이 글은 정치적인 의도가 전혀 없음을 알린다!
1. 필요 패키지 설치
% uv pip install selenium requests
% uv pip install torch transformers accelerate pillow
% uv pip install langchain_community2. 크롬 드라이버 설치(macos 기준)
% brew install chromedriver
% chromedriver --version 3. pyenv 환경 설정
% pyenv install 3.13.3
% mkdir president
% cd president
% pyenv local 3.13.3
% uv venv .venv
% source .venv/bin/activate4. 네이버 이미지 크롤링
이렇게 하면 images21대대선_지지율 디렉토리가 생성되고 그 안에 이미지 검색 최상위 5개가 저장된다.
import os
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from urllib.parse import quote
def download_image(url, folder, index):
try:
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers, timeout=5)
if response.status_code == 200:
ext = url.split('.')[-1].split('?')[0]
if len(ext) > 5 or '/' in ext:
ext = 'jpg'
filename = f'image_{index}.{ext}'
with open(os.path.join(folder, filename), 'wb') as f:
f.write(response.content)
print(f'✔ 저장됨: {filename}')
except Exception as e:
print(f'❌ 다운로드 실패: {url} - {e}')
def fetch_images(query, limit=10):
search_url = f"https://search.naver.com/search.naver?where=image&query={quote(query)}"
folder = f'images_{query.replace(" ", "_")}'
os.makedirs(folder, exist_ok=True)
options = webdriver.ChromeOptions()
options.add_argument('--headless=new')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--window-size=1920,1080")
options.add_argument("user-agent=Mozilla/5.0") # Naver 차단 회피
driver = webdriver.Chrome(options=options)
try:
driver.get(search_url)
time.sleep(2)
# 이미지 요소가 로드될 때까지 기다림
img_elements = driver.find_elements(By.CSS_SELECTOR, "div.thumb img")
print(f"🔍 찾은 이미지 수: {len(img_elements)}개")
count = 0
for img in img_elements:
src = img.get_attribute("src")
if not src:
src = img.get_attribute("data-lazy-src") # 일부는 지연 로딩 속성 사용
if src and src.startswith("http"):
download_image(src, folder, count + 1)
count += 1
if count >= limit:
break
finally:
driver.quit()
print(f"\n✅ 다운로드 완료: {count}개 이미지 → 폴더 '{folder}'")
if __name__ == "__main__":
# 이미지 다운로드 실행
fetch_images("21대 대선 지지율", 5)4-1. 이미지 확인
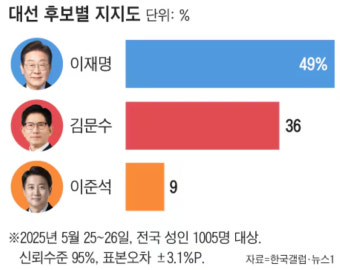
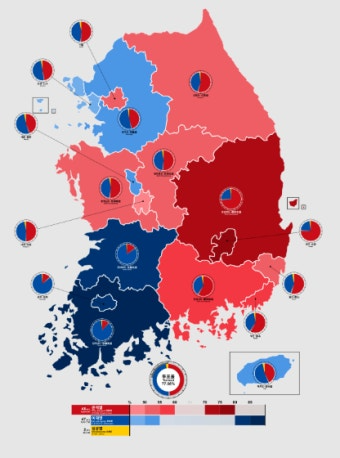
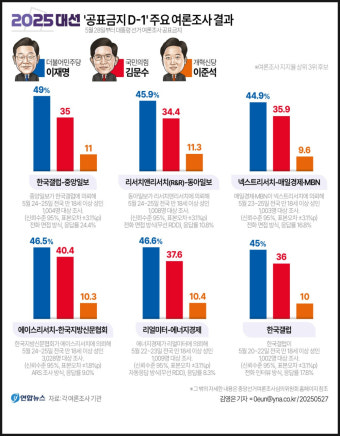
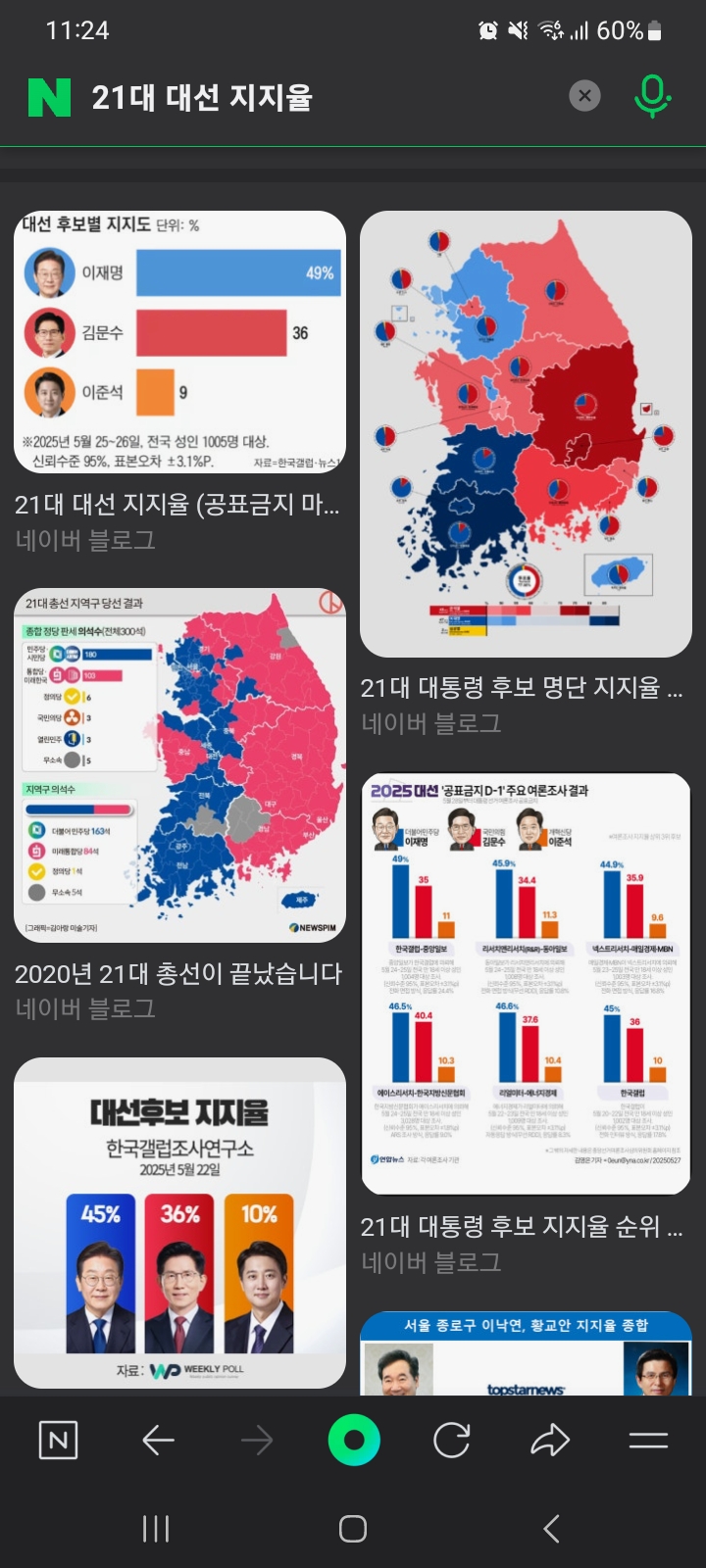
이렇게 5개가 선정되었다. 3번째 이미지는 21대 총선 결과 이미지이므로 제외할 필요가 있겠다.

4-2. 실제 검색 결과
5. 크롤링 이미지 분석 및 요약
image_3.jpg 를 삭제 후 4개만 놓고 분석을 시작하였다.
from get_data import fetch_images
import base64
import requests
from langchain.tools import tool
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_community.llms import Ollama
from typing import Optional
# 1. llava 를 이용한 이미지 설명
def describe_image(image_path: str, prompt: Optional[str] = "Describe the image in detail") -> str:
with open(image_path, "rb") as f:
image_base64 = base64.b64encode(f.read()).decode()
res = requests.post("http://localhost:11434/api/generate", json={
"model": "llava-llama3",
"prompt": prompt,
"images": [image_base64],
"stream": False
})
return res.json().get("response", "").strip()
# 2. exaone3.5용 LangChain 구성
exaone_llm = Ollama(model="exaone3.5:7.8b")
exaone_prompt = PromptTemplate(
input_variables=["image_caption", "user_question"],
template="""
다음은 이미지 설명입니다:
{image_caption}
위 이미지를 기반으로 다음 질문에 답해주세요:
{user_question}
답변:
"""
)
# 3. exaone3.5 체인 구성
exaone_chain = LLMChain(llm=exaone_llm, prompt=exaone_prompt)
# 4. 전체 파이프라인 실행
if __name__ == "__main__":
# 이미지 다운로드 실행
fetch_images("21대 대선 지지율", 5)
request_to_llava = "파란색 계열은 민주당, 붉은색 계열은 국민의힘, 주황색 계열은 개혁신당 입니다. 각 정당 색깔의 주도율을 추출해 주세요."
request_to_exaone = "위 설명을 500자 이내로 요약해 주세요."
caption = ""
for i in range(4):
print(f"🖼️ llava로 이미지 설명 생성 중...{i+1}")
image_path = f"./images_21대_대선_지지율/image_{i+1}.jpg"
caption += describe_image(image_path, request_to_llava) + "\n\n"
print("🧠 exaone으로 질문 응답 생성 중...")
result = exaone_chain.run({
"image_caption": caption,
"user_question": request_to_exaone
})
print("\n✅ 최종 응답:", result)6. 결과
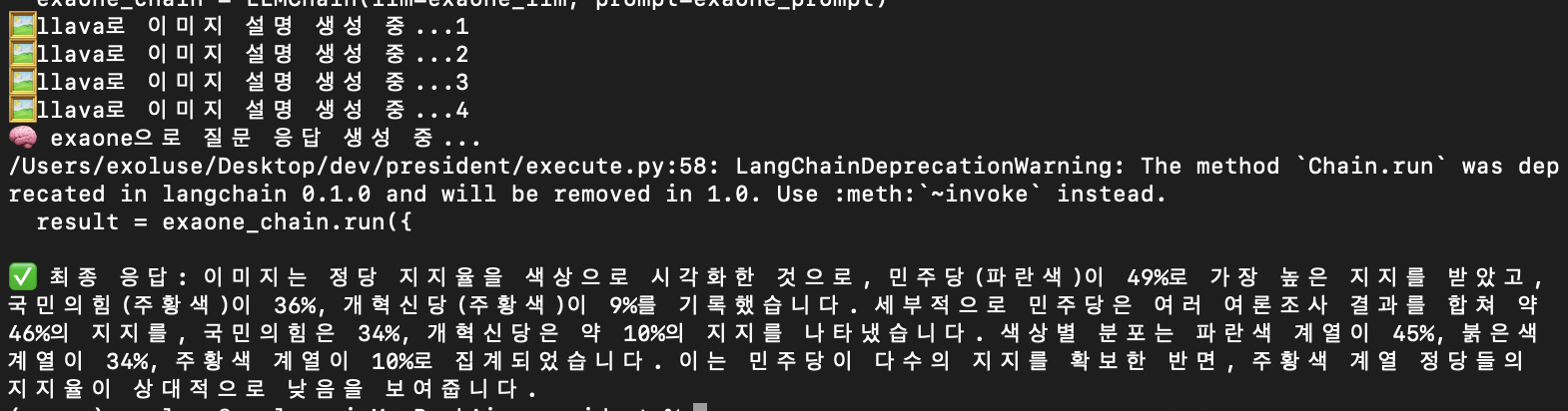
Finally
개표방송 한쪽에 켜놓고 보면서 프로그램 끄적여 보았다.
대체적으로 민주당이 45%~49%, 국민의힘이 34%~36%, 개혁신당이 9%~10% 지지율을 보인다고 요약해 주었다.

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.