AI : Langchain (RAG)
1.[AI] 1. macos pyenv 환경 설정
https://brew.sh/ko/ 에 가면 확인 가능하다.이걸 안해주면...pyenv-virtualenv: '3.18' is not installed in pyenv.It does not look like a valid Python version. See '
2.[AI] 2. Langchain ChatUpstage 를 이용한 검증

1. langchain-upstage, python-dotenv 설치 2. .env 파일 만들기. 3. 환경변수 로드 4. 랭체인 선언 5. invoke 로 실행
3.[AI] 3. ollama 를 사용하여 모델 사용
https://ollama.com 에 접속하여 Download 버튼 클릭설치 파일을 실행하면 다음과 같은 화면이 표시되는데 NextInstall 버튼 클릭https://ollama.com/search 에서 확인 가능하다.llama2 는 매개변수(파라미
4.[AI] 4. 워드 문서를 학습해보자.
1. docx2txt 다운로드 참고 URL https://python.langchain.com/apireference/community/documentloaders/langchaincommunity.documentloaders.word_document.Docx2txt
5.[AI] 5. RetrievalQA Chain 을 사용해 보자
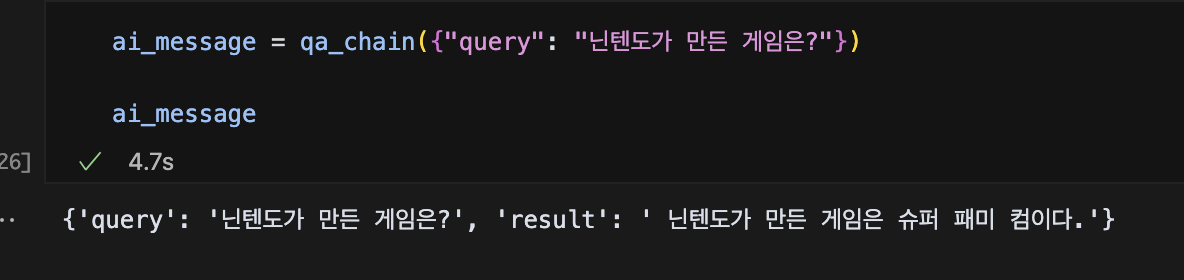
있는 그대로 말하자면 그렇고, 선언된 llm과, Retriever, Prompt 를 묶어서 뭔가 해주겠다는 의미같다. 쪼갠 문서를 벡터 변환하는 모델 선택쪼개진 문서가 벡터로 변환되면 벡터 database 에 저장한다.로컬에 별도 저장하여 재사용 하자. 역시 모델이 구
6.[AI] 6. pinecone 에 vector 를 넣어보자.
이전까지는 문서를 로드하여 쪼갠 후 임베딩한 데이터를 chroma 라는 것을 이용하여 저장 하였는데 이번에는 이 벡터 데이터를 pinecone 이라는 클라우드에 넣어 보겠다.https://app.pinecone.io/ 접속 및 가입가입 직후 Api Key를 복
7.[AI] 7. 구조화된 문서로 테스트해 보자
테스트전 embedding 모델과 llm 모델을 llama3.2:1b 에서 llama3.2:3b 로 변경하였다.인터넷에서 쉽게 입수 가능한 시스템 보안규정 샘플이다. 제x조 > 1,2,3 > ①,② 식의 구조를 가지고 있다.크기는 약 35KB 이고 3페이지 정도의 작은
8.[AI] 8. 질문도 중요하다!

지난번에는 어느정도 구체적인 구조를 가진 문서를 로드하여 테스트해 보았고 문서에 없는 내용 질문 시에 정보가 없다는 대답을 하기도 했다.사실 정확한 대답을 얻기 위해서는 정확한 질문이 중요한데, 이번에는 질문을 튜닝하고, langchain 에 적용해 보도록 한다.제9조
9.[AI] 9. 파이썬으로 구현하면?
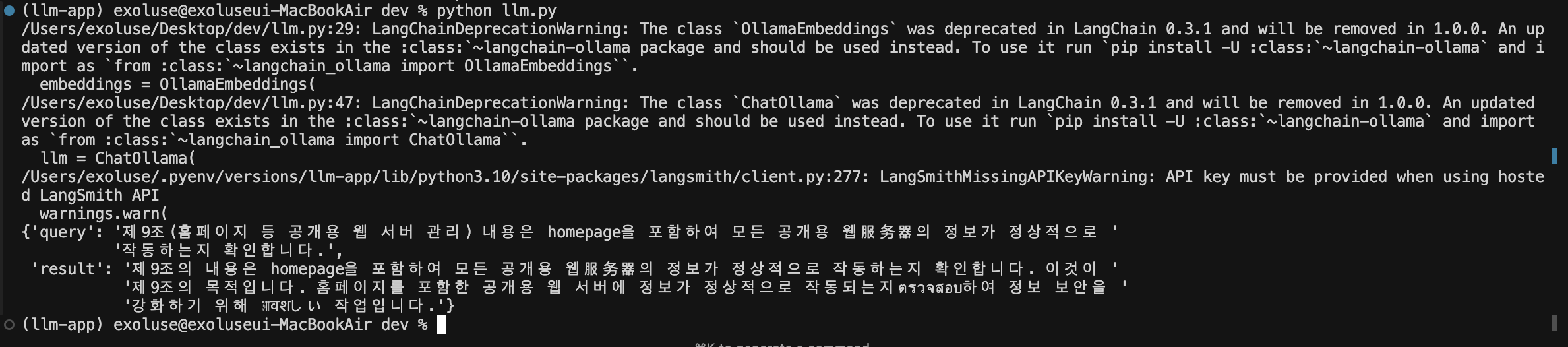
주피터 노트북에 적었던 것을 1개 파일로 모아본다.동작은 뭐... 되긴 한다. 시간이 좀더 걸리는 느낌...
10.[AI] 10. 맥락에 맞는 응답 얻기.

지난번에는 주피터 노트북 작업물을 한데 모아놓고 돌려보았다.그런데 내가 아는 chatgpt 는 채팅하면서 이전 질문을 기억하여 응답을 줬는데 내가 만든건 1회성 질문과 응답일 뿐이었다. 이번에는 맥락을 이해하는 AI를 만들어 보겠다.소스 구석구석에 주석을 달아보았다.
11.[AI] Langchain 복습 - 1

지난 약 2주동안 그냥 계속 뭔가를 만들기만 했지 돌아보는 시간이 없었던거 같아서 며칠 동안은 배운 것을 끄적여 보는 시간을 가지려고 한다.Prompt : 사용자 또는 시스템에서 제공되는 "입력" 으로 LLM에게 특정 작업을 수행하도록 요청하는 지시문.LLM : 대규모
12.[AI] Langchain 복습 - 2
랭체인은 말그대로 체이닝이 중요하다.llm 을 여러번 돌려서 맥락을 연결하여 결과를 뽑는 것을 복습해 보자.꽤 만족스러운 결과가 나왔다.어느것이 좀더 정확한건지... 잘은 모르겠지만... 일단 개소리는 면했다.
13.[AI] Langchain 복습 - 3

한땀한땀 질문해서 얻는것도 좋지만 한번에 여러개의 결과물을 얻고 싶다...invoke 대신에 batch 를 사용하여 굴려보자.같은 주제로 수준별 결과를 내어보았다.뭔가 또 이상한 결과를 내긴 했는데 3가지 수준의 대답을 얻긴 했다.
14.[AI] postgresql 에 vector 데이터 적용
뭔가 또 개소리를 시원하게 날려주고 있다...내가 원했던 데이터는... ㅠㅠ적은 양의 데이터이지만 insert 하는데에 엄청난 시간이 들었는데... (특히 인텔 시스템인 사무실 컴퓨터에서는 30분 정도가 들었다. ) 데이터 수집의 문제인지 할루시네이션이 좀 많이 심한
15.[AI] Langchain 으로 허깅페이스 사용해보자.
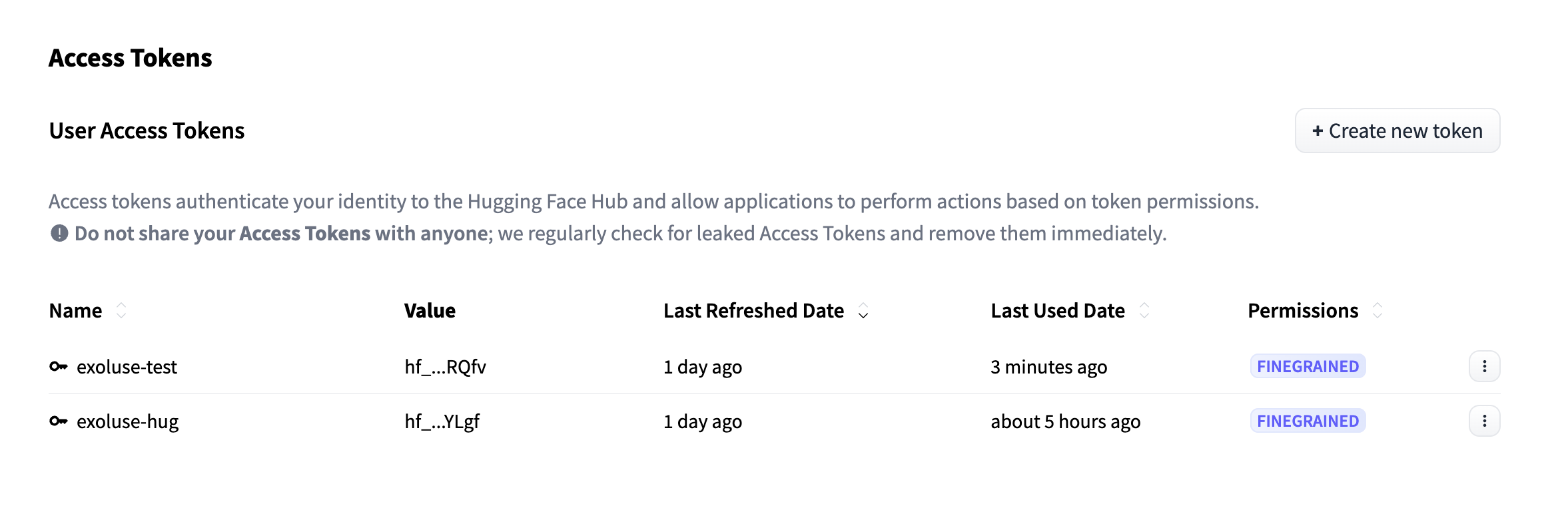
예전에 조금 끄적거렸던... (흔적은 없지만) 허깅페이스가 떠올라 랭체인과 같이 써보면 어떨까 싶어서 급하게(?) 하나 만들어 봤다.https://huggingface.co/settings/tokens 에 접속하면 우측에 +Create New Token 버튼이
16.[AI] 이것저것 버무려보자

모델의 수준 치고는 진짜 만족할만한 결과가 처음으로 나왔다.또다른 질답 결과.llm 이 찾아야만 했던 벡터 데이터의 문자열
17.[AI] Speach To Text - 1

최근(작년말)에 회사에서 STT 관련된 개발을 수행한 바 있다. 그 당시에는 외부 라이브러리를 구매해서 사용했고 성능도 나쁘지 않았던 기억이 있다. 이번에는 허깅페이스의 STT 라이브러리를 사용해서 음원 파일을 읽고 한글로 뽑는 작업을 해 보았다.추가로 필요한 것만 기
18.[AI] langchain + Huggingface + ollama + FAISS 적용해보자

FAISS는 페이스북에서 개발한 대용량 벡터 검색 라이브러리로, 밀집 벡터의 유사도를 빠르게 계산하고 클러스터링하는 데 사용된다. 주로 텍스트, 이미지, 음성 등 비정형 데이터를 벡터 형태로 변환하여 **유사도 기반 검색** 을 수행하는 데 활용된다.
19.[AI] chatgpt 에게 물어본 chromadb vs pgvector vs faiss
🔥 FAISS:최고 성능을 원할 경우. 대규모 벡터 검색 최적화. 단, 별도 인프라 구성 필요 (DB가 아님).🌱 ChromaDB:중간 규모 벡터 검색에 적합. LangChain, RAG 등에 쉽게 통합 가능. 설치 및 사용도 간편.🏢 pgvector:구조화된 S
20.[AI] 파인튜닝과 RAG
AI 파인튜닝 - 실전(영화 소개 문장을 학습)https://velog.io/@exoluse/AI-%ED%8C%8C%EC%9D%B8%ED%8A%9C%EB%8B%9D-%EC%8B%A4%EC%A0%84%EC%98%81%ED%99%94-%EC%86%8C%EA%B0%
21.[AI] 실전 - 음성파일이 보이스피싱인지 판단해보자.
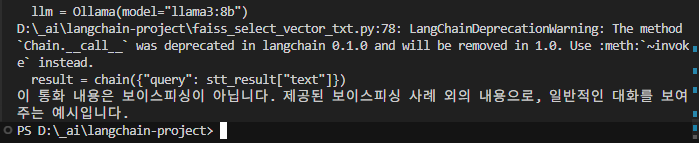
화자분리가 안되어도 좋으니 mp3, ogg, wav 등의 음원이 필요하다.출처 : 다락원 한국어문제가 될 시에는 내리겠다.faiss_index_voice_phishing 폴더에 저장된다.
22.[AI] 5월 13일자 100분 토론 분석기 만들어보자.

내가 막 만든거 아님... 이거 그대로 복사해서 넣었음.2025.05.13 1100회 21대 대선 D-21..표심 흔들 변수는? https://program.imbc.com/BBS/toron?list_id=5464660&list_use=1&page=1&bbs_
23.[AI] Langchain + vision AI(llava) 를 이용한 이미지 설명

배경은 고속도로 이고 사고가 난 모습이다.
24.[AI] Langchain 에 llama.cpp 를 묶어보자.

1. Langchain 너~어는 진짜... LlamaCpp + Langchain https://python.langchain.com/docs/integrations/llms/llamacpp/ 2. 이것저것 테스트... 3.
25.[AI] (대선특집) 각 정당 지지율을 Langchain + selenium + llava + exaone 으로 정리해보자
이 글은 정치적인 의도가 전혀 없음을 알린다! 1. 필요 패키지 설치 2. 크롬 드라이버 설치(macos 기준) 3. pyenv 환경 설정 4. 네이버 이미지 크롤링 이렇게 하면 images21대대선_지지율 디렉토리가 생성되고 그 안에 이미지 검색 최상위 5개가 저장된다. 4-1. 이미지 확인 이렇게 5개가 선정되었다. 3번째 이미지는 21대 총선...
26.[AI] Langchain + RAG 에 Redis 를 붙여보자. (feat. wsl2) - 실패기...
1. Redis Stack 설치 1-1. Redis Stack 웹사이트 일단 Install Redis Stack on Windows 를 선택 https://redis.io/docs/latest/operate/ossandstack/install/archive/insta
27.[AI] Redis 를 Langchain + RAG 에 적용해 봤다.
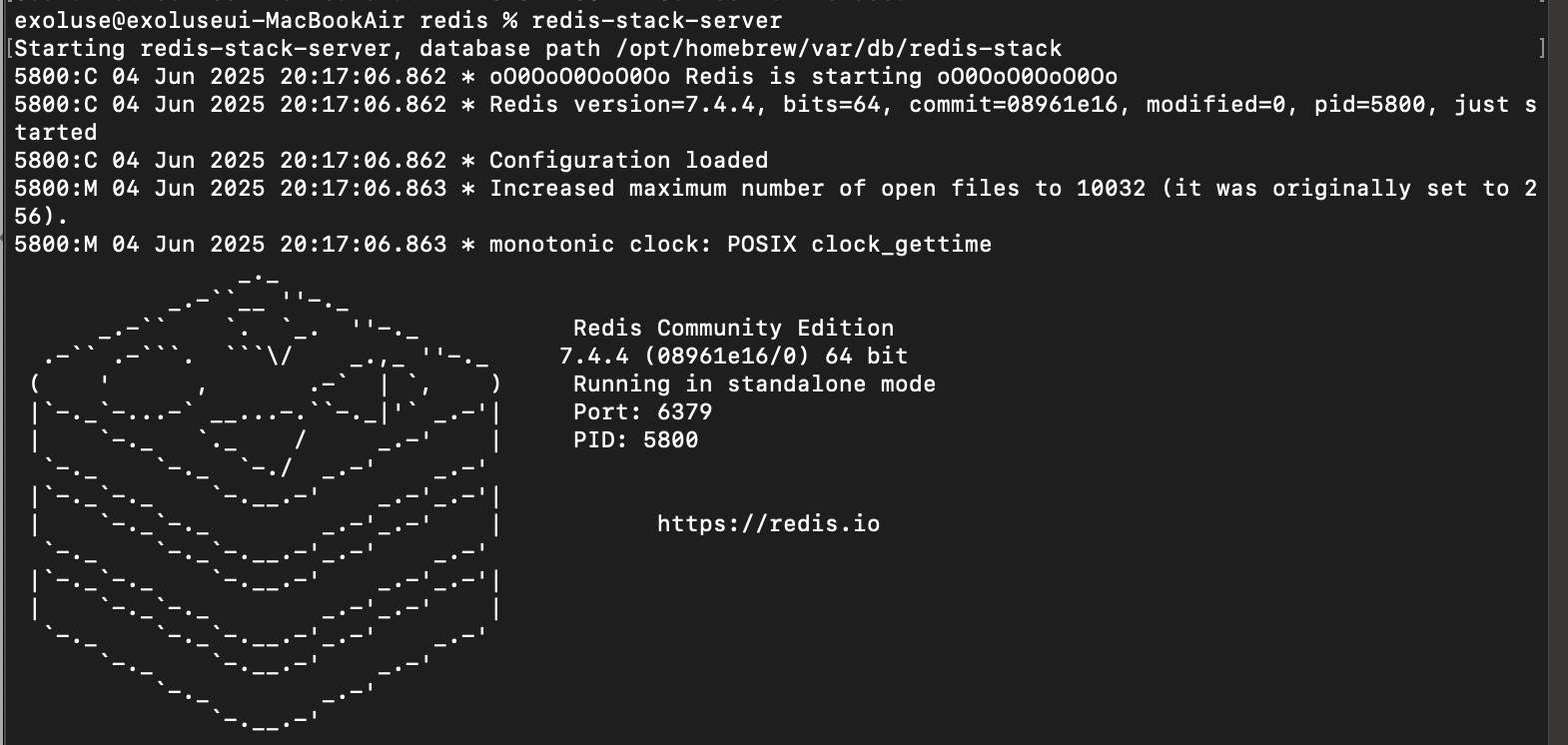
1. Redis Stack 설치 2. redis-stack-server 실행 3. 서버 확인 4. 모듈 확인
28.[AI] llama.cpp + gguf vs ollama
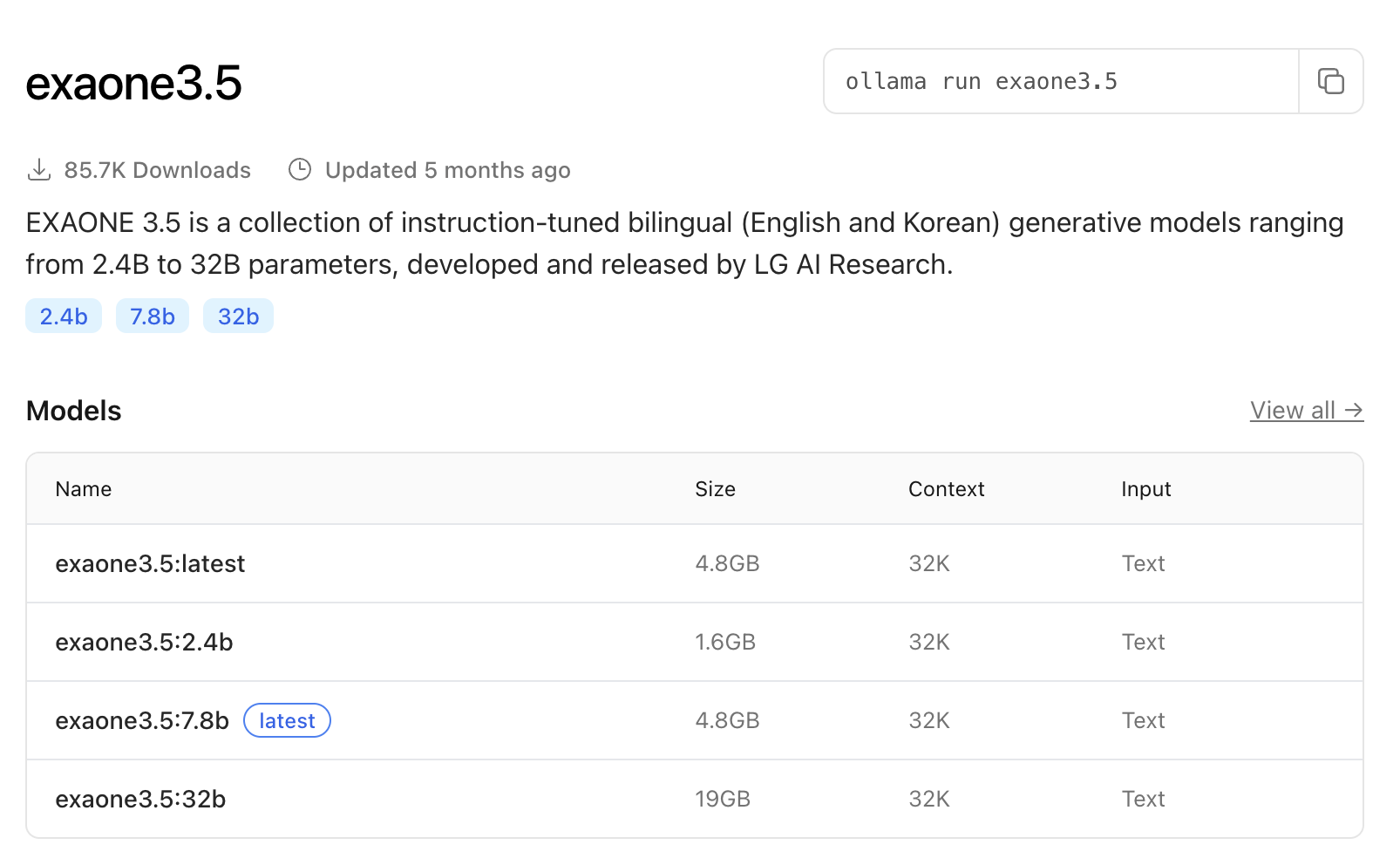
https://ollama.com/library/exaone3.5아키텍쳐 : exaoneparameter : 2.67B quantization : Q4_K_M용량 감소가 Q8 보다는 적은 Q4_K_M 을 선택했다.정확도도 그럭저럭 나오는 옵션이다.You are
29.[AI] RAG 구성시 검색 옵션을 알아보자. (feat. 어린왕자)

직접 검색을 선제적으로 하고 토큰 수 제한 등 전처리를 하고 싶다면, RetrievalQA 구조와 맞지 않아 우회를 해야한다.복잡스럽긴 하지만 뭐... 돌아간다.유사도 검색 상위 10개가 컨텍스트에 포함된다.search_type 가 없으면 similarity 가 기본값
30.[AI] PDF 의 테이블을 모델이 인식하지 못한다고?
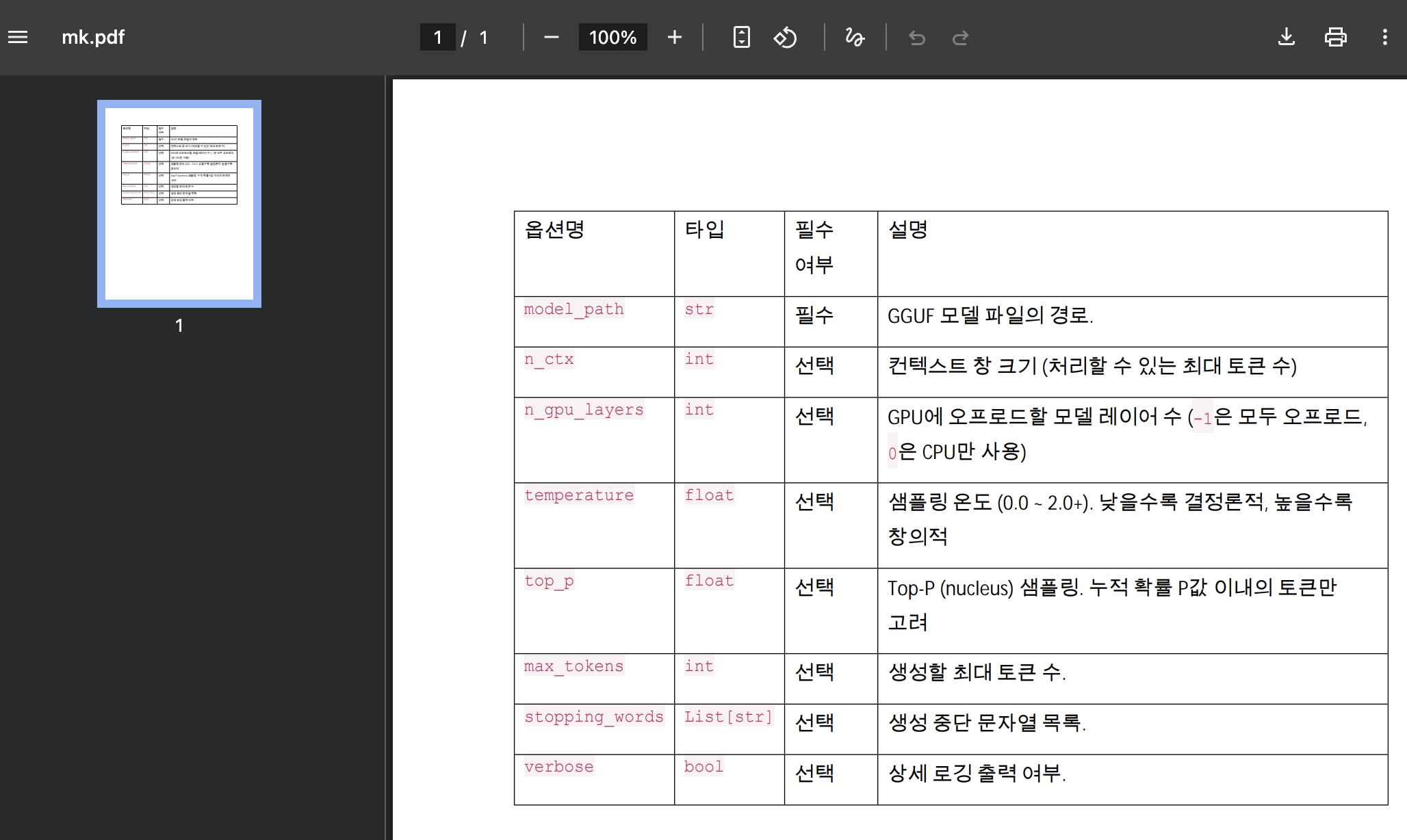
이런식으로 테이블이 들어가있는 문서는 어떨까... 싶어서읽어봤더니 이런식으로 변환되는 거였다.임베딩은 nomic-embed-text, llm은 exaone3.5:2.4b
31.[AI] 알려진 모델들의 프롬프트를 정리해 보자. (정리중)

1. 기본 구성 2. 각 모델별 프롬프트 2-1. llama3 2-2. llama2 2-3. mistral 2-4. vicuna 2-5. openchat 2-6. zephyr 2-7. gpt 2-8. gemma 2-9. claude
32.[AI] FAISS 에 임의의 데이터를 넣고 검색 해보자.

일단 한국어가 되어야 하고(한국어 대응되는 모델 찾기 쉽지 않음...)어느 정도 고차원이 지원되는 모델이어야 한다. jhgan/ko-sbert-sts 너로 결정했다.URL : https://huggingface.co/jhgan/ko-sbert-stsdimens
33.[AI] RetrievalQA is deprecated !!!
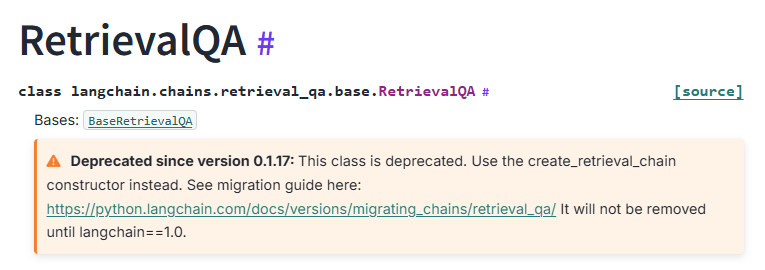
Langchain으로 RAG를 아주 쉽게 구현하게 도와주는 RetrievalQA 가 이제 가신다고 한다... 아주 친절하게도 Langchain 은 그 대안을 제공하는데 그에 맞춰서 구현해 봤다.뭔가 한방에 체이닝 하는 느낌이 아니라 아쉽긴 한데 아예 create_ret
34.[AI] ollama 로 gguf 를 돌린다고?
난 그냥 Q8_0 으로 받을 것이다.exaone3.5-custom:2.4b 으로 만들 것이다.생성완료다른 모델도 양자화 해서 테스트 해봐야겠다.
35.[AI] 블랙웰(50 시리즈) 에서 커널 문제 해결 방안
커널이 없다고 나온다. 계속 해봐도 같은 결과가 나온다.nightly 버전을 찾아내서 적용torch 의 버전이 2.7.1 에서 2.8.0 으로 바뀌었다.모델을 저장하는 과정이 있어서... 좀 걸렸다.
36.[AI] Mariadb 로 RAG 구현해보기
OK전에도 사용한 적이 있는 네이버 뉴스 데이터셋을 써본다.이런 식으로 embedding 컬럼에 벡터 데이터가 쌓이는데 보기엔 바이너리인데 실제론 벡터 데이터가 맞다고 한다.{"category": "IT과학", "title": "나노코리아 2022 나노기술로 지속가능한
37.[AI] Langchain + Mariadb 로 RAG 구현해보자.
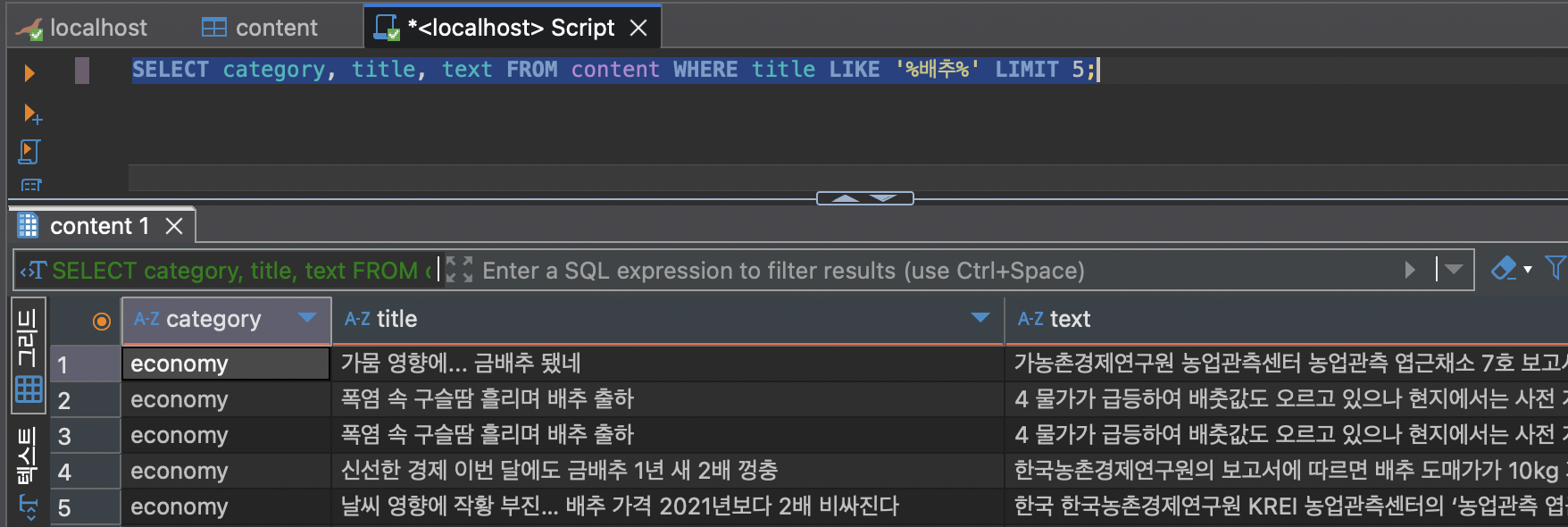
분명 테이블에는 데이터가 있다고...뭔가 이상하다. 내가 설정한 테이블이 아닌 것 같다...chatgpt 의 힘을 빌려 겨우 찾았다.기본값이 langchain_embedding, langchain_collection 이다. 이러니까 안나오지...그냥 복잡하니 langc
38.[AI] mongodb 로 RAG 구현해보자.

macos 에서 설치 해보겠다.https://www.mongodb.com/try/download/compass이제 mongodb 의 준비가 끝났다.총 88 Row 입력 완료벡터 데이터에서 먼저 찾은 후 참조하는 모습이다.상위 1개만 검색해서 그런지 다른 내용은
39.[AI] CUDA out of memory...
4090 이나 5090 같은 24기가, 32기가 VRAM 이 탑재되어 있다면 메모리의 속박에서 조금 더 자유로울 것이다 하지만...아니 뭐 별로 한것도 없다고...def measure_mem(model, tokenizer, text): gc.collect(