테스트전 embedding 모델과 llm 모델을 llama3.2:1b 에서 llama3.2:3b 로 변경하였다.
1. 아래와 같은 docx 파일을 읽는다.
인터넷에서 쉽게 입수 가능한 시스템 보안규정 샘플이다.
제x조 > 1,2,3 > ①,② 식의 구조를 가지고 있다.
크기는 약 35KB 이고 3페이지 정도의 작은 파일이다.
from langchain_community.document_loaders import Docx2txtLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=50)
# 문서 가져와서 쪼개기.
loader = Docx2txtLoader("./system.docx")
document_list = loader.load_and_split(text_splitter=text_splitter)
document_list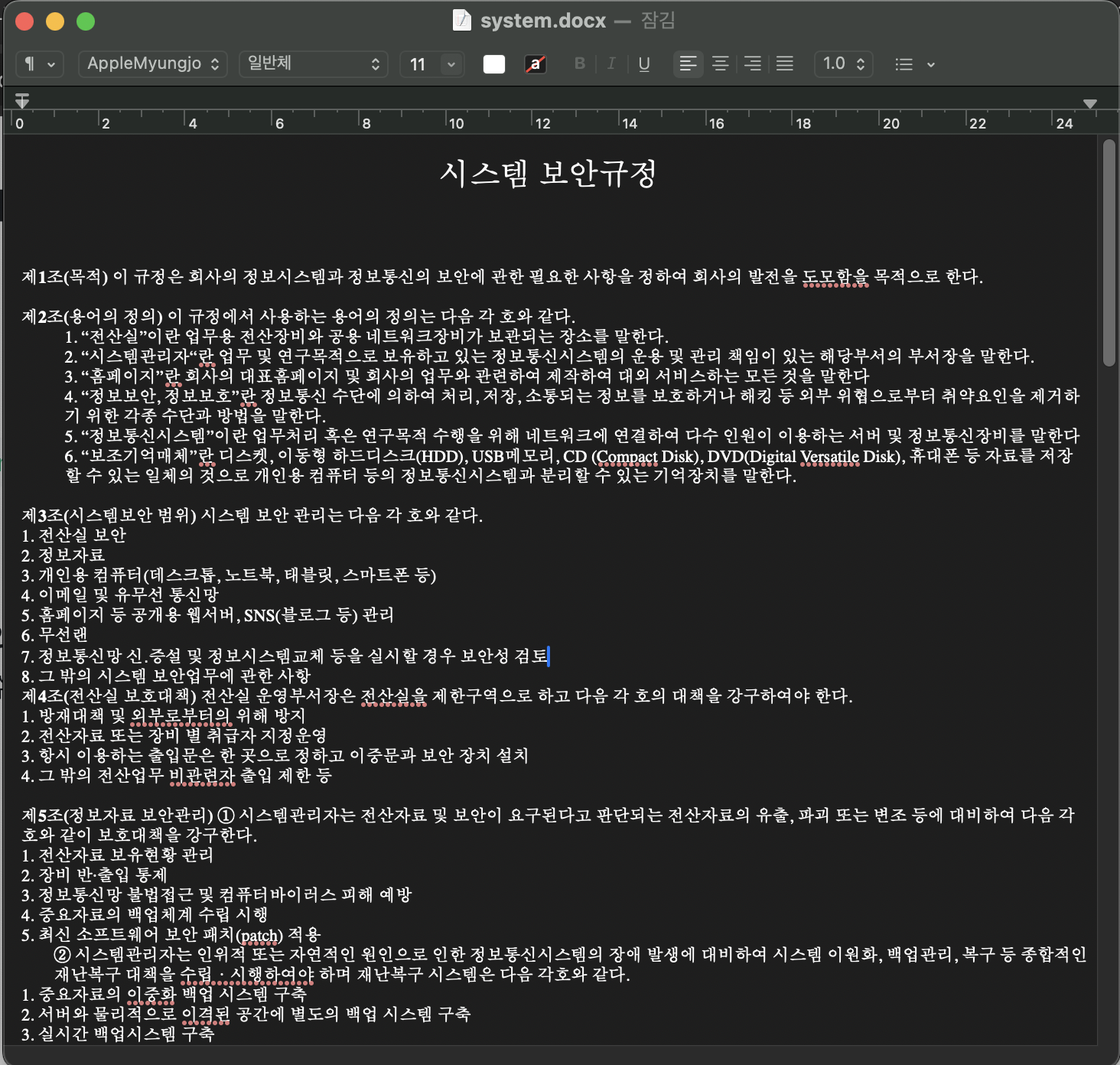
대충 이런 구조로 들어가게 된다.

2. 위 데이터를 pinecone index 에 저장하기 전에는
정보를 찾지 못했다고 솔직하게(?) 얘기해 줬다.

3. embedding 모델 설정
from langchain_community.embeddings import OllamaEmbeddings
embeddings = OllamaEmbeddings(
model="llama3.2:3b"
)4. pinecone index 에 저장해 보자.
Dimension 3072 로 index 를 사전에 생성하였다.
import os
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone
import time
pinecone_api_key = os.environ.get("PINECONE_API_KEY")
pc = Pinecone(api_key=pinecone_api_key)
pinecone_database = PineconeVectorStore.from_documents(
documents=document_list,
embedding=embeddings,
pinecone_api_key=pinecone_api_key,
index_name="index-system"
)5. llm 모델 설정
embedding 모델과 동일한 Dimension 을 가지는 모델로 설정해야 한다.
from langchain_community.chat_models import ChatOllama
llm = ChatOllama(
model="llama3.2:3b"
) ---- prompt 와 qa_chain 부분은 동일하다. ----
6. 다시 질의해 볼까?
ai_message = qa_chain({"query": "보조기억매체 보안관리에 대하여"})
ai_message7. 질의 결과
뭔가 어눌하지만 대답을 해주는 듯 하다.
{'query': '보조기억매체 보안관리에 대하여',
'result': 'bo조기억매체의 보안 관리는 사용자 및 소속부서장에게 책임이 있으며, 보안사고가 발생하지 않도록 철저한 보안관리를 강력하게推진해야 합니다. 정보보안 목적 외에 보안매체를 공개하여서는 안 되며, 접근권한을 차등 부여하여야 합니다. 보조기억매체의 보안 관리는 정보보안 관련 pháp규 및 규정에 따라 executed해야 합니다.'}
Finally
생각했던 것보다 로컬 테스트가 좀 어렵다는 것이 느껴진다. 데이터를 만들 때와 질의 시에 시간을 좀 많이 잡아먹는듯 하다... 이번 llama3.2:3b 는 1b 대비 2배 이상 오래 걸렸다... 코랩으로 학습을 해야하나 고민이 깊어진다... 이러다 또 맥북병에 걸릴수도...

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.