1. 분석할 이미지 선정
배경은 고속도로 이고 사고가 난 모습이다.

2. 사용 모델
2-1. Vision model : llava-llama3
2-2. LLM : exaone3.5:7.8b
3. 전체 소스
import base64
import requests
from langchain.tools import tool
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_community.llms import Ollama
from typing import Optional
# 1. llava 를 이용한 이미지 설명
def describe_image(image_path: str, prompt: Optional[str] = "Describe the image in detail") -> str:
with open(image_path, "rb") as f:
image_base64 = base64.b64encode(f.read()).decode()
res = requests.post("http://localhost:11434/api/generate", json={
"model": "llava-llama3",
"prompt": prompt,
"images": [image_base64],
"stream": False
})
return res.json().get("response", "").strip()
# 2. exaone3.5용 LangChain 구성
exaone_llm = Ollama(model="exaone3.5:7.8b")
exaone_prompt = PromptTemplate(
input_variables=["image_caption", "user_question"],
template="""
다음은 이미지 설명입니다:
{image_caption}
위 이미지를 기반으로 다음 질문에 답해주세요:
{user_question}
답변:
"""
)
# 3. exaone3.5 체인 구성
exaone_chain = LLMChain(llm=exaone_llm, prompt=exaone_prompt)
# 4. 전체 파이프라인 실행
if __name__ == "__main__":
image_path = "./fire.jpg"
user_question = "이 사진에는 무엇이 보이니?"
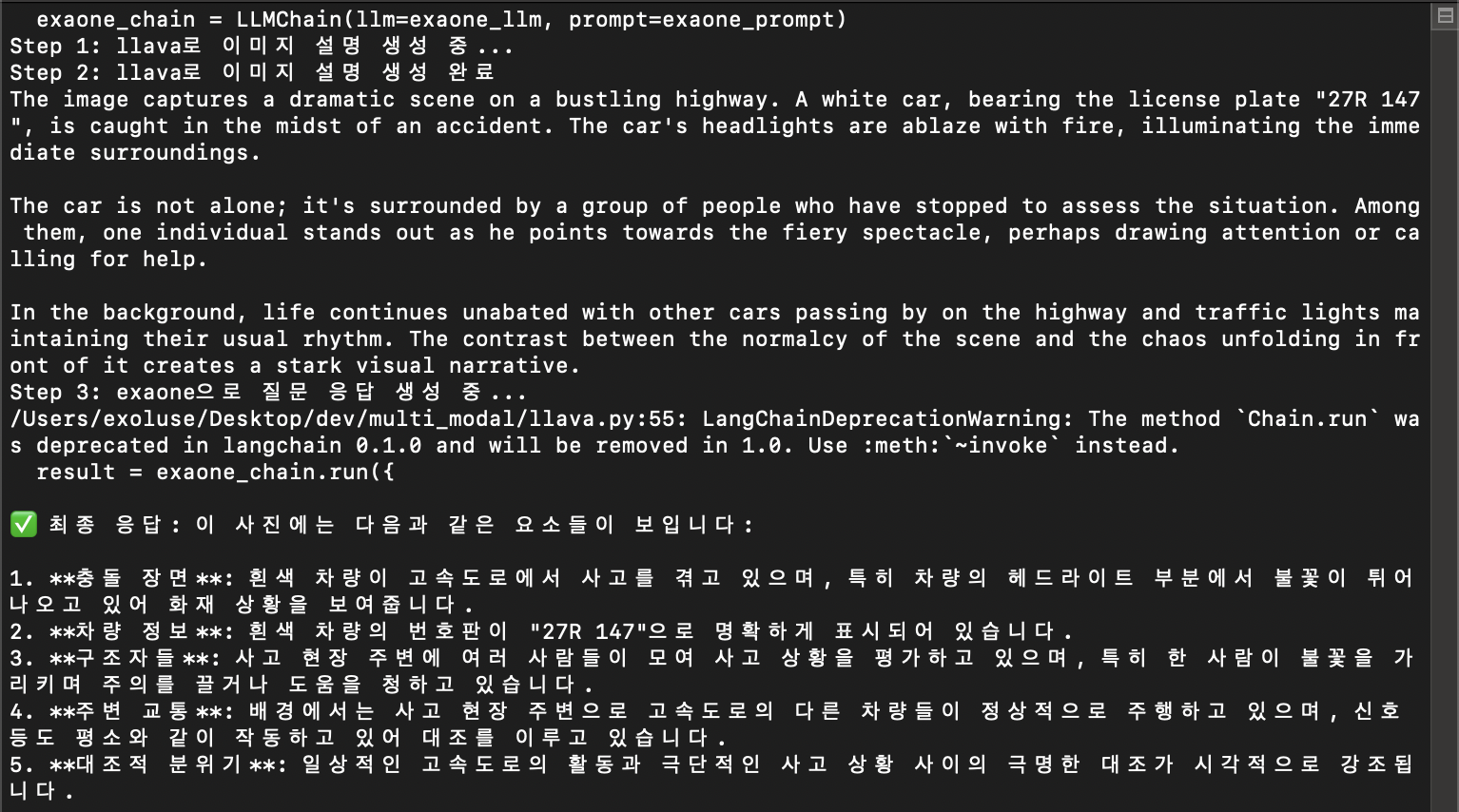
print("🖼️ Step 1: llava로 이미지 설명 생성 중...")
caption = describe_image(image_path)
print("🧠 Step 2: exaone으로 질문 응답 생성 중...")
result = exaone_chain.run({
"image_caption": caption,
"user_question": user_question
})
print("\n✅ 최종 응답:", result)4. 결과
4-1. llava-llama3 결과 (영한 번역)
이 사진은 북적이는 고속도로의 극적인 장면을 포착합니다. "27R 147" 번호판을 단 흰색 차량 한 대가 사고 현장에 갇힙니다. 차량의 헤드라이트는 불꽃으로 가득 차 주변을 비춥니다.
차량은 혼자가 아닙니다. 상황을 파악하기 위해 차를 세운 사람들이 주변에 있습니다. 그중 한 사람이 이글거리는 광경을 가리키며 주의를 끌거나 도움을 요청하는 듯합니다.
배경에서는 고속도로를 따라 다른 차량들이 지나가고 신호등은 평소와 같은 리듬을 유지하는 가운데, 삶이 끊임없이 이어집니다. 평범한 장면과 눈앞에서 펼쳐지는 혼돈의 대비는 강렬한 시각적 서사를 만들어냅니다.4-2. exaone3.5 결과
✅ 최종 응답: 이 사진에는 다음과 같은 요소들이 보입니다:
1. **충돌 장면**: 흰색 차량이 고속도로에서 사고를 겪고 있으며, 특히 차량의 헤드라이트 부분에서 불꽃이 튀어나오고 있어 화재 상황을 보여줍니다.
2. **차량 정보**: 흰색 차량의 번호판이 "27R 147"으로 명확하게 표시되어 있습니다.
3. **구조자들**: 사고 현장 주변에 여러 사람들이 모여 사고 상황을 평가하고 있으며, 특히 한 사람이 불꽃을 가리키며 주의를 끌거나 도움을 청하고 있습니다.
4. **주변 교통**: 배경에서는 사고 현장 주변으로 고속도로의 다른 차량들이 정상적으로 주행하고 있으며, 신호등도 평소와 같이 작동하고 있어 대조를 이루고 있습니다.
5. **대조적 분위기**: 일상적인 고속도로의 활동과 극단적인 사고 상황 사이의 극명한 대조가 시각적으로 강조됩니다.
이러한 요소들이 결합되어 강렬하고 대비적인 장면을 만들어냅니다.4-3. 터미널 화면

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.