1. postgresql 설치
2. vector extension 설치
CREATE EXTENSION IF NOT EXISTS vector;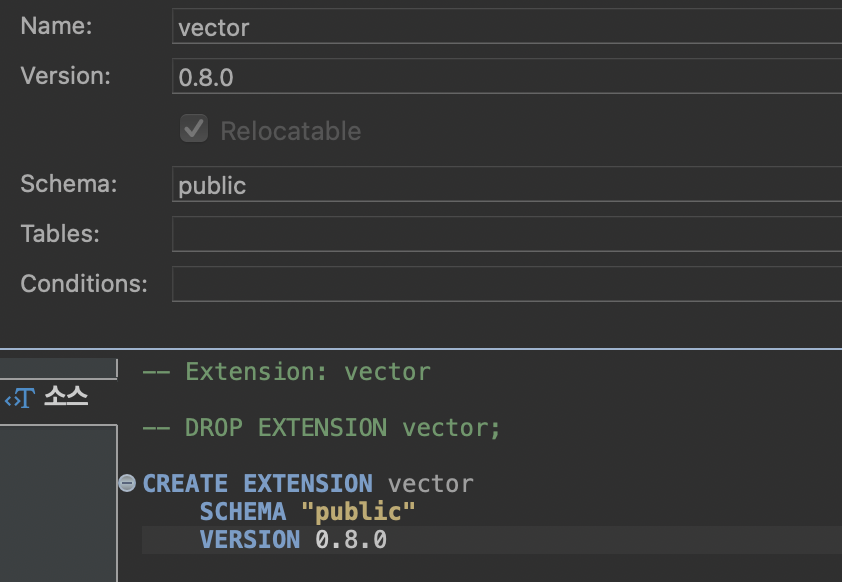
3. 확인
SELECT * FROM pg_extension;4. pgvector 설치
% brew install postgresql@17
% brew install gcc make
# 임시 디렉토리로 이동
cd /tmp
# pgvector 소스코드 다운로드
git clone --branch v0.5.1 https://github.com/pgvector/pgvector.git
# pgvector 디렉토리로 이동
cd pgvector
# 컴파일 및 설치 (Homebrew PostgreSQL 경로 사용)
make PG_CONFIG=/opt/homebrew/opt/postgresql@17/bin/pg_config
sudo make PG_CONFIG=/opt/homebrew/opt/postgresql@17/bin/pg_config install5. vector 데이터 insert
from langchain.text_splitter import CharacterTextSplitter
from modules.llm.embedding import getEmbedding
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores.pgvector import PGVector
from concurrent.futures import ThreadPoolExecutor
# 어린왕자 PDF 파일 로드
loader = PyPDFLoader("./prince.pdf")
pages = loader.load()
# 문서 분할
text_splitter = CharacterTextSplitter(
chunk_size=1000, # 청크 크기
chunk_overlap=200, # 청크 간 겹침
length_function=len, # 길이 측정 함수
)
split_docs = text_splitter.split_documents(pages)
def process_batch(batch):
try:
return PGVector.from_documents(
documents=batch,
embedding=getEmbedding(),
connection_string="postgresql://postgres:1234@localhost:5432/postgres",
collection_name="document"
)
except Exception as e:
print(f"Error processing batch: {e}")
raise
batch_size = 10
with ThreadPoolExecutor(max_workers=16) as executor:
batches = [split_docs[i:i + batch_size] for i in range(0, len(split_docs), batch_size)]
# futures를 리스트로 수집하여 결과 확인
futures = list(executor.map(process_batch, batches))
# 결과 확인
for i, future in enumerate(futures):
print(f"Batch {i} processed successfully")5-1. insert 결과
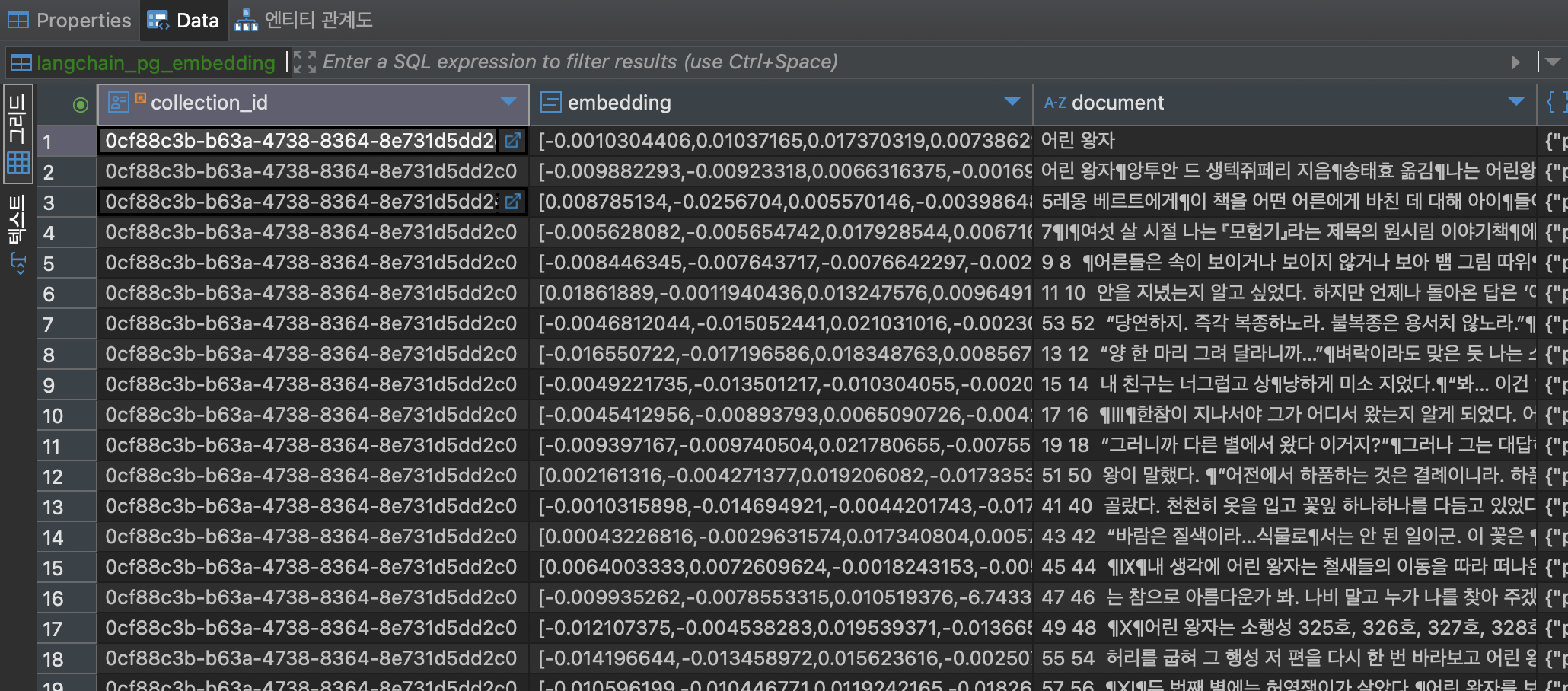
6. vector 데이터 select
from modules.data.postgre import getPostgreRetriever
from modules.llm.llm import getLlm
from langchain.chains import RetrievalQA
from langchain import hub
retriever = getPostgreRetriever();
llm = getLlm();
# 프롬프트를 제공한다.
prompt = hub.pull("rlm/rag-prompt")
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type_kwargs={"prompt": prompt}
)
ai_message = chain({"query": """어린 왕자의 변신 이야기"""}) # Changed query to input
print(ai_message)6-1. 결과
뭔가 또 개소리를 시원하게 날려주고 있다...
ai_message = chain({"query": """두 번째 별에는 누가 살았는가?"""}) # Changed query to input
{'query': '두 번째 별에는 누가 살았는가?', 'result': '두 번째 별에는 어린 왕자가 살고 있다. 어린 왕자는 날아다니는 비행기를 보고 놀라고, 나무가 넘어지듯 넘어졌는데 그의 별에 무슨 일이라도 생긴 걸까? 하는 생각을 한다.'}내가 원했던 데이터는... ㅠㅠ

Finally
적은 양의 데이터이지만 insert 하는데에 엄청난 시간이 들었는데... (특히 인텔 시스템인 사무실 컴퓨터에서는 30분 정도가 들었다. ) 데이터 수집의 문제인지 할루시네이션이 좀 많이 심한 듯 하다. 여러 방법으로 실험이 필요한 듯 하다.

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.