이전까지는 문서를 로드하여 쪼갠 후 임베딩한 데이터를 chroma 라는 것을 이용하여 저장 하였는데 이번에는 이 벡터 데이터를 pinecone 이라는 클라우드에 넣어 보겠다.
---- 문서를 읽고 쪼개는 과정은 생략한다. ----
1. Embbeding 선언
from langchain_community.embeddings import OllamaEmbeddings
embeddings = OllamaEmbeddings(
model="llama3.2:1b"
)2. pinecone Api key 취득
- https://app.pinecone.io/ 접속 및 가입
- 가입 직후 Api Key를 복사할수 있는 다이얼로그 표시
- Api key 복사
가입 직후의 모습은 아래와 같다.
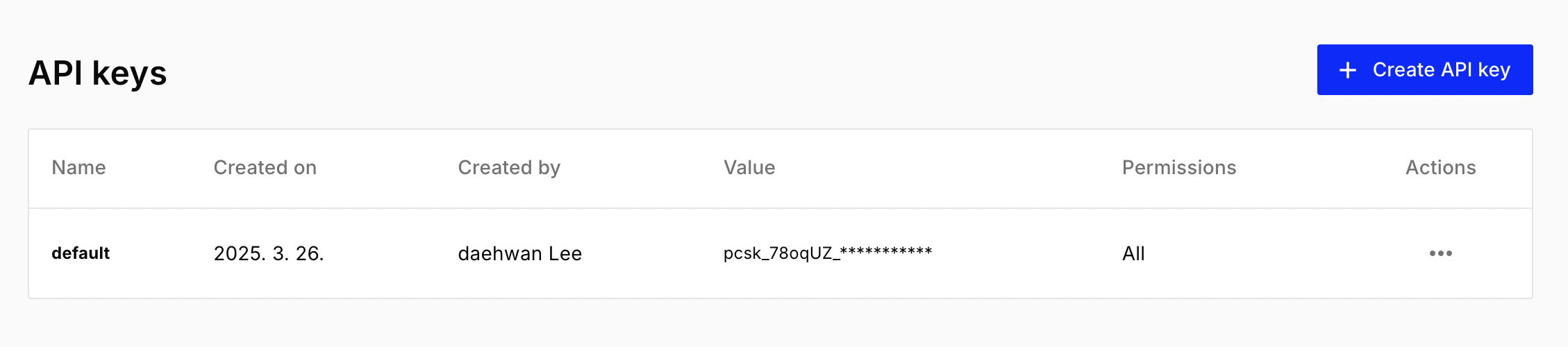
3. index 신규 생성
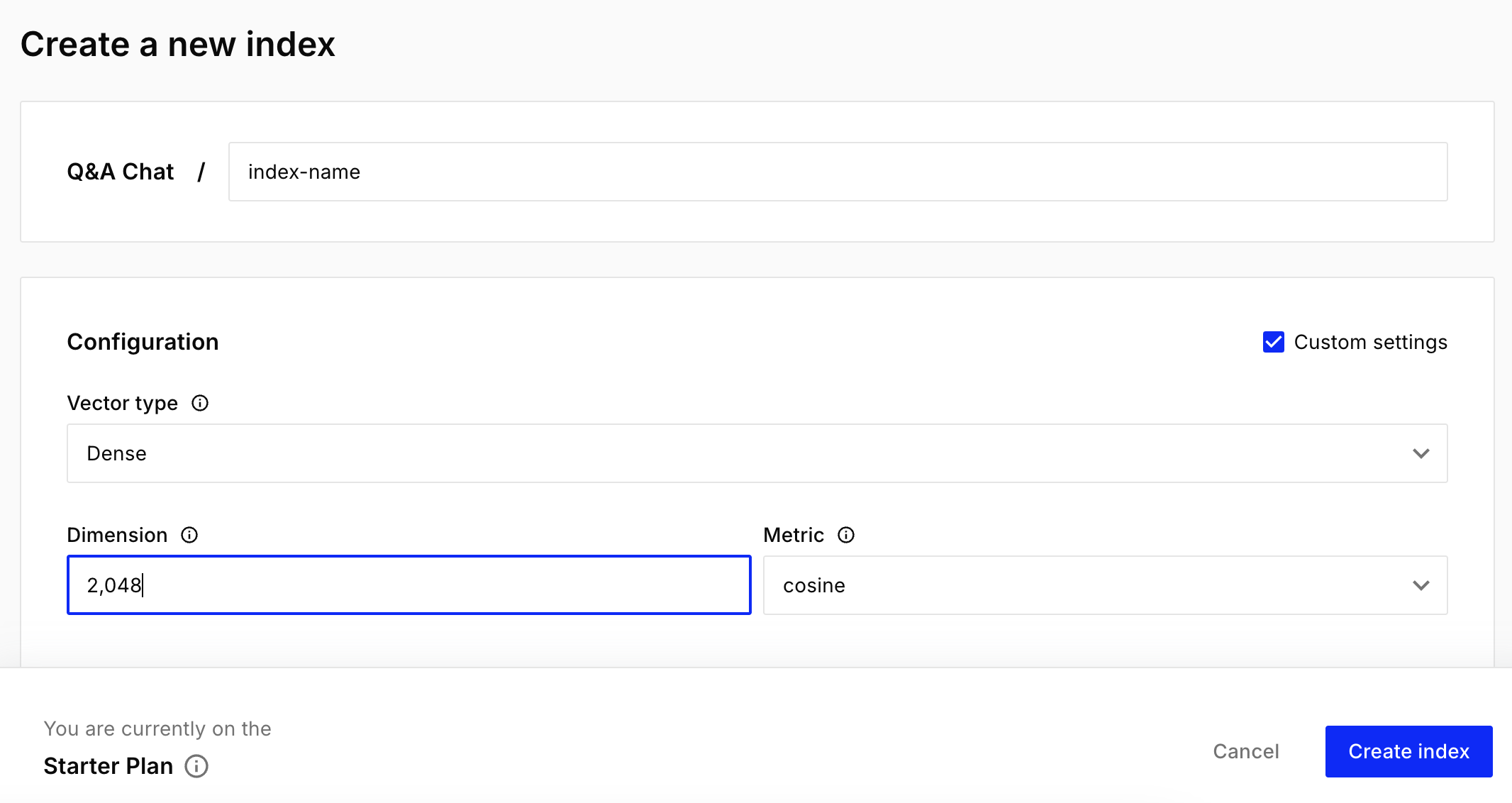
- Create Index 클릭

- Custom settings 를 체크하여 다음과 같이 입력 후 Create index 클릭한다. Dimension 값은 기존에 사용된 embedding 모델의 Dimension 과 동일해야 한다. 맞추지 않으면 아래와 같은 오류를 만나게 될 것이다.
HTTP response body: {"code":3,"message":"Vector dimension 2048 does not match the dimension of the index 3072","details":[]}
*Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings... *index 가 만들어졌다.
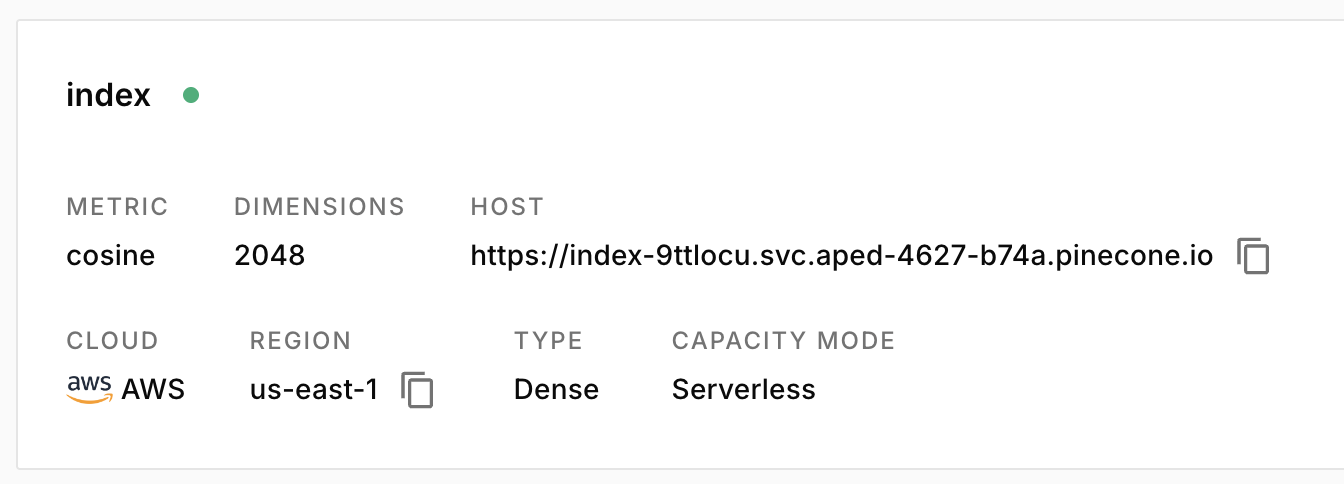
4. .env 에 PINECONE_API_KEY 추가
# 분실하면 다시 만들어야 함.
PINECONE_API_KEY=pcsk_78oqUZ_7KP2dGutbe7tNw............5. 환경변수 로드
from dotenv import load_dotenv
load_dotenv()6. langchain-pinecone 설치
%pip install --upgrade --quiet langchain-pinecone 7. pinecone index 에 저장
langchain-community langchain pinecone-notebooksß
import os
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone
import time
pinecone_api_key = os.environ.get("PINECONE_API_KEY")
pc = Pinecone(api_key=pinecone_api_key)
# pinecone index 에 저장
# dimension 을 어거지로 2048로 맞춘 것...
pinecone_database = PineconeVectorStore.from_documents(
documents=document_list, # 기존과 동일
embedding=embeddings, # 기존과 동일
pinecone_api_key=pinecone_api_key,
index_name="index"
)index 를 저장하면 이런 모습이다.
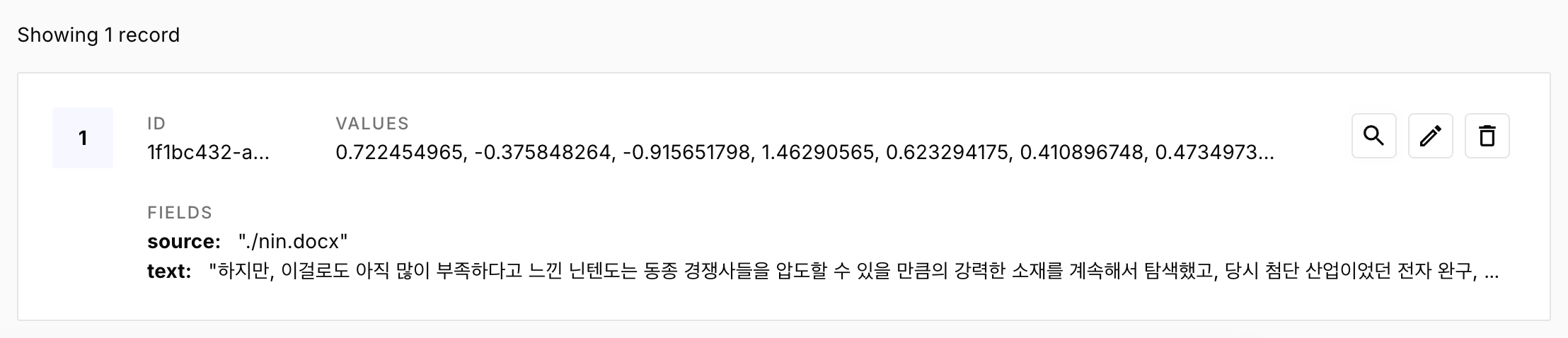
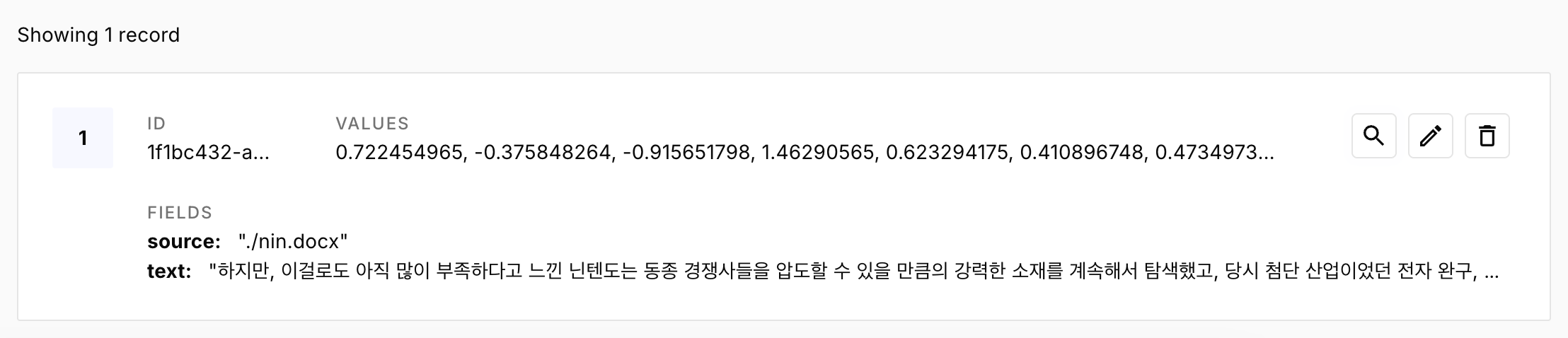
index 상세 내역을 보면 원본 파일명과 쪼갠 텍스트의 일부를 볼 수 있다.
8. llm 선언
from langchain_community.chat_models import ChatOllama
# pull 받은 모델 사용
llm = ChatOllama(
model="llama3.2:1b"
)9. prompt 선언
from langchain import hub
# 프롬프트를 제공한다.
prompt = hub.pull("rlm/rag-prompt")10. qa_chain 선언
retriever 가 chroma_database 에서 pinecone_database 로 변경된다. 나머지는 동일하다.
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm, # llama3.2:1b
retriever=pinecone_database.as_retriever(), # 다양하게 사용됨. 이걸로 데이터를 가져옴.
chain_type_kwargs={"prompt": prompt}
)11. qa_chain 에 질문 던지기.
ai_message = qa_chain({"query": "닌텐도가 만든 게임은?"})
ai_message질문 할때마다 계속 다른 결과물을 준다. 나도 좋은 모델 사용해보고 싶구먼...

Finally
이번에는 chroma 대신 pinecone 을 사용하는 것 뿐이었지만 로컬 vector 데이터를 관리하기가 용이하지 않기에 클라우드 저장소의 이점을 충분히 살릴 수 있을 것 같다. 여러 index 를 미리 만들어놓고 테스트 하기에도 편할듯 하다.

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.