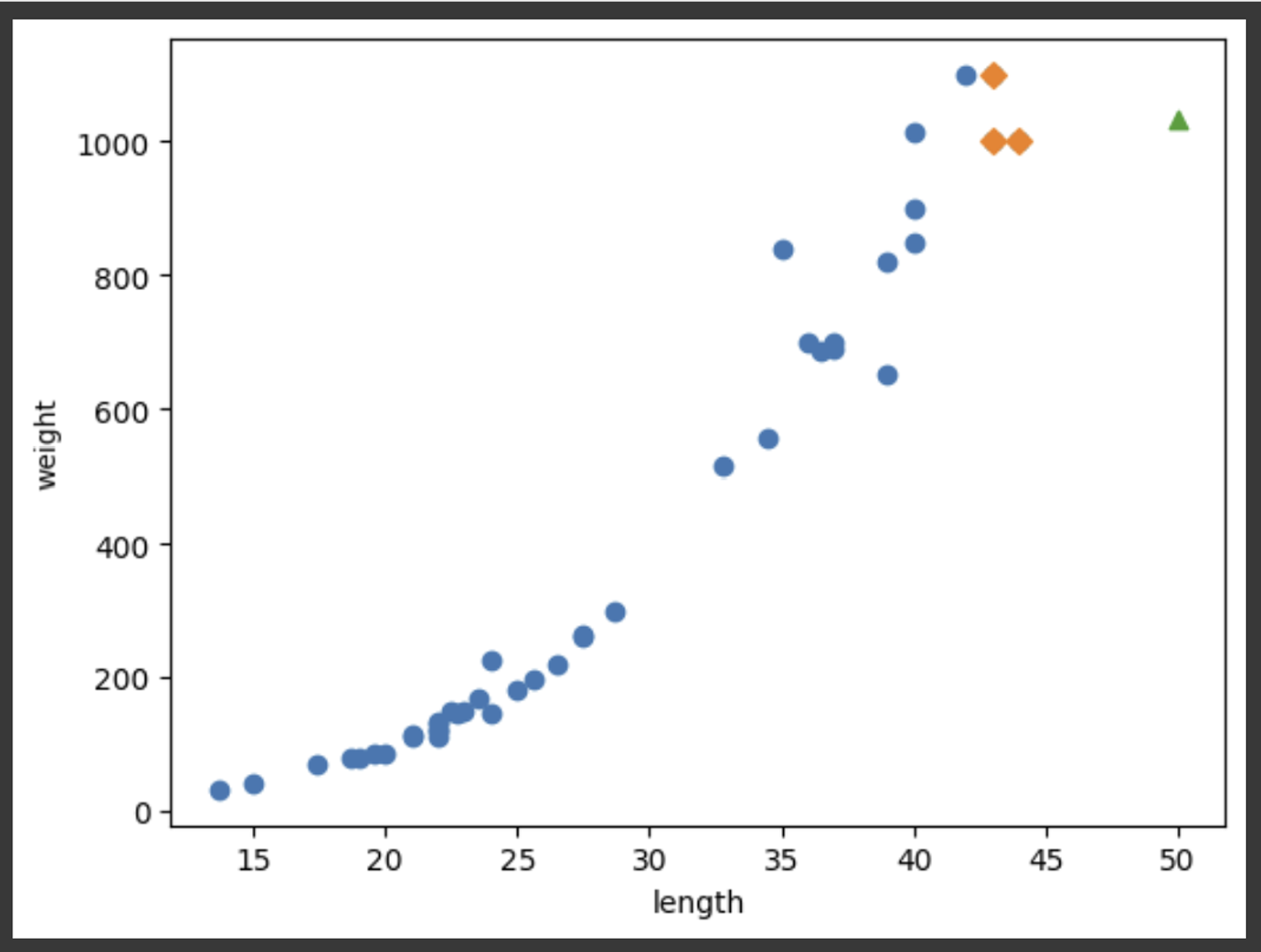
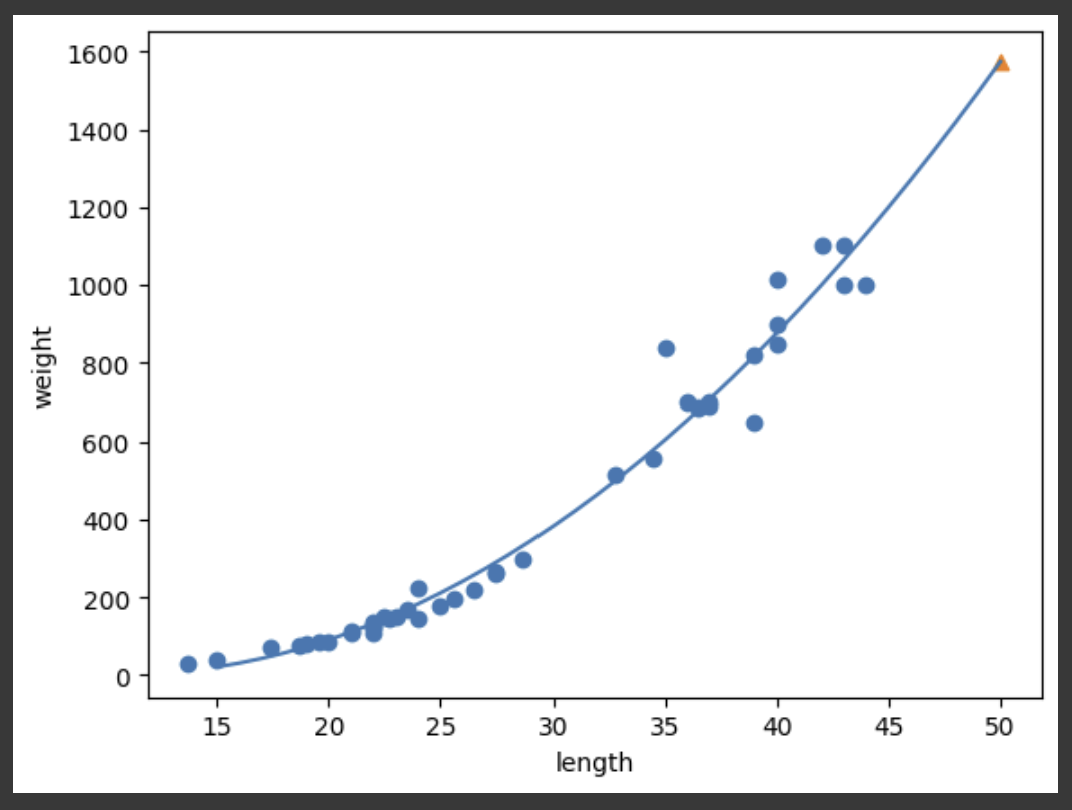
산점도를 그려보니, 이 예측은 별로 합리적이지 않다는 것을 확인할 수 있다. 단순히 새로운 데이터와 길이가 가장 비슷한 3개의 Sample에서 무게의 평균을 구했을 뿐이다. 만약 농어의 길이가 50cm가 아니라, 100cm 또는 200cm였다하더라도, 이 모델은 농어의 무게를 동일한 1033g으로 예측할 것이다.
즉, KNN 회귀 모델은 새로운 데이터가 훈련 Set의 범위를 벗어날 때, 유효한 예측을 해낼 수 없다. 물론, 훈련 Set에 충분히 큰 길이의 농어를 포함시키면 해결될 수 있는 문제이긴 하지만, 별로 좋은 방법이 아니다. 여기서 좋은 방법이 아니라는 말은, 아래의 두 가지 의미로 해석될 수 있다.
- 충분히 긴 농어 데이터를 훈련 Set에 추가하더라도, 그보다 더 긴 농어 데이터가 나타날 가능성이 여전히 존재한다.
- 우리가 궁극적으로 원하는 모델은 훈련 Set의 범위를 벗어난 데이터가 주어지더라도, 훈련 Set을 기반으로 유효한 예측을 해낼 수 있는 모델이다.
2. Linear Regression
1) 단순 선형 회귀
KNN 회귀 알고리즘의 한계를 해결하기 위해, Linear Regression(선형 회귀) 알고리즘을 사용할 수 있다. Linear Regression은 종속 변수와 하나 이상의 독립 변수 사이의 선형 관계를 학습하는 알고리즘으로, 직관적이면서도 성능이 우수하다는 특징이 있다.
선형 회귀를 사용하기 위해선 sklearn.linear_model 패키지의 LinearRegression 클래스를 import 하면 된다. 사이킷런의 모델 클래스들은 fit(), score(), predict() 메서드를 공통으로 갖고 있기 때문에, 기존에 훈련, 평가, 예측에 사용하던 방식을 그대로 사용하면 된다.
from sklearn.linear_model import LinearRegression
...
lr = LinearRegression()
lr.fit(train_input, train_target)
lr.predict([[50]])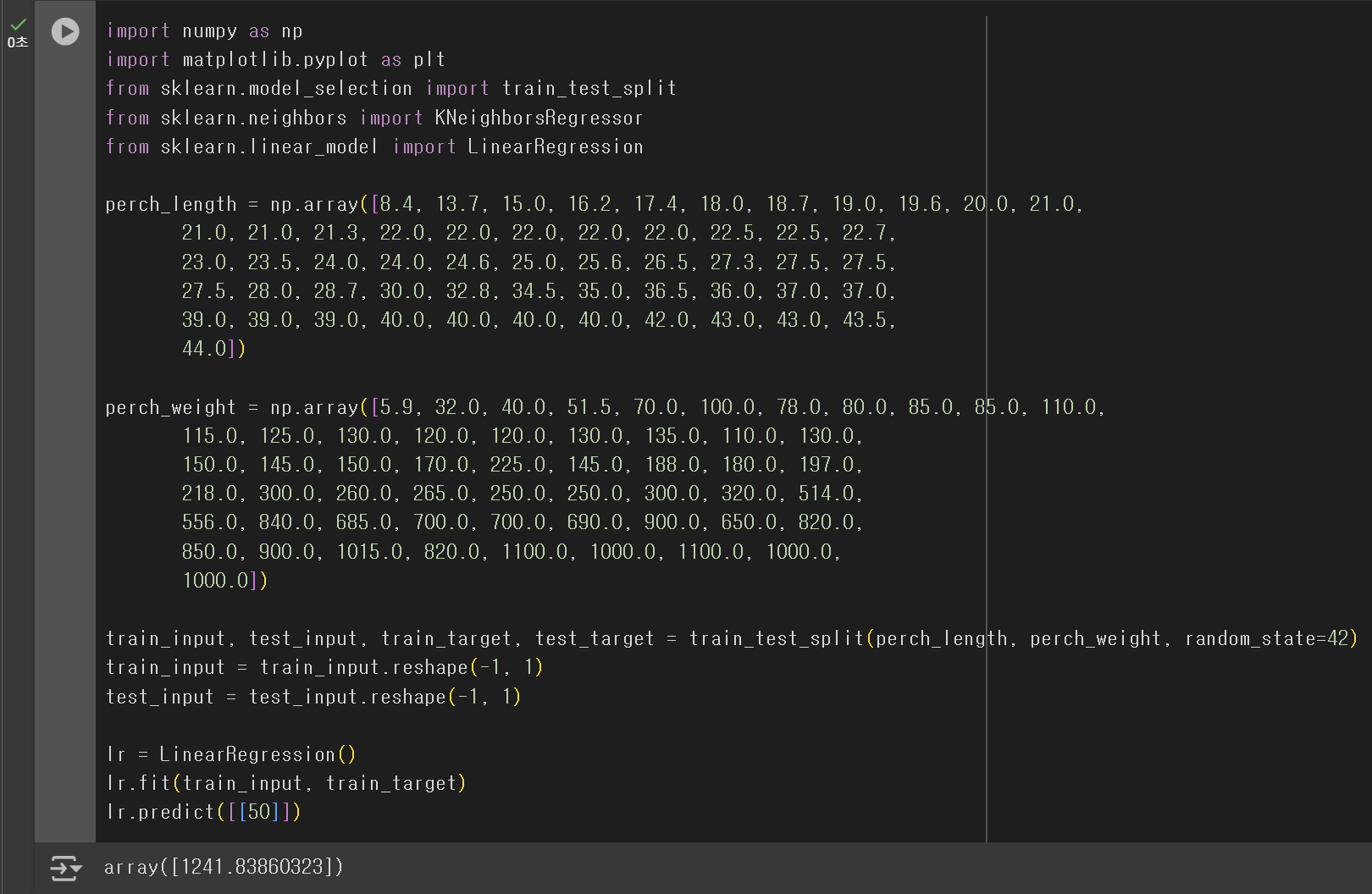
KNN 회귀 분석 결과보다 높은 값을 예측했음을 확인할 수 있다. 그런데, 이 값은 어떻게 계산된 것일까? 선형 회귀는 직선을 학습하기 때문에, 직선을 구성하기 위한 기울기(coefficient)와 y-절편(intercept) 값이 필요하다. 이 값은 LinearRegression 클래스에 의해 계산되며, 계산된 값을 확인하는 방법은 아래와 같다.
print(lr.coef_, lr.intercept_) # [39.01714496] -709.0186449535477 출력아마 이 직선을 그려보면, 선형 회귀 모델이 예측한 결과가 어떻게 계산된 것인지 알아낼 수 있을 것 같다. x의 범위를 [15, 50]으로 두면, 대응되는 y 값은 [15 39 - 709, 50 39 - 709]로 계산되므로, 이 두 점을 이어 직선을 그려보자. 참고로, 두 점을 연결한 직선을 그리는 메서드는 plot()으로, x 좌표의 리스트와 y 좌표의 리스트를 입력 인자로 받는다.
plt.scatter(train_input, train_target) # 훈련 Set
plt.plot([15, 50], [lr.coef_ * 15 + lr.intercept_, lr.coef_ * 50 + lr.intercept_]) # 모델이 학습한 직선
plt.scatter(50, 1241.8, marker="^") # 새로운 농어 데이터
plt.xlabel('length')
plt.ylabel('weight')
plt.show()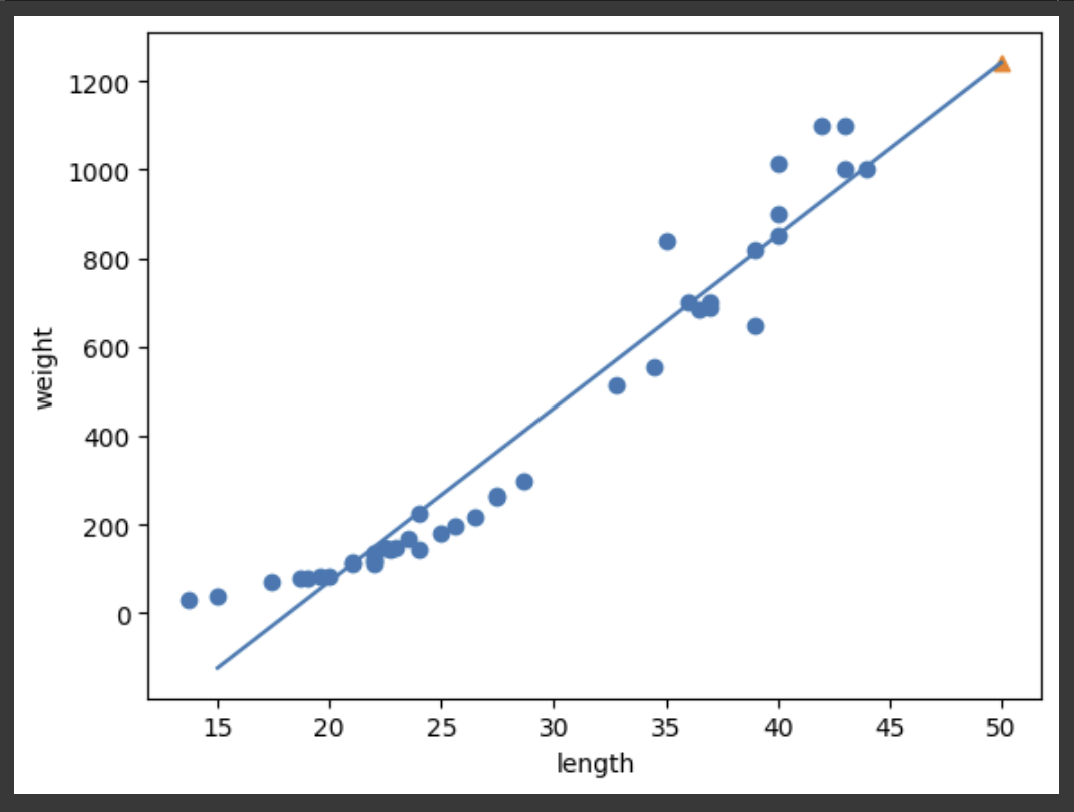
위에 나타난 직선이 선형 회귀 알고리즘이 찾은 최적의 직선이다. 이 직선 덕분에 길이가 50이 넘는 농어의 무게를 예측하는 일이 가능해졌다. 그런데, 아직도 문제가 남아 있다. 그 문제는 바로 농어의 길이가 20보다 낮아질 경우, 무게가 0보다도 낮게 예측한다는 것이다. 실제로 길이가 15cm인 농어의 무게를 예측해보면 음수 값이 출력되는 것을 확인할 수 있다.
lr.predict([[15]]) # array([-123.7614705]) 출력아무래도 곡선 형태의 산점도를 정확히 일진석으로 나타내기에 무리가 있었던 것 같다.
2) 다항 회귀
위 선형 회귀의 문제점을 해결하려면, 최적의 직선이 아닌 최적의 곡선을 찾으면 되는데, 이 때 다항 회귀를 사용한다. 여기서 다항 회귀란, 말 그대로 다항식을 사용한 선형 회귀를 이르는 말이다.
참고로, 다항 회귀는 비선형 구조이지만, 선형 회귀의 한 형태로 분류된다. 그 이유는 적절한 치환을 통해 선형 회귀의 형태로 바꿀 수 있기 때문이다.
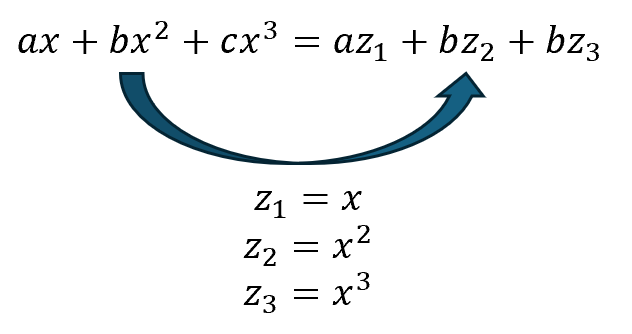
마치, 선형 회귀에서 x에 해당하는 길이 데이터를 이용해 모델을 학습시켰던 것처럼, 다항 회귀에서도 x, x²에 해당하는 길이와 길이² 데이터를 이용해 학습을 진행할 것이다. 그러므로, 길이² 항을 훈련 Set에 추가해주어야 한다.
기존 train_input의 각 데이터를 [train_input², train_input]의 형태로 변환하려면, 지난 시간에 배운 column_stack() 메서드를 사용하면 된다.
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))훈련 데이터가 준비되었으니, 이제 모델을 훈련시킨 후 50cm 농어의 무게를 예측해보자. 이 때, 주의해야 할 것은 predict() 메서드에도 [길이², 길이] 형태로 입력 인자를 전달해야 한다는 것이다.
lr.fit(train_poly, train_target)
lr.predict([[50 ** 2, 50]])
선형 회귀 분석 결과보다도 높은 값을 예측하였다. 이번에도 이 값이 어떻게 계산된 것인지 알아보기로 하자.
print(lr.coef_, lr.intercept_)
# [ 1.01433211 -21.55792498] 116.0502107827827 출력즉, y = 1.01x² − 21.6x + 116.05의 그래프가 다항 회귀 모델이 찾은 최적의 곡선인 것이다. 직접 눈으로 확인해보기 위해 Scatter Flot을 다시 그려보자. 직선이 아닌 곡선을 그려야 할 때에는, 짧은 직선을 연속적으로 이어붙여야 한다. 즉, x의 범위인 [15, 50]까지의 배열을 만들고, 각 원소를 모두 y = 1.01x² − 21.6x + 116.05에 대입하여 plot()에 전달하면 된다.
point = np.arange(15, 51) # 15 ~ 51까지 연속된 배열을 만듦
plt.scatter(train_input, train_target) # 훈련 Set
# point 배열과 pont 배열의 각 원소를 2차 방정식에 대입한 결과를 전달
plt.plot(point, lr.coef_[0] * point ** 2 + lr.coef_[1] * point + lr.intercept_) # 모델이 학습한 곡선
plt.scatter(50, 1574, marker='^') # 새로운 농어 데이터
plt.xlabel('length')
plt.ylabel('weight')
plt.show()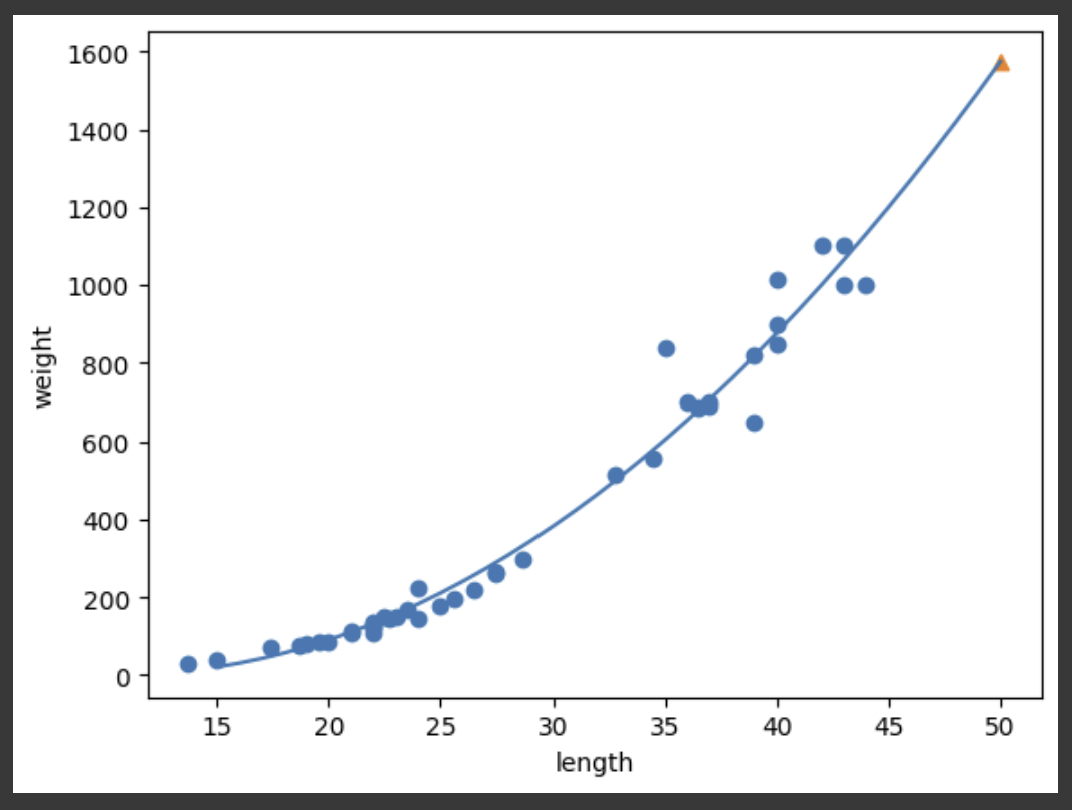
수식이 조금 더 복잡해지긴 했으나, 덕분에 확실히 추세를 더 잘 나타내는 그래프가 그려졌으며, 농어의 무게를 음수로 예측하던 문제도 해결되었다.
3) 성능 비교
단순 선형 회귀 모델과 다항 회귀 모델 중 어떤 모델의 결정 계수가 더 높게 나올까? 당연히 다항 회귀 모델에서의 성능이 더 높게 평가될 것이다.
① 단순 선형 회귀
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))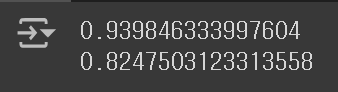
② 다항 선형 회귀
...
lr = LinearRegression()
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))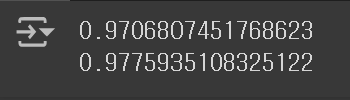
다항 회귀 모델을 사용함으로써, 결정 계수 값이 크게 상승하였음을 확인할 수 있다. 그러나 아직도, 만족할만큼의 높은 점수가 나오지 않고 있다. 이와 같이 훈련 Set과 테스트 Set에서의 점수가 모두 낮은 경우도 과소 적합되었다고 하는데, 이 문제에 대한 해결 방법은 다음 포스팅에서 다뤄보기로 하자.
