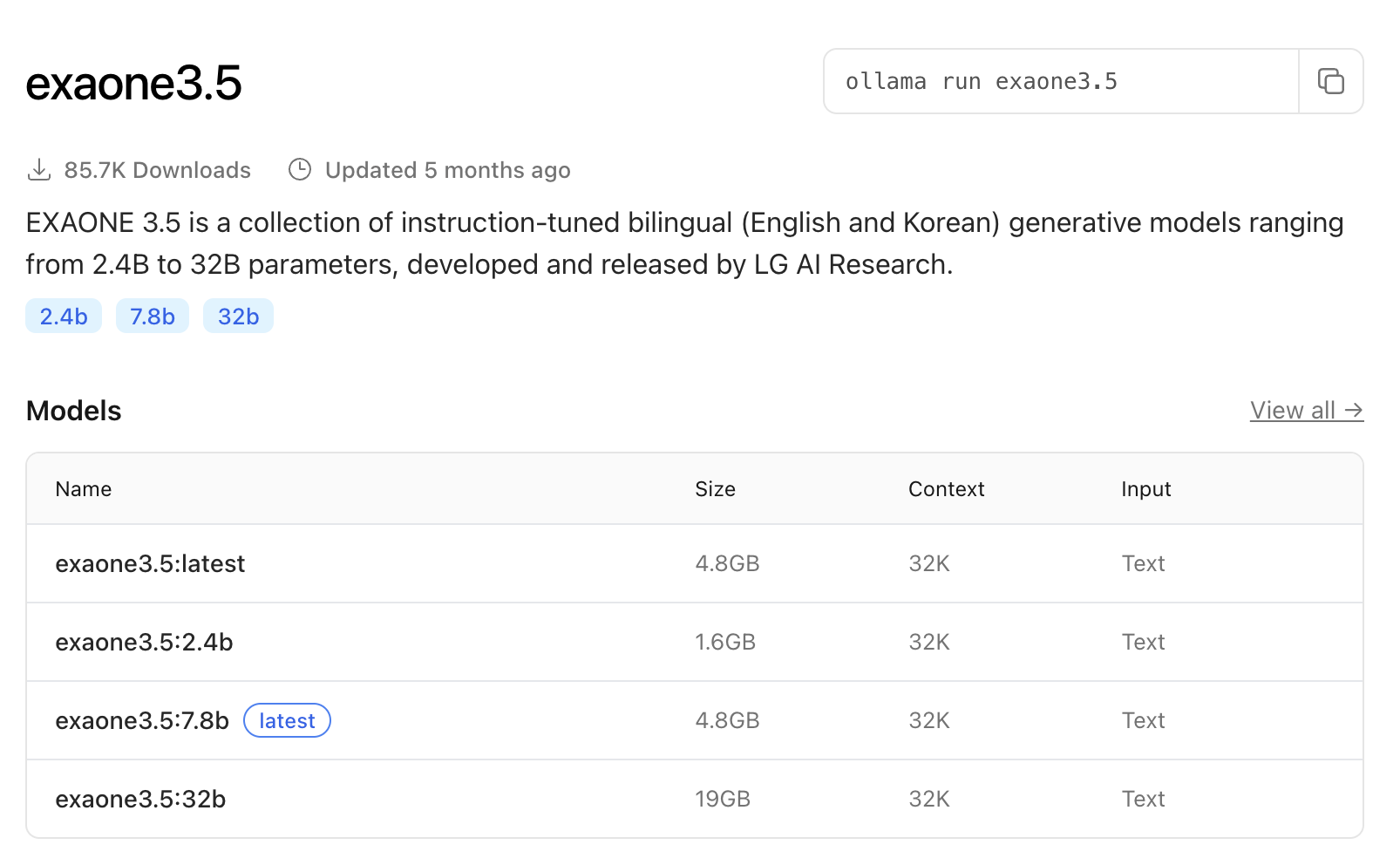
1. ollama 의 exaone3.5:2.4b 를 준비한다.
https://ollama.com/library/exaone3.5
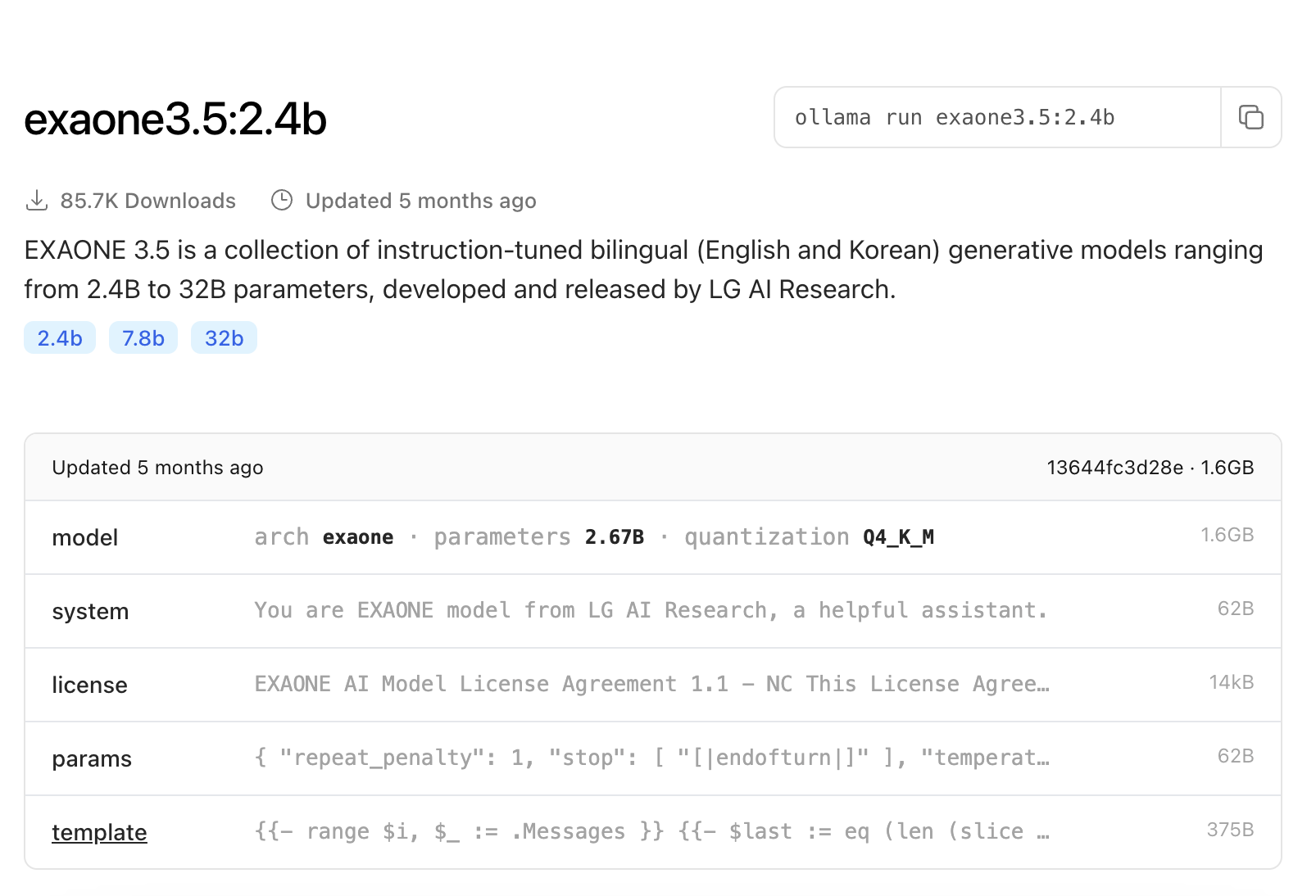
2. 하나씩 뜯어보자.
2-1. model
- 아키텍쳐 : exaone
- parameter : 2.67B
- quantization : Q4_K_M
용량 감소가 Q8 보다는 적은 Q4_K_M 을 선택했다.정확도도 그럭저럭 나오는 옵션이다.
2-2. system
You are EXAONE model from LG AI Research, a helpful assistant.
이게 시스템 프롬프트 인듯 하다.
2-3. license
연구 목적으로 사용은 되지만 수익창출은 안된단다.
2-4. params
[|endofturn|] 이 나오면 응답을 멈추도록 되어 있다.
{
"repeat_penalty": 1,
"stop": [
"[|endofturn|]"
],
"temperature": 1
}2-5. template
Role 이 "assistant" 이고 [|assistant|] 가 나오면 종료.
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{ if eq .Role "system" }}[|system|]{{ .Content }}[|endofturn|]
{{ continue }}
{{ else if eq .Role "user" }}[|user|]{{ .Content }}
{{ else if eq .Role "assistant" }}[|assistant|]{{ .Content }}[|endofturn|]
{{ end }}
{{- if and (ne .Role "assistant") $last }}[|assistant|]{{ end }}
{{- end -}}2-6. 간단히 돌려보기.
from langchain_ollama import OllamaLLM
llm = OllamaLLM(
model="exaone3.5:2.4b"
)
print(llm.invoke("안녕? 넌 누구니?"))
3. 로컬의 gguf 파일
3-1. llama.cpp 로 양자화
이젠 쉽게 양자화 가능하지?
% ./bin/llama-quantize models/EXAONE-3.5-2.4B-Instruct/EXAONE-3.5-2.4B-Instruct.gguf models/EXAONE-3.5-2.4B-Instruct/EXAONE-3.5-2.4B-Instruct.Q4_K_M.gguf Q4_K_M 
3-2. 간단히 돌려보기.
from langchain_community.llms import LlamaCpp
llm = LlamaCpp(
model_path="./EXAONE-3.5-2.4B-Instruct_Q4_K_M.gguf",
temperature=0.1,
top_p=1,
verbose=c,
n_ctx=2048,
n_gpu_layers=0, # ⛔ GPU 안 쓰도록 설정 (CPU 전용)
n_threads=8, # 텍스트 생성에 사용할 CPU 스레드 수
n_batch=8, # 배치 처리 크기 (프롬프트 처리 시)
repeat_penalty=1, # 반복 패널티 (1.0 이상). 값이 높을수록 반복되는 문구 감소
)
print(llm.invoke("안녕? 넌 누구니?"))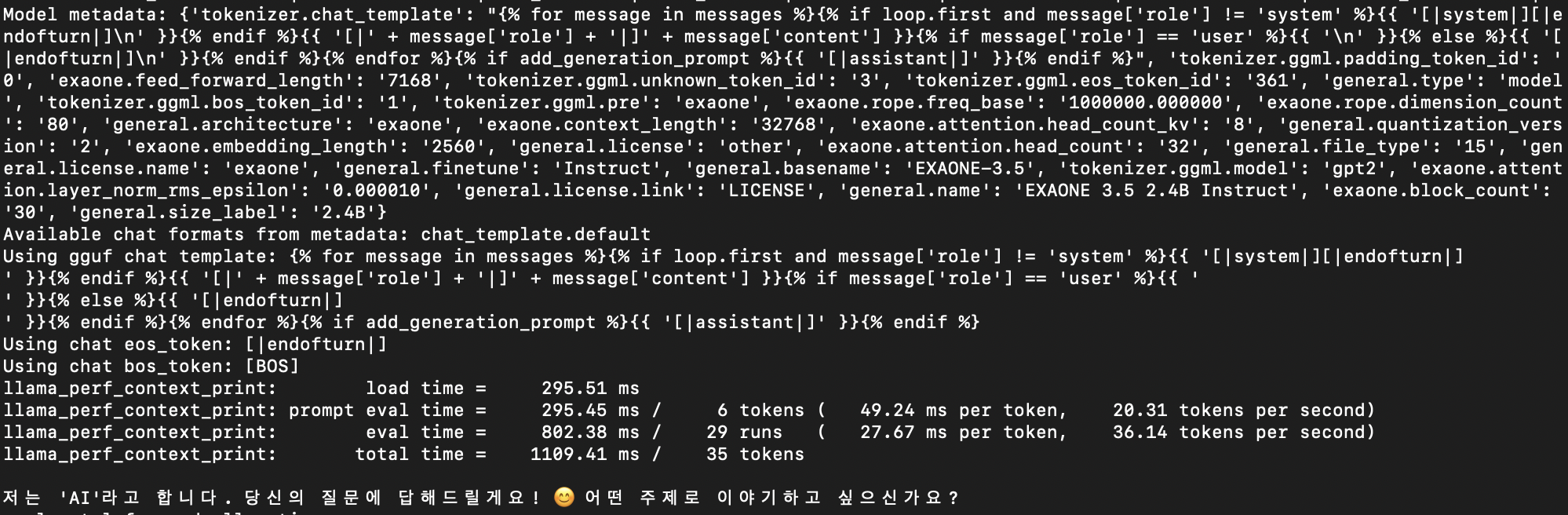
3-3. 좀더 뜯어보기.
- Using chat eos_token 이 [|endofturn|] 으로 되어있다. ollama 에서 봤던 그것과 똑같다.
- prompt 출력에 295.45ms, 추론 시간이 802.38 ms 걸렸다.
Using gguf chat template: {% for message in messages %}{% if loop.first and message['role'] != 'system' %}{{ '[|system|][|endofturn|]
' }}{% endif %}{{ '[|' + message['role'] + '|]' + message['content'] }}{% if message['role'] == 'user' %}{{ '
' }}{% else %}{{ '[|endofturn|]
' }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ '[|assistant|]' }}{% endif %}
Using chat eos_token: [|endofturn|]
Using chat bos_token: [BOS]
llama_perf_context_print: load time = 295.51 ms
llama_perf_context_print: prompt eval time = 295.45 ms / 6 tokens ( 49.24 ms per token, 20.31 tokens per second)
llama_perf_context_print: eval time = 802.38 ms / 29 runs ( 27.67 ms per token, 36.14 tokens per second)
llama_perf_context_print: total time = 1109.41 ms / 35 tokens3-4. 그 외 사용 가능한 옵션
| 옵션명 | 타입 | 필수 여부 | 설명 | llama.cpp 명령줄 인자 유사성 |
|---|---|---|---|---|
model_path | str | 필수 | GGUF 모델 파일의 경로 | -m, --model |
n_ctx | int | 선택 | 컨텍스트 창 크기 (처리할 수 있는 최대 토큰 수) | --ctx-size |
n_parts | int | 선택 | 모델을 분할할 파트 수 (병렬 처리) | (직접적인 유사 인자 없음) |
seed | int | 선택 | 난수 생성 시드. 특정 출력을 재현하는 데 유용 | -s, --seed |
f16_kv | bool | 선택 | KV (Key-Value) 캐시에 FP16 (부동 소수점)을 사용할지 여부 | (내부 구현 관련) |
logits_all | bool | 선택 | 모든 로짓 (Logits)을 반환할지 여부 | (내부 구현 관련) |
vocab_only | bool | 선택 | 어휘만 로드할지 여부 | (내부 구현 관련) |
use_mmap | bool | 선택 | 메모리 맵핑을 사용할지 여부 (기본값: True인 경우가 많음) | (내부 구현 관련) |
use_mlock | bool | 선택 | 메모리를 잠글지 여부 (RAM에 로드된 모델이 스왑 아웃되는 것을 방지) | (내부 구현 관련) |
n_gpu_layers | int | 선택 | GPU에 오프로드할 모델 레이어 수 (-1은 모두 오프로드, 0은 CPU만 사용) | -ngl, --n-gpu-layers |
main_gpu | int | 선택 | 여러 GPU가 있을 때 사용할 기본 GPU ID | --main-gpu |
tensor_split | List[float] | 선택 | GPU 간 텐서 분할 비율 (다중 GPU 사용 시) | --tensor-split |
rope_freq_base | float | 선택 | RoPE (Rotary Positional Embedding) 주파수 기본값 | --rope-freq-base |
rope_freq_scale | float | 선택 | RoPE 주파수 스케일 | --rope-freq-scale |
n_threads | int | 선택 | 텍스트 생성에 사용할 CPU 스레드 수 | -t, --threads |
n_batch | int | 선택 | 배치 처리 크기 (프롬프트 처리 시) | -b, --batch-size |
last_n_tokens_size | int | 선택 | 반복 패널티 등을 적용할 이전 토큰 개수 | --n-prev |
lora_path | str | 선택 | LoRA (Low-Rank Adaptation) 어댑터 파일의 경로 | --lora |
lora_scale | float | 선택 | LoRA 스케일링 팩터 | --lora-scale |
temperature | float | 선택 | 샘플링 온도 (0.0 ~ 2.0+). 낮을수록 결정론적, 높을수록 창의적 | --temp |
top_k | int | 선택 | Top-K 샘플링. 확률이 가장 높은 상위 K개 토큰만 고려 | -top-k |
top_p | float | 선택 | Top-P (nucleus) 샘플링. 누적 확률 P값 이내의 토큰만 고려 | -top-p |
min_p | float | 선택 | Min-P 샘플링. 최소 확률 P보다 높은 토큰만 고려 | --min-p |
typical_p | float | 선택 | Typical P 샘플링 매개변수 | --typical |
tfs_z | float | 선택 | TFS (Tail-Free Sampling) 매개변수 | --tfs |
repeat_penalty | float | 선택 | 반복 패널티 (1.0 이상). 값이 높을수록 반복되는 문구 감소 | -r, --repeat-penalty |
repeat_last_n | int | 선택 | 반복 패널티를 적용할 마지막 N개 토큰 (last_n_tokens_size와 유사) | --repeat-last-n / --n-prev |
mirostat_mode | int | 선택 | Mirostat 샘플링 모드 (0: 비활성화, 1: V1, 2: V2) | -mirostat |
mirostat_tau | float | 선택 | Mirostat 타겟 엔트로피(tau) 값 | -mirostat-tau |
mirostat_eta | float | 선택 | Mirostat 학습률(eta) 값 | -mirostat-eta |
max_tokens | int | 선택 | 생성할 최대 토큰 수 | -n, --n-predict |
stopping_words | List[str] | 선택 | 생성 중단 문자열 목록. 지정된 문자열이 생성되면 출력을 중단 | -s, --stop |
streaming | bool | 선택 | 스트리밍 출력을 사용할지 여부 | (API 관련) |
verbose | bool | 선택 | 상세 로깅 출력 여부 | -v, --verbose |
callbacks | List[BaseCallbackHandler] | 선택 | LangChain 콜백 핸들러 목록 | (LangChain 고유) |
4. 이것저것 버무려보자.
from langchain_community.llms import LlamaCpp
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from dotenv import load_dotenv
import time
from langchain_ollama import OllamaLLM
load_dotenv()
start = time.time()
# 1. LlamaCpp 모델 설정
# 로컬 모델 경로 지정, 콜백 매니저 연결
# 23 seconds
"""
llm = LlamaCpp(
model_path="./EXAONE-3.5-2.4B-Instruct_Q4_K_M.gguf",
temperature=0.1,
top_p=1,
verbose=True, # 모델 실행 시 출력 활성화
n_ctx=2048, # 컨텍스트 크기 설정
n_gpu_layers=0, # ⛔ GPU 안 쓰도록 설정 (CPU 전용)
n_threads=8, # 텍스트 생성에 사용할 CPU 스레드 수
n_batch=8, # 배치 처리 크기 (프롬프트 처리 시)
repeat_penalty=1, # 반복 패널티 (1.0 이상). 값이 높을수록 반복되는 문구 감소
)
"""
# 1-1. Ollama 모델 설정
# 10 seconds
llm = OllamaLLM(
model="exaone3.5:2.4b",
top_k=1,
temperature=0.1,
verbose=True,
n_ctx=2048,
n_threads=8,
n_batch=8,
repeat_penalty=1,
)
# 2. 커스텀 프롬프트 정의
custom_prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
### 시스템:
당신은 매우 유능한 AI 어시스턴트입니다. 사용자의 질문에 대해 문맥을 참고하여 정확하고 간결하게 답변하세요.
### 문맥:
{context}
### 질문:
{question}
### 답변:
""".strip()
)
# 3. 임베딩 모델 설정
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-xlm-r-multilingual-v1"
)
# 4. FAISS 벡터 저장소 로드
vectorstore = FAISS.load_local(
folder_path="/Users/exoluse/Desktop/dev/rag/faiss_index",
embeddings=embeddings,
allow_dangerous_deserialization=True
)
# 5. 체인 구성
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 1}),
chain_type_kwargs={"prompt": custom_prompt}
)
# 6. 질문을 주고 결과 받기 (최종 결과 출력)
result = chain({"query": "소행성 B612호는 무엇인가?"})
print(result["result"])
end = time.time()
print(f"Time taken: {end - start} seconds")4-1. llama.cpp 를 사용할 경우
약 15초 정도 걸렸다.
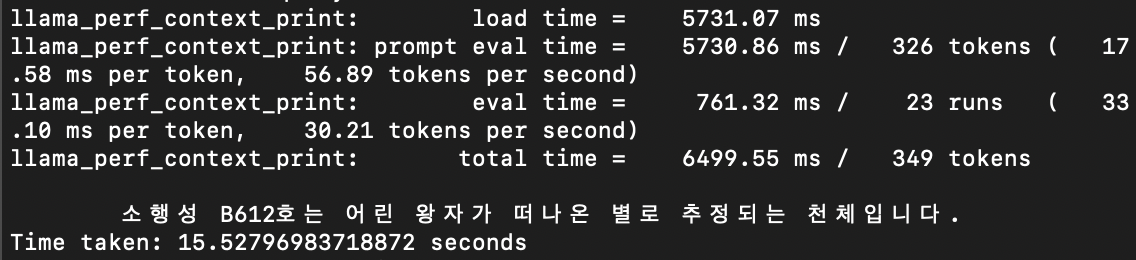
4-2. ollama 를 사용할 경우
아쉽지만 ollama 는 gguf 파일을 로드할 수 없다.

5. 비교 결과
ollama 의 사용성은 정말 최고이지만... 일단, 허깅페이스 모델을 다운로드 받아서 자유롭게 양자화하고 추론할 수 있다는 것에 llama.cpp 에 한표 던지고 싶다. 성능은 비슷한듯 하다.
6. 부록
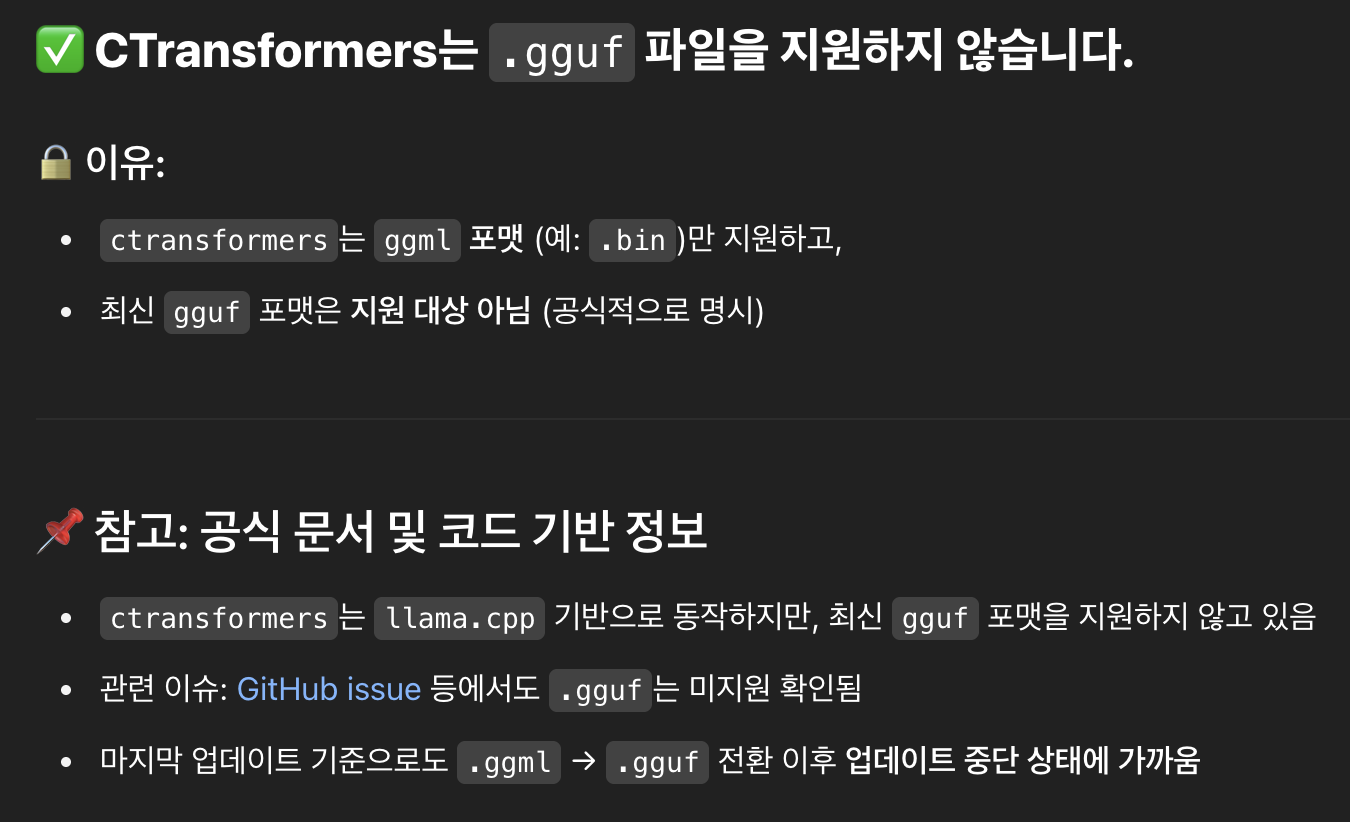
6-1. 허깅페이스 CTransformers
-
허깅페이스의 ctransformers 모듈로는 gguf 파일을 로드할 수 없었다.
-
pipeline 으로 시도해 봤지만... 로딩시간이 너무 오래 걸려서 때려 치았다.
6-2. llama.cpp 로 허깅페이스 Embedding 구현
구동이 안될 수 있다 하여 포기...

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.