1. Binary Classification
머신러닝에서 여러 가지 Class(종류) 중 하나를 구별해 내는 과정을 Classification(분류)이라고 부른다. 특히 그 중에서도 2개의 종류 중 하나를 고르는 가장 기초적인 분류를 Binary Classification(이진 분류)이라고 한다. 이번 포스팅에서는 도미와 빙어를 구분하는 이진 분류 모델을 만들어볼 것이다.
도미와 빙어를 구분하기 위해서는 구별되는 Feature(특징)을 찾아야 한다. 여기서는 이 특징으로 길이와 무게 데이터를 사용할 것이다. 도미와 빙어의 길이 및 무게 데이터 Set이 아래와 같이 주어졌다고 하자.
## 35개의 도미 데이터 ##
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
## 14개의 빙어 데이터 ##
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]이제 이 데이터 셋을 활용하여 도미와 빙어를 이진 분류하는 모델을 만들어보자.
2. Scatter Flot
1) 개념
위에서 주어진 데이터 셋은 다소 정돈되지 않은 느낌을 준다. 이 때, 데이터를 그래프의 형태로 변환하면, 데이터 간의 규칙을 파악하는 일이 보다 용이해질 수 있다.
길이를 x축, 무게를 y축이라 할 때, 각 도미 데이터는 좌표평면의 한 점으로 표시되는데, 바로 이러한 형식의 그래프를 Scatter Flot(산점도)이라 부른다.
파이썬에서 과학계산용 그래프를 그리는 데에 사용하는 대표적인 패키지는 matplotlib이며, 그 중에서도 Scatter Flot을 그릴 때에는 scatter() 메서드를 사용한다. 참고로, Google Colab에는 이미 데이터 분석에 필요한 다양한 패키지가 설치되어 있기 때문에 별도 설치 과정 없이 바로 모듈을 import하여 사용할 수 있다.
2) Scatter Flot 그리기
① 노트북 파일을 생성한 후, 제목을 도미와 빙어로 설정한다.
② 코드 셀에 아래의 코드를 입력한다.
import matplotlib.pyplot as plt
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
plt.scatter(bream_length, bream_weight) # x축, y축 순으로 입력 인자를 전달
plt.xlabel('length') # x축 레이블
plt.ylabel('weight') # y축 레이블
plt.show() # 그래프를 화면에 표시pyplot은matplotlib의 하위 모듈로 선 그래프, 막대 그래프, 히스토그램, 산점도 등을 그리는 데에 사용된다.- import ... as는 패키지 명을 단순화하기 위해 사용하는 것이며, plt뿐 아니라 대부분의 패키지에는 이미 널리 사용되는 줄임말이 존재한다.
③ 코드를 실행하면, 아래와 같이 Scatter Flot이 그려진다.
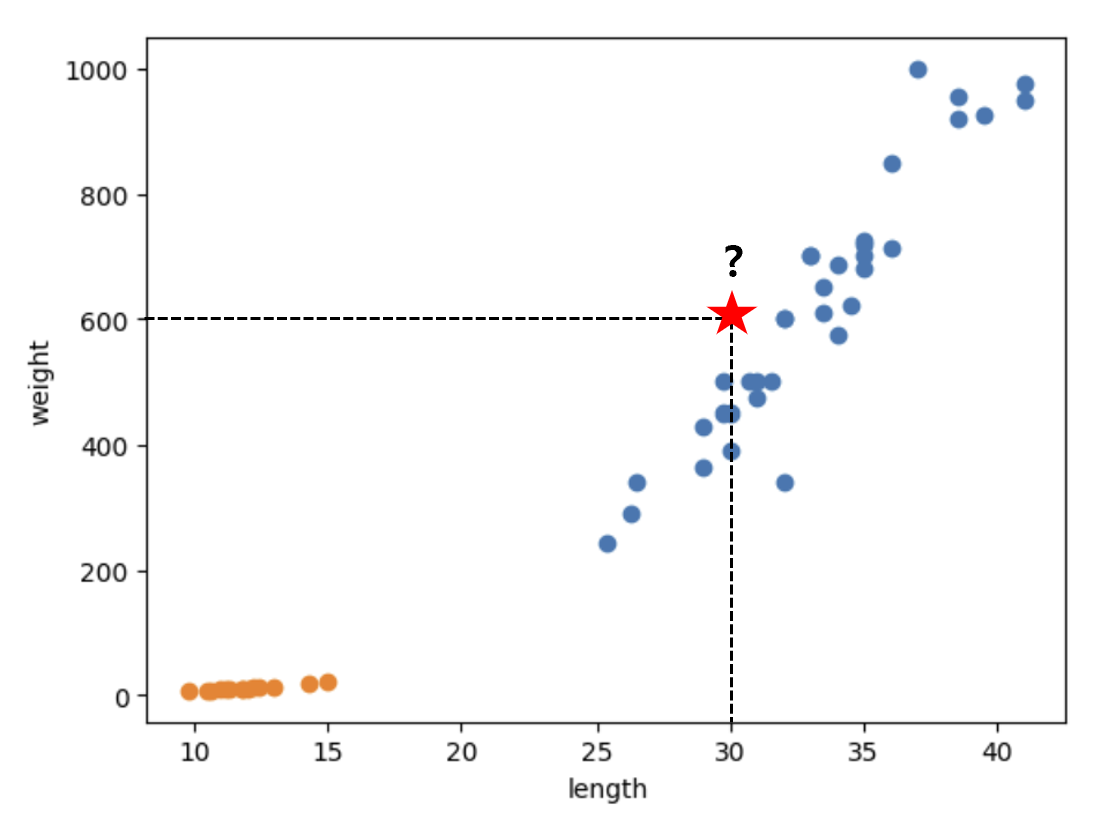
- 생선의 길이가 길수록 무게가 많이 나간다는 규칙성을 한눈에 파악할 수 있게 되었다.
- 산점도가 일직선에 가까운 형태로 나타나는 경우, x와 y가 선형 관계에 놓여있다고 말한다.
④ 위에서 배운 방식을 그대로 사용하여 이번에는 빙어 데이터의 산점도를 그려보자.
scatter()함수를 연달아 사용하여, 하나의 그래프 안에 2개의 산점도를 나타낼 수 있다.
import matplotlib.pyplot as plt
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show() ⑤ 코드를 실행하면, 아래와 같이 Scatter Flot이 그려질 것이다.
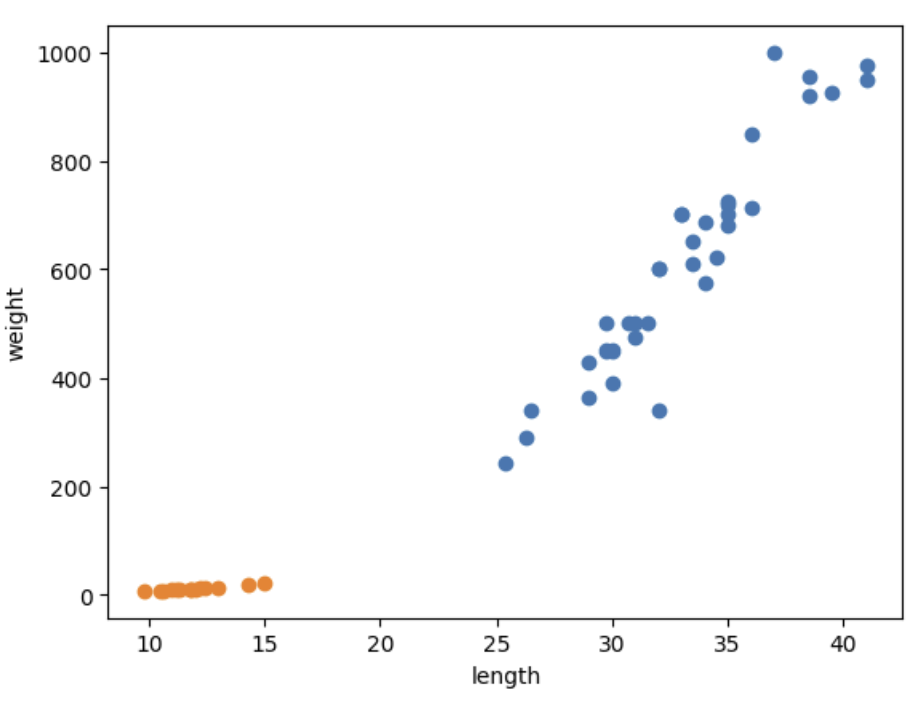
Scatter Flot을 그려봄으로써, 아래와 같은 대략적인 규칙성을 파악할 수 있게 되었다.
- 도미와 빙어 모두 길이와 무게가 비례하는(선형 관계에 놓인) 양상을 보인다.
- 도미에 비해 빙어의 무게는 길이의 영향을 적게 받는다.
3. 이진 분류 모델 만들기
도미와 빙어를 구분하기 위해 K-Nearest Neighbors(KNN) 알고리즘을 사용할 것이다. KNN 알고리즘은 가장 가까운 K개의 이웃을 참조하여 다수결로 분류를 결정하는 방법으로, 간단하고 직관성이 높다.
1) 사전 작업
도미와 빙어를 구분하기 위해서는 주어진 리스트에서 어떤 것이 도미이고, 어떤 것이 빙어인지 알려주는 훈련 과정이 필요하다. 여기서는 훈련을 위해 scikit-learn 패키지에서 제공하는 KNeighborsClassifier의 fit() 멤버 함수를 사용할 것이다. fit() 메서드의 입력인자는 아래와 같다.
- 훈련 데이터
- 2차원 배열이다.
- 각 행은 하나의 Sample(개체)이며, 각 열은 하나의 개체에 포함된 여러 개의 Features 중 하나가 된다.
- 정답 데이터: 훈련 데이터에 대응하는 정답 데이터의 집합
따라서, 주어진 데이터 셋을 2차원 배열로 변환하는 작업이 선행되어야 한다.
① 길이와 무게 데이터 합치기
- length와 weight를 열로 갖는 2차원 배열을 생성하기 위해 먼저는 도미와 빙어의 length와 weight 리스트를 하나로 병합해야 한다.
length = bream_length + smelt_length
weight = bream_weight + smelt_weight② zip() 메서드와 List Comprehension을 이용하여, 2차원 배열로 변환한다.
zip()은 인자로 전달 받은 각 리스트에서 원소를 하나씩 꺼내어 튜플 형태로 반환하는 메서드이다.
fish_data = [[l, w] for l, w in zip(length, weight)]③ 마지막으로, 훈련 데이터에 대응되는 정답 데이터의 집합을 만들어주어야 한다.
- 이진 분류에서는 찾으려는 대상을 1로, 그 외의 대상을 0으로 놓는 것이 일반적이다.
fish_target = [1] * 35 + [0] * 142) 분류 모델 학습시키기
① 코드 셀에 아래의 내용을 입력한다.
- 결과적으로 kn 객체에 학습된 모델이 할당된다.
from sklearn.neighbors import KNeighborsClassifier
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
fish_data = [[l, w] for l, w in zip(length, weight)]
fish_target = [1] * 35 + [0] * 14
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target) ② kn이 얼마나 잘 훈련되었는지 평가해보기 위해 score() 메서드를 사용할 수 있다. score() 메서드는 입력 데이터에 대해 모델이 예측한 결과와 실제 정답 데이터가 일치하는 비율을 0 ~ 1 사이의 값으로 반환한다.
- 아래의 코드는 훈련 데이터를 그대로 입력 데이터로 전달했을 때, 정답 데이터를 잘 예측하는지 여부를 평가한다.
- 당연히 훈련 데이터와 동일한 데이터를 전달하고 있으므로, 1이 나올 것이다.
kn.score(fish_data, fish_target) # 1.0 출력3) 도미와 빙어 분류하기
길이가 30이고 무게가 600인 생선이 있다고 할 때, 이 생선이 도미인지 빙어인지 분류해보자.
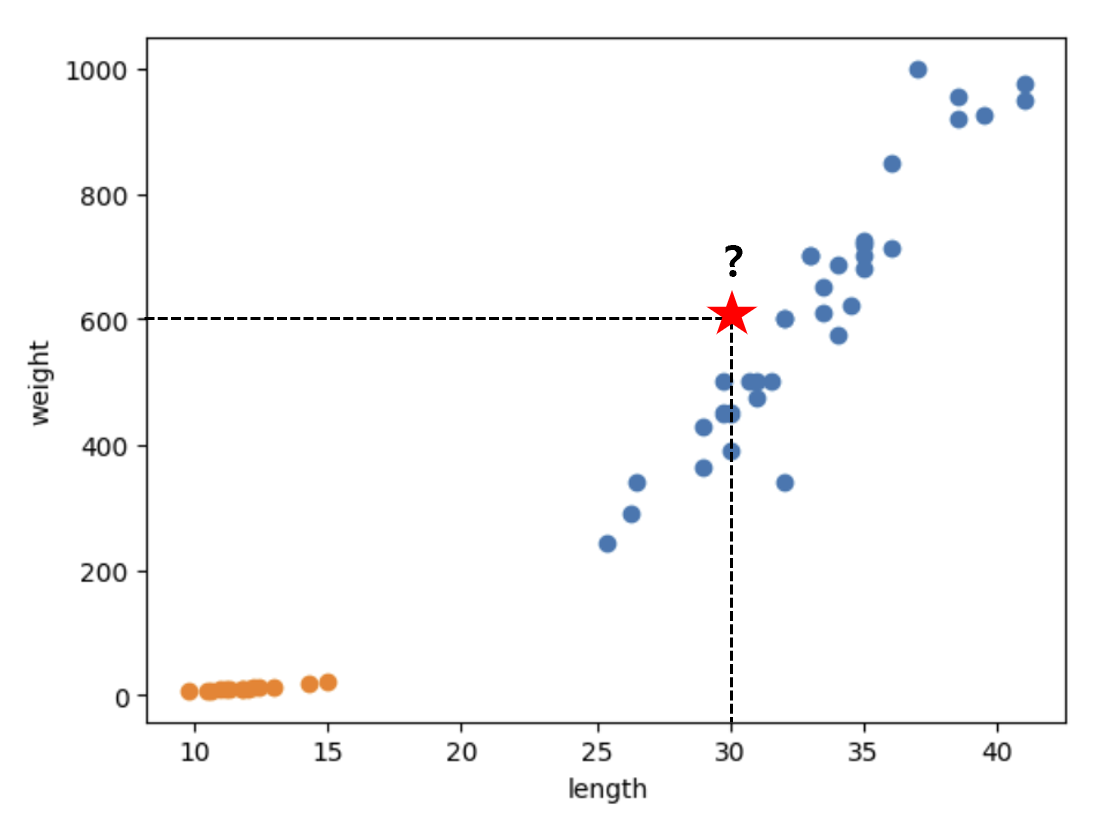
분류 모델이 주어진 입력 데이터에 대해 예측한 값을 반환하게 하는 predict() 메서드를 사용하여 이진 분류를 진행할 수 있다. 참고로, predict() 메서드의 매개변수에는 2차원 배열을 전달해야 한다.
kn.predict([[30, 600]]) # array([1]) 출력1이 반환되었으므로, 도미로 예측했다는 사실을 알 수 있다. 참고로, array([1])이 반환된 이유는 predict() 메서드가 Numpy 배열을 반환하기 때문이다.
정확히 말하면, predict() 메서드를 포함한 모든 사이킷 런 모델에서, 일반적인 파이썬 List 대신 Numpy 배열을 사용한다. 여기서 Numpy 배열이 무엇인지는 다음 포스팅에서 자세히 알아보기로 하고, 일단은 넘어가기로 하자.
4. K-Nearest Neighbors 알고리즘에 대한 고찰
1) KNN 알고리즘의 한계
위에서 직접 실습해본 것처럼 KNN 알고리즘은 매우 직관적이고 간단하다는 장점이 있다. 그러나, 처리해야 하는 데이터의 양이 많은 경우에 사용하기에는 부적합한 알고리즘이다. 그 이유는 아래와 같다.
① 높은 공간 복잡도
- KNN 알고리즘을 이용해 분류를 진행하기 위해선, 많은 데이터를 저장해두고 있어야 한다.
- 실제로
print(kn._fit_X)코드를 실행해보면, 입력했던 데이터가 그대로 저장되어 있는 것을 확인할 수 있다.

② 높은 시간 복잡도
- 가까운 데이터 포인트를 찾기 위해선 먼저, 새로운 데이터와 모든 데이터 포인트 사이의 거리를 측정해야 한다.
- 따라서, 이 직선 거리를 계산하는 데에 많은 시간이 소요될 수 밖에 없다.
2) K 값 선정의 중요성
KNN 알고리즘에 사용할 K 값은 생성자 입력을 통해 변경할 수 있으며, 기본 값은 5이다.
kn = KNeighborsClassifier() # 가장 가까운 5개의 데이터를 참고
kn49 = KNeighborsClassifier(49) # 가장 가까운 49개의 데이터를 참고만약 위 실습에서 kn이 아닌 kn49 모델을 사용하면 어떻게 될까? 49개의 데이터 중 무려 35개가 도미이므로, 모든 입력 데이터에 대해 도미로 예측할 것이다.
kn49.fit(fish_data, fish_taget)당연히 이렇게 학습된 kn49 모델의 성능을, 훈련 데이터를 그대로 사용하여 평가해보면 35/49가 출력될 것이다. 이는 모든 데이터를 도미로 예측했다는 의미로, 잘못 선정된 K 값으로 인해 발생한 문제이다.
kn49.score(fish_data, fish_target) # 0.7142857142857143(= 35/49) 출력따라서, KNN 알고리즘을 사용할 때에는, 분류 모델의 정확성을 최대화하는 적절한 K 값을 선택해 사용해야 한다.
