이번에는 로컬 PC에 모델을 로드하여 질문에 대한 답변을 얻어본다.
1. ollama 설치
-
https://ollama.com 에 접속하여 Download 버튼 클릭
-
설치 파일을 실행하면 다음과 같은 화면이 표시되는데 Next
-
Install 버튼 클릭
2. ollama가 지원하는 모델 확인
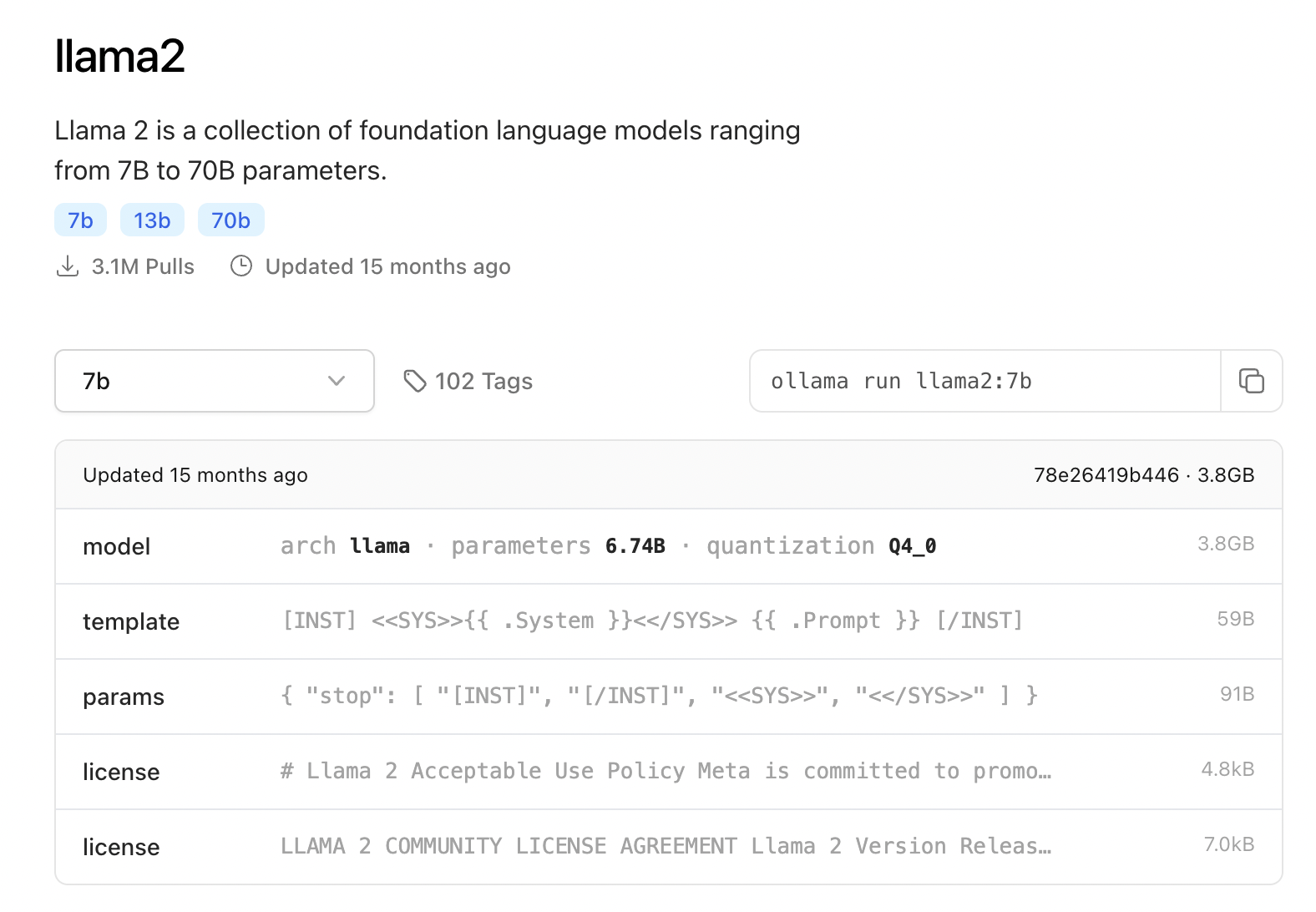
- https://ollama.com/search 에서 확인 가능하다.
- llama2 는 매개변수(파라미터)가 7억, 13억, 70억개인 버전이 있다.
- 매개변수를 Tag 라고 하나보다.
3. 로컬에 모델 다운로드
나는 ollama2 로 하겠다. gemma2 로 돌렸더니 프랑스의 수도를 묻는 질문에 3분 15초만에 답변을 주더라는...
llama2 로만 입력해도 7b 모델이 다운로드 된다.
# % ollama pull <model name:tag name>
% ollama pull llama2:7b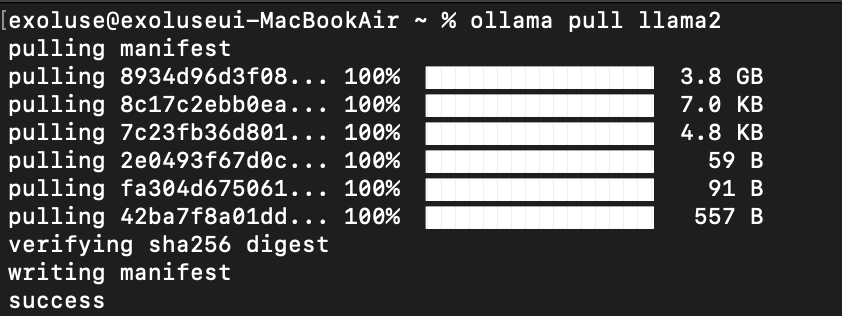
참고로 macos 에서 모델이 저장되는 기본 위치는 아래와 같다.
~/.ollama/models저장 위치를 바꾸려면 이렇게...
% OLLAMA_MODELS={저장 디렉토리} ollama serve4. langchain-community, python-dotenv 설치
여기부터는 지난번과 비슷하게 흘러간다.
% pip install langchain-community python-dotenv
5. dotenv 환경 로드
# ollama 를 이용할 때는 별도의 API KEY가 필요하지 않음.
from dotenv import load_dotenv
load_dotenv()6. ChatOllama 모델 준비
# ChatOllama model
from langchain_community.chat_models import ChatOllama
# 다운로드 받은 llama2 를 불러온다.
chat_model = ChatOllama(model="llama2")7. invoke 로 실행해본다.
result = chat_model.invoke("What is the capital of France?")
print(result.content)이번엔 1.7초만에 답을 줬다 감격의 눙물이...
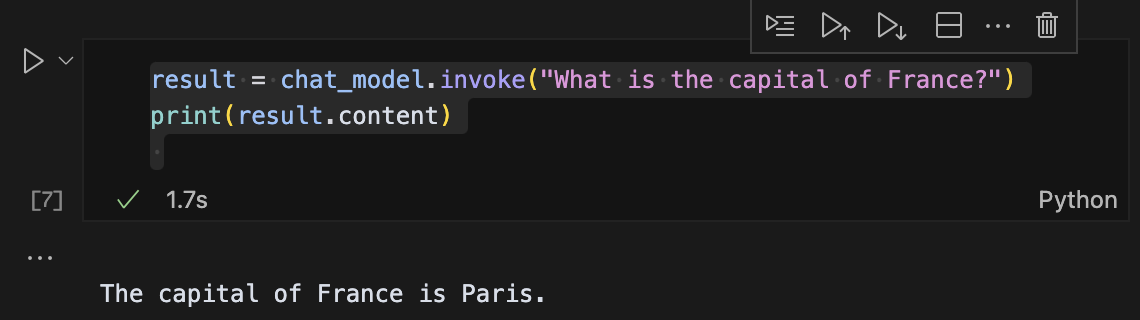
근데 한국어는 못한다고 한다.

8. 혹시 몰라서 한국어 버전의 모델을 찾아봤더니
-
두둥~ 있다. anpigon/qwen2.5-7b-instruct-kowiki 라는 모델이다.
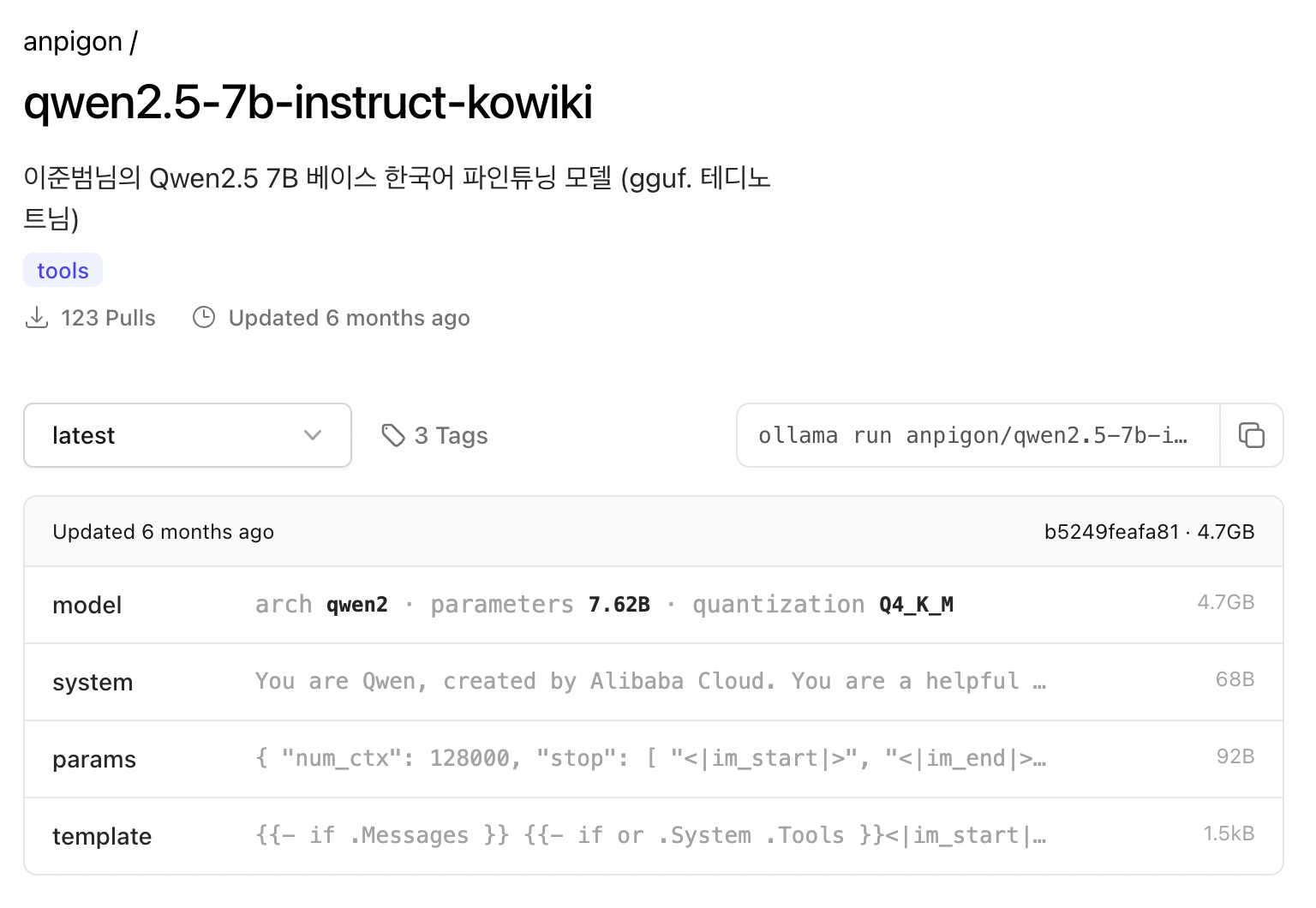
-
anpigon/qwen2.5-7b-instruct-kowiki 모델 다운로드
ollama pull anpigon/qwen2.5-7b-instruct-kowiki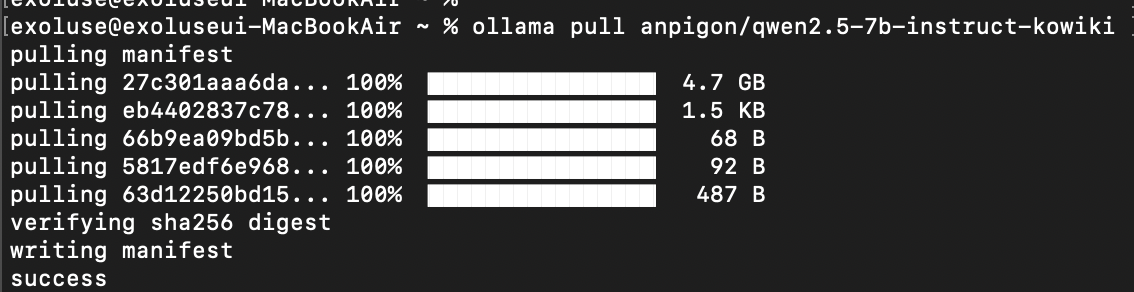
- 다운받은 모델을 적용해 보았다.
# ChatOllama model
from langchain_community.chat_models import ChatOllama
chat_model = ChatOllama(model="anpigon/qwen2.5-7b-instruct-kowiki")- invoke 로 실행!
result = chat_model.invoke("너 한글도 할줄 알아?")
print(result.content)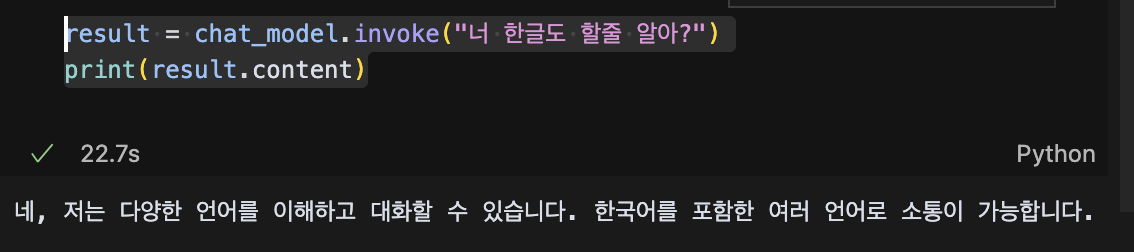
한국어라니... 감격의 눈물 장전!
9. 이런 메시지가 뜬다면?
ConnectionError: HTTPConnectionPool(host='localhost', port=11434)
# ollama 서비스 실행
% ollama serve10. 부록 : 리눅스에 설치
$ curl -fsSL https://ollama.com/install.sh | sh대충 이런 메시지가 뜨면 설치 완료

10-1. ollama 서비스 start
$ ollama serve
10-2. 모델 pull
$ ollama pull tinyllama
10-3. ollama 패키지 설치
$ pip install ollama10-4. 모델 test
실행되고 있는 ollama 서버에 요청해야 한다.
import ollama
import requests
input_text = "한국의 수도를 한국어로 말해 주세요."
model_name = "tinyllama"
response = requests.post(
"http://localhost:11434/api/chat",
json={
"model": model_name,
"messages": [
{"role": "user", "content": input_text}
],
"stream": False
}
)
# 응답 출력
print(response.json()["message"]["content"])? 이게 뭔 개소린지 모르겠다. 분명 한국어 할줄 안다고 했잖아...
그냥 한국어"만" 할수 있었나...


인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.