1. 일단 mariadb 설치
% brew install mariadb2. 서버 시작/중지
% mysql.server start
% mysql.server stop3. 서비스로 등록/해제
% brew services start mariadb
% brew services stop mariadb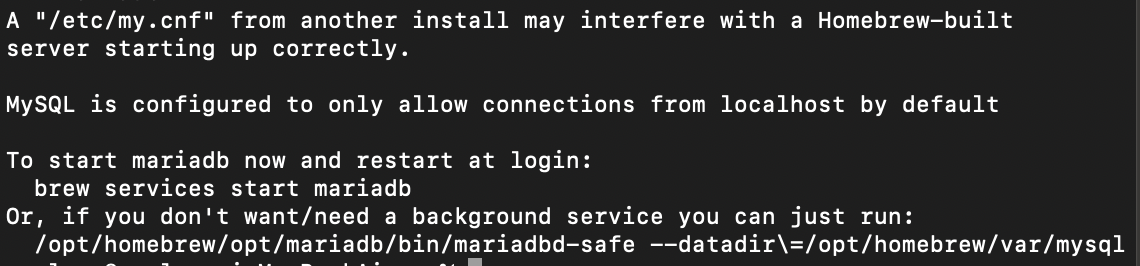
4. mariadb 초기설정
% mysql_secure_installation4-1. root 비밀번호
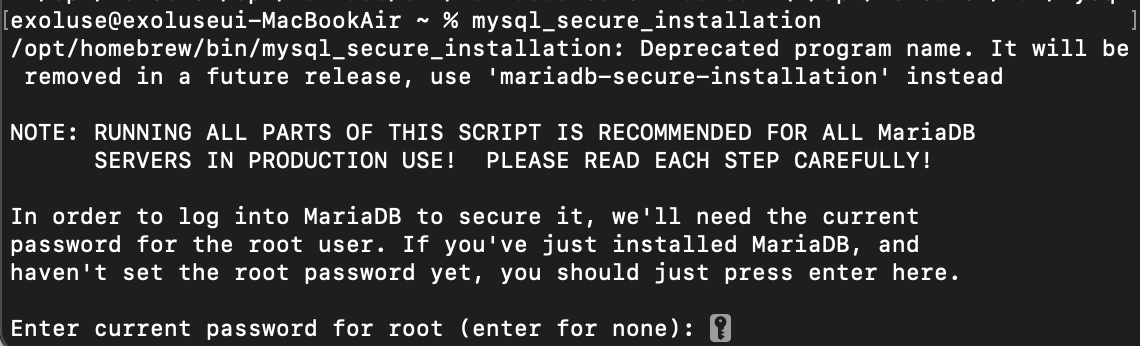
4-2. access denied?
% mysql -u root
> ALTER USER 'root'@'localhost' IDENTIFIED VIA mysql_native_password USING PASSWORD('1234');
> flush privileges;4-3. 이미 root 비번 세팅 -> "n"
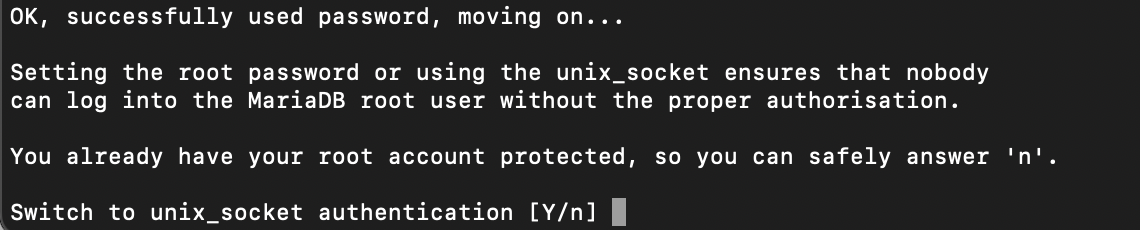

4-4. 익명 사용자 제거 -> "Y"

4-5. root 사용자 원격사용 불허 -> "n"

4-6. 테스트 db 삭제? -> "Y"

4-7. 테이블 권한 reload -> "Y"

4-8. 설정 끝

4-9. client test
OK
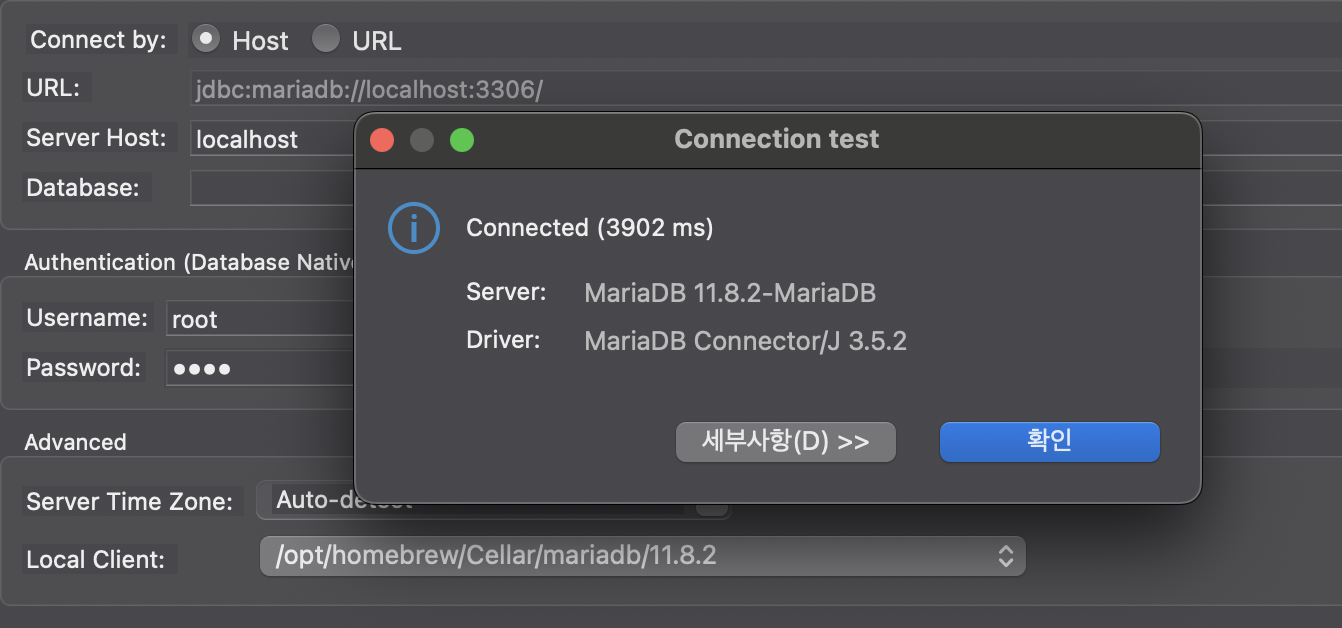
5. DB 및 테이블 생성
5-1. mariadb 패키지 설치
% uv pip install mariadb5-2. DB, 테이블 생성
import mariadb
# MariaDB 연결 설정
DB_HOST = "localhost"
DB_PORT = 3306
DB_USER = "root"
DB_PASSWORD = "1234"
DB_NAME = "exoluse"
TABLE_NAME = "content" # 테이블 이름 명시
# --- MariaDB 연결 (Connect to MariaDB) ---
try:
conn = mariadb.connect(
host=DB_HOST,
port=DB_PORT,
user=DB_USER,
password=DB_PASSWORD,
autocommit=True
)
cur = conn.cursor()
except mariadb.Error as e:
print(f"MariaDB 연결 실패: {e}")
exit(1) # 연결 실패 시 프로그램 종료
# --- 데이터베이스 및 테이블 준비 (Prepare Database and Table) ---
def prepare_database():
try:
cur.execute(f"CREATE DATABASE {DB_NAME}")
cur.execute(f"USE {DB_NAME};")
cur.execute(f"""
CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
category VARCHAR(255) NOT NULL,
title VARCHAR(255) NOT NULL,
text LONGTEXT NOT NULL,
embedding VECTOR(768) NOT NULL,
VECTOR INDEX (embedding)
);
""")
except mariadb.Error as e:
print(f"데이터베이스 또는 테이블 준비 실패: {e}")
exit(1)
if __name__ == "__main__":
prepare_database()
if conn:
cur.close()
conn.close()
print("MariaDB 연결이 닫혔습니다.")
6. 데이터 만들기.
전에도 사용한 적이 있는 네이버 뉴스 데이터셋을 써본다.
6-1. 필요 패키지 설치
% uv pip install datasets6-2. get_naver_news.py
import json
from datasets import load_dataset
# 데이터셋 로드
ds = load_dataset("daekeun-ml/naver-news-summarization-ko")
news_items = ds["train"]
# 한번만 파일 열고 저장
with open("naver_news.jsonl", "w", encoding="utf-8") as f:
for item in news_items:
json.dump({
"category": item["category"],
"title": item["title"],
"summary": item["summary"]
}, f, ensure_ascii=False)
f.write('\n')6-2. 생성된 jsonl

7. 만든 데이터 부어넣기
7-1. ollama 패키지 설치(임베딩용)
% uv pip install ollama7-2. mariadb_rag_data.py
import mariadb
import json
import os
import time
import ollama
# --- 설정 (Configuration) ---
EMBED_MODEL = "nomic-embed-text"
# MariaDB 연결 설정
DB_HOST = "localhost"
DB_PORT = 3316
DB_USER = "root"
DB_PASSWORD = "1234"
DB_NAME = "exoluse"
TABLE_NAME = "content" # 테이블 이름 명시
# --- MariaDB 연결 (Connect to MariaDB) ---
try:
conn = mariadb.connect(
host=DB_HOST,
port=DB_PORT,
user=DB_USER,
password=DB_PASSWORD,
database=DB_NAME,
autocommit=True # 각 쿼리 후 자동 커밋 (실습용)
)
cur = conn.cursor()
print(f"MariaDB 연결 성공: {DB_NAME} 데이터베이스", time.strftime('%Y.%m.%d - %H:%M:%S'))
except mariadb.Error as e:
print(f"MariaDB 연결 실패: {e}")
exit(1) # 연결 실패 시 프로그램 종료
# --- 지식 베이스 파일 읽기 (Read Knowledge Base File) ---
def read_from_file(filename):
"""
JSONL 파일에서 지식 베이스 데이터를 읽어 리스트로 반환합니다.
"""
if not os.path.exists(filename):
print(f"오류: 파일 '{filename}'을 찾을 수 없습니다. 파일 경로를 확인해주세요.")
return []
with open(filename, "r", encoding="utf-8") as file:
return [json.loads(line) for line in file]
# --- 콘텐츠 청크 나누기 (Chunkify Content) ---
def chunkify(content, min_chars=1, max_chars=10000):
"""
긴 텍스트 콘텐츠를 특정 기준에 따라 청크로 나눕니다.
"""
lines = content.split("\n")
chunks, chunk, length, start = [], [], 0, 0
for i, line in enumerate(lines + [""]): # 마지막에 빈 라인 추가하여 마지막 청크 처리 보장
if (
chunk
and (
line.lstrip().startswith("#") # 마크다운 헤더로 시작하거나
or not line.strip() # 빈 줄이거나
or length + len(line) > max_chars # 최대 길이를 초과하거나
)
and length >= min_chars # 최소 길이를 만족할 때
):
chunks.append(
{
"text": "\n".join(chunk).strip(),
"start_line": start,
"end_line": i - 1,
}
)
chunk, length, start = [], 0, i
chunk.append(line)
length += len(line) + 1
return chunks
# --- 임베딩 생성 (Generate Embeddings) ---
def embed(text):
"""
Ollama를 사용하여 텍스트 임베딩을 생성합니다.
"""
try:
response = ollama.embeddings(model=EMBED_MODEL, prompt=text)
return response["embedding"]
except ollama.ResponseError as e:
print(f"Ollama 임베딩 오류: {e}. 모델 '{EMBED_MODEL}'이 실행 중인지 확인하세요.")
return None
except Exception as e:
print(f"임베딩 중 예상치 못한 오류 발생: {e}")
return None
# --- 데이터베이스에 임베딩된 데이터 삽입 (Insert Embedded Data into DB) ---
def insert_into_db():
"""
naver_news.jsonl 파일에서 데이터를 읽어와 임베딩하고 MariaDB에 삽입합니다.
"""
print("\n데이터베이스에 문서 삽입 시작...", time.strftime('%Y.%m.%d - %H:%M:%S'))
kb_pages = read_from_file("naver_news.jsonl")
if not kb_pages:
print("삽입할 데이터가 없습니다. 'naver_news.jsonl' 파일과 내용을 확인하세요.")
return
# 기존 데이터 삭제 (새로운 데이터를 넣기 전 깔끔하게 시작하기 위함)
try:
print(f"테이블 '{TABLE_NAME}'의 기존 데이터 삭제 중...", time.strftime('%Y.%m.%d - %H:%M:%S'))
cur.execute(f"TRUNCATE TABLE {TABLE_NAME};")
print("기존 데이터 삭제 완료.")
except mariadb.Error as e:
print(f"기존 데이터 삭제 실패: {e}")
# 계속 진행하거나 종료할지 결정
return
inserted_count = 0
for p in kb_pages:
chunks = chunkify(p["text"])
for chunk in chunks:
# print(f" - 임베딩 청크 (길이 {len(chunk['text'])}) from '{p['title']}'")
embedding = embed(chunk["text"])
if embedding is None or len(embedding) == 0:
print(f"경고: '{p['title']}' 청크에 대한 임베딩이 생성되지 않았습니다. 건너뜜.")
continue
# **핵심: 파이썬 리스트 형태의 임베딩을 JSON 문자열로 변환**
embedding_json_str = json.dumps(embedding)
try:
cur.execute(
f"""INSERT INTO {TABLE_NAME} (title, category, text, embedding)
VALUES (%s, %s, %s, VEC_FromText(%s))""",
(p["title"], p["category"], chunk["text"], embedding_json_str),
)
inserted_count += 1
except mariadb.Error as e:
print(f"데이터 삽입 중 오류 발생 (제목: {p['title']}): {e}")
conn.rollback() # 오류 발생 시 롤백 (autocommit=True 이므로 사실상 영향 없음)
continue
# conn.commit() # autocommit=True 이므로 명시적 commit 필요 없음 (하지만 명시해도 무방)
print(f"\n총 {inserted_count}개의 문서 청크가 데이터베이스에 성공적으로 삽입되었습니다.", time.strftime('%Y.%m.%d - %H:%M:%S'))
# --- 메인 실행 블록 (Main Execution Block) ---
if __name__ == "__main__":
# 데이터 삽입 (초기 한 번만 실행)
# prepare_database()를 실행한 후, 데이터를 처음 넣을 때만 주석 해제하여 실행
insert_into_db()
# 연결 닫기
if conn:
cur.close()
conn.close()
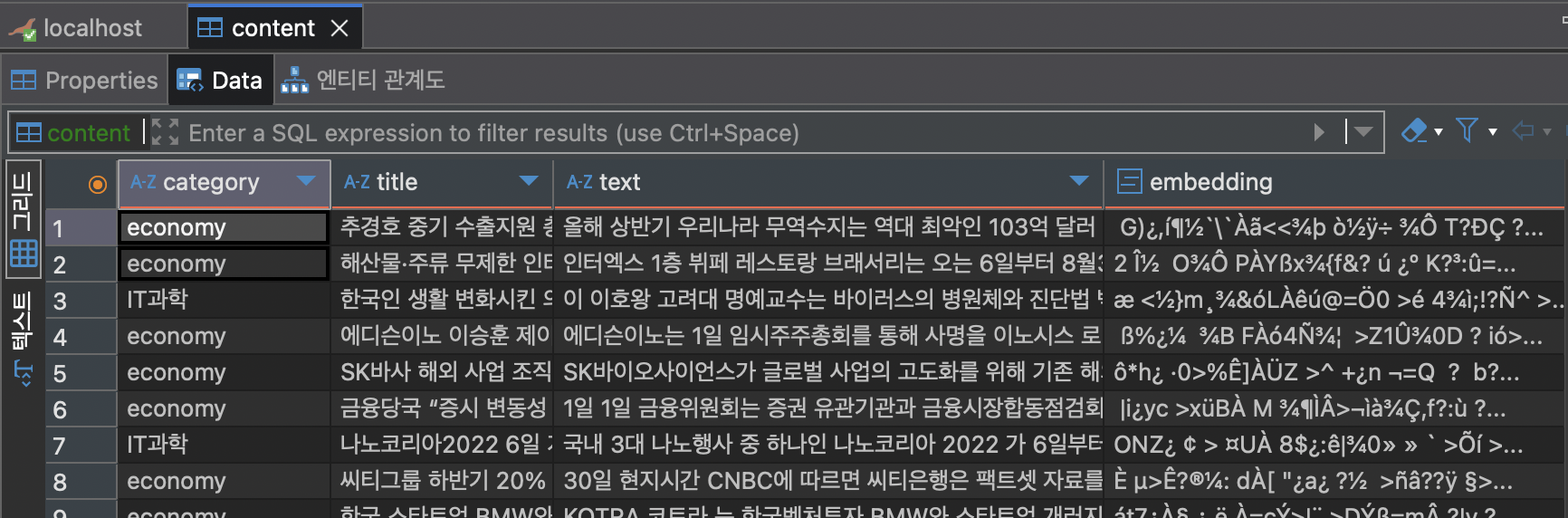
print("MariaDB 연결이 닫혔습니다.")7-3. insert 결과
이런 식으로 embedding 컬럼에 벡터 데이터가 쌓이는데
보기엔 바이너리인데 실제론 벡터 데이터가 맞다고 한다.
8. RAG 시도
8-1. mariadb_rag_test.py
import mariadb
import ollama
import json
import time
# --- 설정 (Configuration) ---
EMBED_MODEL = "nomic-embed-text"
LLM_MODEL = "exaone3.5:7.8b"
# MariaDB 연결 설정
DB_HOST = "localhost"
DB_PORT = 3306
DB_USER = "root"
DB_PASSWORD = "1234"
DB_NAME = "exoluse"
TABLE_NAME = "content" # 테이블 이름 명시
# --- MariaDB 연결 (Connect to MariaDB) ---
try:
conn = mariadb.connect(
host=DB_HOST,
port=DB_PORT,
user=DB_USER,
password=DB_PASSWORD,
database=DB_NAME,
autocommit=True # 각 쿼리 후 자동 커밋 (실습용)
)
cur = conn.cursor()
print(f"MariaDB 연결 성공: {DB_NAME} 데이터베이스", time.strftime('%Y.%m.%d - %H:%M:%S'))
except mariadb.Error as e:
print(f"MariaDB 연결 실패: {e}")
exit(1) # 연결 실패 시 프로그램 종료
# --- 임베딩 생성 (Generate Embeddings) ---
def embed(text):
"""
Ollama를 사용하여 텍스트 임베딩을 생성합니다.
"""
try:
response = ollama.embeddings(model=EMBED_MODEL, prompt=text)
return response["embedding"]
except ollama.ResponseError as e:
print(f"Ollama 임베딩 오류: {e}. 모델 '{EMBED_MODEL}'이 실행 중인지 확인하세요.")
return None
except Exception as e:
print(f"임베딩 중 예상치 못한 오류 발생: {e}")
return None
# --- 가장 유사한 콘텐츠 검색 (Search for Closest Content) ---
def search_for_closest_content(query_text, n):
"""
사용자 질의에 대한 가장 유사한 콘텐츠를 데이터베이스에서 검색합니다.
"""
print(f"\n'{query_text}'에 대한 관련 문서 검색 중...", time.strftime('%Y.%m.%d - %H:%M:%S'))
query_embedding = embed(query_text)
if query_embedding is None or len(query_embedding) == 0:
print(f"경고: 질의 '{query_text}'에 대한 임베딩이 생성되지 않았습니다. 검색 불가.")
return []
# **핵심: 질의 임베딩을 JSON 문자열로 변환**
query_embedding_json_str = json.dumps(query_embedding)
try:
cur.execute(f"USE {DB_NAME};")
cur.execute(
f"""
SELECT title, category, text,
VEC_DISTANCE_COSINE(embedding, VEC_FromText(%s)) AS distance
FROM {TABLE_NAME}
ORDER BY distance ASC
LIMIT %s;
""",
(query_embedding_json_str, n),
)
print(query_embedding_json_str)
results = [
{"title": title, "category": category, "text": text, "distance": distance}
for title, category, text, distance in cur
]
print(f"총 {len(results)}개의 문서가 검색되었습니다.", time.strftime('%Y.%m.%d - %H:%M:%S'))
return results
except mariadb.Error as e:
print(f"데이터 검색 중 오류 발생: {e}")
return []
# --- LLM을 이용한 질의 응답 (Prompt Chat with LLM) ---
def prompt_chat(system_prompt, user_prompt):
"""
Ollama LLM을 사용하여 시스템 프롬프트와 사용자 프롬프트를 기반으로 답변을 생성합니다.
"""
print("\nLLM 응답 생성 중...", time.strftime('%Y.%m.%d - %H:%M:%S'))
try:
response = ollama.chat(
model=LLM_MODEL,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
return response['message']['content']
except ollama.ResponseError as e:
print(f"Ollama LLM 응답 오류: {e}. 모델 '{LLM_MODEL}'이 실행 중인지 확인하세요.")
return "LLM 응답을 생성할 수 없습니다. Ollama 서버와 모델을 확인해주세요."
except Exception as e:
print(f"LLM 응답 생성 중 예상치 못한 오류 발생: {e}")
return "LLM 응답 생성 중 오류가 발생했습니다."
# --- 메인 실행 블록 (Main Execution Block) ---
if __name__ == "__main__":
user_input = "나노코리아2022" # 사용자 질의
print(f"\n사용자 질의: '{user_input}'")
# 3. 관련 콘텐츠 검색
closest_content = search_for_closest_content(user_input, 5) # 상위 5개 문서 검색
# 검색된 문서 내용 출력 (디버깅 목적)
print("\n--- 검색된 지식 내용 ---")
if closest_content:
for i, doc in enumerate(closest_content):
print(f"--- 문서 {i+1} (거리: {doc['distance']:.4f}) ---")
print(f"카테고리: {doc['category']}")
print(f"제목: {doc['title']}")
print(f"내용 (처음 300자): {doc['text'][:300]}...")
print("-" * 20)
else:
print("경고: 질의와 관련된 지식 문서를 찾지 못했습니다. (검색 결과 0건)")
print("------------------------")
# 4. LLM에 질문 및 지식 내용 전달하여 답변 생성
system_prompt_with_rag = """
당신은 아주 똑똑한 AI 어시스턴트입니다.
사용자의 질문에 대해 제공된 '지식 내용'에서 관련된 내용을 찾아 답변합니다.
지식 내용 이외의 정보는 제공하지 마세요. 만약 지식 내용에 답변할 정보가 없다면, '제공된 지식 내용으로는 답변할 수 없습니다.'라고 답변하세요.
"""
# 검색된 문서 리스트를 문자열로 변환하여 LLM 프롬프트에 포함
prompt_with_rag = f"""
지식 내용:\n
{json.dumps(closest_content, ensure_ascii=False, indent=2)} \n\n
질문:\n {user_input}
"""
llm_response = prompt_chat(system_prompt_with_rag, prompt_with_rag)
print("\n--- 최종 LLM 응답 ---")
print(llm_response)
print("--- 추론 완료 ---", time.strftime('%Y.%m.%d - %H:%M:%S'))
# 연결 닫기
if conn:
cur.close()
conn.close()
print("MariaDB 연결이 닫혔습니다.")8-2. 추론 결과

8-3. 제공된 데이터와 비교
{"category": "IT과학", "title": "나노코리아 2022 나노기술로 지속가능한 미래 이끈다", "text": "나노코리아 2022에서는 철원플라즈마산업기술연구원이 퀀텀닷 조명을 활용한 고품질 고추냉이 재배기술을 선보였으며 두와이즈켐의 표면개질 셀룰로스 나노섬유 두와이즈켐은 표면개질 셀룰로스 나노섬유 제품을 공개하는 등 이색적이면서도 환경과 사회를 생각한 이색적이면서도 환경과 사회를 생각한 나노기술이 등장해 눈길을 끌었다."}

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.