1. Redis AI 세팅!
redis-server 설치 후 redis AI 를 빌드한 뒤 redis-server 에 얹어서 시작하는 방식이다.
1-1. wsl 설치
$ wsl --install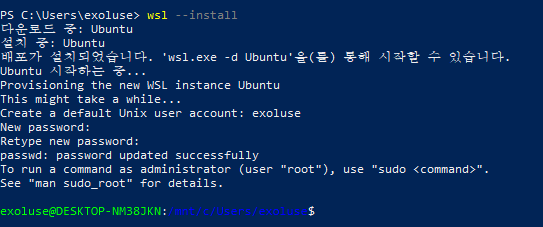
1-2. redis-server 설치
$ sudo apt update
$ sudo apt install redis-server1-3. redis-server 확인
$ sudo service redis-server start
$ redis-cli ping1-4. Redis AI git clone
$ cd ~
$ git clone --recurse-submodules https://github.com/RedisAI/RedisAI.git ~/redis-inference-optimization1-5. Redis AI 설치
Done. 메시지가 나오면 성공~
$ cd redis-inference-optimization
$ bash get_deps.sh
1-6. make 설치
$ sudo apt install make1-7. 모듈 빌드
$ sudo apt install -y build-essential cmake git python3 python3-pip unzip curl wget
$ mkdir build
$ cd build
$ cmake .. -DBUILD_ORT=ON
$ make clean
$ make
1-8. redis-server 시작
$ redis-server --port 6380 --loadmodule ./bin/linux-x64-release/src/redisai.so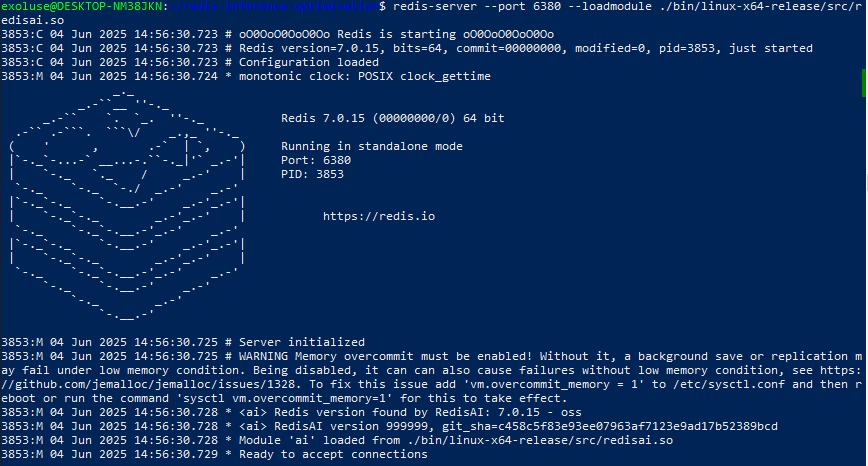
2. 모델 ONNX 변환
2-1. optimum 설치
$ pip install optimum[onnxruntime] accelerate2-2. 모델 다운로드 및 ONNX 변환
cmd 를 관리자 모드로 열어서 권한 문제 해결됨...
from optimum.onnxruntime import ORTModelForCausalLM
from transformers import AutoTokenizer
import os
os.environ["TEMP"] = "C:\\Temp"
os.environ["TMP"] = "C:\\Temp"
hf_token = os.getenv("HUGGINGFACE_API_KEY")
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name, token=hf_token)
# ONNX 변환 및 최적화 자동 진행
model = ORTModelForCausalLM.from_pretrained(model_name, from_transformers=True, export=True, token=hf_token)
model.save_pretrained("./tinyllama-onnx")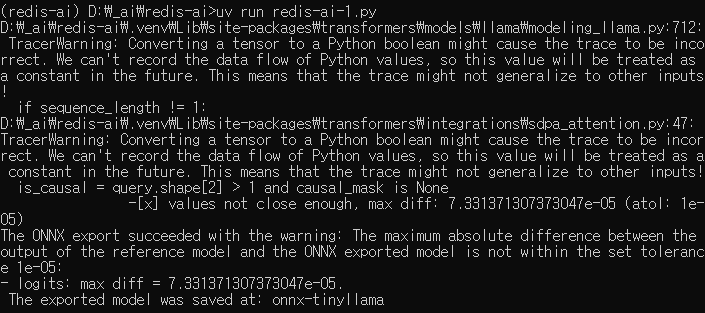
2-3. ONNX 모델 확인
대충 이런 형태면 된다.
import onnx
model = onnx.load("./onnx-tinyllama/model.onnx")
print("Inputs:")
for input in model.graph.input:
print("-", input.name)
print("\nOutputs:")
for output in model.graph.output:
print("-", output.name)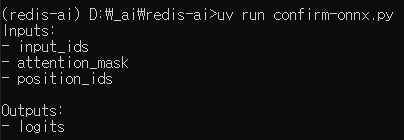
3. ONNX 모델 Redis 에 업로드
3-1. 필요 패키지 설치
pip install redis redisai3-2. 업로드 실행
import redisai as rai
# RedisAI 클라이언트 연결 (RedisAI 모듈이 로드된 Redis 서버)
con = rai.Client(host='localhost', port=6381)
# ONNX 모델 로드
with open("./onnx-tinyllama/model.onnx", "rb") as f:
model_data = f.read()
# 모델 등록 (입력/출력 이름은 실제 ONNX 모델에 따라 변경 필요)
con.modelstore(
"tinyllama", # Redis 키 이름
backend="onnx", # 모델 백엔드
device="cpu", # 또는 "gpu"
data=model_data,
inputs=["input_ids", "attention_mask", "position_ids"], # 실제 입력 이름
outputs=["logits"] # 실제 출력 이름
)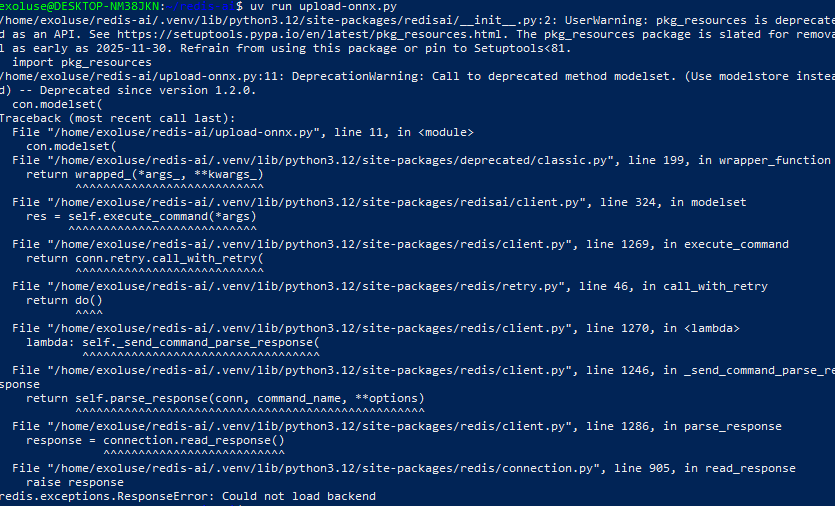
백엔드 모듈 오류만 20번은 본거 같다...

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.